定义:二类分类 模型,定义在特征空间上的间隔最大的线性分类器
算法:求解凸二次规划(convex quadratic programming)的问题,也等价于正则化的合页损失函数的最小化问题
分类【由简至繁】:
- 线性可分支持向量机:训练数据线性可分时,通过硬间隔最大化
- 线性支持向量机:训练数据近似线性可分时,通过软间隔最大化
- 非线性支持向量机:训练数据线性不可分时,通过使用核技巧(kernel trick)及软间隔最大化
对于感知机算法来说因为采取随机梯度下降的优化方法,以及误分类点几何间隔最小化的策略,其结果为局部最优解,且不存在一个明确的目标函数去衡量超平面的好坏。这就导致其实存在多个超平面可以将数据集划分开,并不是最优超平面。
硬间隔支持向量机以此为切入点进行优化,通过间隔最大化的策略,希望在线性可分数据集中尽可能找到一个最优超平面或者是接近最优的超平面。
被分类点到超平面的距离我们可以称之为确信度,显然离超平面越远的点确信度越高,被误分类的概率越小,反之确信度最低的点就是离超平面距离最近的点。间隔最大化策略就是希望以尽可能大的确信度对训练数据分类,同时也保证离平面最近的点也能有足够大的确信度。
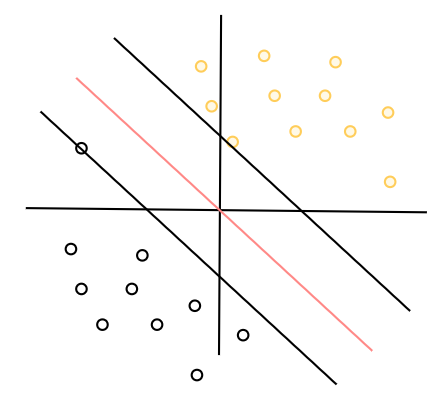
我们可以从上图,从分类结果直观的去感受硬间隔向量机,两个支持向量是离超平面距离最近的点,超平面取两个支持向量中间,同时保持距离两个支持向量的函数间隔是相同的,这样就能保证对于两个最容易分类错的点来说都达到了确信度最大。
输入:我们假设输入空间可以完全映射到特征空间,则特征空间为 { X 1 , X 2 , . . . X n } \{X_1,X_2,...X_n\} {X1,X2,...Xn}
输出: { + 1 , − 1 } \{+1,-1\} {+1,−1}
则几何间隔最大化问题可以抽象为一个约束最优化问题,及所有点到超平面的几何间隔尽可能大:
max γ = y ( ω T x + b ) ∥ ω ∥ 2 s . t . y i ( ω T x i + b ) ≥ γ ′ ( i = 1 , 2... m ) \max \gamma = \frac{y(\omega^T x +b)}{\Vert \omega \Vert_2} \\ s.t. \\ y_i(\omega^T x_i +b) \geq \gamma'(i=1,2...m) maxγ=∥ω∥2y(ωTx+b)s.t.yi(ωTxi+b)≥γ′(i=1,2...m)
首先简化这个优化问题,我们要先明确目标,我们的目标是为了求 ω , b \omega,b ω,b,且最大化几何间隔之间进行的是超平面的相对比较,而函数间隔并不影响,所以我们取 γ ′ = 1 \gamma' =1 γ′=1,则原问题转化为:
max γ = 1 ∥ ω ∥ 2 s . t . y i ( ω T x i + b ) ≥ 1 ( i = 1 , 2... m ) \max \gamma = \frac{1}{\Vert \omega \Vert_2} \\ s.t. \\ y_i(\omega^T x_i +b) \geq 1(i=1,2...m) maxγ=∥ω∥21s.t.yi(ωTxi+b)≥1(i=1,2...m)
那么为什么说函数间隔不影响呢?
1)从约束条件来看,因为超平面的 ω , b \omega,b ω,b与 γ ′ \gamma' γ′成比例放缩,放缩 γ ′ \gamma' γ′并不会影响到超平面的位置 2)其次对于目标函数来说,几何间隔其实是对点到超平面的距离进行了归一化处理,所以放缩函数间隔也不会影响到超平面在空间中的位置。 3)函数间隔本身代表的是的就是一种相对距离,其数值没有实际的几何含义。
从放缩结果来说,我们是固定了分子来进行分母的比较,这和感知机固定分母来进行分子比较的思想正好相反。
那么原问题求解 max 1 ∥ ω ∥ 2 \max \frac{1}{\Vert \omega \Vert_2} max∥ω∥21,其中的反比例函数并不适合我们进行分析和比较,则原问题可以转化为一个凸二次规划的优化问题:
P = min γ = min 1 2 ∥ ω ∥ 2 2 s . t . y i ( ω T x i + b ) ≥ 1 ( i = 1 , 2... m ) P=\min \gamma =\min \frac{1}{2}\Vert \omega \Vert_2^2 \\ s.t. \\ y_i(\omega^T x_i +b) \geq 1(i=1,2...m) P=minγ=min21∥ω∥22s.t.yi(ωTxi+b)≥1(i=1,2...m)
我们通过构建拉格朗日函数来求解,则原问题P转为拉格朗日最小最大问题:
P = min ω , b max α i L ( ω , b , α ) = 1 2 ∥ ω ∥ 2 2 − ∑ i = 1 m α i y i ( ω T x i + b ) − 1 α i ≥ 0 P = \min_{\omega,b} \max_{\alpha_i } L(\omega,b,\alpha) = \frac{1}{2}\Vert \omega \Vert_2^2 - \sum_{i=1}^{m}\alpha_iy_i(\\omega\^T x_i +b)-1 \\\alpha_i \geq 0 P=ω,bminαimaxL(ω,b,α)=21∥ω∥22−i=1∑mαiyi(ωTxi+b)−1αi≥0
显然函数满足Slater条件,则原问题转为对应对偶问题
P = max α i min ω , b L ( ω , b , α ) = 1 2 ∥ ω ∥ 2 2 − ∑ i = 1 m α i y i ( ω T x i + b ) − 1 α i ≥ 0 P = \max_{\alpha_i } \min_{\omega,b} L(\omega,b,\alpha) = \frac{1}{2}\Vert \omega \Vert_2^2 - \sum_{i=1}^{m}\alpha_iy_i(\\omega\^T x_i +b)-1 \\\alpha_i \geq 0 P=αimaxω,bminL(ω,b,α)=21∥ω∥22−i=1∑mαiyi(ωTxi+b)−1αi≥0
求内部的最小化问题,我们对 ω , b \omega,b ω,b求偏导等于0得到多元微分最小值的驻点:
∂ L ∂ ω = 0 → ω = ∑ i = 1 m α i x i y i ∂ L ∂ b = 0 → ∑ i = 1 m α i y i = 0 \frac{\partial L}{\partial \omega} = 0 \rightarrow \omega = \sum_{i=1}^m \alpha_ix_iy_i \\ \frac{\partial L}{\partial b} = 0 \rightarrow \sum_{i=1}^m \alpha_iy_i=0 ∂ω∂L=0→ω=i=1∑mαixiyi∂b∂L=0→i=1∑mαiyi=0
代入原式:
min ω , b L ( ω , b , α ) = 1 2 ∥ ω ∥ 2 2 − ∑ i = 1 m α i y i ( ω T x i + b ) − 1 = 1 2 ω T ∑ i = 1 m α i x i y i − ∑ i = 1 m α i x i y i ω T − ∑ i = 1 m α i y i b + ∑ i = 1 m α i = 1 2 ω T ∑ i = 1 m α i x i y i − ω T ∑ i = 1 m α i x i y i − b ∗ 0 + ∑ i = 1 m α i = − 1 2 ω T ∑ i = 1 m α i x i y i + ∑ i = 1 m α i = − 1 2 ( ∑ i = 1 m α i y i x i T ) ( ∑ i = 1 m α i x i y i ) + ∑ i = 1 m α i = − 1 2 ∑ i = 1 , j = 1 m α i y i x i T α j y j x j + ∑ i = 1 m α i \min_{\omega,b} L(\omega,b,\alpha) =\frac{1}{2}\Vert \omega \Vert_2^2 - \sum_{i=1}^{m}\alpha_iy_i(\\omega\^T x_i +b)-1 \\ =\frac{1}{2} \omega^T \sum_{i=1}^m \alpha_ix_iy_i -\sum_{i=1}^m \alpha_ix_iy_i\omega^T- \sum_{i=1}^m \alpha_iy_ib +\sum_{i=1}^m \alpha_i \\ =\frac{1}{2} \omega^T \sum_{i=1}^m \alpha_ix_iy_i-\omega^T\sum_{i=1}^m \alpha_ix_iy_i-b*0+\sum_{i=1}^m \alpha_i \\ =-\frac{1}{2} \omega^T \sum_{i=1}^m \alpha_ix_iy_i+\sum_{i=1}^m \alpha_i \\ =-\frac{1}{2}(\sum_{i=1}^m \alpha_iy_ix_i^T)(\sum_{i=1}^m \alpha_ix_iy_i)+\sum_{i=1}^m \alpha_i \\ =-\frac{1}{2}\sum_{i=1,j=1}^m \alpha_iy_ix_i^T\alpha_jy_jx_j+\sum_{i=1}^m \alpha_i ω,bminL(ω,b,α)=21∥ω∥22−i=1∑mαiyi(ωTxi+b)−1=21ωTi=1∑mαixiyi−i=1∑mαixiyiωT−i=1∑mαiyib+i=1∑mαi=21ωTi=1∑mαixiyi−ωTi=1∑mαixiyi−b∗0+i=1∑mαi=−21ωTi=1∑mαixiyi+i=1∑mαi=−21(i=1∑mαiyixiT)(i=1∑mαixiyi)+i=1∑mαi=−21i=1,j=1∑mαiyixiTαjyjxj+i=1∑mαi
则对结果取反,原问题可以转为:
min 1 2 ∑ i = 1 , j = 1 m α i y i x i T α j y j x j − ∑ i = 1 m α i s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2... m \min\frac{1}{2}\sum_{i=1,j=1}^m \alpha_iy_ix_i^T\alpha_jy_jx_j-\sum_{i=1}^m \alpha_i\\ s.t. \\ \sum_{i=1}^m \alpha_iy_i=0,\alpha_i \geq 0,i=1,2...m min21i=1,j=1∑mαiyixiTαjyjxj−i=1∑mαis.t.i=1∑mαiyi=0,αi≥0,i=1,2...m