一.前置事项
请注意,需要先实现Windows的本地JDK和Hadoop的安装。
二.windows安装Anaconda
资源:Miniconda3-py38-4.11.0-Windows-x86-64,在window使用的Anaconda资源-CSDN文库
右键以管理员身份运行,选择你的安装路径,但是请注意最好文件路径不要有空格或者中文,并且要自己找得到。
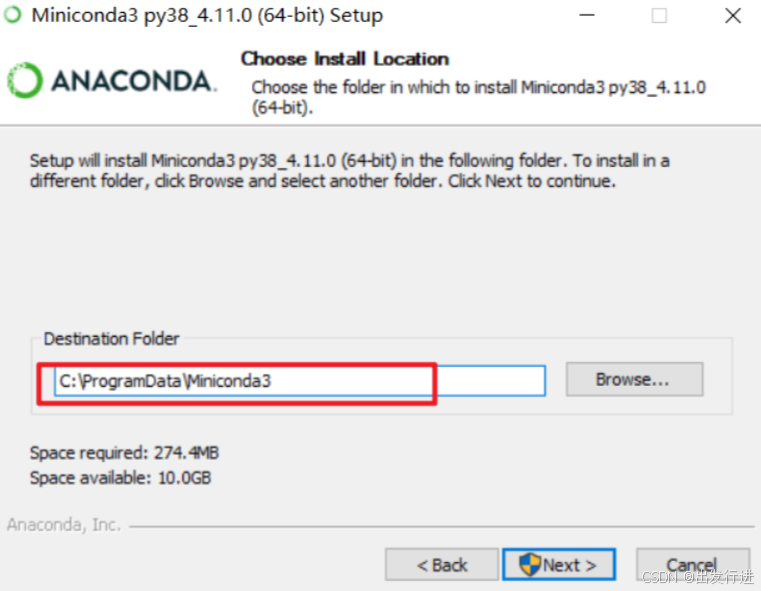
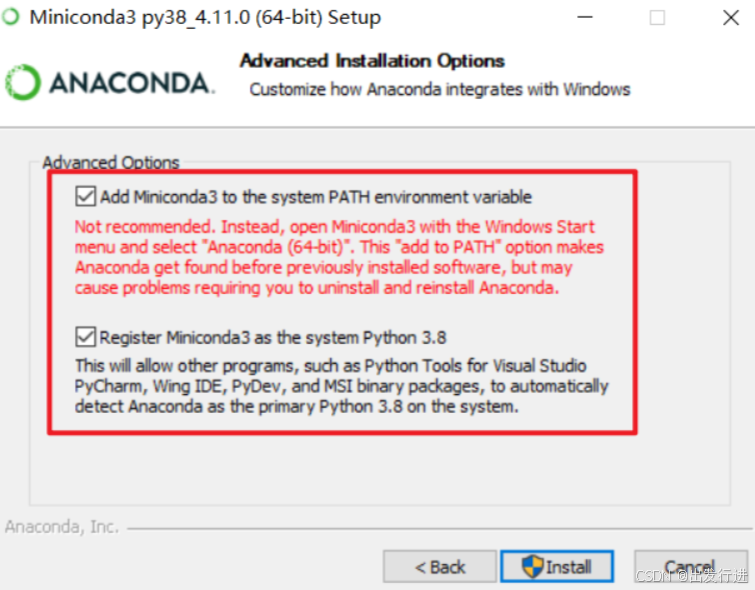
然后傻瓜式安装即可。
三.Anaconda中安装PySpark
进入黑窗口,操作如下:

bash
进入base环境中:
conda activate base
安装pyspark [此时的pyspark和pyspark命令不是一会儿事儿]
pip install pyspark==3.1.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
也可以使用阿里云的源:https://mirrors.aliyun.com/pypi/simple中间如果遇到输入y或者n,就输入y
检查是否安装成功:
可以通过conda list或者pip list检查是否包含:py4j和 pyspark两个包。
四.Pycharm中创建工程
如图:

大概介绍一下目前为止都在干什么:
Annaconda : 这个软件它包含了Python,并且可以安装各种环境,比如pyspark
PySpark : pip install pyspark==3.1.2 首先这个是pyspark的开发环境,这个软件安装在了 Annaconda里面,所以Annaconda 安装在了哪个盘,你这个pyspark 就在哪个盘。
pycharm: 这个是一个IDE工具,IDE工具关联了 本地的Annaconda,你这个Annaconda 里面有什么工具,pycharm 中就可以使用什么工具。
假如我没有在黑窗口安装这个pyspark ,就关联了pycharm ,请问,这个pycharm 如何才能有pyspark的环境?
那么继续,创建项目后来检查一下:

看一下如下文件夹里面是否有py4j和pyspark:

有的话恭喜没有问题,那么继续下一步:

创建四个文件夹:
main :用于存放每天开发的一些代码文件
resources :用于存放程序中需要用到的配置文件
datas :用于存放每天用到的一些数据文件
test :用于存放测试时的一些代码文件
main和resource的创建后:

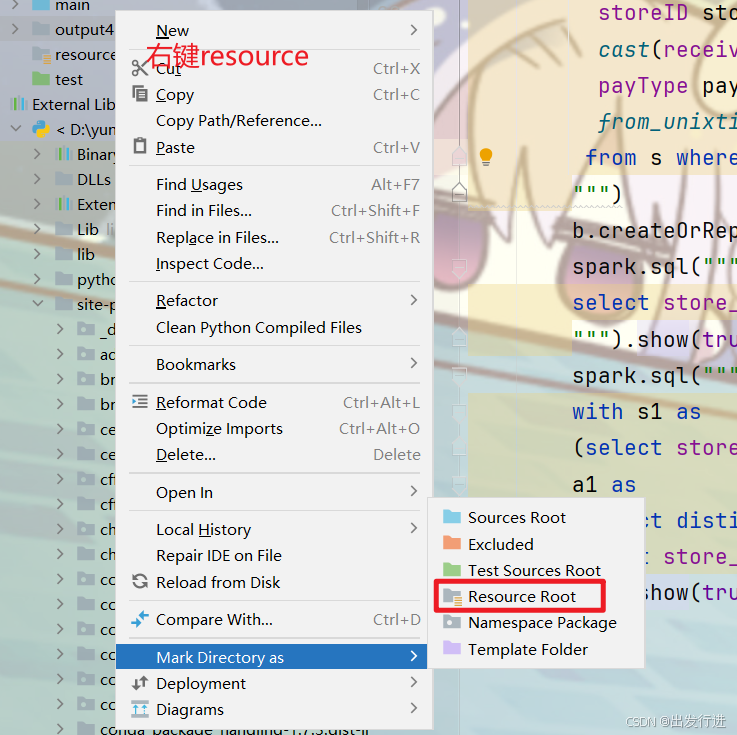
同理test选择test sources root,一样的操作不再放图了。
好的,那么准备工作已经完成,来写一个代码测试一下:
在main里新建一个Python文件然后:
python
import os
if __name__ == '__main__':
print("你好")
os.environ['JAVA_HOME'] = 'D:/Program Files/Java/jdk1.8.0_271'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'请改成自己电脑里的配置。
获取SparkContext对象:
Spark中的核心类,任何一个Spark的程序都必须包含一个SparkContext类的对象
python
import os
# 导入pyspark模块
from pyspark import SparkContext,SparkConf
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'D:/Program Files/Java/jdk1.8.0_271'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 获取 conf 对象
# setMaster 按照什么模式运行,local bigdata01:7077 yarn
# local[2] 使用2核CPU * 你本地资源有多少核就用多少核
# appName 任务的名字
conf = SparkConf().setMaster("local[*]").setAppName("第一个Spark程序")
# 假如我想设置压缩
# conf.set("spark.eventLog.compression.codec","snappy")
# 根据配置文件,得到一个SC对象,第一个conf 是 形参的名字,第二个conf 是实参的名字
sc = SparkContext(conf=conf)
print(sc)
# 使用完后,记得关闭
sc.stop()运行结果如下:

可见非常明显的问题,每次都要写入这固定的环境配置,非常麻烦,那么我们将它模板化:

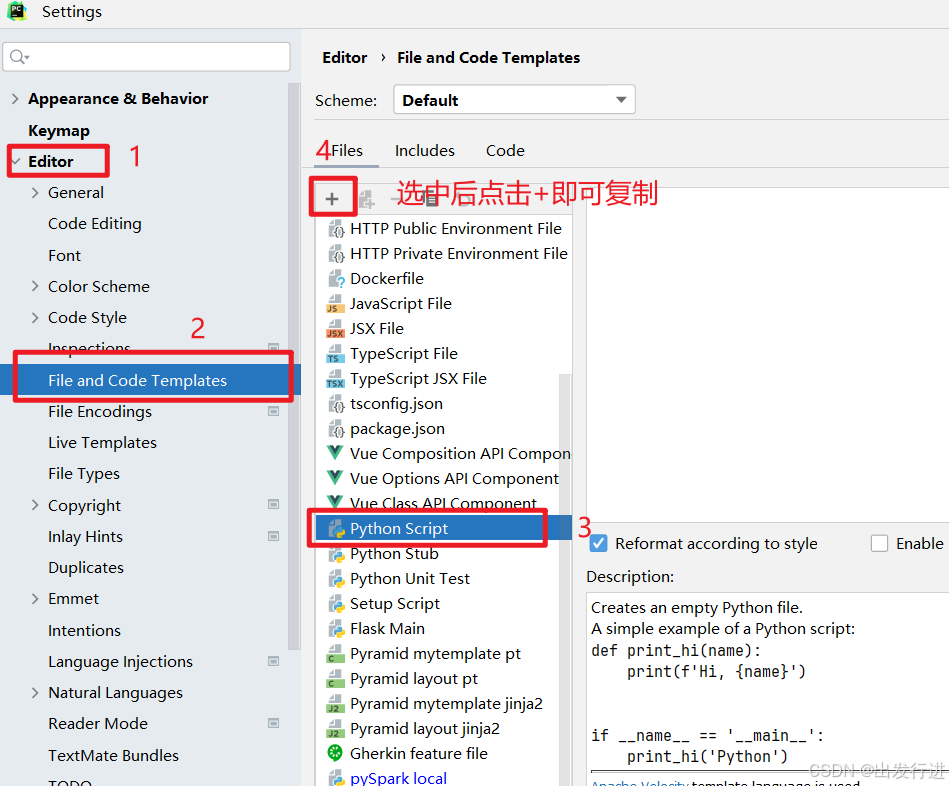
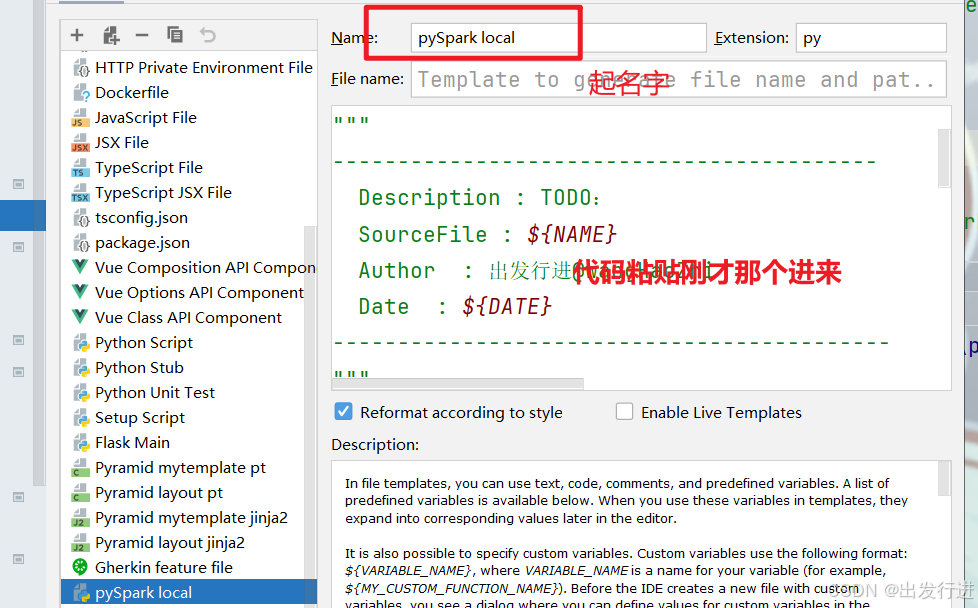
配置完成后记得是要点击:

再退出,否则没有保存的话肯定用不了,
然后再次进行新建的时候:

就可以直接选择我们的模板了。非常的方便。