RAGas是一个用于评测RAG系统的评测框架,它支持与不同大语言模型的集成,并与langchain生态打通,能够很方便的构建评测系统。下面是RAGas的一些链接
官方文档及github对框架的使用介绍的比较详细,本文不会就该方面做更多的赘述。本文尝试深入到框架代码底层,尝试分析相关指标怎样进行的计算。
RAGas QuickStart
-
安装ragas
pip install ragas
-
代码示例
from datasets import Dataset
import os
from ragas import evaluate
from ragas.metrics import faithfulness, answer_correctnessos.environ["OPENAI_API_KEY"] = "your-openai-key"
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL--NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[faithfulness,answer_correctness])
score.to_pandas()
RAGas运行主要依赖于LLM(大语言模型)和embeddings(向量化)的模型,并支持langchain(同时支持llama_index)。这意味着只需要基于langchain框架实现LLM和embeddings相关接口,理论上都可以对接至RAGas框架。
指标实现
在评估RAG系统好坏时,我们通常需要下面四种类型的数据,分别是Question(问题)、Answer(回答)、Context(召回的上下文)、Ground truth(标准答案)(新版本代码中,这些元素的表达可能是user_input、response、retrieved_contexts、reference)。所有的评测指标也是围绕这四个数据元素展开的。
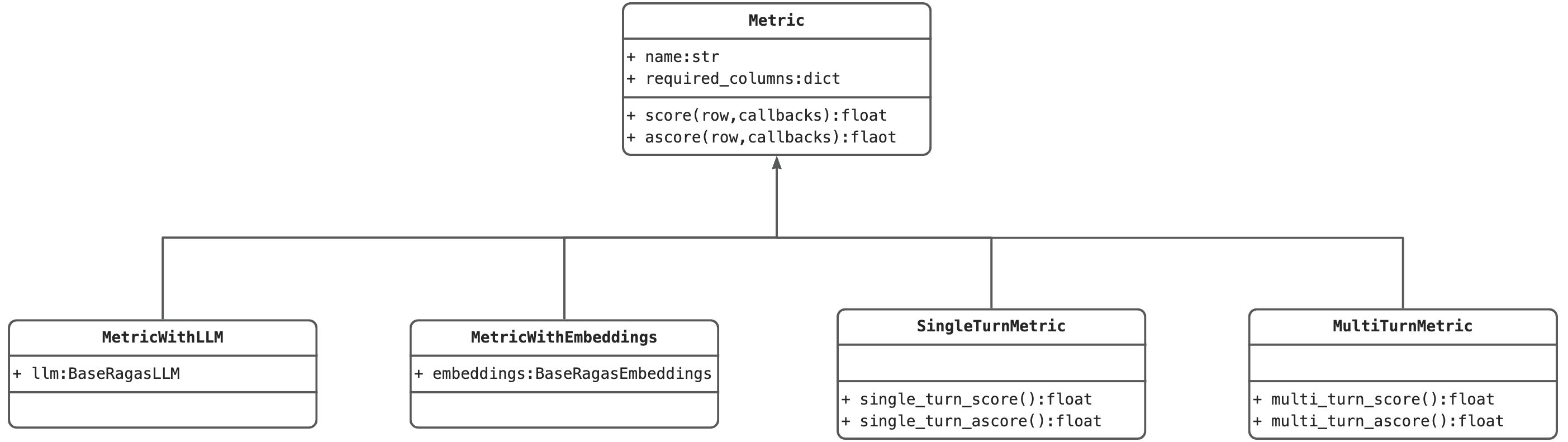
在开始走读代码之前,先就RAGas中的metric类代码继承关系做下简要的说明。所有的指标类都都继承自Metric这个基类,其中必选name、required_cloums两个属性,分别代表指标名和评测该指标所必须的数据列。有四个类继承自Metric,分别是
MetricWithLLM:需要调用LLM进行评测的指标,包含llm属性参数
MetricWithEmbeddings:需要调用Embedding进行评测的指标,包含embeddings成熟性参数
SingleTurnMetric:单轮对话评测指标
MultiTurnMetric:多轮对话评测指标
Faithfulness忠诚度
Faithfulness是用来评判大模型幻觉程度的指标,其核心思想是将回答拆分成一个个陈述,再看该陈述是否能够通过上下文推理得出
class Faithfulness(MetricWithLLM, SingleTurnMetric)Faithfulness类继承MetricWithLLM, SingleTurnMetric,也就意味着这个指标的评测是依赖于LLM,并且评测对象是单轮对话。同时其_required_columns为"user_input","response","retrieved_contexts",代表评测该指标需要用户输入、大模型回复及召回上下文。其进行指标得分计算的代码逻辑位于_ascore函数中
async def _ascore(self: t.Self, row: t.Dict, callbacks: Callbacks) -> float:
"""
returns the NLI score for each (q, c, a) pair
"""
# 判断是否传入llm
assert self.llm is not None, "LLM is not set"
# 对回答进行分割,分割后使用大模型生成1~n个陈述语句表达回答中的观点
statements_simplified = await self._create_statements(row, callbacks)
if statements_simplified is None:
return np.nan
# 将生成的陈述语句,打平到一个数组中
statements = []
for component in statements_simplified.sentences:
statements.extend(component.simpler_statements)
# 利用LLM对每个句子进行判断,判断其是否可以从上下文中推论出来
verdicts = await self._create_verdicts(row, statements, callbacks)
# 计算 可推论的句子/句子总数 得到该项指标的分数
return self._compute_score(verdicts)从ascore函数的代码中可以看出,faithfulness指标的计算还是比较简单的。整体逻辑就是将response进行拆解,拆解成一个个小的陈述语句,然后再有大模型判断每个语句是否能够从上下文中进行推断。如果不能进行推断,可能就是回答时由于大模型的幻觉产生的答案。
Answer Relevance回答相关性
回答相关性,是用来评判大模型的回答时与用户提问的相关性如何,其方法是通过回答推理出一系列可能的提问,判断回答是否有解答该提问。并用可能的提问与真实的提问计算余弦相似度,以此来决定其权重大小,最后对数据加和得到得分。
class ResponseRelevancy(MetricWithLLM, MetricWithEmbeddings, SingleTurnMetric)从指标的继承关系,可以看出,该指标是依赖于LLM和Embedding能力的评测单轮对话的指标。
async def _ascore(self, row: t.Dict, callbacks: Callbacks) -> float:
assert self.llm is not None, "LLM is not set"
prompt_input = ResponseRelevanceInput(response=row["response"])
responses = []
# 给回答生成'strictness'个可能的问题,并评判答案是否有对问题进行解答
for _ in range(self.strictness):
response = await self.question_generation.generate(
data=prompt_input,
llm=self.llm,
callbacks=callbacks,
)
responses.append(response)
# 计算得分
return self._calculate_score(responses, row)
def _calculate_score(
self, answers: t.Sequence[ResponseRelevanceOutput], row: t.Dict
) -> float:
question = row["user_input"]
gen_questions = [answer.question for answer in answers]
committal = np.any([answer.noncommittal for answer in answers])
if all(q == "" for q in gen_questions):
logger.warning(
"Invalid JSON response. Expected dictionary with key 'question'"
)
score = np.nan
else:
# 前端都是组装数据,以及判断数据的有效性,重要的是这两行的计算
# 首先计算生成的问题与用户真实输入的余弦相似度,作为评分权重系数
cosine_sim = self.calculate_similarity(question, gen_questions)
# 通过权重系数 * 回答中已解答的数据 作为分数
score = cosine_sim.mean() * int(not committal)
return scoreContextPrecision上下文精确度
上下文精度,是用来评判召回的上下文对回答问题的帮助程度大小,如召回无关的文档,将会使该指标评分降低
class LLMContextPrecisionWithReference(MetricWithLLM, SingleTurnMetric)还是先看类的定义,仔细看过前面文章应该对该指标的依赖和能够评测怎样的数据有大概了解了。接下来我们走读下代码,看看该指标是如何计算的
async def _ascore(
self: t.Self,
row: t.Dict,
callbacks: Callbacks,
) -> float:
assert self.llm is not None, "LLM is not set"
# 判别每条context是否有助于生成答案
responses = []
for context in row["retrieved_contexts"]:
verdicts: t.List[Verification] = (
# 多次调用llm,输出多次判定结果
await self.context_precision_prompt.generate_multiple(
data=QAC(
question=row["user_input"],
context=context,
answer=row["reference"],
),
n=self.reproducibility,
llm=self.llm,
callbacks=callbacks,
)
)
responses.append([result.model_dump() for result in verdicts])
answers = []
for response in responses:
# 进行一致性投票,以多数服从少数的原则,最终输出一个判定结果
agg_answer = ensembler.from_discrete([response], "verdict")
answers.append(Verification(**agg_answer[0]))
# 分数计算
score = self._calculate_average_precision(answers)
return score
# 计算平均精确度
def _calculate_average_precision(self, verdict_list: t.List[int]) -> float:
score = np.nan
# 正例的数量
denominator = sum(verdict_list) + 1e-10
numerator = sum(
[
# 累计精确度
(sum(verdict_list[: i + 1]) / (i + 1)) * verdict_list[i]
for i in range(len(verdict_list))
]
)
score = numerator / denominator
return score本次我们拆解下代码中调用大模型的prompt,看看调用大模型都做了些什么。首先是context_precision_prompt如下。其要求大模型根据给出的问题、答案以及上下文来判断,这条context是否对于输出答案有帮助,如果有帮助则输出1,否则输出0
Given question, answer and context verify if the context was useful in arriving at the given answer. Give verdict as "1" if useful and "0" if not with json output.同时在上述计算得分的代码中,使用平均精确度计算最后的得分,而不是使用 有帮助的context/context总数的方法。是因为,使用平均精确度还会考虑context在返回文本中的位置,如果有助于推论的context越靠前,其在最终得分的权重会越高。
AnswerSimilarity回答&答案相似度
该指标是用来评判基于RAG系统的回答与标准答案之间的相似程度。该指标的计算比较简单,分别取回答和答案,对其进行向量化和归一化处理后,计算其余弦相似度。如果有设置检测阈值的话,分数将输出0、1的二值数据
class SemanticSimilarity(MetricWithLLM, MetricWithEmbeddings, SingleTurnMetric)
async def _ascore(self: t.Self, row: t.Dict, callbacks: Callbacks) -> float:
assert self.embeddings is not None, "embeddings must be set"
ground_truth = t.cast(str, row["reference"])
answer = t.cast(str, row["response"])
if self.is_cross_encoder and isinstance(self.embeddings, HuggingfaceEmbeddings):
raise NotImplementedError(
"async score [ascore()] not implemented for HuggingFace embeddings"
)
else:
embedding_1 = np.array(await self.embeddings.embed_text(ground_truth))
embedding_2 = np.array(await self.embeddings.embed_text(answer))
# Normalization factors of the above embeddings
norms_1 = np.linalg.norm(embedding_1, keepdims=True)
norms_2 = np.linalg.norm(embedding_2, keepdims=True)
embedding_1_normalized = embedding_1 / norms_1
embedding_2_normalized = embedding_2 / norms_2
similarity = embedding_1_normalized @ embedding_2_normalized.T
score = similarity.flatten()
assert isinstance(score, np.ndarray), "Expects ndarray"
if self.threshold:
score = score >= self.threshold
return score.tolist()[0]写在后面
本文介绍了4种最常用的用来评判RAG系统好坏的指标,可以看出在RGAas框架下的指标评测代码非常清晰。同时在最新版本的RAGas代码中还包含其他多种指标类型,包含评判有害性的指标、评测多轮对话的指标、评测Agent能力的指标以及评测SQL生成能力的指标
同时RAGas支持langchain生态和llamaindex的接入,可以非常容易的应用到生产系统中