在数据分析和数据库操作中,SQL 查询是至关重要的一环。本文将通过分析四道典型的 SQL 题目,深入探讨如何从复杂的业务需求中构建准确高效的 SQL 查询。
一、删除学生表冗余信息
需求解读
给定一个学生表,其中包含自动编号、学号、姓名、课程编号、课程名称和分数等字段。要求删除除了自动编号不同,其他信息(学号、姓名、课程编号、课程名称、分数)都相同的冗余记录。
学生表
自动编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
代码片段
建表
sql
CREATE TABLE students (
id INT, -- 自动编号
student_id STRING, -- 学号
student_name STRING, -- 姓名
course_id STRING, -- 课程编号
course_name STRING, -- 课程名称
score INT -- 分数
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;导入数据
sql
INSERT INTO students
VALUES ('1', '2005001', '张三', '0001', '数学', '69'),
('2', '2005002', '李四', '0001', '数学', '89'),
('3', '2005001', '张三', '0001', '数学', '69');SQL如下
sql
select *
from students
where id not in (
select min(id)
from students
group by student_id, student_name, course_id, course_name, score
);如果查询结果符合预期,再将SELECT *替换为DELETE来执行实际的删除操作。
二、寻找 GDP 增速超过罗湖区的区
1)表名:macro_index_data
2)字段名:数据期(年月)(occur_period)、地区代码(area_code)、指标代码
(index_code)、指标类型(增速、总量)(index_type)、指标值(index_value)、数据更新时间
(update_time)。说明:罗湖区的区划代码为440305000000、GDP指标代码为gmjj_jjzl_01、指标类型的枚举值分别是增速(TB)、总量(JDZ)
3)请写出,2020年4个季度中GDP的增速都超过罗湖区同期的区有哪些
需求解读
本题要求找出 2020 年四个季度中 GDP 增速都超过罗湖区同期的区。涉及到从macro_index_data表中筛选出符合条件的数据。
代码剖析
查询语句通过两个子查询分别计算罗湖区和其他区的 GDP 增速数据。在每个子查询中,使用sum函数与case when语句根据月份范围计算每个季度的 GDP 增速指标值。然后通过join条件,将其他区与罗湖区的数据进行比较,筛选出四个季度增速都大于罗湖区的区。例如:
代码片段
建表
sql
CREATE TABLE macro_index_data (
occur_period string, -- 数据期(年月)
area_code string, -- 地区代码
index_code string, -- 指标代码
index_type string, -- 指标类型
index_value double, -- 指标值,这里使用 double,可根据实际调整
update_time timestamp -- 数据更新时间
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' -- 假设字段分隔符为制表符,可根据实际修改
STORED AS TEXTFILE;导入数据
数据暂无可由AI生成放入 HDFS 中,例如在/user/hive/data/macro_index_data.txt路径下,使用以下命令:
sql
LOAD DATA INPATH '/user/hive/data/macro_index_data.txt' INTO TABLE macro_index_data;SQL如下
sql
select t2.area_code
from (
--先求出罗湖区2020年四季度的GDP指标
select area_code,
sum(case when month('occur_period') between 1 and 3 then
index_value else 0 end) `one`,
sum(case when month('occur_period') between 4 and 6 then
index_value else 0 end) `two`,
sum(case when month('occur_period') between 7 and 9 then
index_value else 0 end) `three`,
sum(case when month('occur_period') between 10 and 12 then
index_value else 0 end) `four`
from macro_index_data
where area_code = '440305000000'
and index_code = 'gmjj_jjzl_01'
and index_type = 'TB'
and year('occur_period') = 2020
group by area_code
) t1
join (
--再求出其它区2020年四季度的GDP指标
select area_code,
sum(case when month('occur_period') between 1 and 3 then
index_value else 0 end) `one`,
sum(case when month('occur_period') between 4 and 6 then
index_value else 0 end) `two`,
sum(case when month('occur_period') between 7 and 9 then
index_value else 0 end) `three`,
sum(case when month('occur_period') between 10 and 12 then
index_value else 0 end) `four`
from macro_index_data
where area_code <> '440305000000'
and index_code = 'gmjj_jjzl_01'
and index_type = 'TB'
and year('occur_period') = 2020
group by area_code
) t2 on t2.one > t1.one
and t2.two > t1.two
and t2.three > t1.three
and t2.four > t1.four;三、核酸检测人数相关统计
1)表1:t_syrkxxb (实有人口信息表),字段名:姓名(xm)、证件号码(zjhm)、证件类型(zjlx)、出
生日期(csrq)、居住地址(jzdz)、所在街道(jdmc)、所在社区(sqmc)、联系电话(lxdh)、更新时间(gxsj)
2)表2:t_hsjcqkb (核酸检测情况表),字段名:姓名(xm)、证件号码(zjhm)、证件类型(zjlx)、
检测机构(jcjgou)、检测时间(jcsj)、报告时间(bgsj)、检测结果(jcjguo)
3)说明:实有人口信息表中,因网格统计的时候一人有多处房产或者在多地有居住过的,会有多
条数据,仅取最新一条记录;核酸检测情况表中,同一人在同一天内不同检测机构检测多次的算多次检
测,同一人在同一天内同一检测机构检测多次的只算最后一次
4)请写出各街道已参与核酸检测总人数、今日新增人数、已检测人数占总人口数的比例;
需求解读
需要计算各街道已参与核酸检测总人数、今日新增人数以及已检测人数占总人口数的比例。涉及到t_syrkxxb(实有人口信息表)和t_hsjcqkb(核酸检测情况表)两张表。
代码剖析
通过三个子查询和连接操作来实现。首先从实有人口信息表计算各街道总人口数。对于今日新增人数,从核酸检测表中筛选出今日(2021 - 07 - 29)检测的用户,通过左连接排除之前检测过的用户后按街道分组计数。已参与核酸检测总人数的计算,先从实有人口表中获取每个用户的最新记录,再与检测过的用户连接并按街道分组计数。最后将三个结果集连接并选择相应字段。
代码片段
建表
创建实有人口信息表t_syrkxxb
sql
CREATE TABLE t_syrkxxb (
xm STRING,
zjhm STRING,
zjlx STRING,
csrq STRING,
jzdz STRING,
jdmc STRING,
sqmc STRING,
lxdh STRING,
gxsj TIMESTAMP
);创建核酸检测情况表t_hsjcqkb
sql
CREATE TABLE t_hsjcqkb (
xm STRING,
zjhm STRING,
zjlx STRING,
jcjgou STRING,
jcsj TIMESTAMP,
bgsj TIMESTAMP,
jcjguo STRING
);导入数据
数据暂无可由AI生成放入 HDFS 中,例如在/user/hive/data/t_hsjcqkb.txt路径下,使用以下命令:
sql
LOAD DATA INPATH '/user/hive/data/t_hsjcqkb.txt' INTO TABLE t_hsjcqkb;
LOAD DATA INPATH '/user/hive/data/t_syrkxxb.txt' INTO TABLE t_syrkxxb;SQL如下
sql
select t6.jdmc `所在街道`,
t8.jiance_person_num `已参与核酸检测总人数`,
t7.add_num `今日新增人数`,
t6.person_num `已检测人数占总人口数的比例`
from (
--各街道总人口数
select jdmc,count(*) `person_num`
from t_syrkxxb
group by jdmc
) t6
join (
--各街道今日新增人数:以前没有检测过的用户
select t4.jdmc,count(*) `add_num`
from (
select zjhm,zjlx,jdmc
from t_hsjcqkb
where date_format('jcsj','yyyy-MM-dd') = '2021-07-29'
) t4
left join (
--求出检测过的用户
select zjhm,zjlx
from t_hsjcqkb
group by zjhm,zjlx
) t5 on t4.zjhm = t5.zjhm
and t4.zjlx = t5.zjlx
where t5.zjhm is null
group by jdmc
) t7 on t6.jdmc = t7.jdmc
join (
--求出各街道已参与核酸检测总人数
select t1.jdmc,count(*) `jiance_person_num`
from (
--先将实有人口表按更新时间排序后过滤出最新的记录
select t1.*
from (
select *,row_number() over(partition by zjhm order by gxsj desc)
`rank_gxsj`
from t_syrkxxb
group by zjhm
) t1
where rank_gxsj = '1'
) t2
join (
--求出检测过的用户
select zjhm,zjlx
from t_hsjcqkb
group by zjhm,zjlx
) t3 on t2.zjhm = t3.zjhm and t2.zjlx = t3.zjlx
group by t1.jdmc
) t8 t6.jdmc = t8.jdmc; 四、查询用户连续三天登录数据
需求解读
给定用户登录记录表,要查询出用户连续三天登录的所有数据记录。
代码剖析
查询过程分为四步。首先使用lead()函数求出每行日期后面第三行的日期later3dt,同时用date_add()函数求出真正第三天的日期true3dt。第二步通过if函数判断两者是否相等来标记是否连续登录。第三步筛选出标记为 1 的记录,即连续登录三天的起始日期。第四步通过与一个包含 0、1、2 的数组进行笛卡尔积操作和date_add()函数计算出连续三天的日期。核心代码如下:
代码片段
建表
sql
create table user_log(
id int,
dt string
)
row format delimited
fields terminated by '\t';导入数据
sql
INSERT INTO user_log
VALUES
(1, '2024-04-25'),
(1, '2024-04-26'),
(1, '2024-04-27'),
(1, '2024-04-28'),
(1, '2024-04-30'),
(1, '2024-05-01'),
(1, '2024-05-02'),
(1, '2024-05-04'),
(1, '2024-05-05'),
(2, '2024-04-25'),
(2, '2024-04-28'),
(2, '2024-05-02'),
(2, '2024-05-03'),
(2, '2024-05-04');SQL如下
第一步
求解每行日期后面第三行的日期 lead()和 真正第三天的日期
sql
select*,
lead(dt,2) over(partition by id order by dt) later3dt,
date_add(dt,2) true3dt
from user_log;
第二步
判断是否连续登录三天
sql
with t as (
select*,
lead(dt,2) over(partition by id order by dt) later3dt,
date_add(dt,2) true3dt
from user_log
) select *,if(later3dt==true3dt,1,0) num from t;
第三步
筛选出连续登录三天的每个起始日期
sql
with t as (
select*,
lead(dt,2) over(partition by id order by dt) later3dt,
date_add(dt,2) true3dt
from user_log
) ,t1 as (
select *,if(later3dt==true3dt,1,0) num from t
)select * from t1 where num=1;
第四步
表合并求最终结果(和一个三行的表进行合并)(笛卡尔积)
sql
with t as (
select*,
lead(dt,2) over(partition by id order by dt) later3dt,
date_add(dt,2) true3dt
from user_log
) ,t1 as (
select *,if(later3dt==true3dt,1,0) num from t
),t2 as (
select * from t1 where num=1
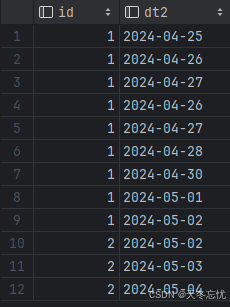
) select id, date_add(dt,d.list) dt2 from t2,(select explode(array(0,1,2)) list) d;
按照需求修改代码
sql
with t as (
select*,
lead(dt,2) over(partition by id order by dt) later3dt,
date_add(dt,2) true3dt
from user_log
) ,t1 as (
select *,if(later3dt==true3dt,1,0) num from t
),t2 as (
select * from t1 where num=1
) select id, date_add(dt,d.list) dt2 from t2,(select explode(array(0,1,2)) list) d;结果
四、总结
通过对这四道 SQL 题目的分析,我们可以看到在处理实际业务需求中的数据查询时,需要深入理解业务逻辑,构建合适的查询语句。对代码进行优化是提高查询效率和代码质量的关键,这包括合理使用数据库函数、优化连接条件和处理日期数据等方面。希望这些分析和建议能帮助大家在 SQL 查询中更加得心应手,写出高效准确的代码。