本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院
在各行业中,AI知识库已成为提升效率的核心工具。今天我将通过企业实际落地案例,详解从架构设计到性能优化的全流程技术方案,助你避开共性陷阱。希望对你有所帮助,记得点个小红心,你的鼓励就是我更新的动力。
一、企业常见业务痛点与技术选型
典型业务场景
- 分散文档管理(Word/PDF/Markdown混合存储)
- 高频技术咨询(容器操作、API调用、故障排查)
- 专家经验依赖导致的响应延迟
技术选型黄金三角
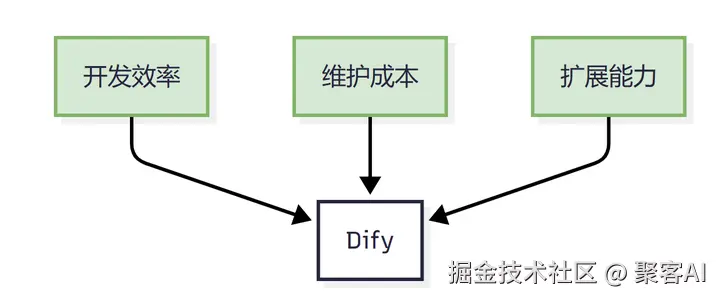
选择依据:
- Dify平台可视化工作流降低60%开发门槛
- 原生支持多模态解析(文本/表格/图像)
- 无缝集成BGE-M3向量模型与通义千问72B大模型
二、文档处理核心难题与解决方案
1. PDF表格提取优化(坑点1)
问题:边框缺失/跨页表格解析失败
代码级解决方案:
python
def extract_tables(pdf_path, page):
# 三级降级策略
try:
tables = camelot.read_pdf(pdf_path, flavor='lattice') # 有边框表格
if validate(tables): return tables
except:
tables = camelot.read_pdf(pdf_path, flavor='stream') # 无线表格
if validate(tables): return tables
return pdfplumber_extract(pdf_path) # 兜底方案2. 文档智能切分(坑点2)
保留技术文档的层级结构:
ini
def group_by_section(elements):
blocks = []
for elem in elements:
if elem.type == "Heading":
blocks.append([]) # 新建章节块
blocks[-1].append(elem) # 归集内容3. 多模态统一处理(坑点3)
技术文档中的关键元素处理方案:
| 元素类型 | 处理方案 | 输出格式 |
|---|---|---|
| 代码块 | Pygments语法高亮 | Markdown代码栏 |
| 参数表格 | Camelot+人工校验 | CSV矩阵 |
| 系统截图 | CLIP视觉特征提取 | 图文关联索引 |
三、工作流设计关键技术
1. 多模态路由架构(坑点4)
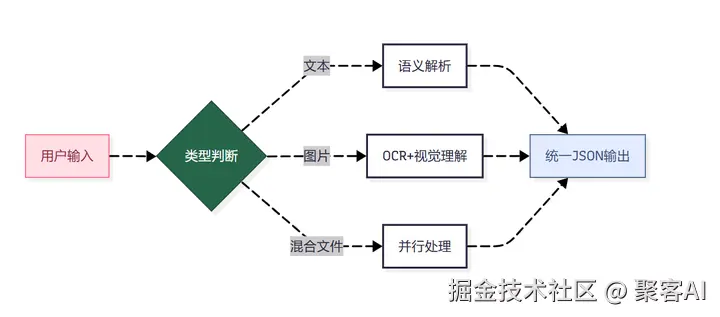
2. 上下文标准化(坑点5)
解决多轮对话格式混乱:
python
def normalize_history(hist):
if isinstance(hist, list): return hist # 标准列表格式
elif isinstance(hist, str):
try: return json.loads(hist) # 尝试解析字符串
except: return [{'role':'user','content':hist}] # 兜底方案3. 三阶段意图分析(坑点6)
- 关联分析:计算当前问题与历史对话的余弦相似度
- 意图提炼:使用Qwen2.5模型生成完整query
- 决策判断:根据置信度选择检索/追问/直答策略
四、知识库安全与性能优化
1. 向量检索权限控制(坑点7)
元数据过滤方案:
json
{
"chunk_content": "数据库连接配置",
"metadata": {
"role": "dba",
"security_level": "confidential"
}
}检索时动态过滤:
ini
filter = {"role": user_role, "security_level": {"$lte": user_clearance}}2. 性能调优四板斧(坑点8)
- 并行处理:PySpark加速文档解析
- 缓存机制:Redis缓存Top100问答对
- 异步响应:Celery处理大文件上传
- 负载均衡:Kubernetes自动扩缩容
五、质量保障体系
五维测试矩阵(坑点9)
| 测试类型 | 验证重点 | 示例用例 |
|---|---|---|
| 基础检索 | 单点问题准确性 | "如何创建K8s服务?" |
| 多轮对话 | 上下文连贯性 | "上一个方法的替代方案?" |
| 综合推理 | 跨文档信息整合 | "容器启动失败的常见原因" |
| 边界测试 | 异常输入处理 | "你确定吗?我觉得不对" |
| 格式化输出 | 复杂内容呈现 | "用表格列出API参数" |
回答质量四原则(坑点10)
- 知识库外问题明确拒答
- 歧义场景主动追问
- 所有回答标注来源文档
- 用户反馈驱动迭代
这里还是想说一下,如果你想往AI大模型岗位去发展,或者企业对这块有需求,建议你还是系统的学习一下AI大模型应用开发,零零碎碎的知识会让你在实践中遇到很多的坑,这里为你整理了一套学习路径,粉丝朋友自行领取《如何更系统的学习AI大模型,挑战AI高薪岗位?》
六、关键实施建议
- MVP先行:首期聚焦35%最高频问题(如容器操作)
- 文档预清洗:投入20%时间做文档标准化(格式/术语)
- 渐进式训练:
最后总结一下:企业需持续优化知识蒸馏(Knowledge Distillation)与工作流编排,方能将AI知识库转化为真正的生产力引擎。好了,今天的分享就到这里,点个小红心,我们下期见。