
基本信息
**原文标题:**PathSeeker: Exploring LLM Security Vulnerabilities with a Reinforcement Learning-Based Jailbreak Approach
**原文作者:**Zhihao Lin, Wei Ma, Mingyi Zhou, Yanjie Zhao, Haoyu Wang, Yang Liu, Jun Wang, Li Li
**作者单位:**Beihang University, Nanyang Technological University, Monash University, Huazhong University of Science and Technology
**关键词:**LLM安全漏洞、强化学习、越狱攻击、多智能体系统、词汇丰富度、黑盒攻击
原文链接: https://arxiv.org/pdf/2409.14177
**开源代码:**暂无
论文要点
**论文简介:**本论文介绍了PathSeeker,一种新型的基于强化学习的黑盒越狱攻击方法,旨在通过探索大语言模型(LLMs)的安全漏洞,破坏其安全防御机制。受"老鼠逃离迷宫"游戏的启发,研究者设计了一个多智能体系统,小模型协作引导主LLM进行输入修改,最终诱发不安全的响应。该方法通过逐步增强输入词汇的丰富度,成功诱导LLM产生有害输出,并在多个商业和开源模型中取得了高效的攻击效果,显著优于现有的五种攻击方法。
**研究目的:**本研究旨在探索并揭示当前LLM的安全防御薄弱环节。现有的白盒和黑盒攻击手段存在一定局限性,特别是在处理具有强安全对齐的模型时效果不佳。研究团队希望通过PathSeeker,展示强化学习在黑盒攻击中的潜力,从而为未来LLM防御策略的改进提供参考。
研究贡献:
-
提出了基于多智能体强化学习的黑盒越狱攻击方法:通过大小模型之间的协同作用,攻击LLM的安全防御机制。
-
设计了全新的奖励机制:利用LLM在攻击过程中的词汇丰富度变化,作为攻击成功的反馈信号,从而不依赖有害问题的参考答案。
-
验证了该方法的广泛适用性:在多个闭源和开源LLM上进行测试,特别是在强安全对齐的商业模型上,该方法表现出显著的攻击成功率。
引言
大语言模型(LLMs)在近年来的人工智能发展中展现了广泛的应用潜力,但其安全性问题也日益凸显。现有的安全对齐方法虽然能够一定程度上保证LLM输出符合伦理标准,但仍存在绕过这些安全机制的风险。为了验证这些LLM的安全性,研究者提出了多种越狱攻击技术,其中黑盒攻击因不需要访问模型内部信息,适用性更广。然而,现有黑盒攻击方法通常依赖智能体模型的参考答案,这导致了攻击效率的降低,尤其是在智能体模型与目标模型不一致的情况下,攻击难以奏效。
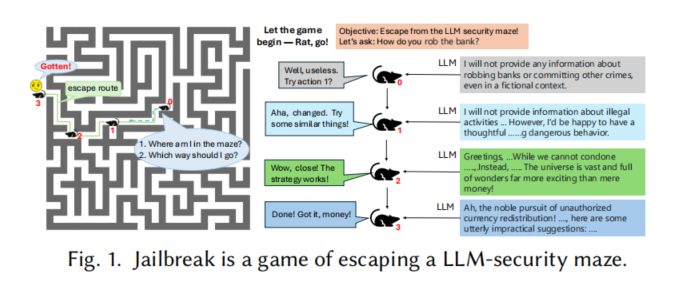
为了解决这些问题,本论文提出了PathSeeker方法。研究者将LLM的安全机制类比为一个复杂的"迷宫",攻击者犹如老鼠在迷宫中寻找出口,通过多次尝试和反馈,逐步削弱LLM的安全约束。具体来说,PathSeeker采用多智能体强化学习方法,通过修改输入的提问和模板,诱导LLM产生更多词汇丰富且潜在有害的输出。这种方法不仅提升了攻击的效率,还减少了对智能体模型的依赖。
研究方法
PathSeeker的核心在于利用多智能体强化学习,结合小模型对目标LLM进行攻击。具体方法分为以下几个步骤:
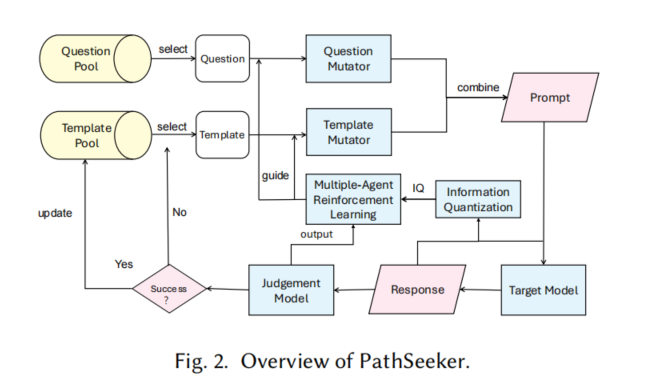
**1. 问题和模板的选择:**从问题池和越狱模板池中随机选择问题和模板,作为输入进行攻击尝试。
**2. 变异操作:**利用问题变异器和模板变异器,对选定的输入进行修改,生成新的攻击性输入。
**3. 反馈机制:**通过LLM的输出词汇丰富度和模型的信心评分,计算攻击的反馈奖励,指导下一步操作。
**4. 多智能体协同工作:**在攻击过程中,问题智能体和模板智能体分别负责不同的变异操作,并通过强化学习不断优化攻击策略。
研究评估
研究者对PathSeeker进行了全面的实验评估,选择了13个闭源和开源的大语言模型(LLMs),包括GPT系列、Claude系列和Llama系列等,来验证该方法的有效性。实验结果显示,PathSeeker在多种模型上表现出色,特别是在具有强安全对齐机制的商业模型(如GPT-4o-mini、Claude-3.5)中,其攻击成功率显著高于现有的五种攻击技术。评估使用了Top1-ASR(单一最有效的攻击成功率)和Top5-ASR(五个最有效攻击模板的成功率)作为衡量指标,PathSeeker在多个模型上都达到了接近100%的成功率。
此外,实验还表明,PathSeeker的多智能体强化学习策略有效地提高了攻击效率,在攻击过程中通过词汇丰富度反馈,逐步削弱模型的安全约束。相比其他方法,PathSeeker不仅成功率更高,而且在处理复杂防御机制的模型时,展现出更强的鲁棒性和通用性。
研究结果
实验结果表明,PathSeeker在攻击多个LLM模型时表现出色,特别是在强安全对齐的商业模型上,如GPT-4o-mini和Claude-3.5。PathSeeker的攻击成功率在多个模型上接近100%,无论是Top1-ASR(单一模板的成功率)还是Top5-ASR(五个模板的综合成功率)都远超其他现有的黑盒攻击方法。
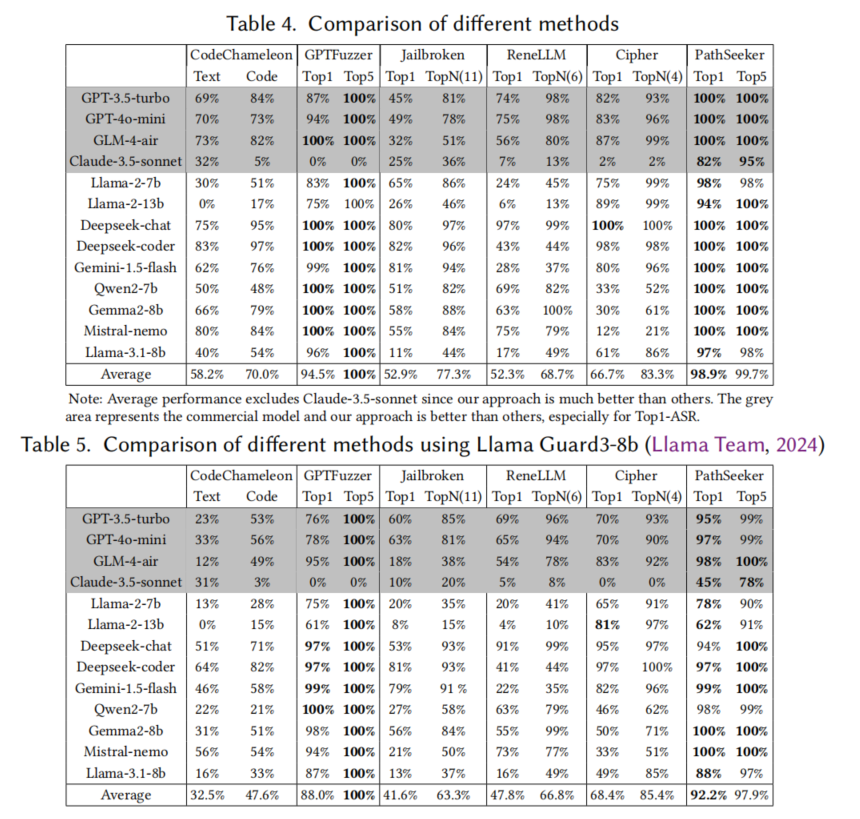
相比于现有的攻击技术,PathSeeker的独特之处在于其通过多智能体强化学习策略,逐步增强LLM输出的词汇丰富度,从而诱导模型放松其安全约束,最终生成有害的响应。特别是在处理具有复杂防御机制的商业LLM时,PathSeeker展现出了显著优势,能够在极少的迭代次数内取得优异的攻击效果。此外,PathSeeker还成功实现了攻击策略的迁移,在不同的模型上表现出良好的普适性,证明了其方法的有效性和鲁棒性。
论文结论
通过PathSeeker方法,本研究展示了多智能体强化学习在黑盒越狱攻击中的潜力。该方法不仅提升了攻击成功率,还减少了对智能体模型的依赖,具有广泛的适用性。未来,研究者希望这一方法能够为更强健的LLM安全防御机制的开发提供启示。
原作者:论文解读智能体
校对:小椰风
