1.创建;
create database if not exists myhive;

use myhive;

2.查看:
查看数据库详细信息:desc database myhive;

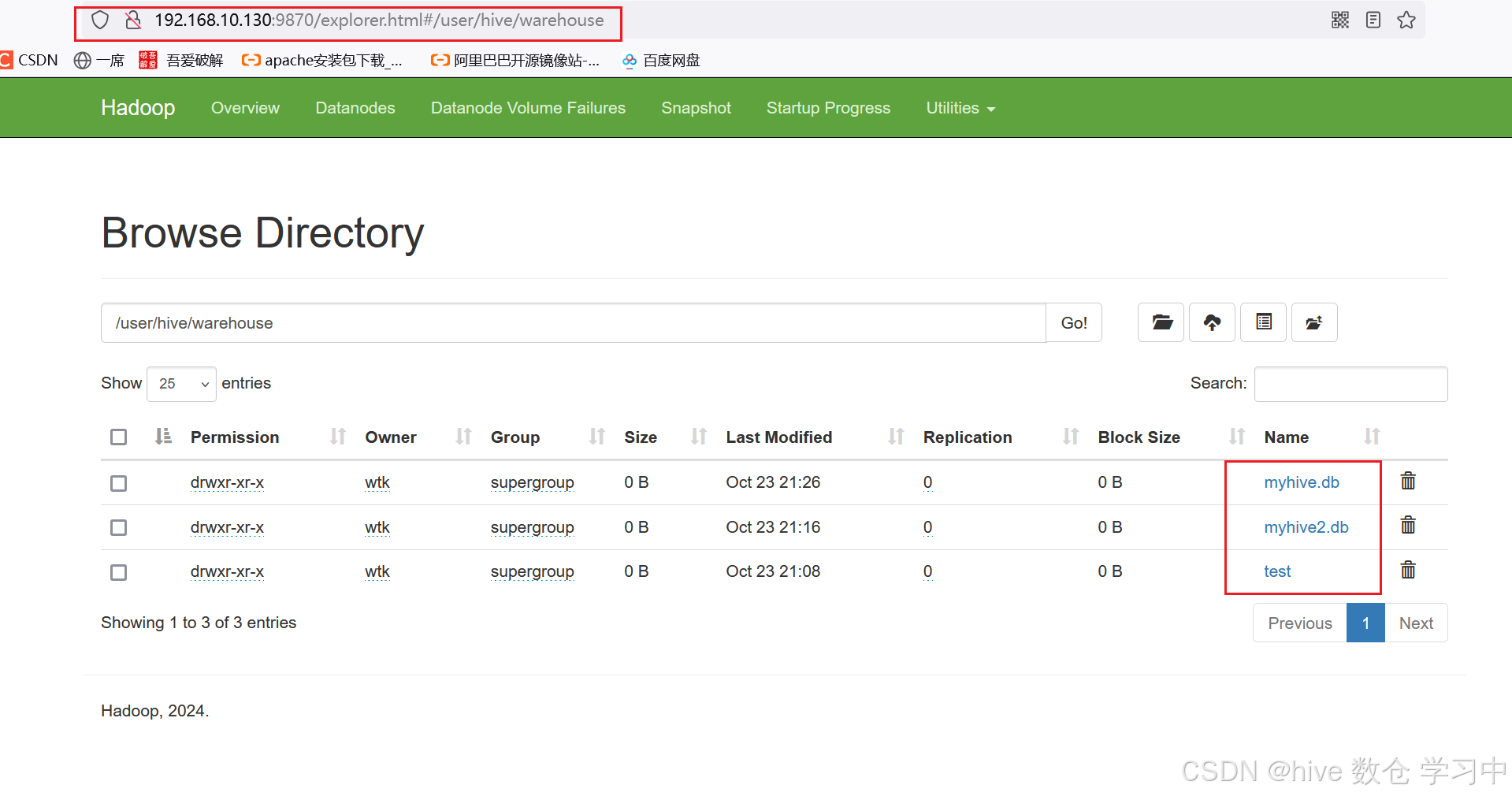
默认数据库的存放路径是 HDFS 的: /user/hive/warehouse 内
补充:创建数据库并指定 hdfs 存储位置:create database myhive2 location '/myhive2

3.删除一个空数据库,如果数据库下面有数据表,那么就会报错
drop database myhive;
强制删除数据库,包含数据库下面的表一起删除
drop database myhive2 cascade;
4.创建数据库表语法

EXTERNAL,创建外部表
PARTITIONED BY,分区表
CLUSTERED BY,分桶表
STORED AS,存储格式
LOCATION,存储位置
eg:
CREATE TABLE test(
id INT,
name STRING,
gender STRING
);
5.删除表: 命令:DROP TABLE table_name;
6.内部表和外部表:
内部表( CREATE TABLE table_name ...... ):
未被 external 关键字修饰的即是内部表, 即普通表。 内部表又称管理表 , 内部表数据存储的位置由hive.metastore.warehouse.dir 参数决定(默认: /user/hive/warehouse ),删除内部表会直接删除元数据( metadata )及存储数据,因此内部表不适合和其他工具共享数据。
外部表( CREATE EXTERNAL TABLE table_name ......LOCATION...... ):
被 external 关键字修饰的即是外部表, 即关联表。外部表是指表数据可以在任何位置,通过 LOCATION 关键字指定。 数据存储的不同也代表了这个表在理念是并不是Hive 内部管理的,而是可以随意临时链接到外部数据上的。所以,在删除外部表的时候, 仅仅是删除元数据(表的信息),不会删除数据本身。

操作:创建一个基础的表(加入插入)
create database if not exists myhive;
use myhive;
create table if not exists stu(id int,name string);
insert into stu values (1,"zhangsan"), (2, "wangwu");
select * from stu;

内部表: