一、介绍
MinerU作为一款智能数据提取工具,其核心功能之一是处理PDF文档和网页内容,将其中的文本、图像、表格、公式等信息提取出来,并转换为易于阅读和编辑的格式(如Markdown)。在这个过程中,MinerU需要利用图像识别、文本识别(OCR)、布局分析等技术来理解和处理PDF文档和网页中的视觉信息。这些技术正是计算机视觉领域的重要组成部分。
二、构建流程
系统:Ubuntu系统,
显卡:3090,
显存:24G,cuda11.8
特别提示:使用显卡3060也可以(没尝试,感觉可以)
1.查看系统是否有Miniconda3的虚拟环境
conda -V
如果输入命令没有显示Conda版本号,则需要安装。

2.更新系统命令
输入下列命令将系统更新及系统下载
apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
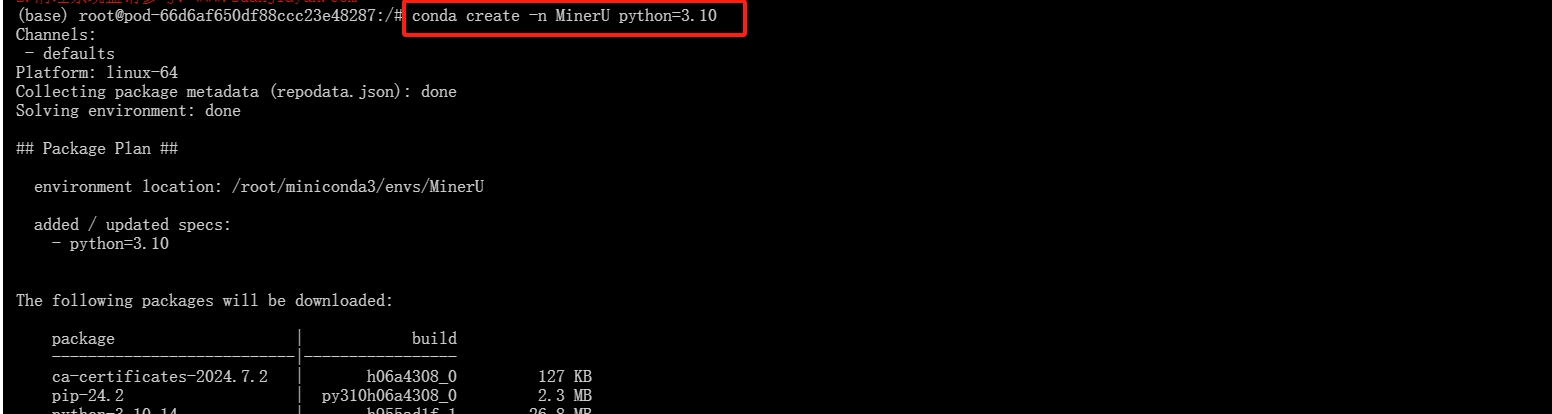
3.创建虚拟环境
-
创建名称为MinerU的虚拟环境
conda create -n MinerU python=3.8
-
激活"MinerU"虚拟环境
conda activate MinerU

4.下载模型
输入下列命令对MinerU模型进行下载(11G左右)
git clone https://gitclone.com/github.com/opendatalab/MinerU.git
进入模型文件
cd MinerU-master
5.下载依赖包
输入下列命令:
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com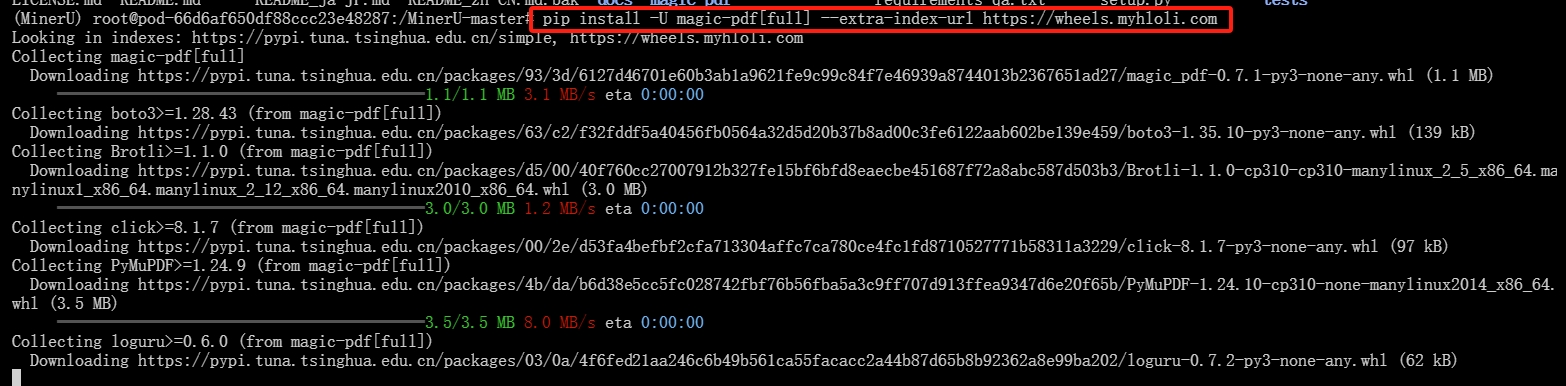
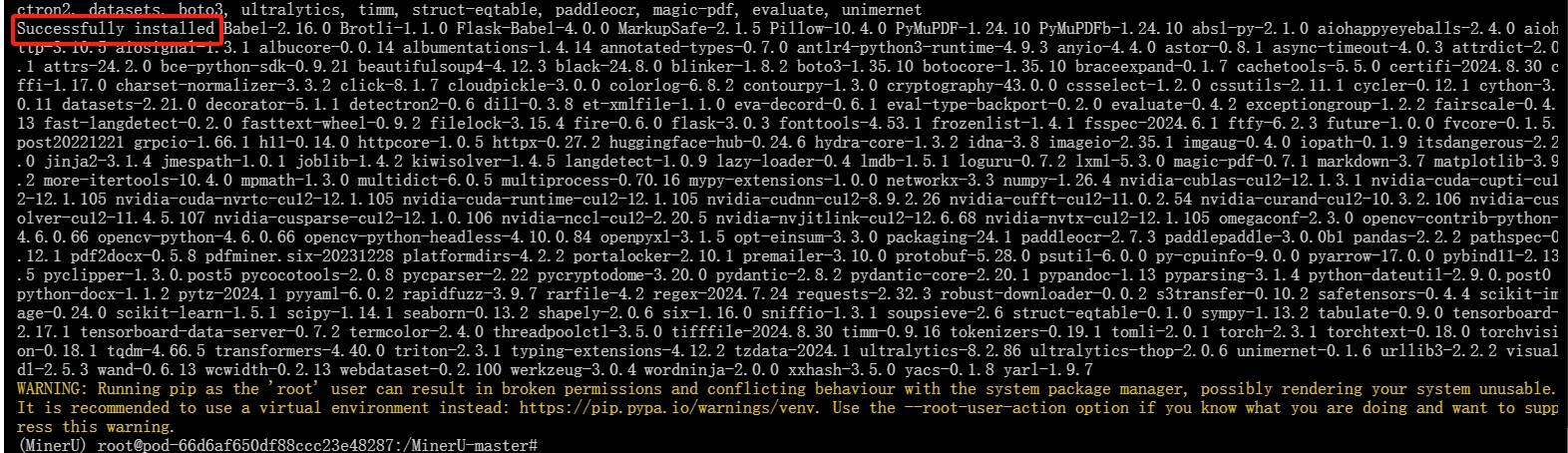
下载时间会很长,耐心等待,直到出现"Successfully"开头的下载结果
6.下载模型权重文件
输入下列命令进行下载:
git lfs install
git clone https://hf-mirror.com/opendatalab/PDF-Extract-Kit
更改权重文件路径(后面运行找不到权重,你也可以更改运行代码的获取权重文件路径):
cp -r /MinerU-madter/PDF-Extract-Kit/models /tmp/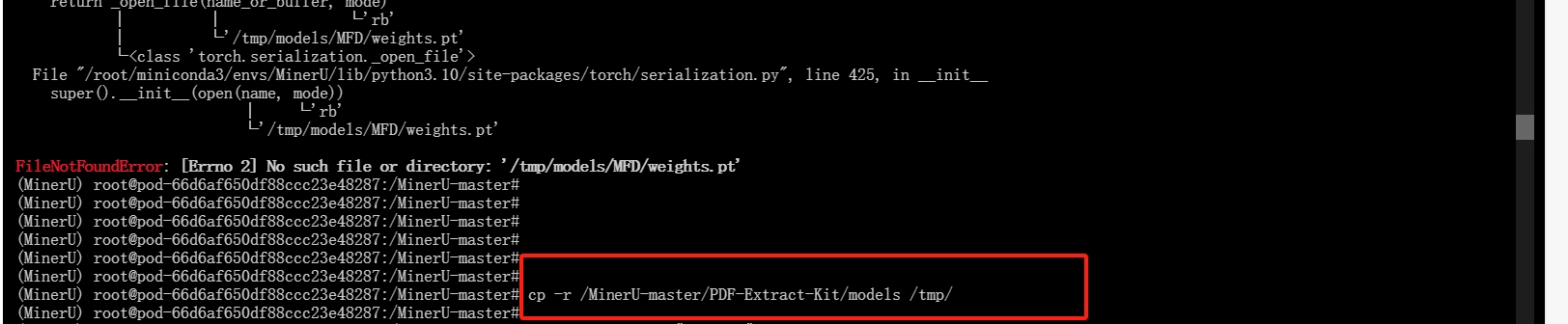
7.项目运行
"try.pdf"是本上传用于测试的文档,你可以根据自己所需上传自己的PDF文档。
输入下列命令:
magic-pdf --path "try.pdf"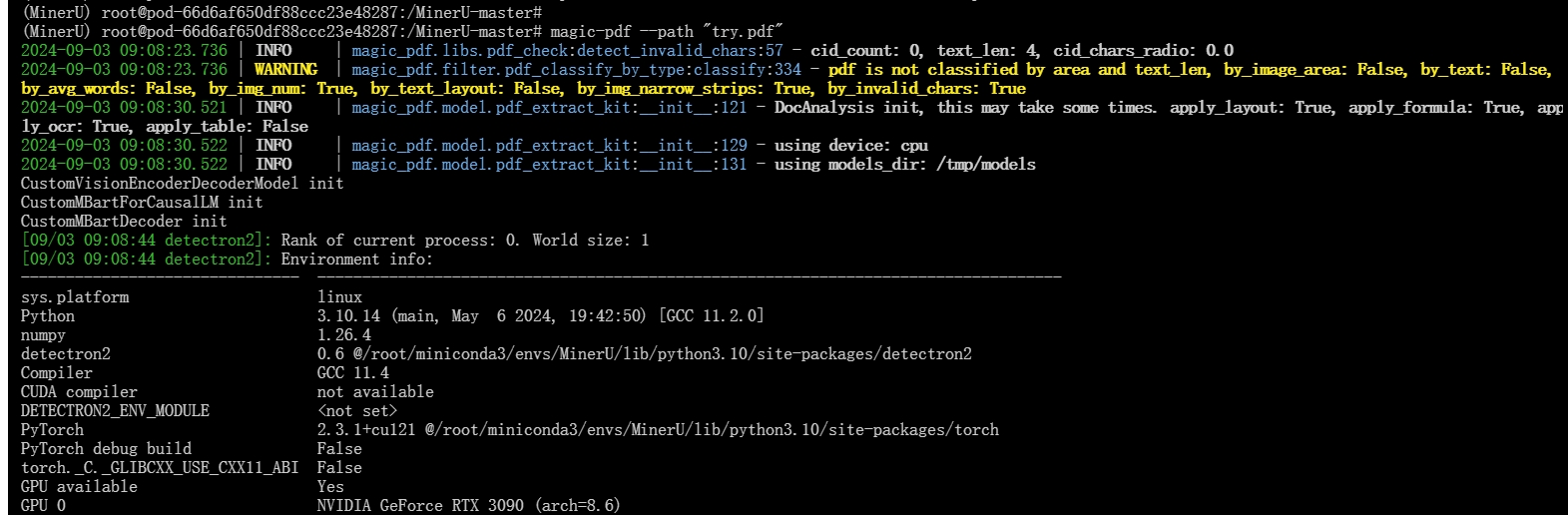
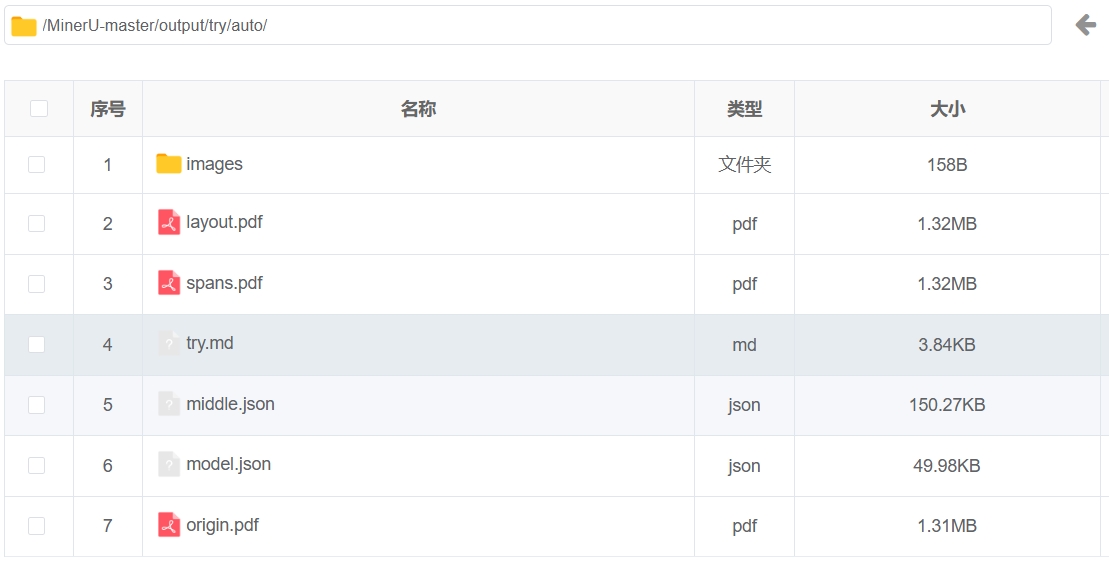
解析结束:
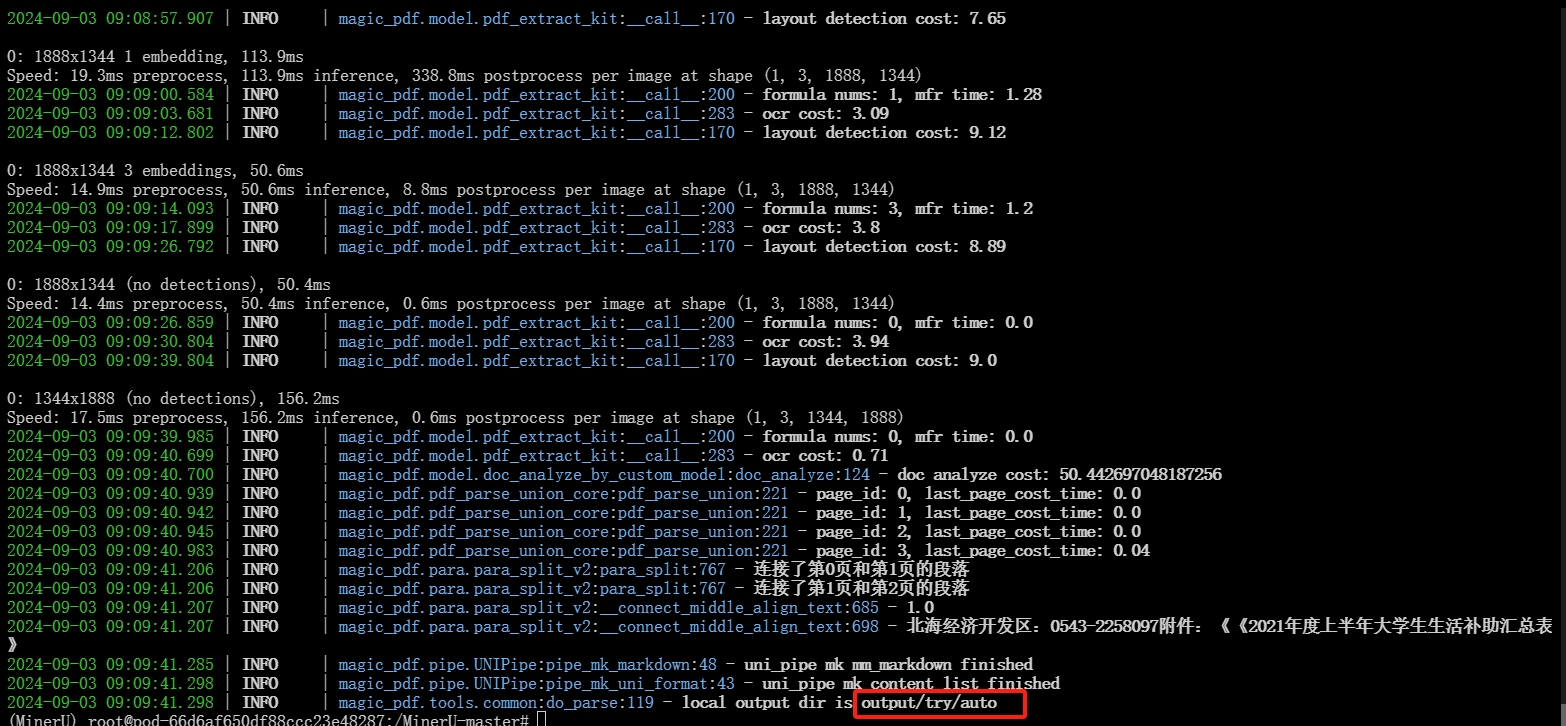
查看结果文件: