本文介绍如何通过阿里云实时计算Flink版实时读写云原生数据仓库AnalyticDB PostgreSQL版数据。
背景信息
云原生数据仓库AnalyticDB PostgreSQL版是一种大规模并行处理(MPP)数据仓库服务,可提供海量数据在线分析服务。实时计算Flink版是基于Apache Flink构建的⼀站式实时大数据分析平台,内置丰富上下游连接器,满足不同业务场景的需求,提供高效、灵活的实时计算服务。通过实时计算Flink版读取AnalyticDB PostgreSQL版数据,可以充分发挥云原生数据仓库的优势,提高数据分析的效率和精度。
使用限制
-
该功能暂不支持AnalyticDB PostgreSQL版Serverless模式。
-
仅Flink实时计算引擎VVR 6.0.0及以上版本支持云原生数据仓库AnalyticDB PostgreSQL版连接器。
-
仅Flink实时计算引擎VVR 8.0.1及以上版本支持云原生数据仓库AnalyticDB PostgreSQL版7.0版本。
说明
如果您使用了自定义连接器,具体操作请参见管理自定义连接器。
前提条件
-
AnalyticDB PostgreSQL版实例和Flink全托管工作空间需要位于同一VPC下。
说明
不在同一VPC下时请参见网络连通性。
-
已创建Flink全托管工作空间。具体操作请参见开通实时计算Flink版。
步骤一:配置白名单并准备数据
-
将目标Flink工作空间所属的网段加入AnalyticDB PostgreSQL版的白名单。
-
单击页面右上方的登录数据库 ,并填写账号和密码。连接数据库的更多方式,请参见客户端连接。
-
在对应实例的目标数据库中创建一张名为adbpg_dim_table的表并插入50条测试数据。
建表SQL和插入数据SQL的示例如下:
--创建名称为adbpg_dim_table的表。 CREATE TABLE adbpg_dim_table( id int, username text, PRIMARY KEY(id) ); --向adbpg_dim_table的表中插入50行数据,其中id字段的值为从1到50的整数,而username字段的值为username字符串后面跟随当前行数的文本表示。 INSERT INTO adbpg_dim_table(id, username) SELECT i, 'username'||i::text FROM generate_series(1, 50) AS t(i);您可以使用
select * from adbpg_dim_table order by id;语句查看插入后的数据。 -
创建一张名为adbpg_sink_table的表,用于Flink写入结果数据。
CREATE TABLE adbpg_sink_table( id int, username text, score int );
步骤二:创建Flink作业
-
登录实时计算控制台,单击目标工作空间操作 列下的控制台。
-
在左侧导航栏,单击数据开发 > ETL ,单击新建 ,选择空白的流作业草稿 ,单击下一步。
-
在新建作业草稿对话框,填写作业配置信息。
|----------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------|
| 作业参数 | 说明 | 示例 |
| 文件名称 | 作业的名称。 说明 作业名称在当前项目中必须保持唯一。 | adbpg-test |
| 存储位置 | 指定该作业的代码文件所属的文件夹。 您还可以在现有文件夹右侧,单击 图标,新建子文件夹。 | 作业草稿 |
图标,新建子文件夹。 | 作业草稿 |
| 引擎版本 | 当前作业使用的Flink的引擎版本。引擎版本号含义、版本对应关系和生命周期重要时间点详情请参见引擎版本介绍。 | vvr-8.0.1-flink-1.17 | -
单击创建。
步骤三:编写作业代码并部署作业
-
将以下作业代码拷贝到作业文本编辑区。
---创建一个datagen源表。本示例中无需修改WITH参数。 CREATE TEMPORARY TABLE datagen_source ( id INT, score INT ) WITH ( 'connector' = 'datagen', 'fields.id.kind'='sequence', 'fields.id.start'='1', 'fields.id.end'='50', 'fields.score.kind'='random', 'fields.score.min'='70', 'fields.score.max'='100' ); --创建adbpg维表。需根据您的实际情况修改WITH参数。 CREATE TEMPORARY TABLE dim_adbpg( id int, username varchar, PRIMARY KEY(id) not ENFORCED ) WITH( 'connector' = 'adbpg', 'url' = 'jdbc:postgresql://gp-2ze****3tysk255b5-master.gpdb.rds.aliyuncs.com:5432/flinktest', 'tablename' = 'adbpg_dim_table', 'username' = 'flinktest', 'password' = '${secret_values.adb_password}', 'maxRetryTimes'='2', --写入数据失败后,重试写入的最大次数。 'cache'='lru', --缓存策略, 'cacheSize'='100' --缓存大小 ); --创建adbpg结果表。需根据您的实际情况修改WITH参数。 CREATE TEMPORARY TABLE sink_adbpg ( id int, username varchar, score int ) WITH ( 'connector' = 'adbpg', 'url' = 'jdbc:postgresql://gp-2ze****3tysk255b5-master.gpdb.rds.aliyuncs.com:5432/flinktest', 'tablename' = 'adbpg_sink_table', 'username' = 'flinktest', 'password' = '${secret_values.adb_password}', 'maxRetryTimes' = '2', 'conflictMode' = 'ignore',--当Insert写入出现主键冲突或者唯一索引冲突时的处理策略。 'retryWaitTime' = '200' --重试的时间间隔。 ); --维表和源表join后的结果插入adbpg结果表。 INSERT INTO sink_adbpg SELECT ts.id,ts.username,ds.score FROM datagen_source AS ds JOIN dim_adbpg FOR SYSTEM_TIME AS OF PROCTIME() AS ts on ds.id = ts.id; -
根据实际情况修改参数。
本示例中无需修改datagen源表。您需要根据实际情况修改adbpg维表和结果表参数,具体说明如下。涉及的连接器更多相关参数和类型映射请参见相关文档。
|--------------|----------|-------------------------------------------------------------------------------------------------------------------------------------|
| 参数 | 是否必填 | 说明 |
| url | 是 | AnalyticDB PostgreSQL版的JDBC连接地址。格式为jdbc:postgresql://<地址>:<端口>/<连接的数据库名称>。您可在云原生数据仓库 AnalyticDB PostgreSQL版控制台对应实例的数据库连接页面查看。 |
| tablename | 是 | AnalyticDB PostgreSQL版的表名。 |
| username | 是 | AnalyticDB PostgreSQL版的数据库账号。 |
| password | 是 | AnalyticDB PostgreSQL版的数据库账号密码。 |
| targetSchema | 否 | Schema名称。默认为public。如果您使用了对应数据库下其他Schema,请填写此参数。 | -
在作业开发页面顶部,单击深度检查,进行语法检查。
-
单击部署。
-
在运维中心 > 作业运维 页面,单击目标作业操作 列下的启动。
步骤四:查看写入数据结果
-
单击登录数据库 ,连接数据库的更多方式,请参见客户端连接。
-
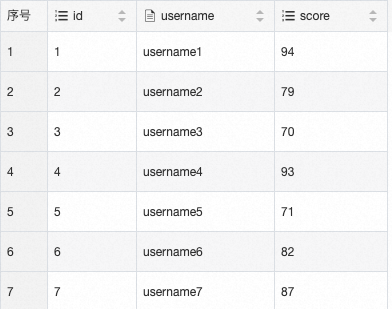
执行如下查询语句,查看Flink写入数据。
SELECT * FROM adbpg_sink_table ORDER BY id;结果如下图所示。