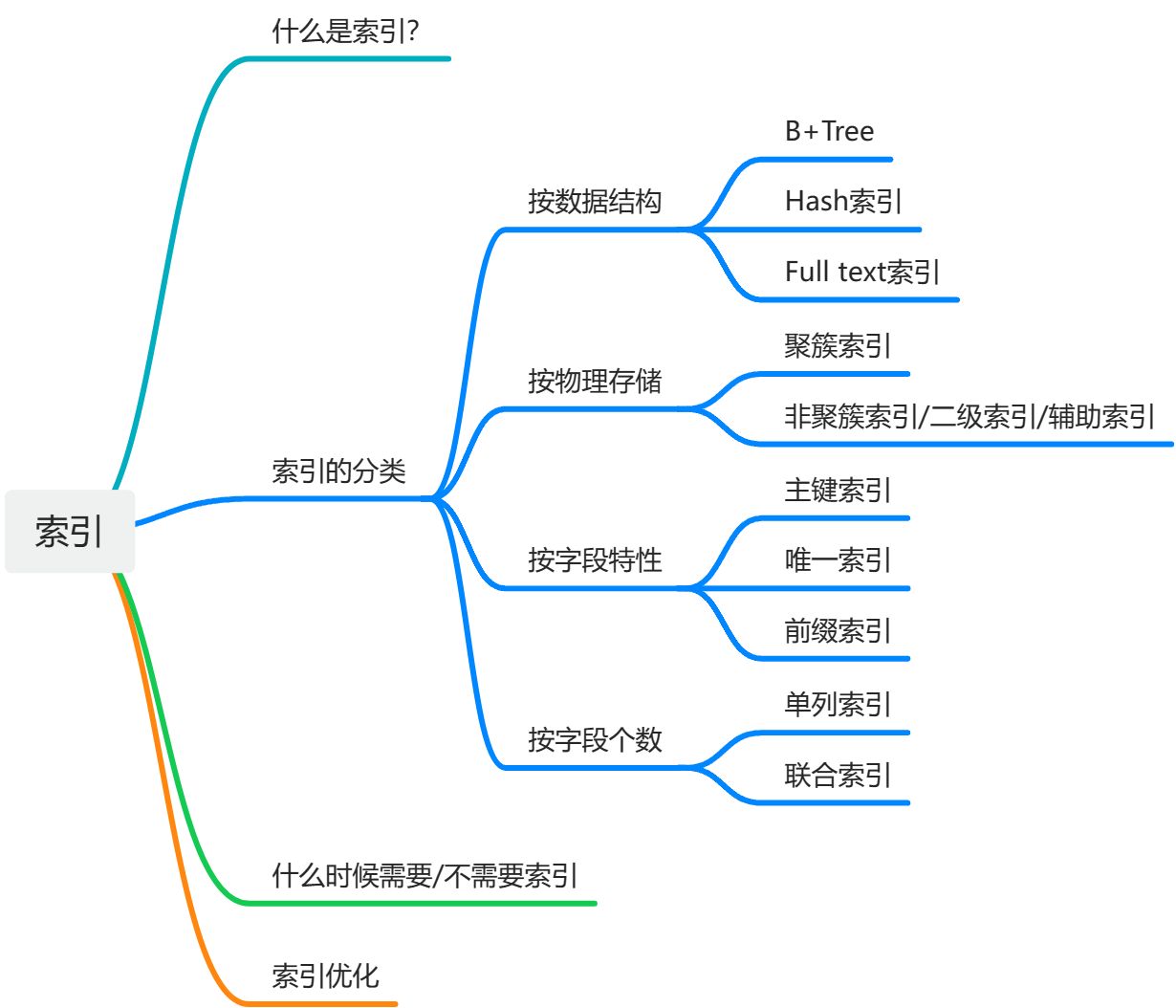
一. 什么是索引?
- 索引是用来帮助存储引擎快速检索数据的一种数据结构;索引可以被称为数据的目录。
- 在InnoDB中,数据是通过聚簇索引存储的,其他字段构成的索引是非聚簇索引存储的是主键的值。
- 在MyISAM中,是非聚簇索引存储数据的地址,进而检索数据。
二. 常见存储引擎支持的索引结构
| InnoDB | B+Tree,自适应Hash索引,Full-Text索引 |
|---|---|
| MyISAM | B+Tree,Full-Text索引 |
| Memory | B+Tree,Hash索引 |
B+Tree为InnoDB默认的索引存储结构,InnoDB的数据存储结构为聚簇索引,叶子节点存储的是完整的数据;
当表中有主键的时候,会按主键作为聚簇索引的Key,
当表中没有主键,会以第一个不含Null值的列作为聚簇索引的Key,
当以上都不满足,会默认生成隐式自增id,作为聚簇索引的Key。
其他的索引都是辅助索引/非聚簇索引。
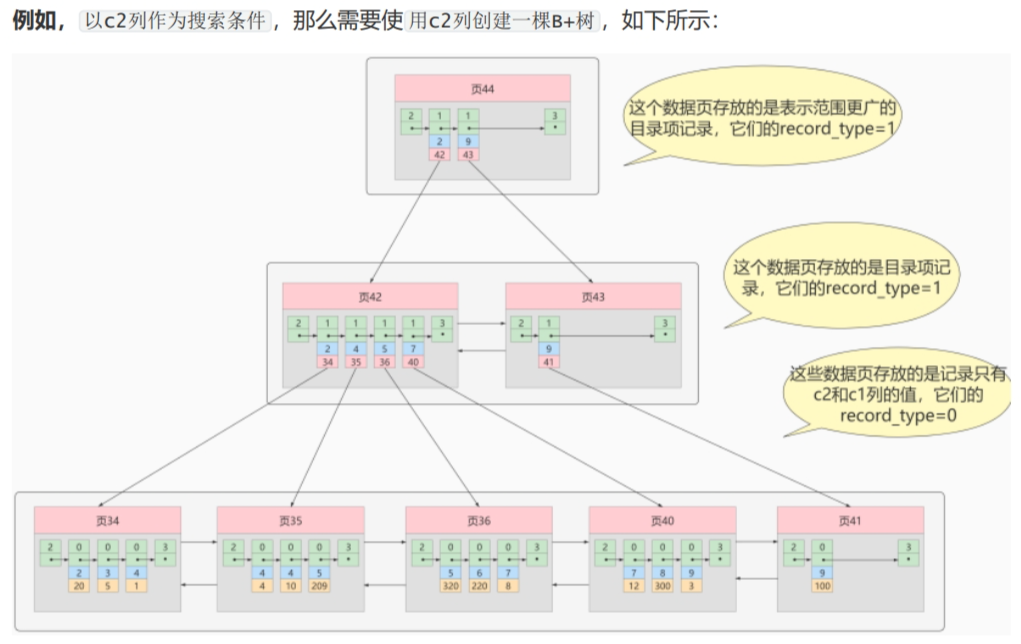
三. B+Tree聚簇索引(InnoDB)
首先我们要知道数据页 ,和记录行 两个概念。对于存储引擎默认生成的主Key索引来说
记录行
记录行分为:
- 目录记录行
B+Tree聚簇索引的非叶子节点存放的是目录记录行,存储的是指向下一条目录记录行的指针,指向数据页最小索引(主键)大小的数据,和数据页的页号。
| record_type | next_record | key | page |
|---|---|---|---|
| 表示记录的类型 | 指向下一个记录行的指针 | 对应数据页最小主键信息 | 对应主键的记录行位于所在页的偏移量。 |
| 0为叶子节点,2为最小记录,3为最大记录,1为非叶子节点 | 可以快速定位记录行的位置。 |
- 数据记录行
B+Tree聚簇索引的叶子节点存放的是数据记录行,存储的是指向下一条数据记录行的指针,主键,其他数据。
| record_type | next_record | key | other data |
|---|---|---|---|
| 表示记录的类型 | 指向下一个记录行的指针 | 主键 | 完整的数据 |
| 0为叶子节点,2为最小记录,3为最大记录,1为非叶子节点 |
数据页
MySQL中数据是以页为单位加载到内存中,一个页默认大小为16KB。一个页中包含多个记录行。我们重点关注的就是User Record和Page Directory两个数据页的组成部分。
- User Record 用于存储真实的数据(存放的数据记录行)。
- Page Directory 用于对真实数据简历的目录(存放的目录记录行)。
记录行与记录行之间是单链表结构,数据页与数据页之间是双链表结构。在数据页中数据都是按照主键的大小进行排序,我们拥有了最小和最大主键记录的偏移量,采用二分法的形式然后与查询条件主键进行比较,从而快速的定位到所在的分组后,再按照单向链表找到指定的主键对应的记录。这样查询效率迅速提升。
综合以上内容,生成下面的索引结构就是B+Tree的聚簇主键索引结构:

四. 非聚簇索引的存储结构(InnoDB)
非聚簇索引的存储结构和聚簇索引的存储结构类似,有以下不同:
- 非叶子节点不存储主key的值,而是存储构建索引字段的值(c2,c3...),按照索引大小进行排序,c2相同大小对c3进行排序,
- 叶子节点存储的是(c2,c3...)和主key(c1)的值。
五. 聚簇索引和非聚簇索引的区别
- 聚簇索引
- 叶子节点存储的是主键和用户数据。
- 非叶子节点存储的是主键+页号。
- 页内是按照主键大小排成的单项链表。
- 页和页之间是按照主键大小拍成的双向链表。
优点:
- 访问数据更快,因为数据和索引在一个B+树中。
- 对于主键的排序查找和范围查找速度很快。
- 数据库可以从更少的数据块中查找数据,减少IO次数。
缺点:
- 插入数据是按照主键大小进行插入,如果不是顺序插入可能会引起页分裂,严重影响性能。我们一般使用自增ID作为主键。
- 更新主键的代价很大,一般定义主键不能更新。
特点:
- 一张表只能有一个聚簇索引。
- 只有InnoDB支持聚簇索引。
- 只有在搜索条件是主键的时候才会发挥作用
- 非聚簇索引
- 叶子节点存储的是主键和构成索引字段的值。
- 非叶子节点存储的是c2,c3...和页号。
- 页内记录是按照c2,c3...大小拍成的单项链表。
- 页与页之间按照c2,c3...大小拍成的双向链表。
特点:
- 一张表可以有多个非聚簇索引。
MyISAM中的非聚簇索引
与InnoDB唯一区别就是,在叶子节点中,MyISAM存储的是主键对应记录行数据的地址的指针。
七. B+树和B树的区别
- B+树中非叶子节点的关键字(索引值)也会同时存在在子节点中,并且是在子节点中所有关键字的最大值 (或最小)。
- B+树中非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。
- B树 中, 非叶子节点既保存索引,也保存数据记录 。
- B+树中所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键 字的大小从小到大顺序链接。
八. InnoDB索引查询的流程
假设我们表结构为:
| id(主键) | age(索引) | name |
|---|---|---|
| 1 | 12 | xxx |
| 2 ... | 13 ... | mmm ... |
InnoDB会根据id主键默认生成一棵聚簇索引树来存储数据,叶子节点存储的就是完整的数据。
用户自定义age字段为索引,存储引擎会根据age字段生成一棵非聚簇索引树,叶子节点存储的是主键id的值。
SQL语句如下:
select name from tb where age =13;
查询过程:
因为过滤字段为age,首先会在非聚簇索引的跟节点使用二分法找到age=13所在的区间对应的下一层page节点,找到page再在page中使用二分法找到age=13对应的第三层数据页的page,第三层也就是叶子节点,存储的是age,和主键值,使用二分法找到age=13的主键id值.
因为我们需要的是name字段的值,所以会根据得到的id值,再到聚簇索引中使用上述同样的方法查找完整的数
据,这个过程称为**回表查询. **最终得到name的值.
InnoDB和MyISAM索引机制的区别
InnoDB包含一个聚簇索引,其他都是非聚簇索引;MyISAM的索引方式都是非聚簇的。MyISAM所有索引都需要回表,InnoDB在走主键索引不需要回表,MyISAM回表的速度很快因为叶子节点存储的是数据地址的偏移量,InnoDB是根据主键值再去聚簇索引中查询。
九. 索引覆盖
索引覆盖就是当我们在使用非聚簇索引在查询字段的时候,这个字段的值同样是构成该索引树的字段,这种情况下不需要进行回表操作,直接将该值返回。
例如:表中索引为 (a,b)
SQL为:
sql
select a,b from tb where a=1;使用非聚簇索引找到符合a=1的数据,直接将a,b值合并返回;不需要回表查询。
十. 索引下推
索引下推是MySQL的新特性,这种情况发生在当我们查询的字段有多个,在使用联合索引查询字段的时候,不满足所有的索引字段都在过滤条件中,MySQL会把索引当中的所有数据全部用到减少回表的次数。
例如:表中有联合索引(a,b,c)
sql
where a=.. and b=.. and c=..该SQL会完全使用到索引。
sql
where a=.. and c=..该SQL会使用到索引a,因为b索引断了,索引c此时会浪费掉。
如果没有索引下推:
MySQL会将符合 a=.. 条件的主键,进行回表查询,然后判断c字段的值是否符合;有索引下推:
MySQL会接着判断c字段是否符合条件,因为c也在索引的结构中,将不符合的条件过滤,最后再进行回表查询,减少了回表的次数,提高查询效率。注意: 索引是遵循最左匹配原则的,如果直接从第二个字段查询,就会索引失效,全表扫描。
索引: (a,b,c)
sql
where b =.. and c=...十一. 索引跳跃
MySQL一定是遵循最左前缀匹配的,这句话在以前是正确的,但是在MySQL 8.0出现了索引跳跃扫描。
MySQL 8.0.13 版本中,对于range查询引入了索引跳跃扫描(Index Skip Scan)优化,支持不符合组合索引最左前缀原则条件下的SQL,依然能够使用组合索引,减少不必要的扫描。
举例:
表中索引为:(a,b,c)
SQL语句为: 该sql不符合最左前缀匹配,在以前版本的mysql不会用到索引
sql
select a from tb where c>40;
使用Explain工具查看:在新版本的MySQL中是使用到索引的

原理:
首先获取a,b字段的值,例如a=1,b=1;然后构造 where a=1 and b=1 and c>40;进行范围查询
一直到扫描完了a字段所有的唯一值,b字段的所有唯一值,最后将结果合并返回;使用该策略可以减少访问的行数,因为会跳过不符合构造范围的行。
限制条件:
- 不能联表查询
- 不能使用group by聚合,以及distinct
- 查询的字段必须为索引中的列
十二. 索引失效的情况
- 使用左/左右模糊匹配的时候('%like','%like%')
- 在查询条件中使用索引列进行计算/函数/类型转换操作的时候.
- 联合索引不符合最左前缀匹配原则(除去索引跳跃的情况).
- or 字段前是索引列,后不是索引列的情况.
- 为了更好利用索引,索引列需要使用Not Null修饰.
十三. 索引优化方法
- 前缀索引优化
前缀索引顾名思义就是使用某个字段中字符串 的前几个字符建立索引,那我们为什么需要使用前缀来建立索引呢?使用前缀索引是为了减小索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
不过,前缀索引有一定的局限性,例如:order by 就无法使用前缀索引;无法把前缀索引用作覆盖索引;
- 覆盖索引优化
- 主键索引最好是递增的
- 防止索引失效
十四. Explain工具字段解释

对于执行计划,参数有:
- possible_keys 字段表示可能用到的索引;
- key 字段表示实际用的索引,如果这一项为 NULL,说明没有使用索引;
- key_len 表示索引的长度;
- rows 表示扫描的数据行数。
- type 表示数据扫描类型,我们需要重点看这个。
type 字段就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为:
- All(全表扫描);
- index(全索引扫描);
- range(索引范围扫描);
- ref(非唯一索引扫描);
- eq_ref(唯一索引扫描);
- const(结果只有一条的主键或唯一索引扫描)。
除了关注 type,我们也要关注 extra 显示的结果。
这里说几个重要的参考指标:
- Using filesort :当查询语句中包含 group by 操作,而且无法利用索引完成排序操作的时候, 这时不得不选择相应的排序算法进行,甚至可能会通过文件排序,效率是很低的,所以要避免这种问题的出现。
- Using temporary:使了用临时表保存中间结果,MySQL 在对查询结果排序时使用临时表,常见于排序 order by 和分组查询 group by。效率低,要避免这种问题的出现。
- Using index:所需数据只需在索引即可全部获得,不须要再到表中取数据,也就是使用了覆盖索引,避免了回表操作,效率不错。
十五. 索引和Count字段
我们都知道Count(), Count(1),Count(主键),Count(其他字段)都是求个数的操作.Count(), Count(1),Count(主键)都是计算出表中数据总和, Count(其他字段)是计算这个字段不为Null的行数.他们都有什么区别呢?
通过上面的介绍我们知道了聚簇索引,二级索引.
Count(*),Count(1)
在MySQL中Count()和Count(1)其实是一样的道理,Count()会被转化成Count(0);所以它们两个其实是一样的.是怎么计算的呢?
当表中不含有二级索引,上面两个计算都是通过主键索引也就是扫描聚簇索引,InnoDB循环遍历聚簇索引,将得到的记录返回给Server层,因为括号里面的是数字不是字段,所以不需要读取字段的值,每读到一条记录就会count变量+1,最终返回.
当表中含有二级索引,InnoDB会选择扫描二级索引进行计算,因为二级索引是非聚簇索引,所占的空间比聚簇索引少,IO次数就少成本低.
Count(主键)
Count(主键)和上面两个不同之处是,括号里面的参数是字段,在进行计算的时候,InnoDB会读取字段的值,所以该操作会比上面两个操作多一个步骤,成本更高一些.
计算过程同上,多一个读取主键值的步骤.
Count(字段)
当该字段不是二级索引的时候,计算操作是扫描全表,Explain中type字段为ALL,所以它的成本比上面的操作都要大.为了减小该操作的成本,建议为括号里面的字段构建二级索引.
其他
上面描述的都是InnoDB存储引擎的操作,在MyISAM中,会将Count(*)的保存成常量,请求的时候直接返回,成本比InnoDB小的多.
#总结
Count(*)=Count(1)<Count(主键)<Count(字段)