继The Information周日文章说Pre-Train模型的预训练"撞墙"了,近日Ilya Sutskever与SSI(Safe Superintelligence)接受路透采访,亦提出了类似观点:使用大量未经标记数据来训练(学习)语言模式和结构的AI模型已经停滞不前,即"传统的无监督Pre-training已达极限"。

可以说我们自经历了2010年以来的scaling时代后,当下正在经历下一个持续探索与发现的时代。
不过,Ilya暂未透露他和团队如何解决或应对这一问题的更多细节,只表示SSI正在研究一种替代方法来扩大预训练规模。
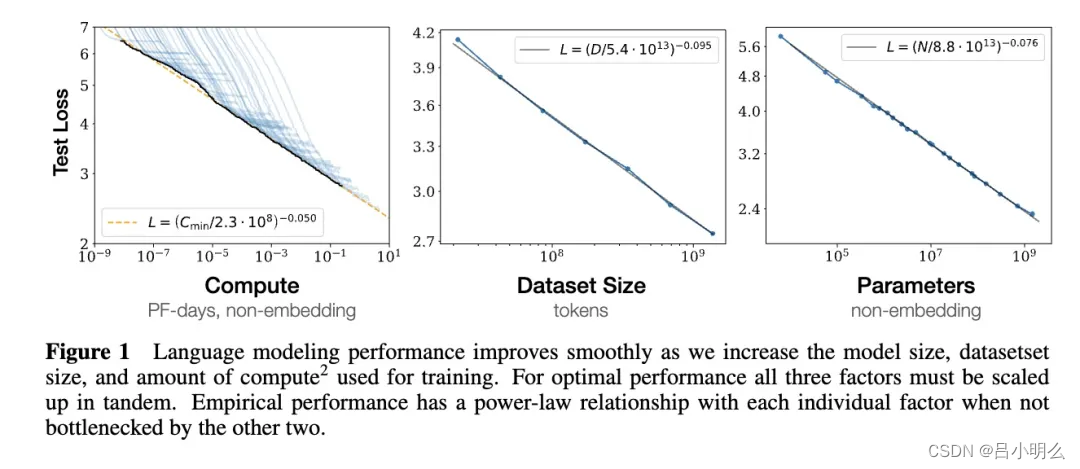
我们知道,OpenAI o1的发布似乎预示着"test-time compute作为一个新approach在尝试重构scaling law体系,然而这种new scaling与之前对应的train-time不管在思想内涵还是方法框架上我想还是存在着一些差异,当然他们背后对于在认知&推理模式的本质上存在着底层深刻联系。
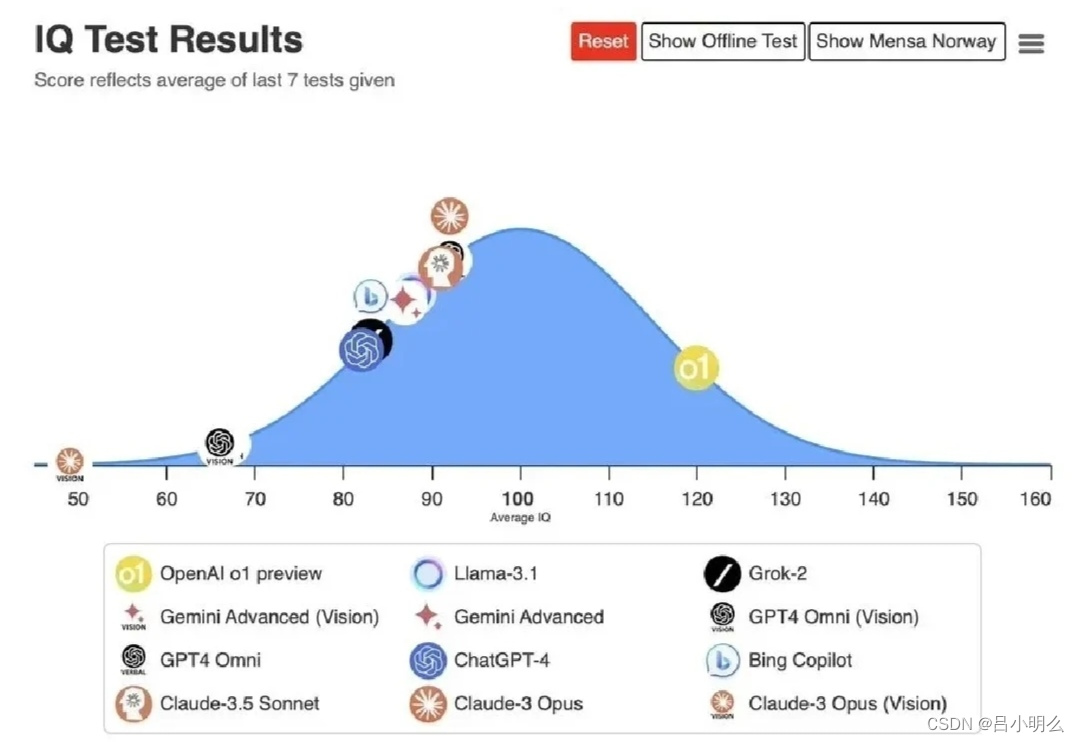
熟悉我的小伙伴之前应该在读到了我多篇关于OpenAI o1的观点笔记、以及今年初提出的LLMs×RL融合思想的观点文章、再到对来自国内外智谱、清北、Google、Meta、MIT、Stanford等多家研究机构近期连续发表的多篇关于RL基于CoT嵌入LLMs pre-train的创新思想或框架方法的解读中,可以窥见我的一些也许并不成熟或完备的核心观点与思想。

包括自己最近两周在精读、细品、重温一些经典论文中,也进一步印证了自己曾经的某些观点以及尝试理解了其中一些底层更深刻的内涵。
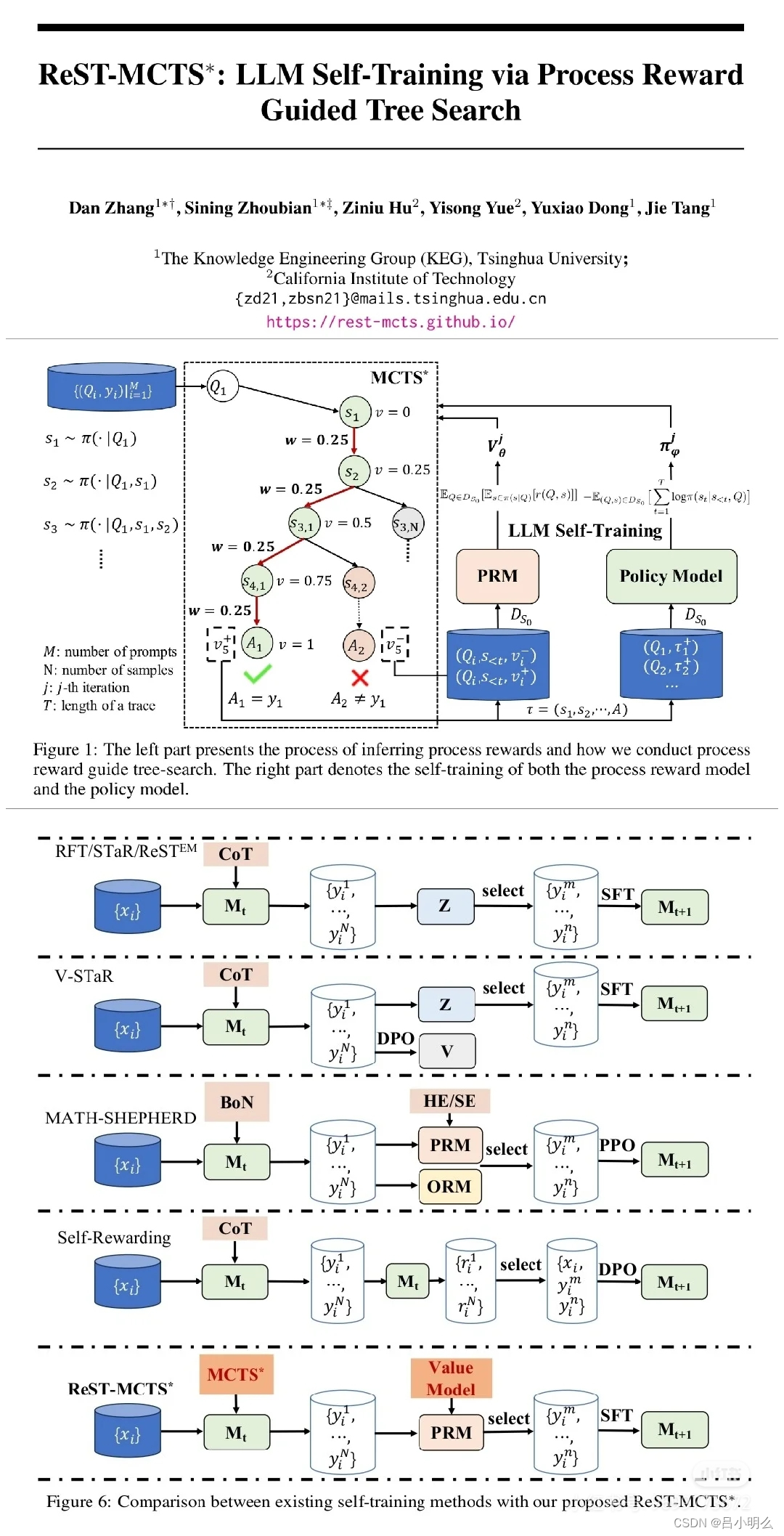
如上周记录的"重温清华KEG的ReST-MCTS*及延伸思考"观点笔记中所提出的一些关于对RL self-play过程中的探索与利用、奖励验证、形式化体系及模型在庞杂的泛化空间穿梭下的些许深刻思考..
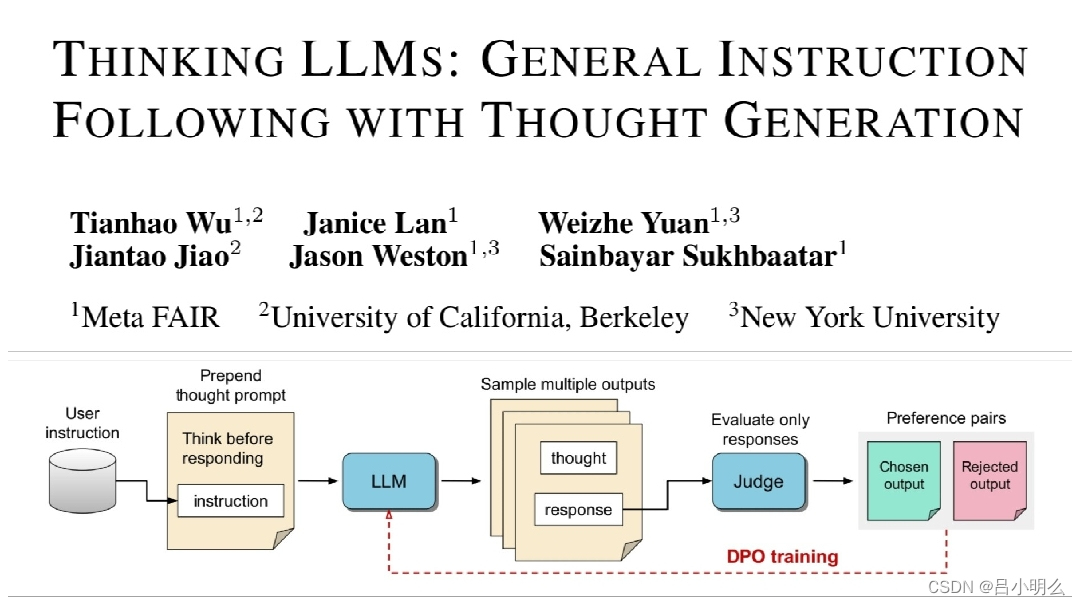
再如上个月来自对Meta的那篇TPO框架的延展思考中与今年早期自己对"模型参数化隐式训练与推理" vs "类o1的test-time compute或multi-agent"两者间背后深刻内涵联系与底层本质的思考..
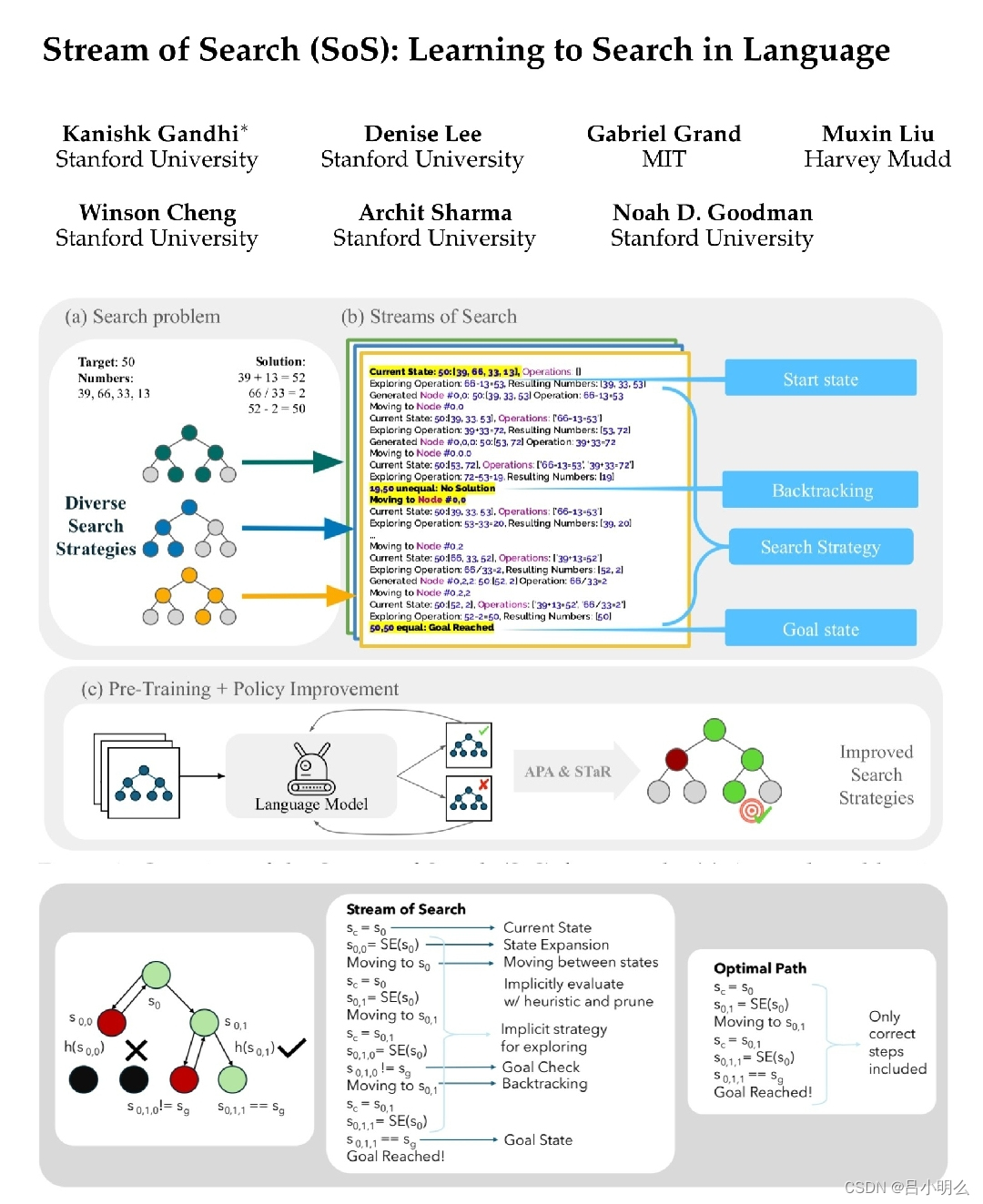
以及昨天在重温Stanford&MIT更早期探索的SoS框架中自己对形式化本质的思考..
正如昨日在学术讨论群中朋友@我对于近期事件看法与观点时我回答那样:
"我觉得还是类似猜测中的o1老路线,也许找到了继续扩大预训练规模的新方法或找到复杂推理泛化数据分布的密码,比如建立了一个相对完备的框架,找到了对更通用泛化rl过程中探索与利用的平衡及self verify。"