- Filebeat 是 Elastic Stack 中的一个轻量级日志转发器,主要用于收集和转发日志数据。
- Filebeat 作为代理安装在您的服务器上,可以监控您指定的日志文件或位置,收集日志事件,并将其转发到 Elasticsearch 或 Logstash 进行索引。
一、原理
How Filebeat works | Filebeat Reference 8.15 | Elastic
Filebeat 的工作原理如下:启动 Filebeat 时,它会启动一个或多个输入,这些输入会查找您为日志数据指定的位置。对于 Filebeat 找到的每个日志,Filebeat 都会启动一个采集器。每个采集器都会读取新内容的单个日志,并将新的日志数据发送到 libbeat,libbeat 会聚合事件并将聚合数据发送到您为 Filebeat 配置的输出。
Filebeat 的两个主要组件
- Harvester 负责读取单个文件的内容。Harvester 逐行读取每个文件,并将内容发送到输出。为每个文件启动一个 harvester。Harvester 负责打开和关闭文件,这意味着当 Harvester 运行时,文件描述符保持打开状态。
- input 负责管理采集器并查找所有要读取的源 。
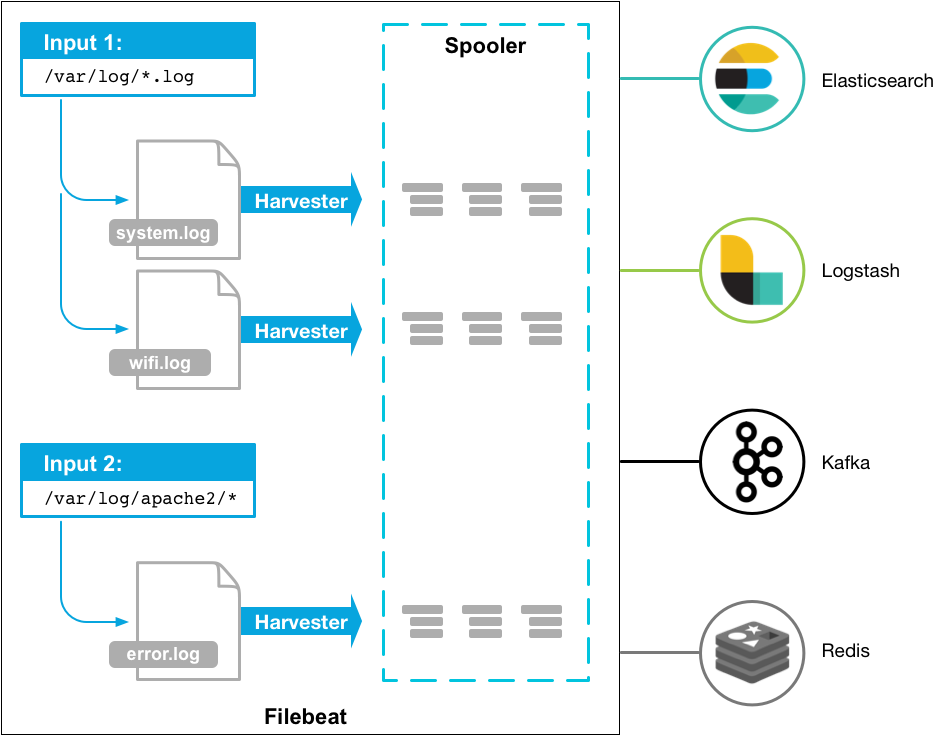
Filebeat 如何保持文件的状态
Filebeat 会保留每个文件的状态,并经常将状态刷新到注册表文件中的磁盘。该状态用于记住 Harvester 读取的最后一个偏移量,并确保发送所有 log 行。如果无法访问输出(例如 Elasticsearch 或 Logstash),Filebeat 会跟踪发送的最后一行,并在输出再次可用时继续读取文件。当 Filebeat 运行时,每个输入的状态信息也会保留在内存中。当 Filebeat 重新启动时,注册表文件中的数据用于重建状态,并且 Filebeat 在最后一个已知位置继续每个采集器。
二、安装及配置
下载安装
Filebeat quick start: installation and configuration | Filebeat Reference 8.15 | Elastic
下载解压即可。
windows 下启动命令:
powershell
.\filebeat.exe
## 这个命令启动无任何输出,添加 -e 可输出相关日志配置
Configure Filebeat | Filebeat Reference 8.15 | Elastic
默认配置模版(仅保留部分)
yaml
###################### Filebeat Configuration Example #########################
# ============================== Filebeat inputs ===============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input-specific configurations.
# filestream is an input for collecting log messages from files.
- type: filestream
# Unique ID among all inputs, an ID is required.
id: my-filestream-id
# Change to true to enable this input configuration.
enabled: false
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
# Line filtering happens after the parsers pipeline. If you would like to filter lines
# before parsers, use include_message parser.
#exclude_lines: ['^DBG']
# Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
# Line filtering happens after the parsers pipeline. If you would like to filter lines
# before parsers, use include_message parser.
#include_lines: ['^ERR', '^WARN']
# Exclude files. A list of regular expressions to match. Filebeat drops the files that
# are matching any regular expression from the list. By default, no files are dropped.
#prospector.scanner.exclude_files: ['.gz$']
# Optional additional fields. These fields can be freely picked
# to add additional information to the crawled log files for filtering
#fields:
# level: debug
# review: 1
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
# ======================= Elasticsearch template setting =======================
setup.template.settings:
index.number_of_shards: 1
#index.codec: best_compression
#_source.enabled: false
# ================================== Outputs ===================================
# Configure what output to use when sending the data collected by the beat.
# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
# Performance preset - one of "balanced", "throughput", "scale",
# "latency", or "custom".
preset: balanced
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
# ------------------------------ Logstash Output -------------------------------
#output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
# ================================== Logging ===================================
# Sets log level. The default log level is info.
# Available log levels are: error, warning, info, debug
#logging.level: debug
# At debug level, you can selectively enable logging only for some components.
# To enable all selectors, use ["*"]. Examples of other selectors are "beat",
# "publisher", "service".
#logging.selectors: ["*"]inputs
指定 Filebeat 如何查找和处理输入数据。
- type :指定输入的类型,支持以下类型(仅列举常见部分):
- id :此输入的唯一标识符。每个 filestream 输入都必须具有唯一的 ID。注意:更改输入 ID 可能会导致数据重复,因为文件的状态将丢失,并且将再次从头开始读取它们。
- paths:必选项,读取文件的路径,基于glob匹配语法。
- enabled:是否启用该模块。
- exclude_lines:排除匹配列表中的正则表达式。
- include_lines:包含匹配列表中的正则表达式。
- exclude_files:排除的文件,匹配正则表达式的列表。
- fields:可选的附加字段。这些字段可以自由选择,添加附加信息到抓取的日志文件进行过滤。
outputs
可以通过在 <font style="color:rgb(85, 85, 85);background-color:rgb(248, 248, 248);">filebeat.yml</font> 配置文件的 Outputs 部分中设置选项,将 Filebeat 配置为写入特定输出。只能定义单个输出。
三、 模块 modules
Filebeat 的模块(Modules)主要是为了简化了常见日志格式的收集、解析和可视化而生。
每个模块都包含一组预定义的配置文件,这些配置文件定义了如何收集特定类型的数据。使用模块可以让 Filebeat 更加易于配置和管理,特别是在处理多种不同类型的数据源时。
主要作用
- 简化配置:每个模块都有预定义的配置模板,包含了采集数据所需的默认配置项,使得用户不需要手动编写复杂的配置文件。
- 自动化采集 :模块可以自动检测并采集特定类型的日志文件。例如,
<font style="color:rgb(44, 44, 54);">system</font>模块可以自动采集操作系统日志,<font style="color:rgb(44, 44, 54);">nginx</font>模块可以自动采集 Nginx 的访问日志。 - 预处理和格式化数据:模块包含了预定义的处理器(processors),这些处理器可以对采集到的数据进行格式化和标准化。
- 集成和索引模板:模块可以与 Elasticsearch 配合使用,自动创建索引模板。索引模板定义了如何存储和索引数据,确保数据的一致性和可查询性。
- 监控和健康检查:一些模块还包含了监控和健康检查功能,可以定期检查数据源的状态,并报告任何问题。
内置模块
windows 可以使用以下命令查看已经启用和禁用的模块:
powershell
PS D:\program\filebeat-8.15.3-windows-x86_64> .\filebeat.exe modules list
Enabled:
Disabled:
activemq
apache
auditd
aws
awsfargate
azure
cef
checkpoint
cisco
coredns
crowdstrike
cyberarkpas
elasticsearch
envoyproxy
fortinet
gcp
google_workspace
haproxy
ibmmq
icinga
iis
iptables
juniper
kafka
kibana
logstash
microsoft
misp
mongodb
mssql
mysql
mysqlenterprise
nats
netflow
nginx
o365
okta
oracle
osquery
panw
pensando
postgresql
rabbitmq
redis
salesforce
santa
snyk
sophos
suricata
system
threatintel
traefik
zeek
zookeeper
zoom启用模块
执行以下命令即可启用特定模块:
powershell
PS D:\program\filebeat-8.15.3-windows-x86_64> .\filebeat.exe modules enable mysql
Enabled mysql启用后需要在 modules.d 目录中修改启用的模块的配置文件,具体配置需要根据具体模块文档来处理,如以下 mysql 模块的配置文件:
yaml
- module: mysql
error:
enabled: true
var.paths: ["C:/ProgramData/MySQL/MySQL Server 8.0/Data/PC202105231223.err*"]
slowlog:
enabled: true
var.paths: ["C:/ProgramData/MySQL/MySQL Server 8.0/Data/PC202105231223-slow.log*"]四、使用实例
文件输入,控制台输出
yaml
# 输入
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- D:\logdemo\*.log
# 输出
output.console:
pretty: true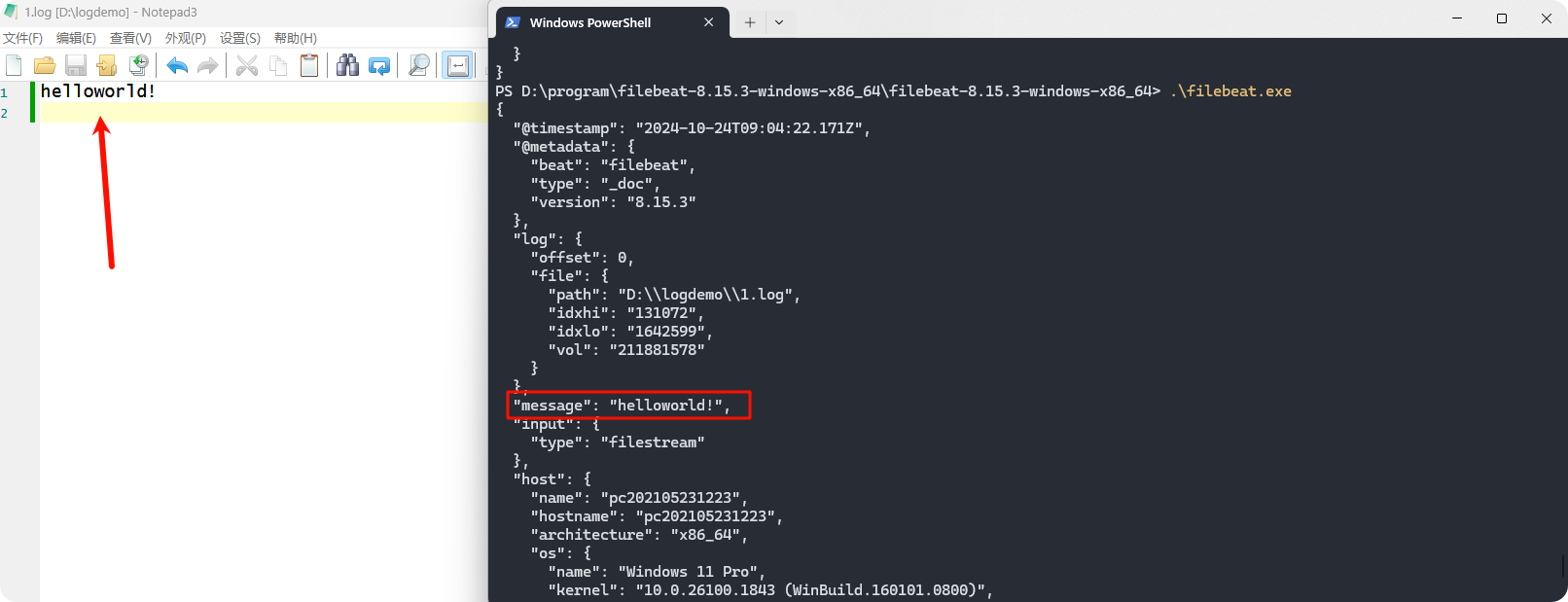
TCP 输入,控制台输出
yaml
filebeat.inputs:
- type: tcp
id: my-filestream-id
enabled: true
host: "localhost:9000"
fields:
aTestField: this is a test!!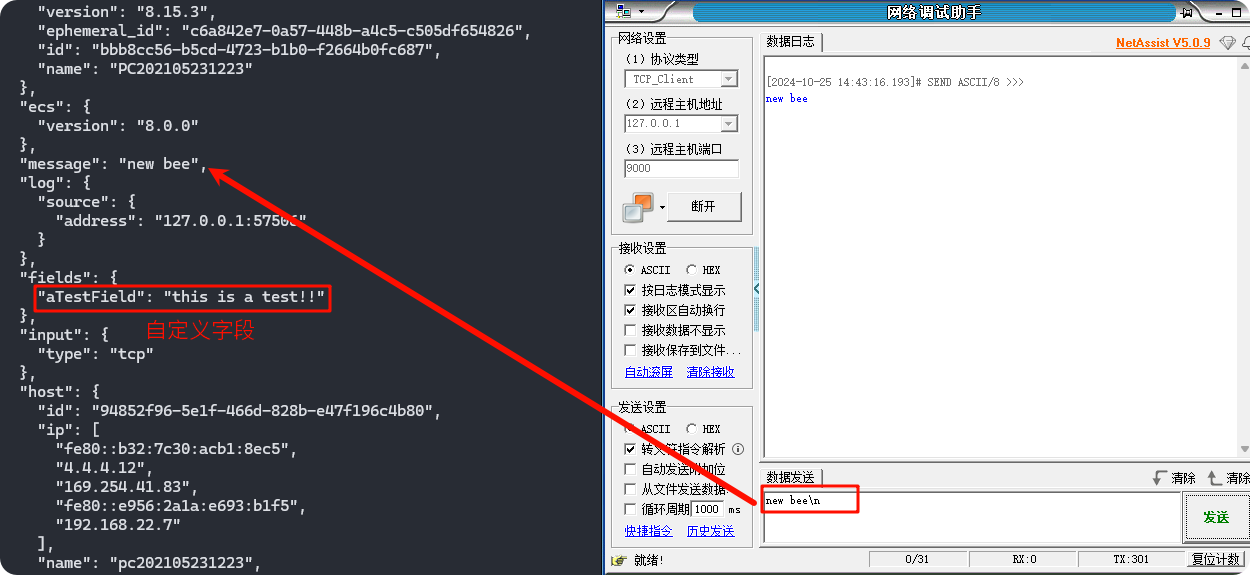
默认使用 \n 作为 line_delimiter(行分隔符),可自行修改 :
yaml
filebeat.inputs:
- type: tcp
id: my-filestream-id
enabled: true
host: "localhost:9000"
fields:
aTestField: this is a test!!
line_delimiter: '&'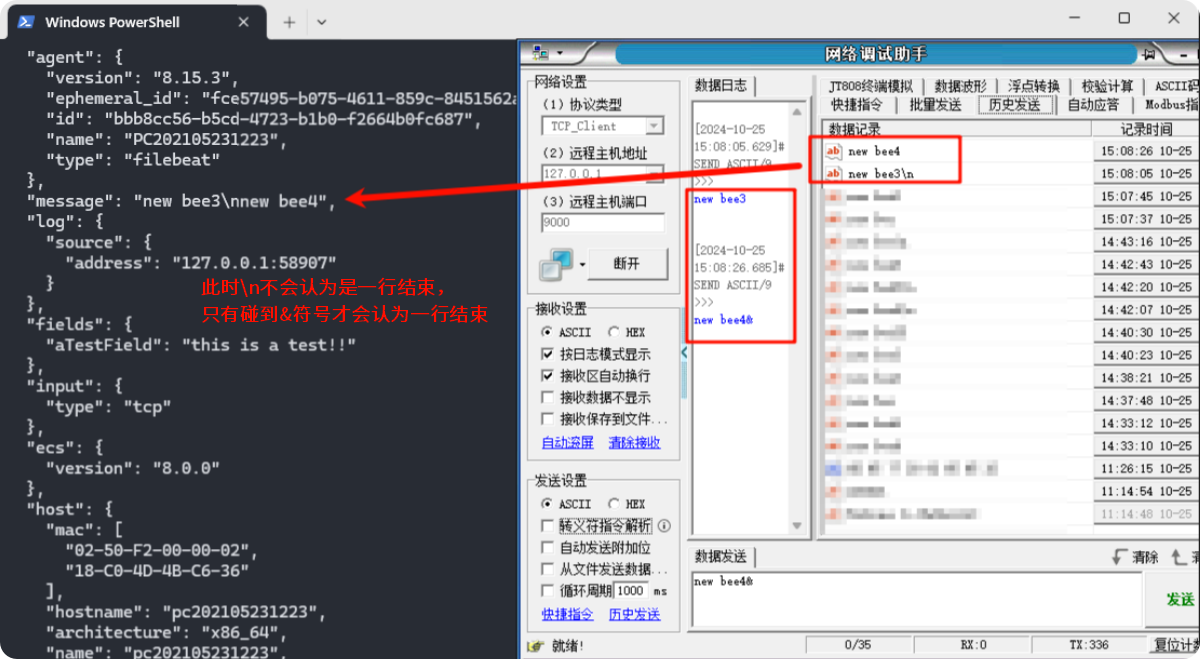
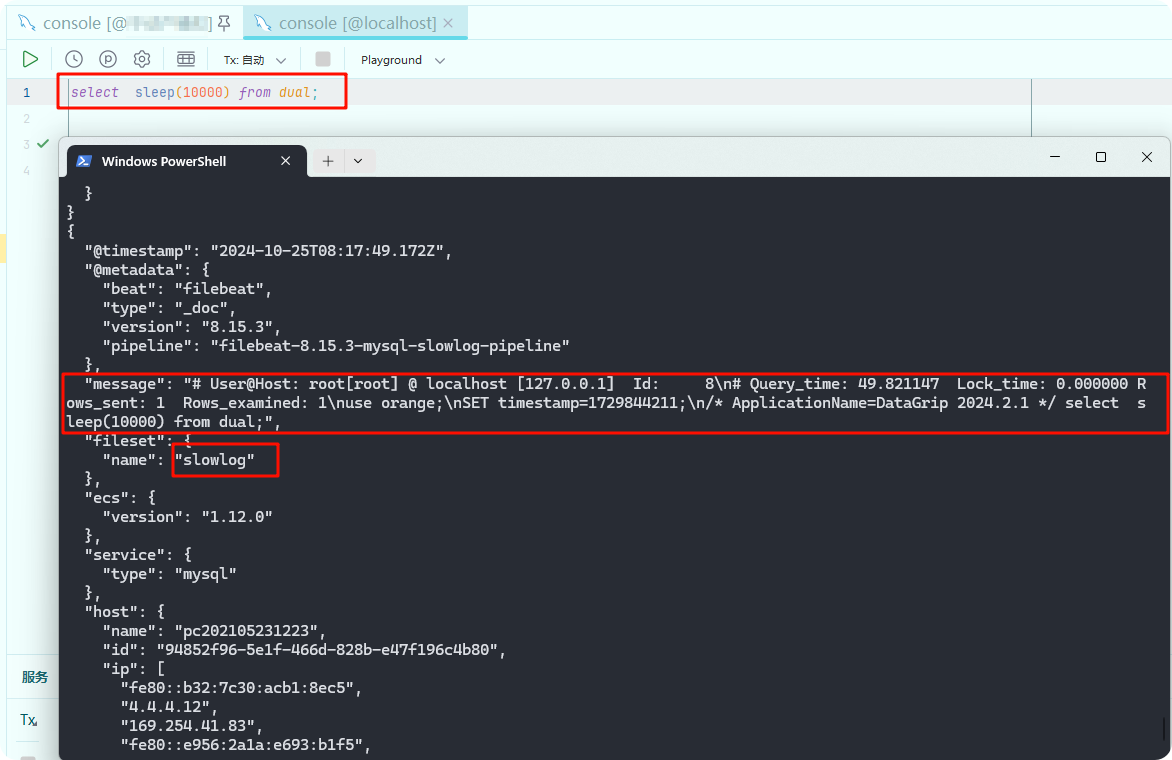
使用 mysql 模块采集慢日志,控制台输出
配置方式参见 [三、modules 3启用模块](#三、modules 3启用模块)