文章目录
- AI大模型开发工程师
-
- [001 AI 大模型应用开发基础](#001 AI 大模型应用开发基础)
-
- [1 AI 大模型应用开发基础准备](#1 AI 大模型应用开发基础准备)
- [2 大白话解释 AI 大模型原理](#2 大白话解释 AI 大模型原理)
- [3 手推Transformer网络架构](#3 手推Transformer网络架构)
-
- [Transformer 网络架构](#Transformer 网络架构)
- 独热编码(one-hot编码)
- word2vec
- ELMo模型
- [Multi-head Self Attention](#Multi-head Self Attention)
- [4 Transformer 网络架构源码剖析](#4 Transformer 网络架构源码剖析)
-
- [从代码层面理解 Transformer](#从代码层面理解 Transformer)
- [输入向量化 Input Embedding](#输入向量化 Input Embedding)
- [位置编码 Positional Encoding](#位置编码 Positional Encoding)
- [多头自注意力机制 Multi-Head Attention](#多头自注意力机制 Multi-Head Attention)
- [防退化&标准化 Add&Norm](#防退化&标准化 Add&Norm)
- [前馈网络 Feed Forward](#前馈网络 Feed Forward)
- 编码器
- 解码器
- 输出概率
- [整体 Transformer](#整体 Transformer)
- [5 OpenAI GPT 不同版本对比](#5 OpenAI GPT 不同版本对比)
AI大模型开发工程师
001 AI 大模型应用开发基础
1 AI 大模型应用开发基础准备
网络环境
- 需要科学上网
- OpenAI账户
开发环境
- 语言:Python3(建议Python3.10及以上)
- 开发工具:Pycharm,Visual Studio Code都行,喜欢什么用什么就行
- 课程演示:Jypter Notebook
资源准备

如何租赁云服务器?
- 云平台地址:https://www.autodl.com/

2 大白话解释 AI 大模型原理
成语接龙和暴力穷举

大模型如何理解人类语言
- 计算机底层:二进制
- 将 现实问题 转化为 数学问题

如何存储数据?
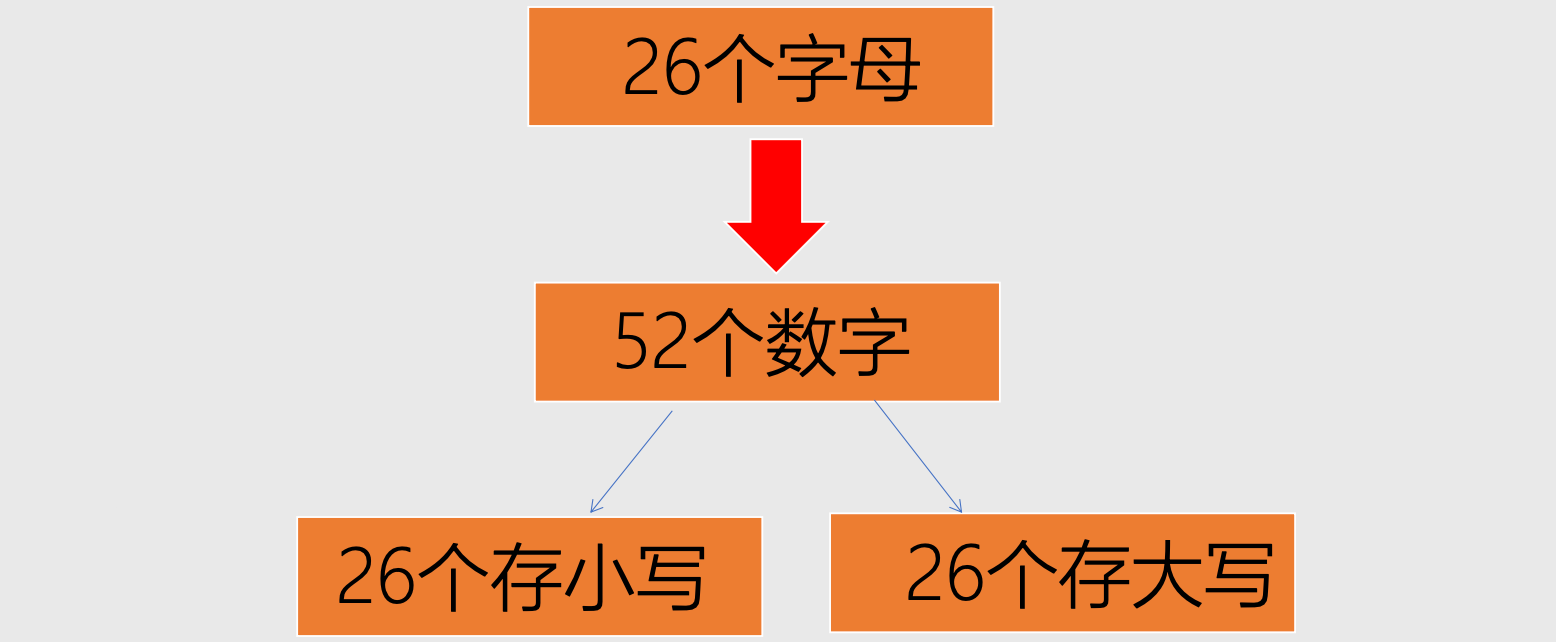
如何存储图像?
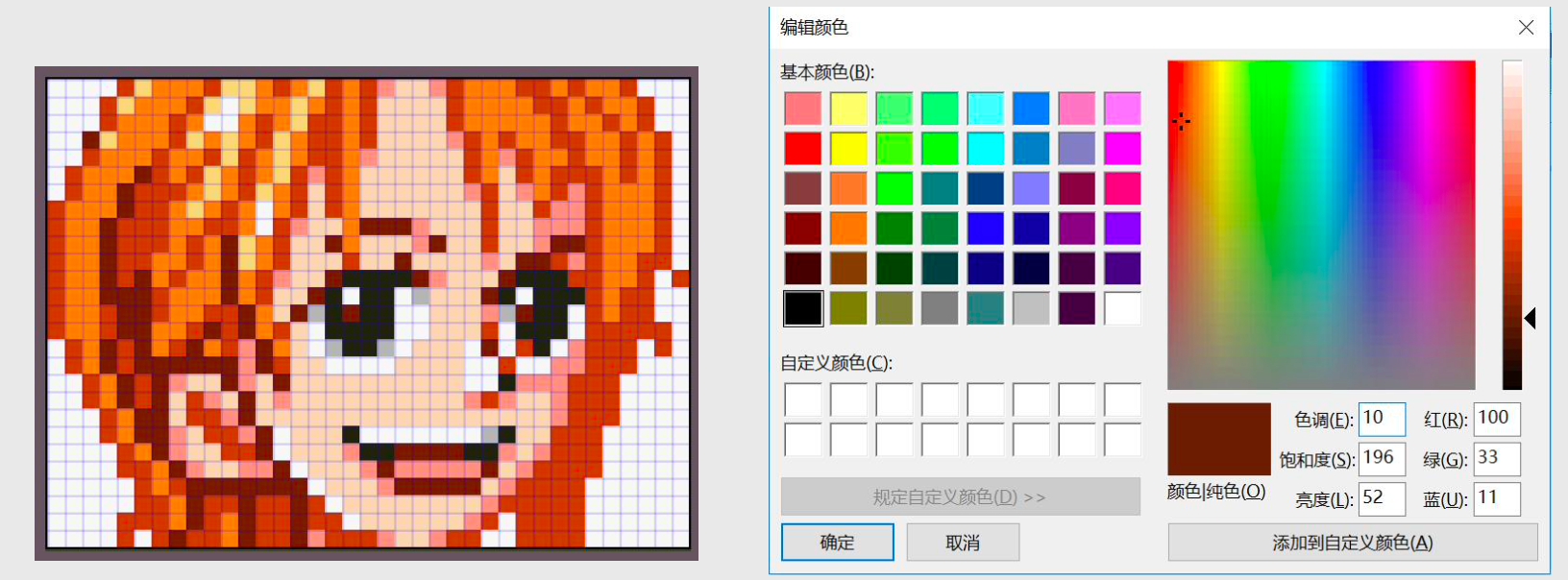
如何让电脑知道存的是什么?

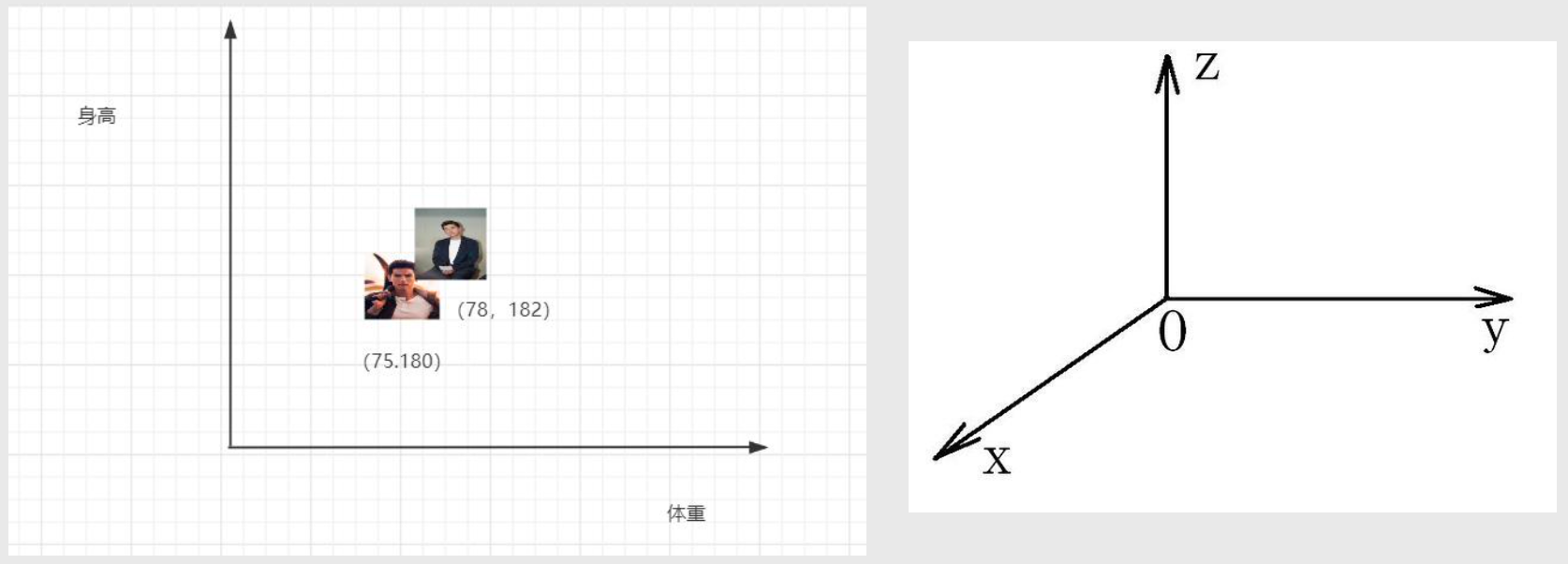
向量化
- 将 东西 与 数字组合,比如 0, 180, 75, 35 分别表示 性别, 身高, 体重, 年龄
- 更多维度:
- 【性别,年龄,身高,体重,胸围,肤色,腰围,体脂率,爱好,语言,城市,收入等】
- 【0,22,170,170,170,11,22,33,65, 345,67,8888】
为什么需要向量化?
- 方便电脑处理
- 寻找规律
- 每个字都是用数字代替
- 床【0,11,2,33,44,54,66,75,89,12】
- 大【0,11,2.234,...】
- 美【0,11,2.222,...】
- 向量可以计算
- 相加、相减、相乘
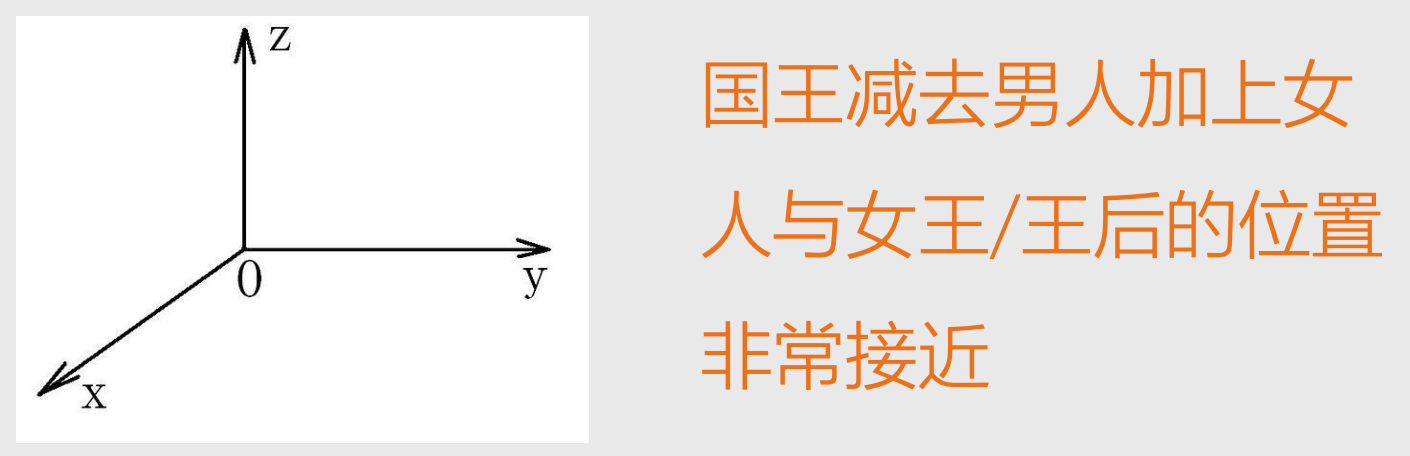
出现了难题
- 坐标要多少维度?
- 每个维度代表什么?
调整位置
- 通过计算距离,不断调整位置

科学的方式
Word2vec算法

信息压缩与特征提取

问题

谷歌论文-自注意力机制
- 解决了自然语言特征提取的问题

- 解决问题的思路

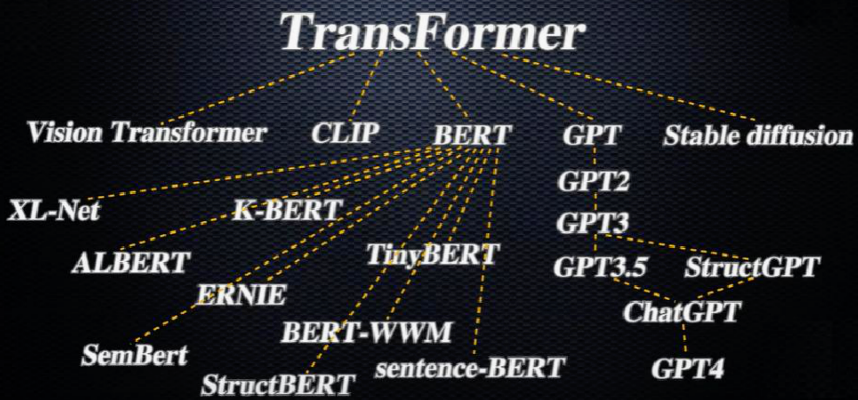
TransFormer算法演进

通用人工智能模型
- 在此之前,都是一些细分领域:围棋、玩游戏、图像识别、设计模型、标注数据等

- 而通用人工智能,是利用自然语言,理解整个文明成果的能力,和人类无缝交流的能力
发展分支
- 涌现智能

百模大战

3 手推Transformer网络架构
Transformer 网络架构
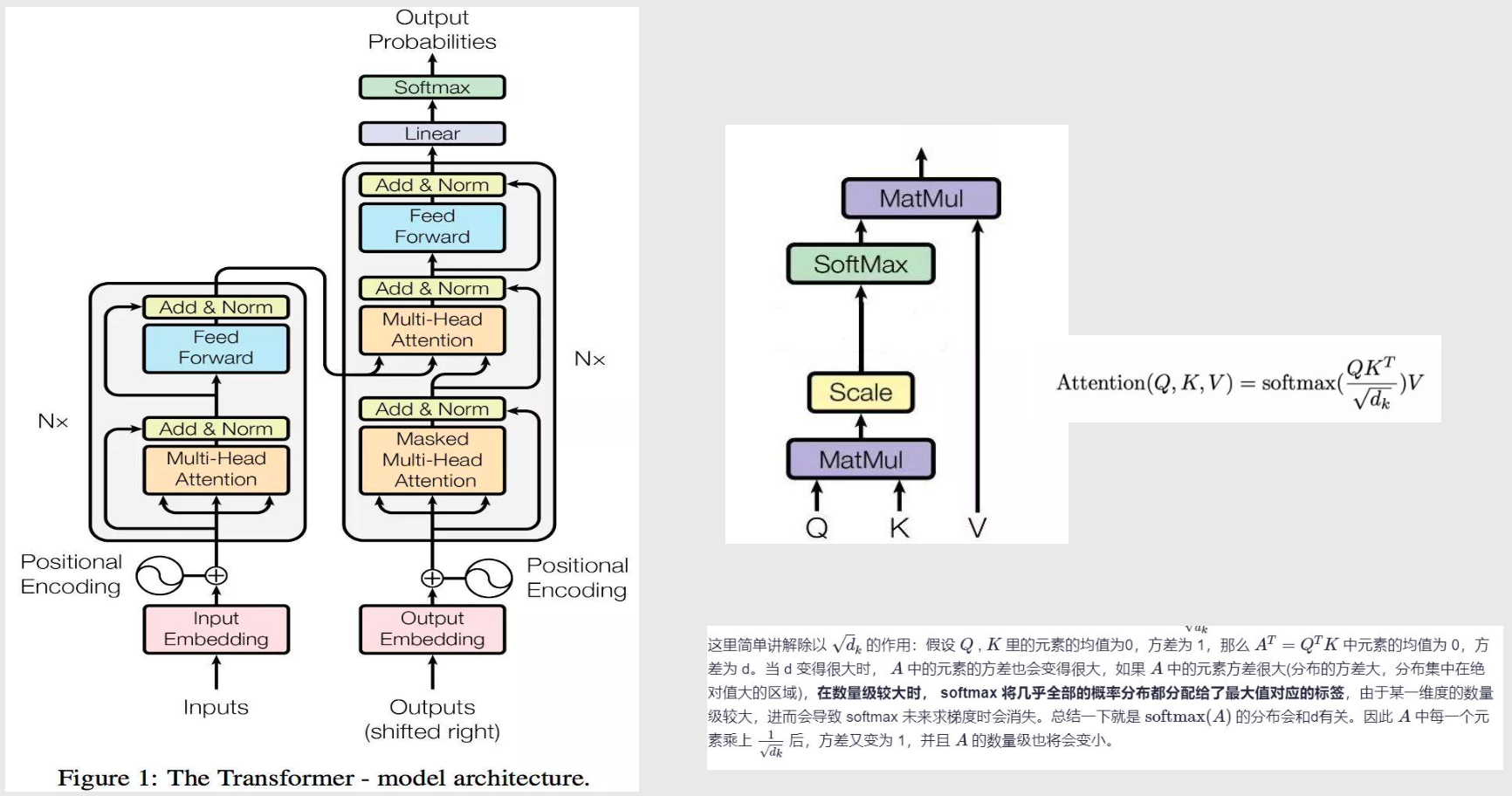
- Add:防止梯度退化
- Norm:归一化
- Feed Forward:全链接前馈网络
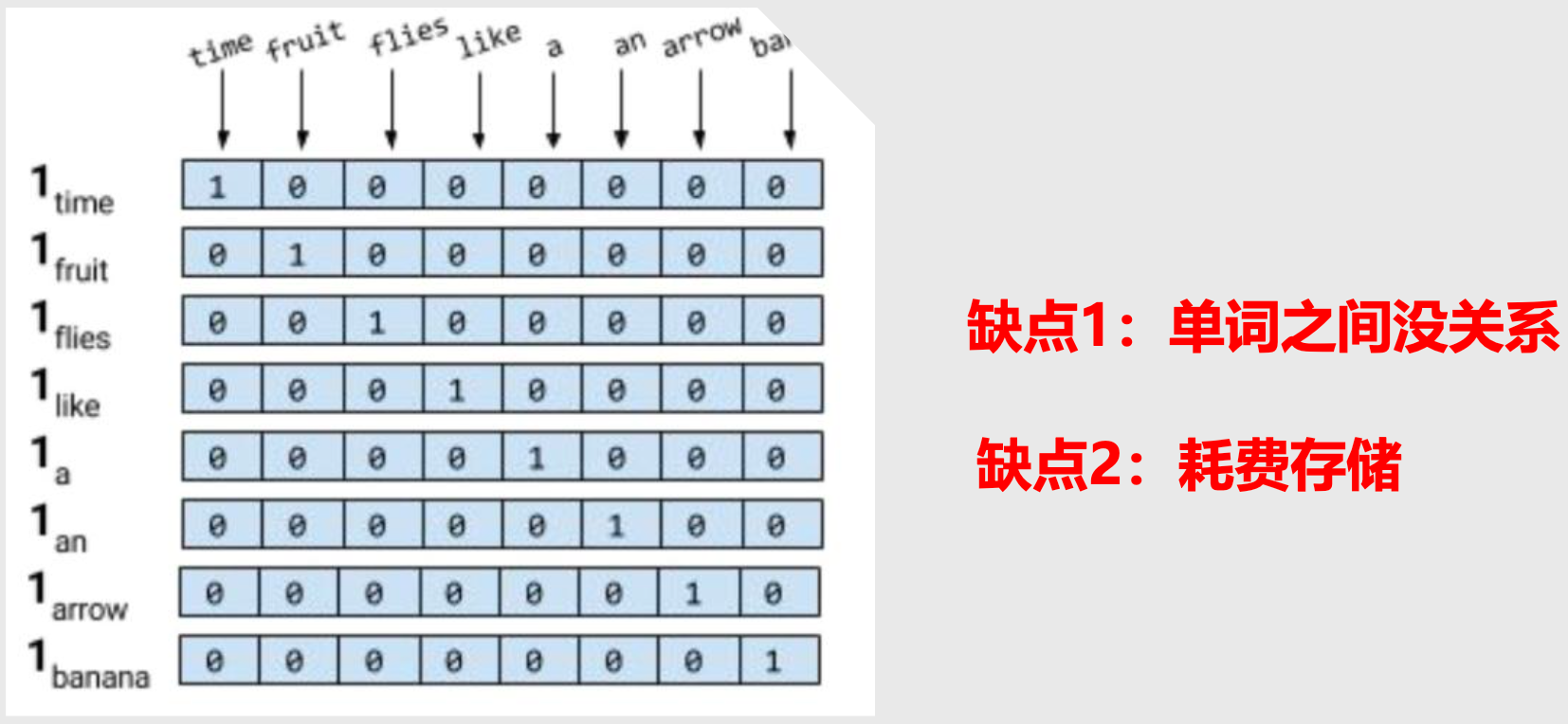
独热编码(one-hot编码)
word2vec
- Q 矩阵,对于任何一个独热编码的词向量都可以通过 Q 矩阵得到新的词向量

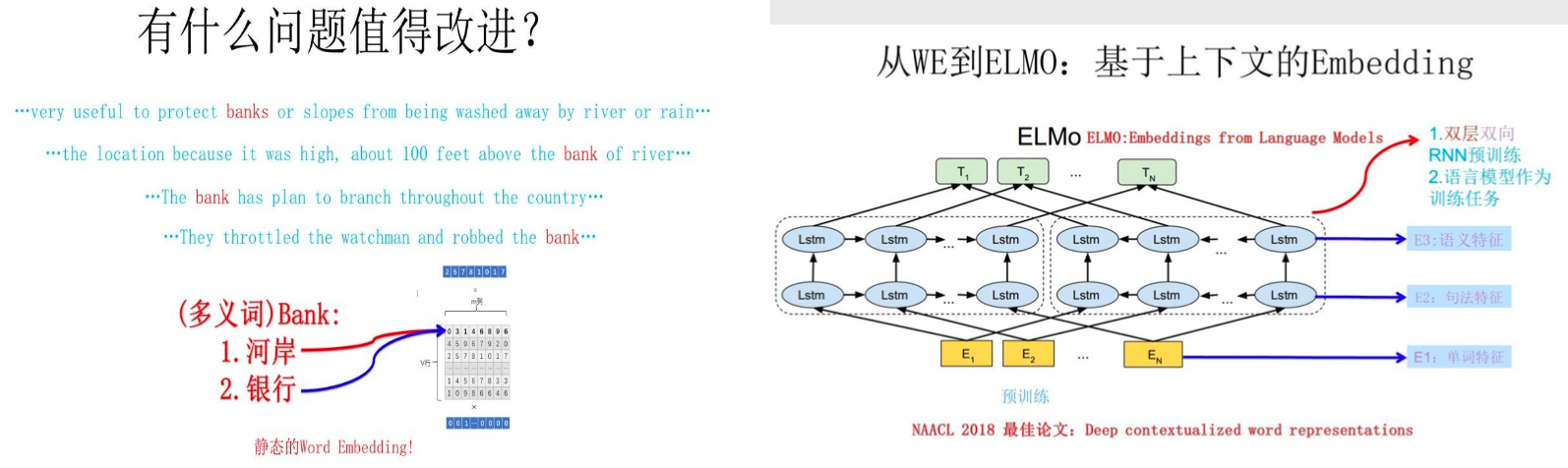
缺点:多义词
ELMo模型
Multi-head Self Attention
4 Transformer 网络架构源码剖析
从代码层面理解 Transformer
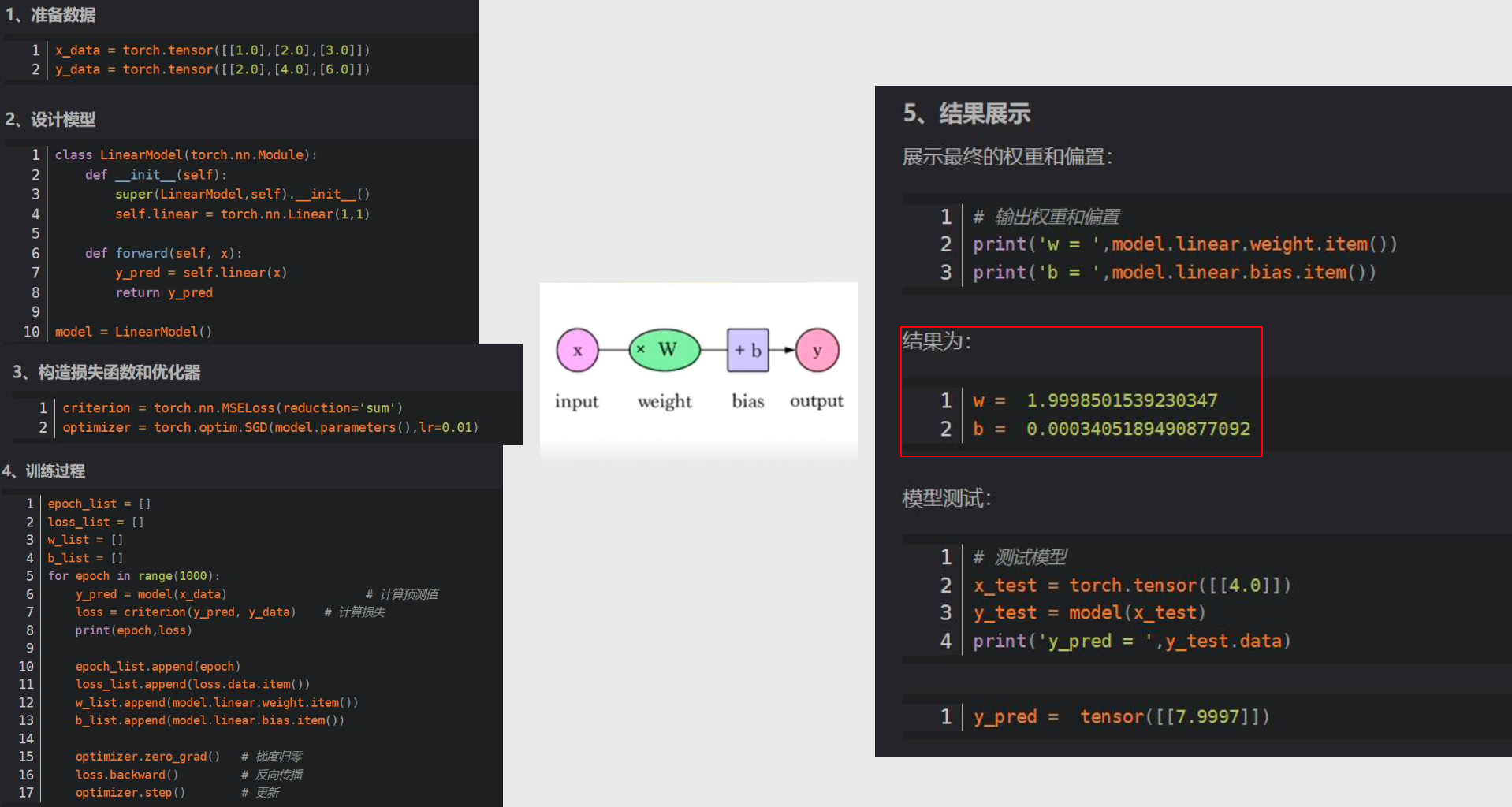
- 举一个简单的案例
用到的技术:Python、Pytorch(用于开发机器学习和深度学习的框架)
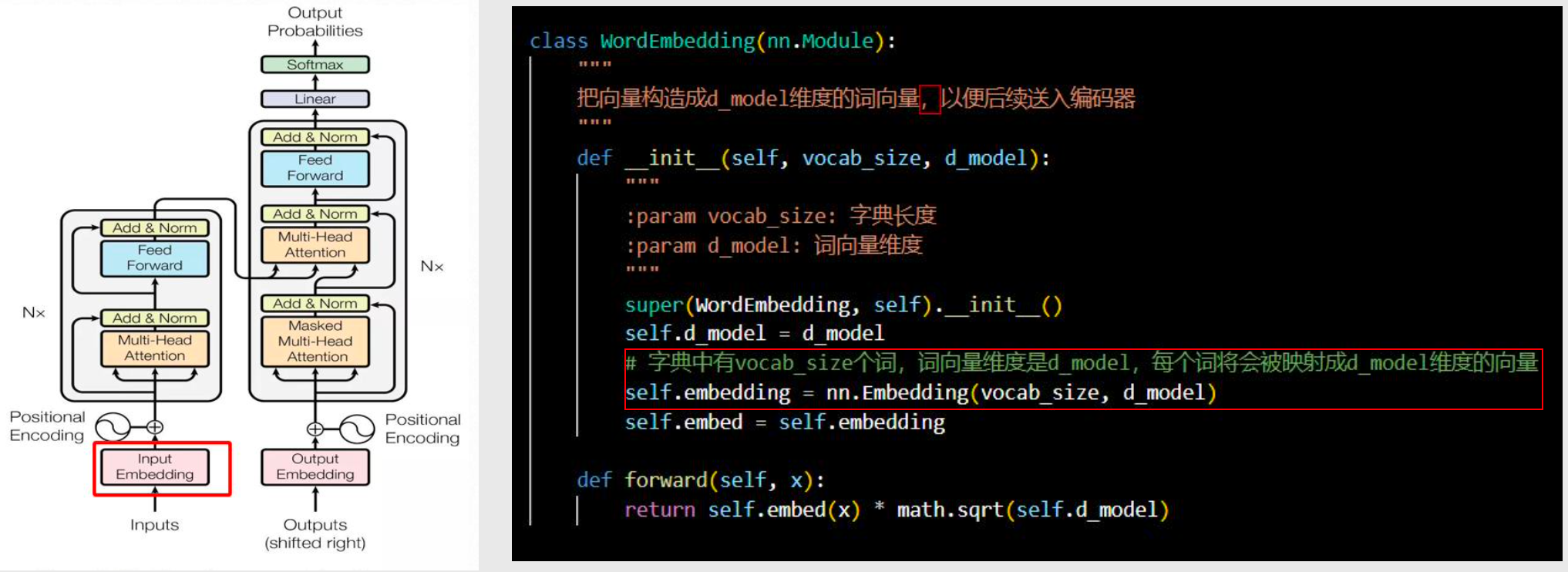
输入向量化 Input Embedding
位置编码 Positional Encoding
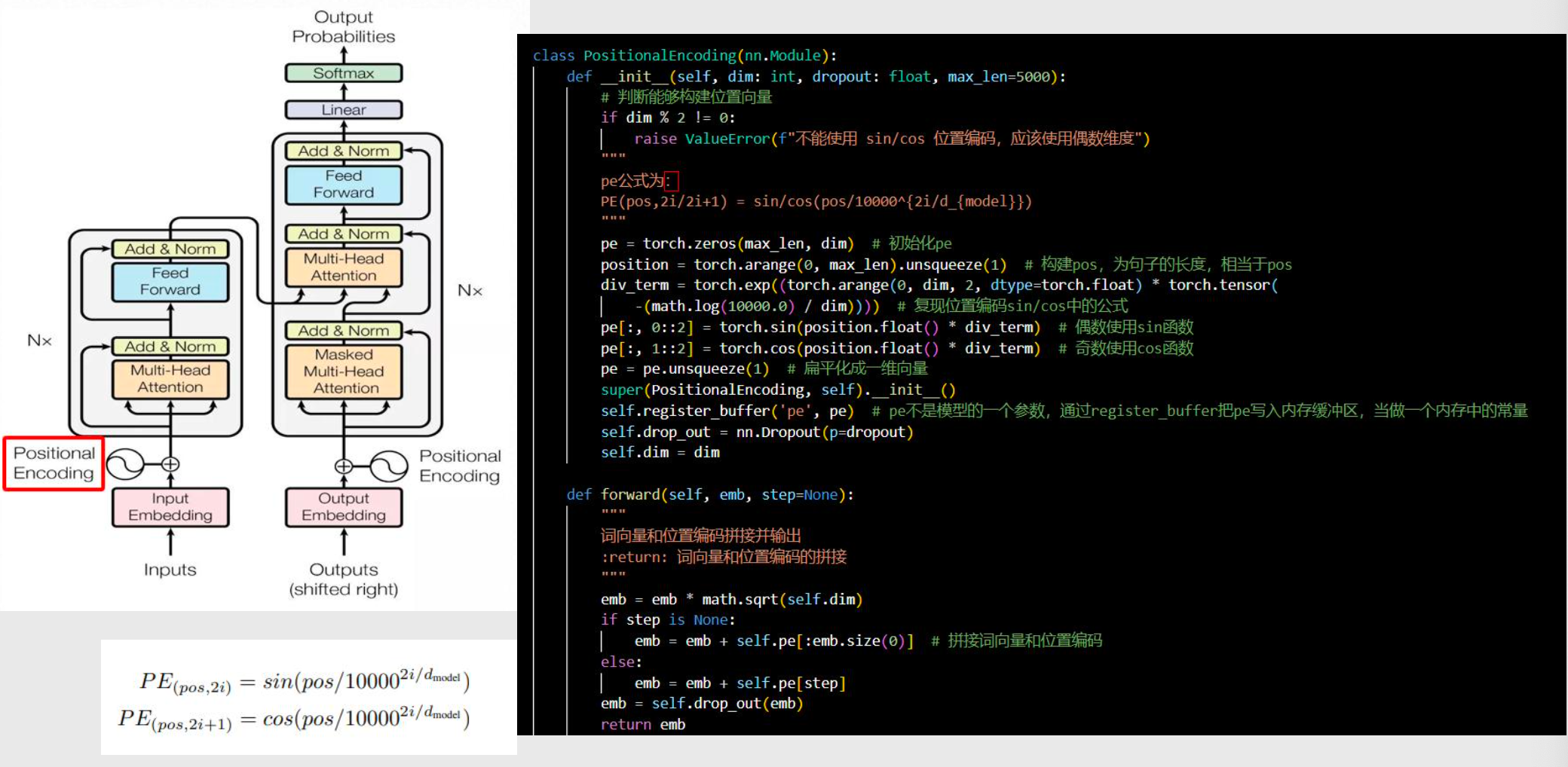
多头自注意力机制 Multi-Head Attention
- 自注意力实现
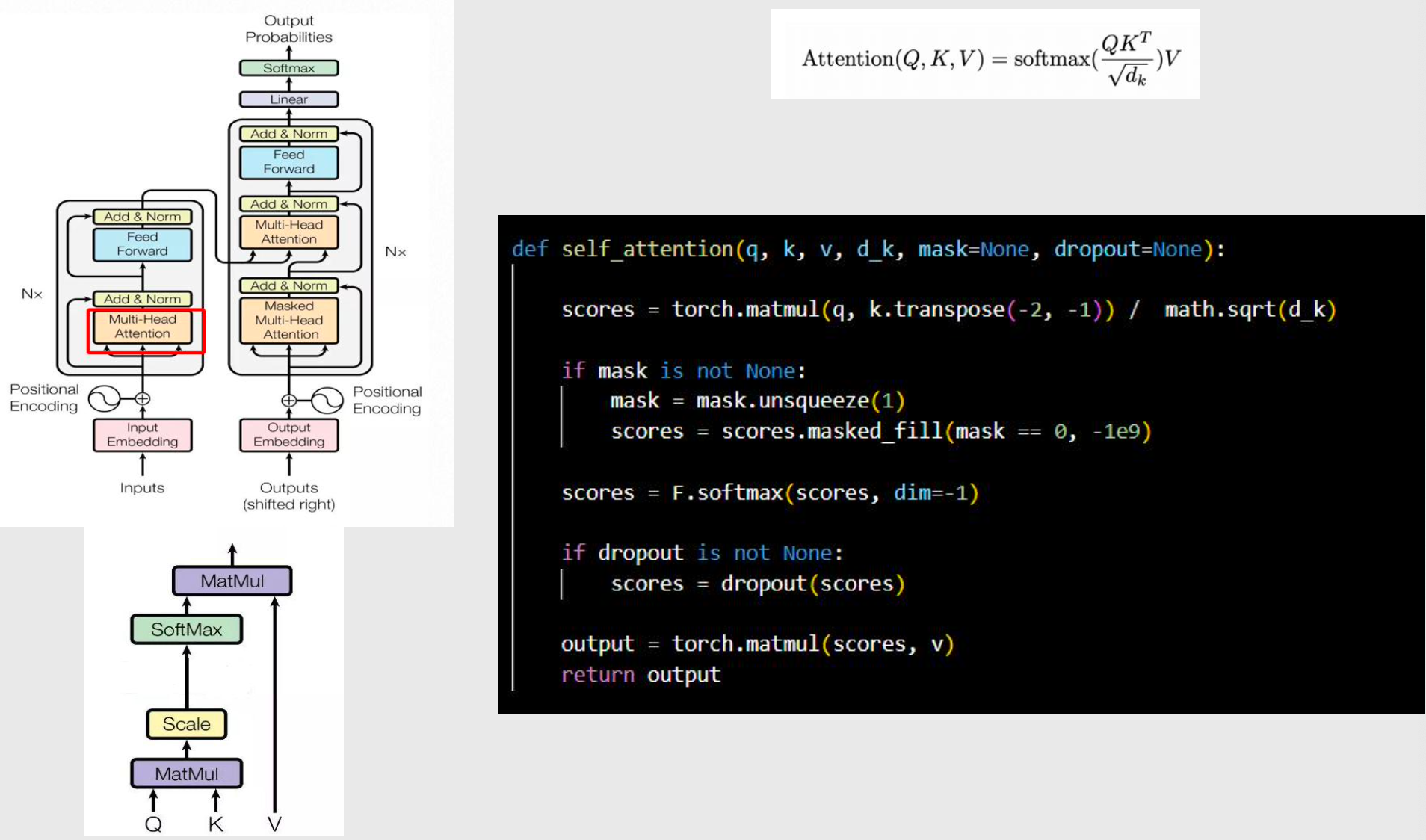
mask:是否做掩码
dropout:为了防止过拟合
- 多头注意力实现

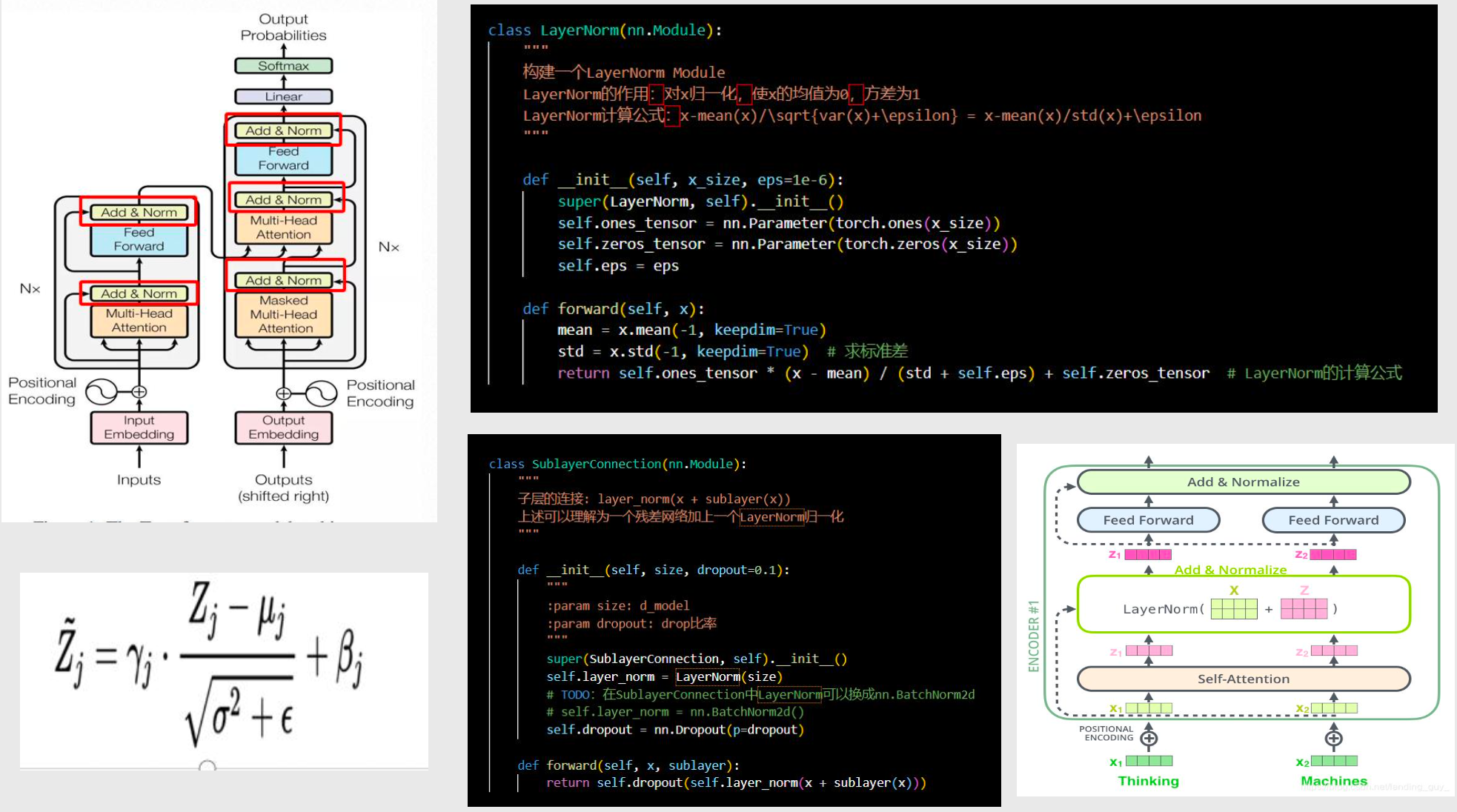
防退化&标准化 Add&Norm
前馈网络 Feed Forward
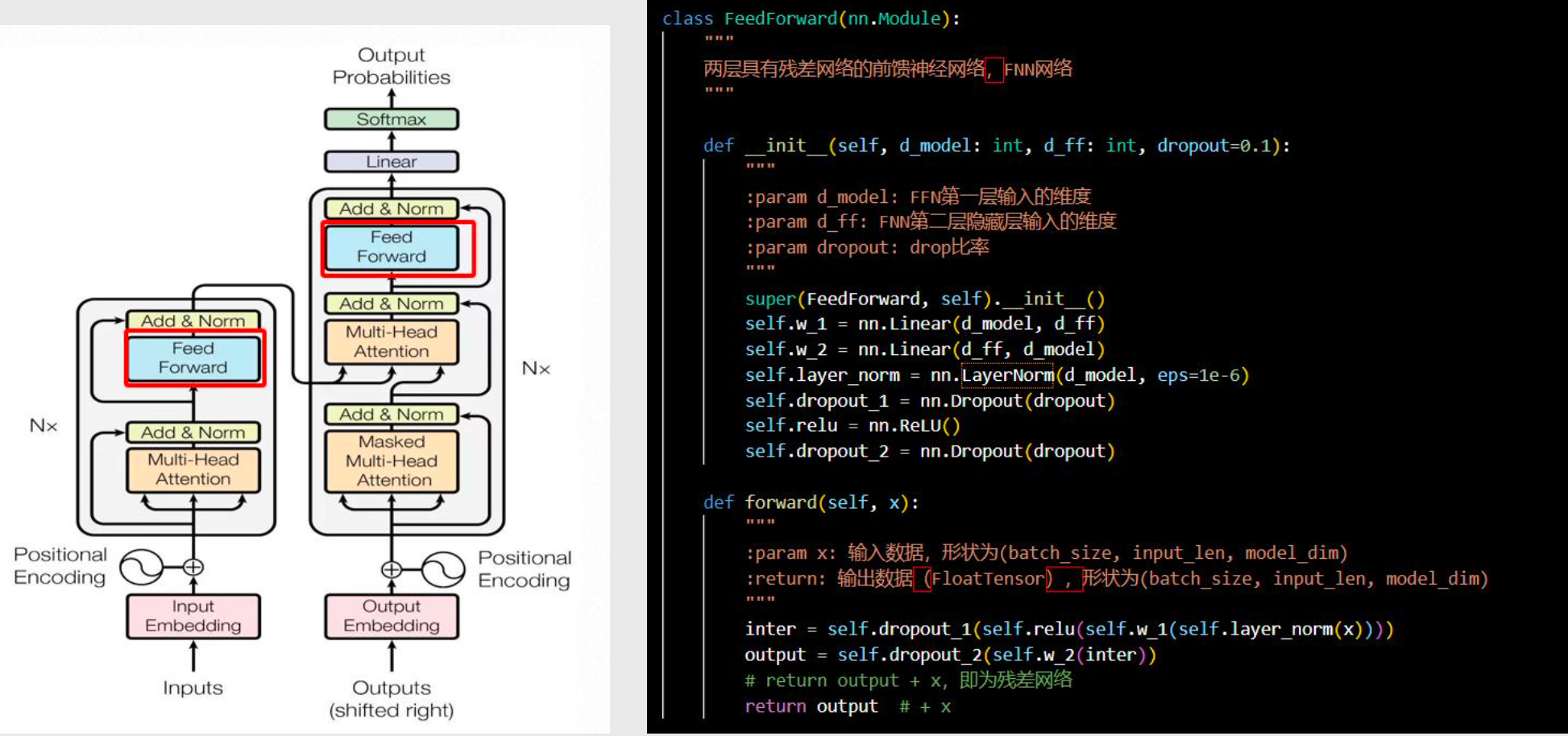
relu:激活函数
编码器
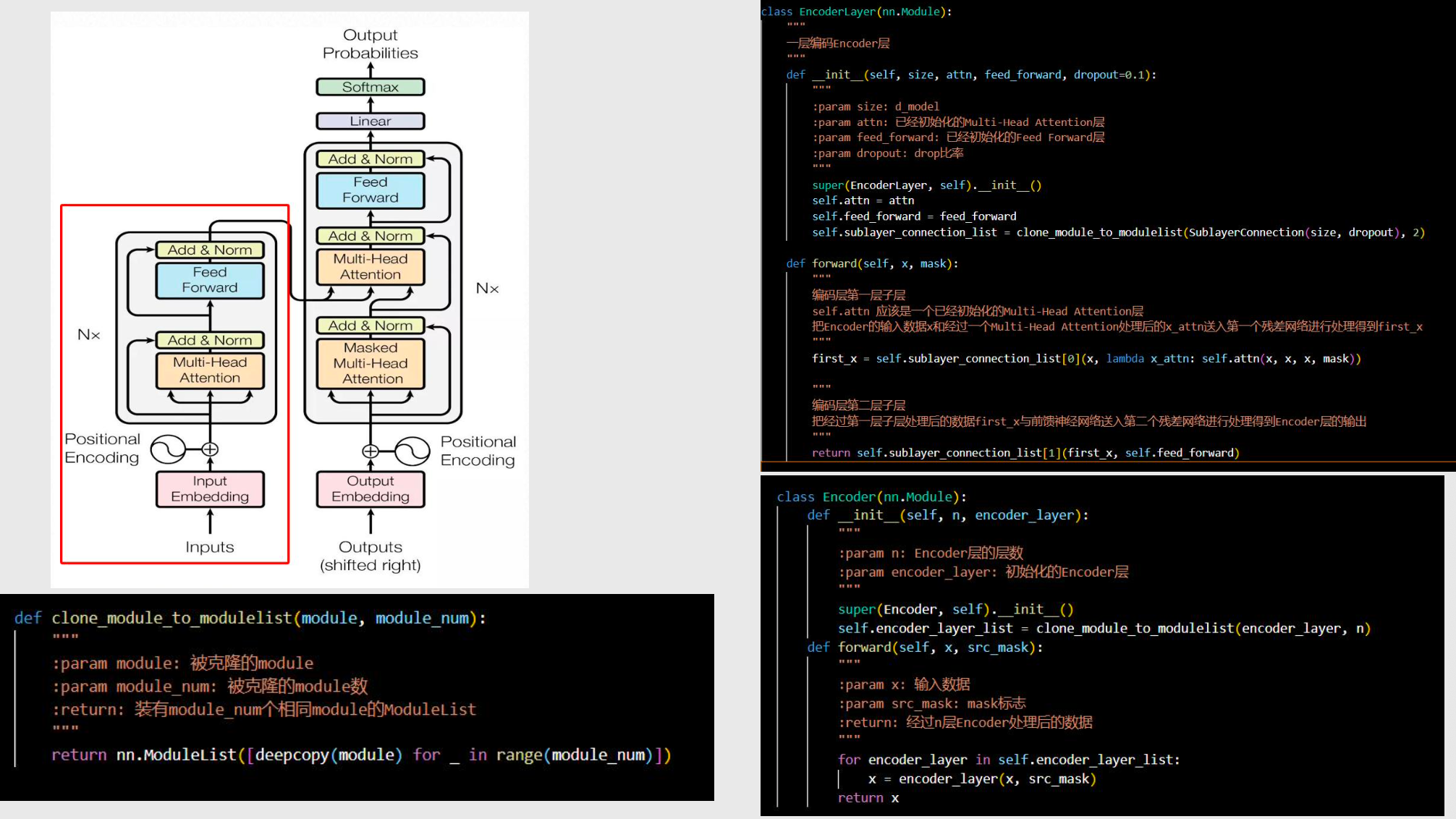
clone_module_to_modulelist:克隆出多层
self.attn:自注意力
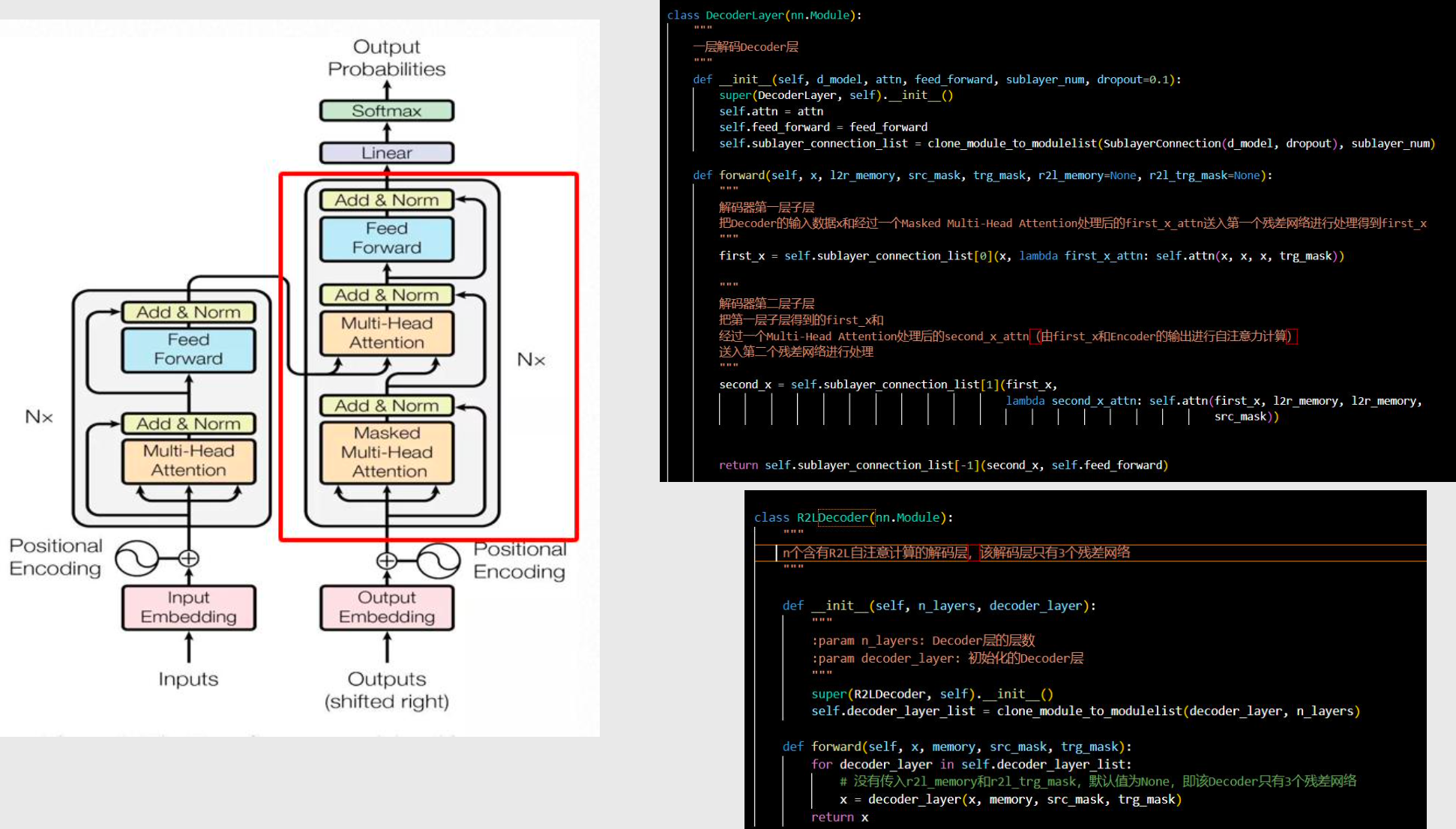
解码器
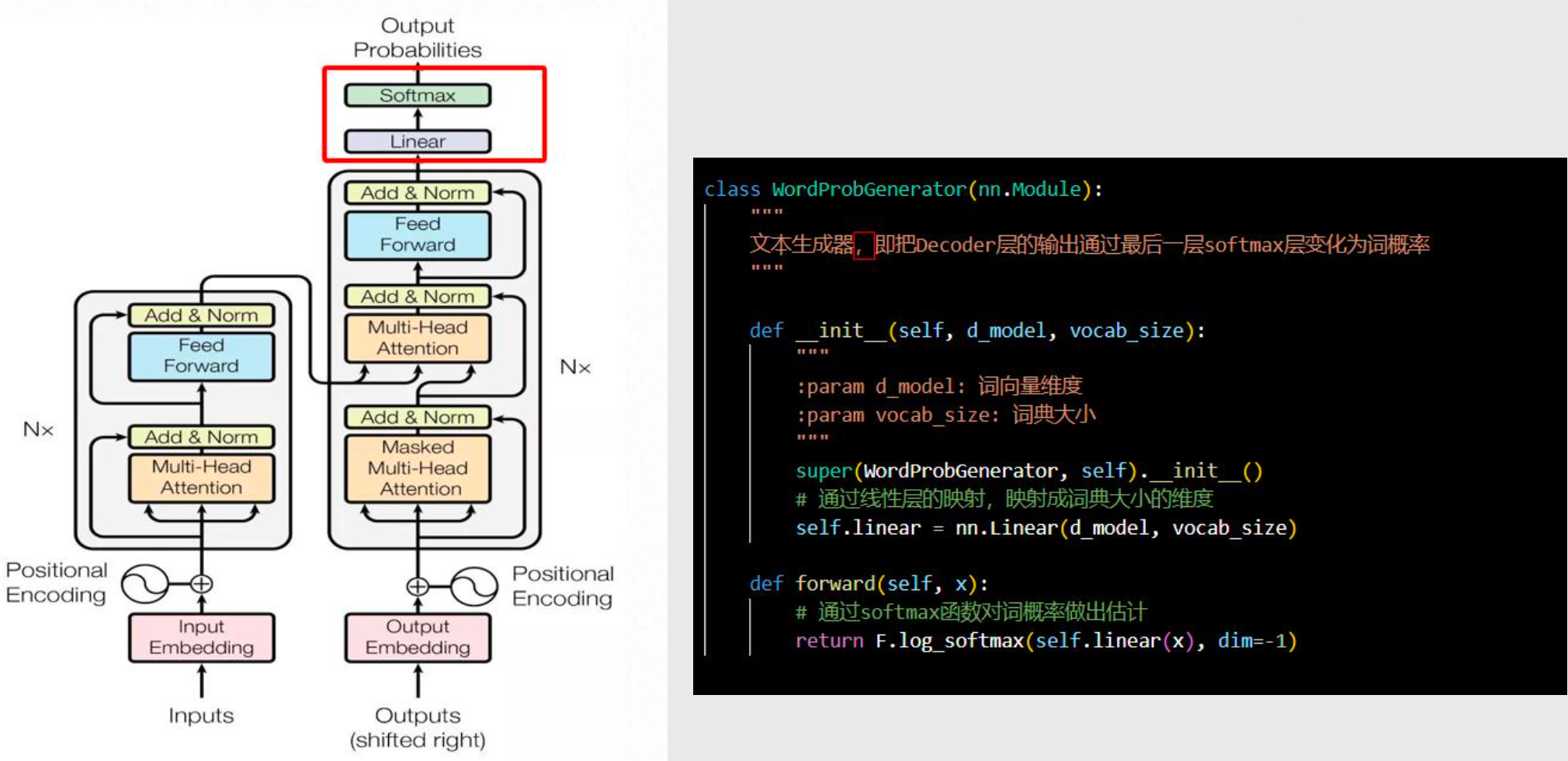
输出概率
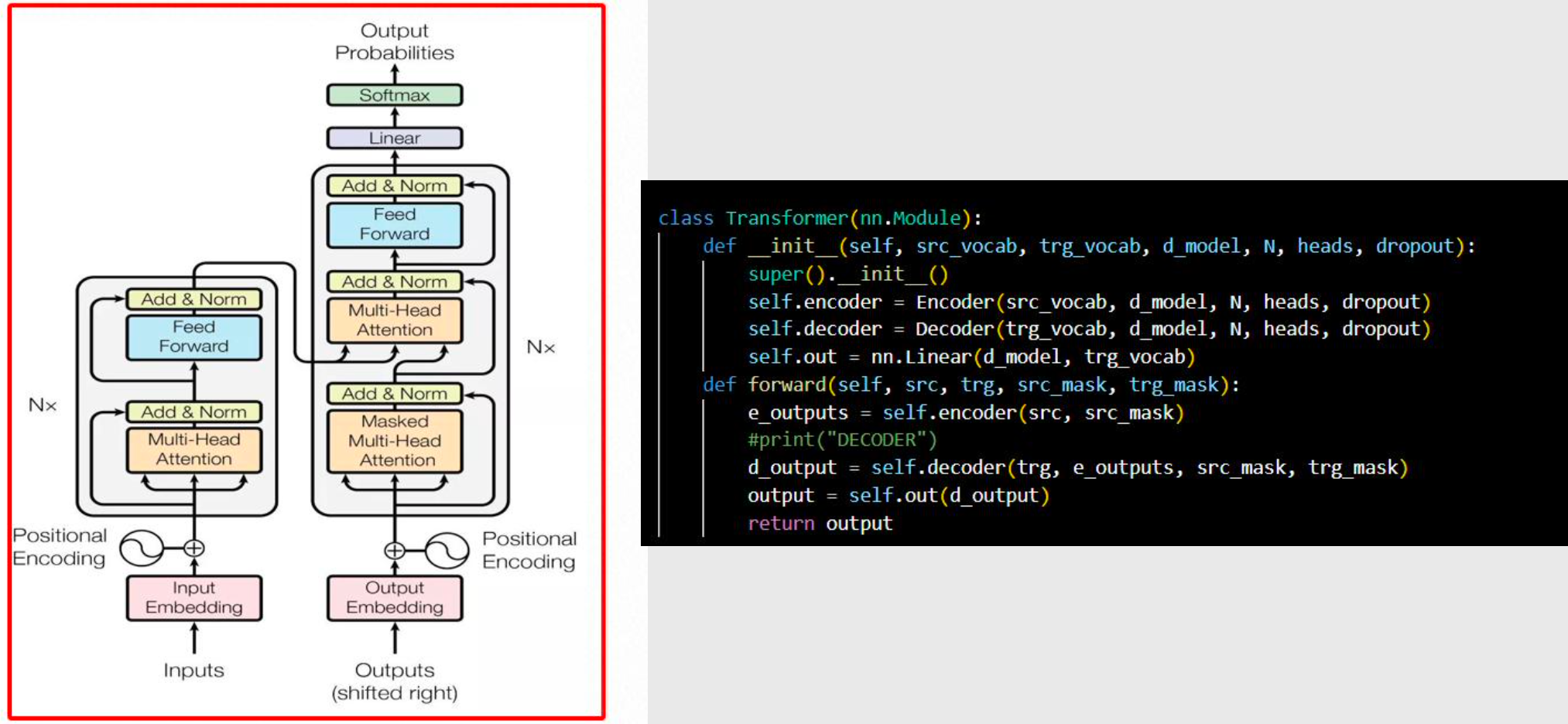
整体 Transformer
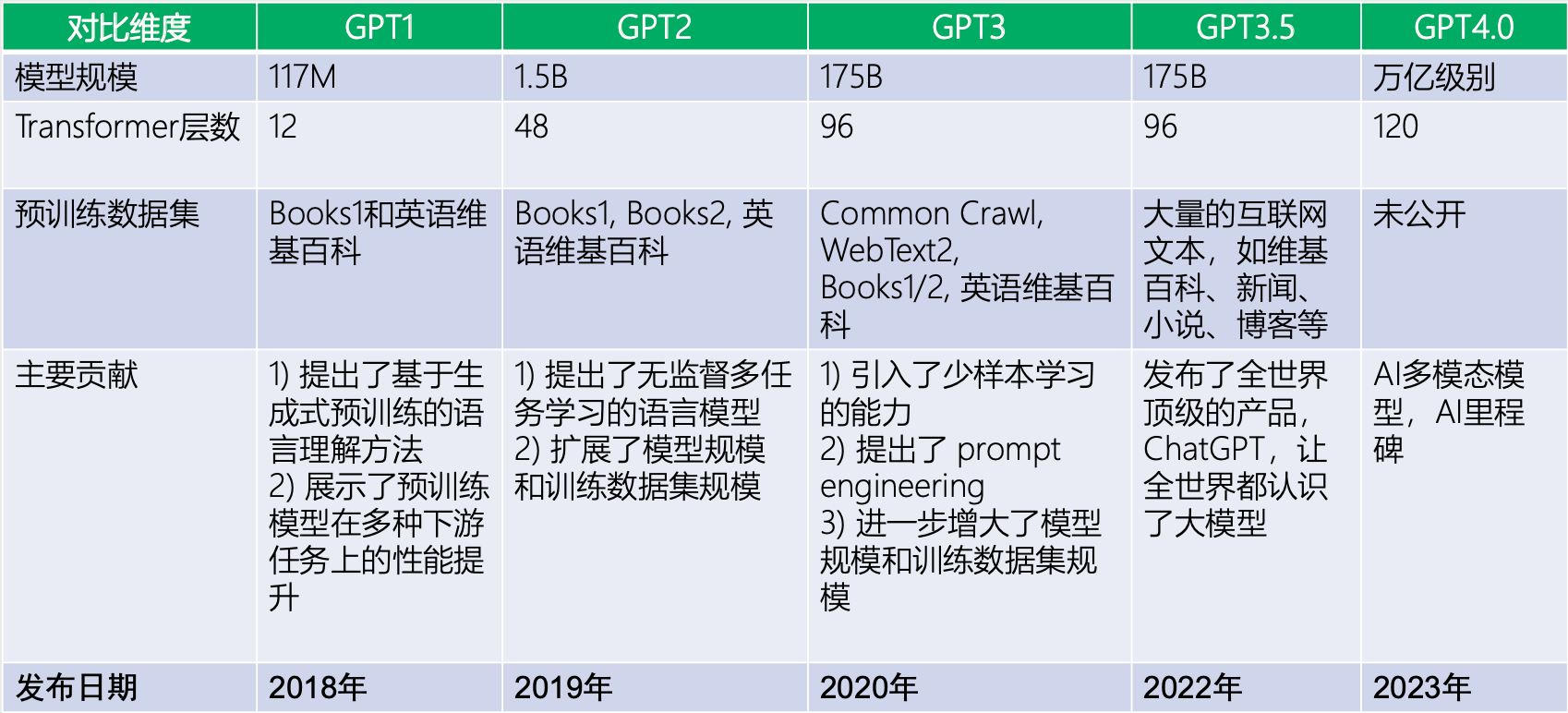
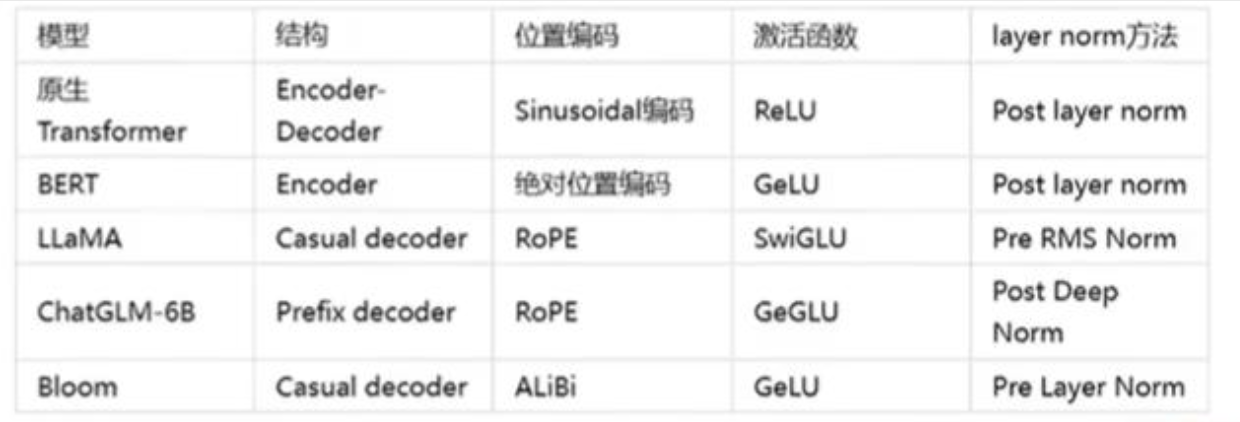
5 OpenAI GPT 不同版本对比
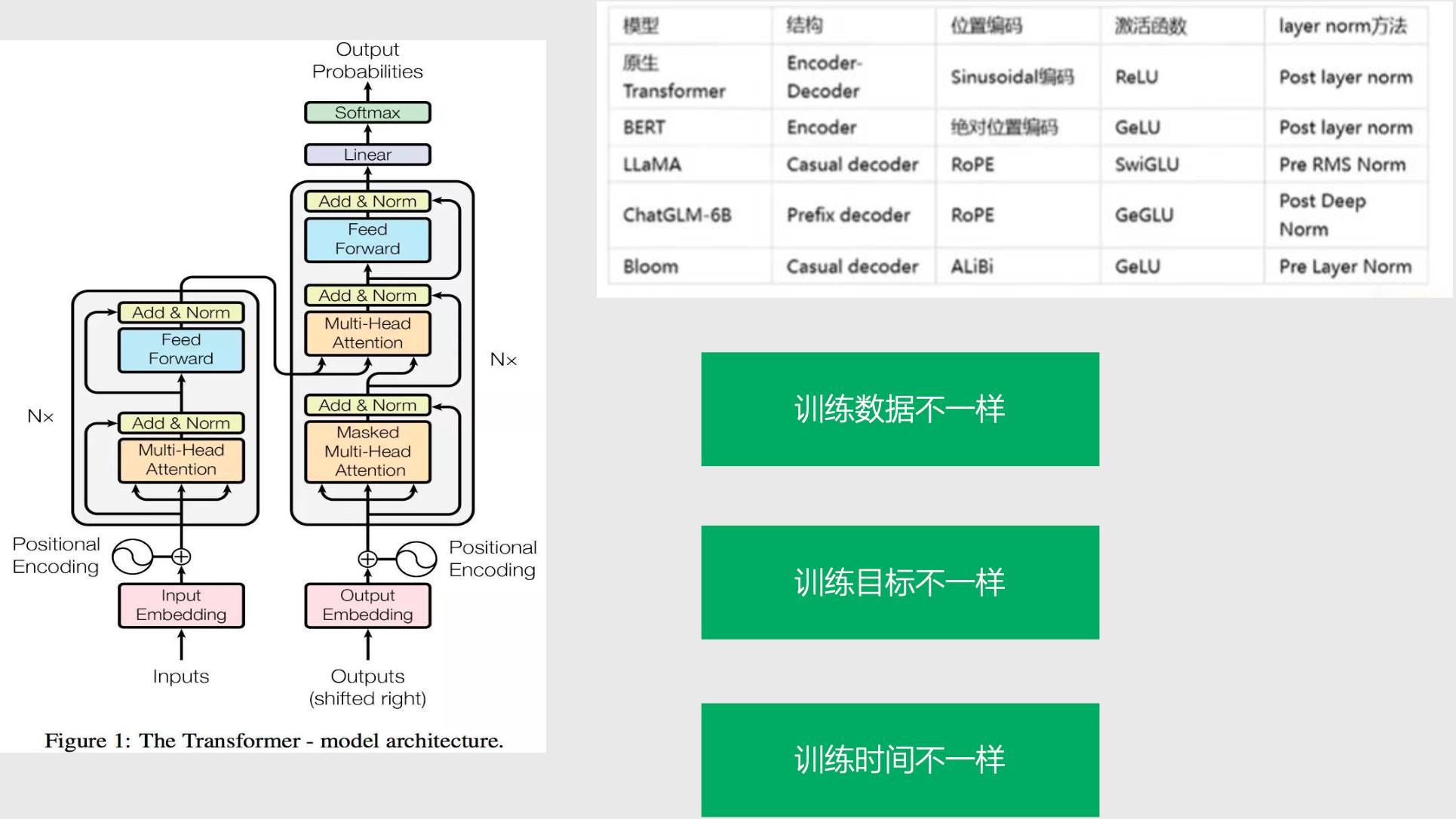
- 虽然使用的都是 Transformer 网络架构,但是各个模型训练数据不一样、训练目标不一样、训练时间也不一样,因此表现出的特性和性能也不一样。
各大模型
- 在线大模型:GPT、GLM、Gemini、Claude3
- 开源大模型:Llama、Qwen、baichuan、ChatGLM3
GPT系列对比