
时序数据库 IoTDB 应用于宝武集团全基地钢铁时序数据管理,激活数据资产,赋能大型设备智能运维。
1. 背景概述
宝武装备智能科技有限公司(以下简称:宝武智维)是中国宝武设备智能运维专业化平台公司,30 余年始终专注于钢铁行业设备技术服务,逐步打通检测、诊断、检修、制造等设备服务环节,形成系统解决方案服务模式,希望为用户提供稳定可靠、智能高效的设备运行保障。
随着工业物联网的迅速发展,面向钢铁领域设备的智能运维 成为大数据、人工智能等先进技术重要的应用方向之一。钢铁产线设备大型化、复杂度高,设备之间相互耦合,现场问题定位和修复难度非常高 。同时,钢铁设备通常处于连续运转状态,出现异常对于产线产能影响可观,实现设备的实时性、预防性维护对于保障产线效能、实现企业降本增效均十分重要。
为实现钢铁产线设备智能运维这一项极具挑战的复杂系统创新工程,宝武智维基于海量工业时序数据积累及其丰富的应用场景,自主构建具备低成本、大规模接入能力的设备远程智能运维平台 ,并于 2023 年全面融合国产时序数据库 IoTDB,作为该平台管理宝武全集团时序数据的核心组件。
通过 IoTDB,宝武智维得以"激活"时序数据价值,大幅提升宝武集团、基地侧智能化数据写入、存储、分析、传输性能,并为下游设备故障排查业务场景提供了坚实的数据支撑,形成了面向钢铁全流程,一个平台、一个专家系统、一套标准化体系的智能设备运维新模式。
2. 选型痛点
在全面接入 IoTDB 之前,宝武智维已经经过多年探索,并使用基于 Hadoop 的 HBase 和 OpenTSDB 作为钢铁设备的时序数据管理架构。业务初期,该架构应用效果较好,但随着更多数据量的接入,其慢慢成为了制约发展的底层瓶颈,主要体现在两个大方面:"慢"和"难"。
- **写入慢:**常规情况下,旧版架构勉强能够达到写入性能要求,但后续业务的扩张伴随设备、数据量的激增,结合基地网络资源的有限性,写入性能逐渐捉襟见肘。如果碰到网络断线等异常场景,往往大量消息、数据出现堵塞,网络恢复后需要快速地进行消费,但旧版架构也无法支撑消费速度要求。
- **查询慢:**宝武集团查询数据跨度可能以年为单位,并要求大跨度数据实现查询秒级响应,而在数据量增加后,旧版架构仅能实现 5-30 秒内返回,对于业务平台使用效果与实时监控设备状态的目的实现存在较大影响。
- **加工慢:**数据写入存储后,需要使用聚合函数等方法实现多类数据加工,但基于旧版架构其速度非常有限,且很容易导致整体数据架构不稳定。
- **抽取慢、汇聚难:**当进行集团-基地数据资产整合时,往往需要不断地将基地存储数据抽取至集团侧。旧版架构对于数据的实时传输支持不足,对持续的传输过程稳定性影响较大。
- **清理难:**基于旧版架构的数据清理、删减主要依靠 TTL,过程复杂且灵活度较低。宝武集团实践时,曾出现磁盘将满情况下,定好的数据需要写程序进行导出,再导回系统的情况,数据运维工作十分繁琐。
- **备份难:**庞大的数据体量下,基于旧版架构的策略化备份实现非常困难,基本无法备份,只能选择部署 3 节点集群以响应备份需求。
耗费大量成本获取的海量高价值数据,却变成了深不见底的数据黑洞。随着数据量不断增长,运行效率却无法提升,数据反而成为拖累,下游应用系统、团队的施展空间很低,无法将数据价值真正转化为业务价值。

因此,宝武智维的时序数据库选型标准可以概括为:
-
能够写入海量并发数据;
-
能够用更低成本存储全量数据、高频数据;
-
能够实时查询、分析数据,实现高效的数据清理与备份;
-
能够实现集团侧-基地侧数据实时同步、汇聚的易用方案。
3. 部署方案
2023 年开始,IoTDB 全面替换 OpenTSDB ,成为宝武集团时序数据湖的数据底座。运用 IoTDB 为时序数据管理核心的宝武智维云平台 ,已部署至宝武集团全部生产基地,并逐步扩展至集团外,负责接入宝武全集团所有基地内的所有设备数据,并进行在线状态监测与设备智能运维业务。
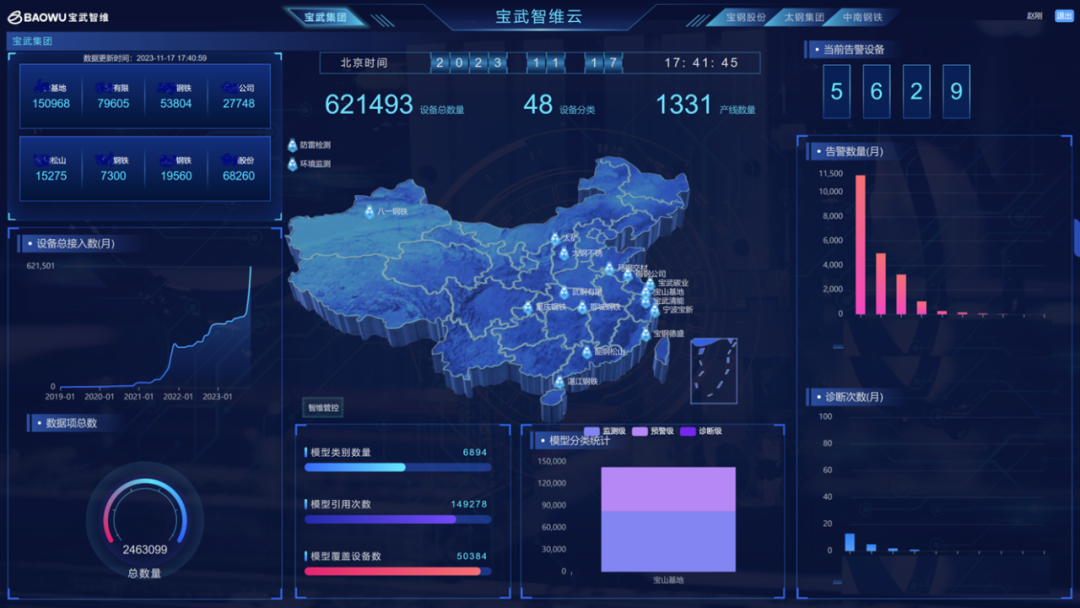
目前,宝武智维云 全面 覆盖宝武集团 21 大生产基地,接入 27 个子平台、60 万以上设备、240 万以上数据项,总数据量超 5 PB。平台配置规则超 10 万条,已沉淀智能模型超 40 大类,平台用户数超 1 万。
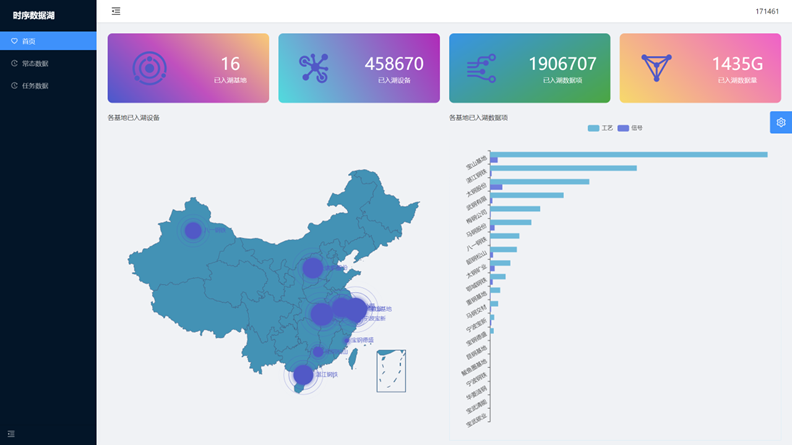
从以 IoTDB 进行重构的全新架构来看,宝武超大规模分布式数据湖由1 个 E4-IoTDB 集团数据湖和 N 个 E3-IoTDB 基地数据湖 集群组成。多个 E3-IoTDB 基地数据湖负责存储管理该基地的设备数据,而宝武集团层的 E4-IoTDB 数据湖主要覆盖常态数据的降频存储和故障相关数据的原始频率存储 。同时,集团层可以通过下发任务方式,从各个基地抽取所需数据并进行存储,用于模型训练及定制化数据任务。
宝武集团与基地之间的数据同步方式目前有两种。第一种为通过 Pipe 使用 IoTDB 自研的时序数据标准文件格式 TsFile 进行高效传输,不需要数据的重新组织和重复写入,可实现数据端到端的直接使用。另一种为使用全贯通的 Kafka 数据总线进行数据上传,能够满足宝武各基地及集团的数据防火墙传输要求。

实现数据的高性能写入、存储,并打通数据抽取、传输链路后,宝武集团成功构建了 E4 集团数据湖与 E3 基地数据湖。集团数据湖包括一个主库、N 个功能库和一个备份库,功能库又包括故障特征库与 AI 训练库 。故障特征库包括所有基地的设备故障特征,各基地一天几十条至几百条不等的故障事件所涉及到的相关数据均会上传并进行存储,方便集团集中分析故障趋势与原因。各基地数据湖则包括一个主库、一个功能库和一个备份库,功能库主要做为同步库使用。
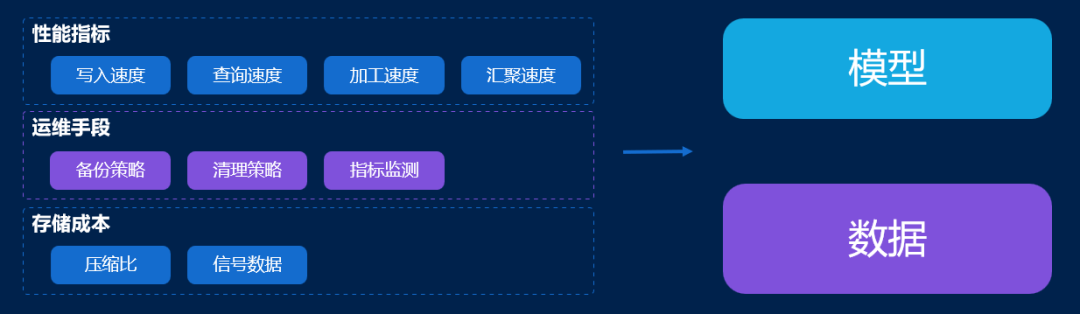
使用 IoTDB 后,宝武集团时序数据管理效果提升非常明显,实现性能提升 1 个量级,存储成本大幅下降,运维手段丰富,数据资产汇聚,AI 模型训练加速等有效成果。
存储成本方面,通过实践,基于 IoTDB 可实现 10 倍数据压缩比,并能够用少量服务器存储集团规模数据。对于钢铁领域最重要的数据类型之一------信号数据的存储成本也得到大幅降低。
运维手段方面,相比旧版架构僵化、暴力的数据清洗处理方式,宝武集团成功基于 IoTDB 实现备份、清理的灵活策略化,能够积累丰富的指标、监测信息,帮助运维人员实现对设备状态的更好理解。
性能指标方面,IoTDB 写入速度可实现千万点/秒 ,可以长时间稳定写入高频数据;基地上报的秒级数据及边缘侧上报的毫秒级数据,一年数据量查询可实现秒级返回 ,并能够覆盖长达十年、数百万点的设备数据降采样分析,性能获得用户认可。同时,IoTDB 提供了丰富的聚合函数,有效拓宽宝武集团的数据加工场景,加速原始数据加工,并通过上述数据传输方案提升数据汇聚速度,方便数据真正形成模型,实现规模化运用。
与前文中的选型要求对照可见,IoTDB 在写入、存储、查询、分析、运维、汇聚等方向,均契合了宝武智维的时序数据库选型标准,从根源处解决了 OpenTSDB 与 HBase 架构的多个性能与功能实践痛点。
4. 应用场景举例
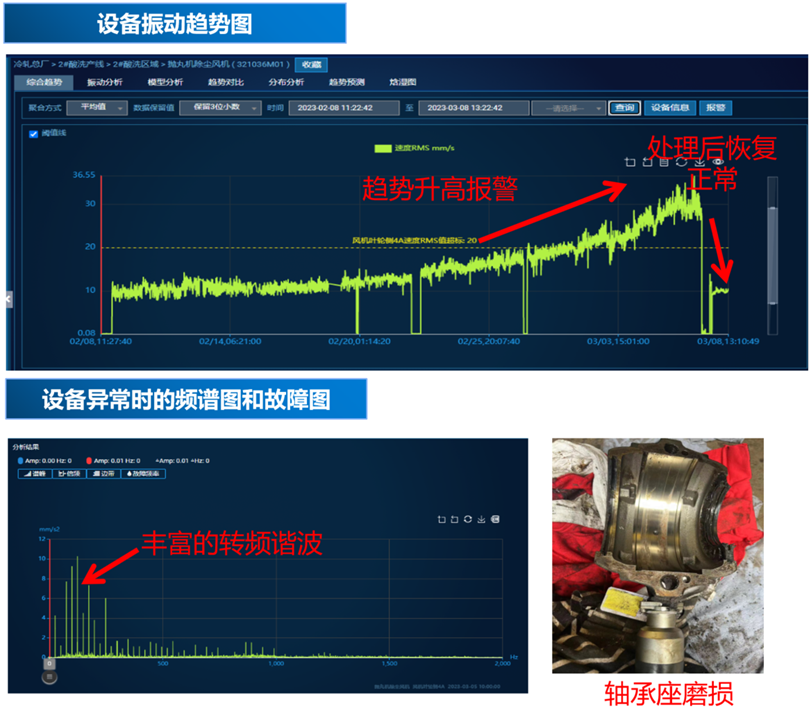
场景一:波形信号数据处理
钢铁行业中,设备实时上报的振动波形数据 是最可靠的时序数据资产之一,能够有效反映设备的运行状态。宝武集团的振动波形数据一般分为两类,一类是通过 PLC、DCS 采集上报的工艺量数据 ,一类是通过加装大量传感器 ,如温振传感器采集上报的振动波形数据。各类传感器安装数量庞大,因此后一类数据的体量十分可观。
旧版架构中,以上两类数据基本通过对象存储方式存入 HBase,存储量占比在某些基地达到 1:20。一个基地的数据中,20 份为振动数据,1 份为工艺量数据,可见振动传感器上传的时序数据体量十分庞大,存储管理的成本,以及后续使用处理的难度可想而知。
引入 IoTDB 之后,参考 IoTDB 团队所在的天谋科技技术人员的建议,宝武智维不再将振动波形数据作为对象进行存储,而是直接将数据拆散之后,以纳秒级精度存储到 IoTDB ,这样能够有效提升该类数据的存储压缩比 ,大幅降低其存储成本。同时,存储模式发生变化后,应用模式也随之发生变化。宝武智维可以直接在 IoTDB 层面对振动波形数据进行处理 ,为后续的数据加工工作提供了有力支撑。宝武智维表示该项改良是"非常颠覆性的设计"。
场景二:结合 AI 的创新应用
IoTDB 有效解决了数据的抽取、存储、处理、上传问题后,丰富的时序数据资产被彻底激活,宝武智维也就能够拓宽目前应用数据的模式与发展空间。其 AI 团队成功从"找数据"改变为"要数据",能够发散更多有想象力的创新应用场景,面向多设备、长周期数据进行进一步归纳与分析。衍生场景包括但不限于:
- **通用数据集的自动构建、自动标签化:**基于反馈(误报和漏报) 和闭环进行标签化。
- **同类故障的数据集的构建:**故障记录和多源数据的匹配映射,基于故障记录和故障匹配的数据对故障类型、故障程度进行标签化。
- **同类设备的数据集的构建:**同类设备数据的归并和映射,基于设备基准、设备参数信息,对同类、同部件同型号进行匹配和标签化。
- **振动信号的特征提取:**时域信号分段特征的提取、长周期信号特征的提取、频域特征的提取。
- **趋势特征的提取:**长周期数据特征的提取,月度或年度数据特征的提取;生产周期的划分,周期性生产过程特征的提取。
- **数据对齐和数据融合:**工况数据的匹配,多源异构数据(时序、文本、人工输入数据)的匹配。
- **文本对象数据集的构建:**文本数据信息的抽取、实体的匹配。
- **AI 平台与 IoTDB 的双向通讯:**数据集映射、抽取至 AI 平台,实现存储处理与深度分析的一体化融合。
5. 未来展望
宝武智维计划未来在与 IoTDB 深度融合的更多方面进行研究,包括但不限于:
- 视图功能: 切实结合业务需求,实现测点数据扁平化。围绕生产、质量、运维等不同角度,结合 IoTDB 自带的时序数据树状模型 ,运用视图功能组织、复用数据资产,从业务方向组织成不同视角的数据树状架构,进一步降低团队运维学习成本。
- 中台功能: 基于 IoTDB 进行通用数据 API 与专用数据 API 的研发,形成数据资产管理,并在该数据中台之上进行 APP 轻量化,以及数据可视化的自主探索。
- UDF 函数: 目前,IoTDB 主要用于构建宝武智维平台中的数据存储、处理底座,未来希望针对振动波形、信号数据、长周期趋势分析等关键场景,通过研发 UDF 自定义函数并内嵌至数据湖中,替代原有的外挂 Python 程序调用,结合数据 API、AI 模型,全面提升宝武集团工业数据应用分析能力。
- AINode: 通过引入IoTDB 内生支持的机器学习智能节点,替代原有的数据再抽取、单独外部训练模式,支持使用已有模型直接在 IoTDB 内部进行推理,针对钢铁领域数据预测、异常检测等方面进行预制模型训练和加载,达到无需导出数据,直接使用内置模型进行数据推理的目标,实现端到端的数据深度分析。
以数据为牵引,以平台化为手段,IoTDB 将继续与宝武智维深度合作,更好地串联产业链上下游数据资源,共建钢铁生态圈智能运维服务生态,让数据赋能钢铁产业价值。
更多内容推荐:
• 了解更多 IoTDB 应用案例