作者:宋大宝,与大宝同学因那篇《回顾·总结·展望「融合RL与LLM思想,探寻世界模型以迈向AGI」》结识于今年春天,虽我们当时某些思想观念有些出入,也碰撞出了很多火花与共鸣,并持续地相互启发的走到了现在。他是AI领域创业先行者,拥有着令人惊艳的的思想观念,博学多才,被我誉为百科全书式AI探索者,貌(确)似(实)近期在内容输出上有压倒我之势~哈哈,这篇2万字+文章即是他近期的在更大的宏观叙事上的思考与观点之作,先分享给大家,后续有时间的话我会针对部分内容再做一番自己的理解和思考延展。
另外,作为对本篇宏观叙事上的对照,也再次分享给更多的伙伴们我之前"微观"视角下的一些在Scaling law、RL×LLM、AGI、认知推理等相关领域延展性思考文章:
-
回顾·总结·展望「融合RL与LLM思想,探寻世界模型以迈向AGI」
-
对于Ilya当下Scaling law瓶颈观的思考
-
世界模型融合与统一深度思考:自回归与扩散生成
-
回顾半年前AGI思考探究过程中的意义、价值与乐趣 Ⅰ
-
回顾半年前AGI思考探究过程中的意义、价值与乐趣 Ⅱ
-
Think | AGI的探索(Axplore)与对齐(Align)
-
初探 system Ⅱ · 慢思考
-
这届物理与化学诺奖对S2AI&AI4S的启示
-
谷歌DeepMind新RL方法·SCoRe,让我后背一紧
-
当下OpenAI o1机理与内涵的回顾与再探索
-
OpenAI o1:隐含在训练与推理间的动态泛化与流形分布
-
OpenAI o1碎片化过程中的探索与利用的泛化
-
Nature: 多智能体隐层表征通信下的语言结构涌现及演化
-
大模型×认知科学:多维潜空间洞悉复杂认知
-
大模型→世界模型下的「认知流形」本质·上
-
大模型→世界模型下的「认知流形」本质·下

正文如下:
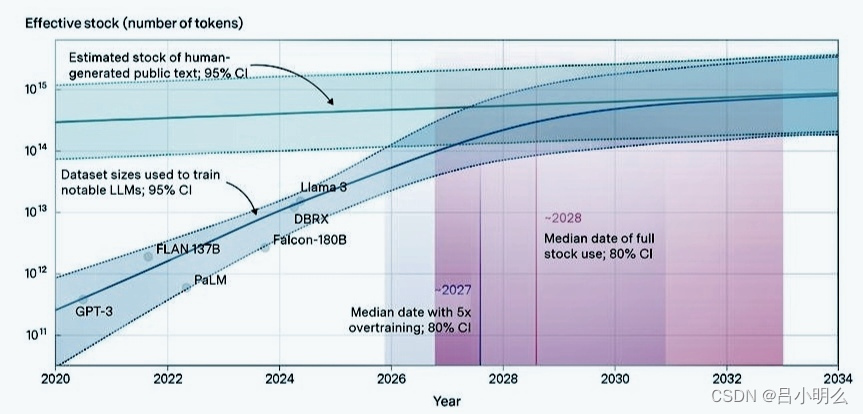
近段时间来,围绕大模型扩展和低精度训练的技术讨论愈演愈烈,最新的
《Scaling Laws for Precision》一文更是点燃了AI社区的广泛热议。然而,关于Scaling Law是否已"破壁"或"终结"的说法,我认为这只是媒体一厢情愿的炒作。真正的情况远非如此简单,我们需要在更深层次上理解Scaling Law的本质,以及当前技术发展的真实方向。作为长期关注开源AI生态的研究者,我想以更为理性的视角,重新审视这一现象背后的核心问题。
一、Scaling Law的本质:工程实践与理论创新的动态平衡
当我们深入探讨Scaling Law的演进,不能忽视其与计算范式转变的深层联系。目前业界普遍关注的是模型规模与计算效率的权衡,但实际上,真正的突破点在于**计算范式的革新**。从Google的PaLM到Anthropic的Claude系列,这些大模型的扩展过程都展现出一个关键现象:当模型规模达到一定程度后,其能力提升不仅来自于参数规模的增长,更多地体现在**架构适应性**和**计算效率**上。
Scaling Law并非什么"绝对的科学定律",而是行业在长期工程实践中总结出的**经验法则**。正如摩尔定律预测了晶体管密度的指数增长,Scaling Law也为大模型的性能提升提供了指导。然而,与摩尔定律一样,Scaling Law并不是永恒不变的真理,而是在现有技术条件和资源约束下的最优实践。
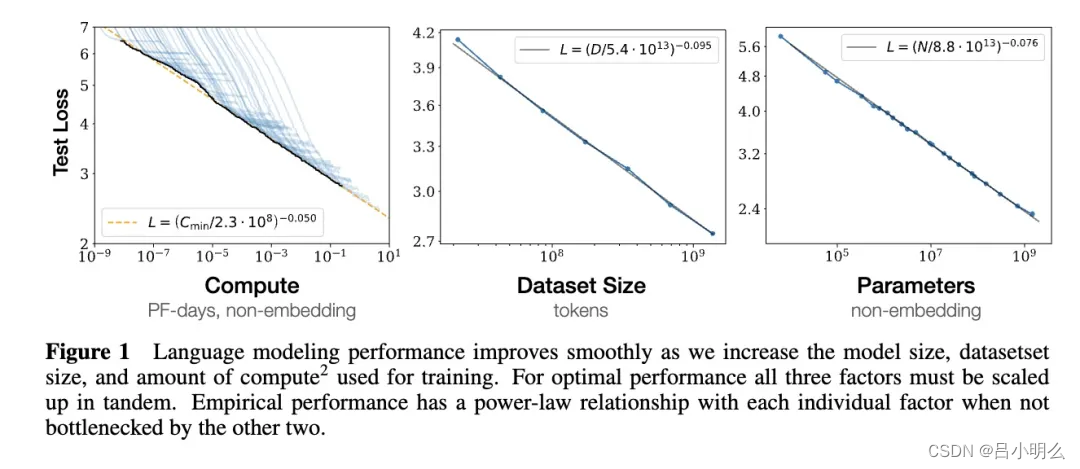
特别值得注意的是:在当前算力受限的背景下,我们观察到一个有趣的现象:一些相对"小型"的模型(如70B量级)通过优化架构和训练策略,在特定任务上已经能够接近甚至超越更大规模模型的性能。这说明模型规模与实际性能之间的关系正在发生质的改变,我们需要建立新的评估框架来描述这种复杂的关系。
事实上,开源社区的丰富实践已经证明,许多理论突破往往源于大规模工程中的**异常发现**。例如,Chinchilla定律正是OpenAl和DeepMind等团队在探索更高效的训练策略时,基于真实数据和实践得出的新规律。开源社区通过群体智慧、共享实验数据和反馈,帮助验证和调整这些经验法则。这并不意味着Scaling Law已"终结",而是进入了**效率递减的调整期**。这不是一场"危机",而是AI技术演进的必经阶段。
二、硬件约束与算法创新:协同演进的必然选择
要理解Scaling Law的调整,我们必须正视当前AI领域面临的**物理与硬件限制**。摩尔定律的增速放缓、晶体管尺寸的物理极限、能耗的不断增加,都在限制我们通过单纯扩展硬件能力来提升模型性能的路径。因此,单一依赖低精度量化(如8-bit、4-bit)来提升效率的做法已经近乎触顶。在大模型训练中,我们越来越清楚地看到,**降低精度会带来性能损耗**,尤其是在大规模数据集和更复杂的推理任务上。
临界动力学假说:系统的最佳计算能力可能出现在有序和混沌的临界点附近。这可以解释为什么某些规模的模型会表现出特殊的能力。
多尺度动力学:不同的认知功能可能对应着系统在不同时间和空间尺度上的动力学行为,这解释了为什么某些能力会在特定规模突然出现。
非平衡态计算:模型的计算过程可以被理解为一个非平衡态系统,这为理解涌现行为提供了新的视角。
相变理论的应用
在这个理论框架下,我们可以用相变理论来描述模型的能力演进:
序参量的识别:通过识别关键的序参量,我们可以预测系统何时会发生质变。这为预测涌现能力提供了理论基础。
临界指数:不同类型的涌现能力可能对应着不同的临界指数,这解释了为什么不同能力有不同的规模阈值。普适性类:可能存在某种普适性类别,使得不同架构的模型在大尺度上表现出相似的行为。
信息几何的视角
从信息几何的角度,我们可以得到新的理解:
参数空间的曲率:模型的学习过程可以被理解为在一个黎曼流形上的优化问题。曲率的变化可能与模型能力的突变有关。
信息瓶颈理论:通过分析信息流的压缩和扩展过程,我们可以更好地理解模型的表征学习机制。
几何约束:某些架构限制可能来自于参数空间的几何性质,这为设计新架构提供了理论指导。
计算复杂性的重新思考
在这个框架下,我们可以重新审视计算复杂性问题:
动态复杂度:系统的有效计算复杂度可能是动态变化的,这为突破现有复杂度限制提供了可能。
多尺度计算:通过在不同尺度上组织计算,可能找到降低整体复杂度的新方法。
量子类比:某些量子计算的概念可能为设计新的计算范式提供启发。
站在技术演进的临界点上,专注技术本质可能比追逐表层创新更有意义。基于开源社区多年的实践经验,我认为真正的技术突破将发生在计算范式的根本性重构上,而不是渐进式的优化改良。首先需要重新思考神经网络计算的本质。当前主流架构,无论是Transformer还是其衍生变体,本质上都是
以LLaMA系列的演进为例,我们可以清晰地看到开源社区推动技术革新的轨迹。从最初的参数规模竞赛,到后来的指令微调优化,再到现在的多模态融合,每一步都体现了开源社区的集体智慧。特别是像vLLM、FastChat这样的开源项目,正在探索如何在有限算力下最大化模型性能,这些尝试正在重新定义我们对Scaling Law的理解。
在实际部署中,混合精度训练(Mixed Precision Training)配合动态量化策略的应用,展现出了突破性的效果。例如,在处理注意力计算时,我们可以根据不同层的敏感度采用不同的量化策略,这种"精细化"的优化方案正是突破当前瓶颈的关键。那么,出路在哪里?答案在于硬件和算法的协同演进。在现有的硬件条件下,我们需要**重新定义计算架构和优化算法**。混合精度训练、稀疏化技术
(如Mixture of Experts)、模块化架构等技术,正为我们开辟新的优化路径。这不仅是硬件和算法的优化,更是**系统架构的整体革新**。
三、经济学视角下的Scaling Law边际效益递减与资源配置困境
近期llya Sutskever在采访中指出,预训练(Pre-Train)模型的边际效益已经逐渐趋于递减,引发了更广泛的思考:大模型训练的经济效益是否已经走到了尽头?要理解这一问题,不能仅仅停留在技术层面,而需要从经济学的视角深入分析。预训练模型所面临的"撞墙"现象,其实反映了更深层的经济问题,包括边际效益递减、资源错配以及市场竞争格局的转变。
AI社区对预训练模型的执着扩展,正在陷入典型的"资本密集型陷阱"。根据经济学理论,当一个行业对生产要素(如算力、数据、资金)的投入过度依赖时,其边际收益将逐渐递减。早期GPT系列模型确实通过参数和数据的扩展,显著提升了自然语言处理的能力。然而,随着模型参数规模的进一步扩大,性能增益却呈现出逐渐趋缓的趋势。
从经济学中的投入产出分析来看,当前预训练模型的扩展已进入边际效益递减的阶段。大量算力和资金的投入仅能带来微小的性能提升,甚至不足以覆盖其高昂的训练成本。例如,训练一个10万张GPU卡的集群,每月的沉没成本可高达1亿美元,然而带来的性能提升却远低于预期。这种现象表明,单纯依赖模型规模的扩展已不再具有长期的经济合理性。
从资源经济学的视角来看,AI行业对超大规模模型训练的过度投入,实际上正在加剧资源配置的不平衡。大量资金和算力被集中在预训练模型的扩展上,而这导致其他具有潜力的技术方向如强化学习
(RL)、符号推理、因果建模等被忽视。这种资源错配,不仅限制了技术创新的多样性,也导致了整个产业链的效率低下。
"机会成本"的概念在这里显得尤为关键。当前,AI研究的资本密集化使得资源被锁定在大模型参数扩展的竞赛中,而这无疑牺牲了对更具创新潜力的技术的投入。例如,近期有消息指出,OpenAI已将其算力的重心转向强化学习后训练(RL Post-Train),因为在相同资源下,RL Post-Train能带来更高的边际收益。这种策略上的调整,反映了行业内对更高效的资源利用和技术路径的重新评估。
AI技术的"预训练"路线不仅在经济上面临边际效益递减的问题,还正在导致市场竞争格局的重塑。当前的预训练竞赛主要由少数具备雄厚资本和计算资源的科技巨头主导,而中小型企业则面临资源和技术门槛的双重挑战。这种趋势使得市场逐渐向寡头垄断方向演变。根据经济学理论,市场垄断会抑制创新活力,降低整体市场的效率。而在AI领域,这种垄断将加剧技术路径依赖,进一步固化现有的大模型架构,阻碍颠覆性技术的涌现。
扎克伯格、Dario Amodei等业内领袖多次强调Scaling Law并未放缓,然而背后的战略考量可能更多是为了维持市场领导地位。相反,微软CEO Satya Nadella则公开表示,预训练语言模型已经"商品化",未来的重点应是如何基于现有模型实现更高效的智能应用。这一论断揭示了当前预训练技术的局限性:模型扩展虽然重要,但其边际收益已经不足以支撑持续的巨额投入。
当前的大模型训练还暴露了能耗和环境外部性的问题。巨大的算力需求导致高额的电力消耗,训练和推理过程的能源消耗已经对环境产生了负面影响。在经济学中,这被称为"负外部效应",即企业在追求自身利益最大化的过程中,对社会整体福利造成潜在的损害。随着全球对可持续发展的关注,AI行业的这种高能耗发展模式显然与之背道而驰。
从算力基础设施的经济学视角来看,尽管预训练模型的扩展需要大量的GPU,但也开始显现出新型架构的需求。传统的超大集群面临扩展瓶颈,而分布式集群和更灵活的算力架构(如Nvidia的BG2、超节点和superchip)正在崭露头角。这表明,未来的技术演进将不再依赖单一的超大规模算力集群,而是通过更灵活、更高效的资源利用方式来实现同样的计算目标。
当前AI社区围绕预训练模型的扩展遇到了经济上的瓶颈,而这种瓶颈不仅反映了边际效益递减的经济规律,更揭示了技术路径依赖和市场垄断所带来的深层问题。在这种背景下,未来的技术创新不应再单纯依赖大模型规模的扩展,而是应通过更精细的资源配置和更具多样性的技术路径来实现突破。
lya的"舍生一击"---未来到底应该去scale什么因子------恰恰道出了AI产业发展的关键命题。预训练、强化学习、推理优化乃至多模态融合,这些技术方向都有可能成为未来的突破点,而不再仅仅局限于参数规模的扩大。开放的市场竞争和多元化的技术创新,才是推动AI持续进化的根本动力。
当下的AI技术进化,已不再是单纯的"算力堆砌"和"参数扩展"的竞赛,而是一场更深刻的经济和战略再平衡。Scaling Law的边际效益递减,预示着预训练模型已经达到瓶颈,而行业的重心将转向更高效的资源利用和更具颠覆性的技术探索。在有限的资源和日益严峻的市场竞争环境中,AI企业应当重新思考其技术路线,以确保在下一轮技术浪潮中占据主动,由此可见,在算力成本和市场竞争的双重压力下,大家就得八仙过海各显神通,Scaling Law的边际效益递减并不意味着预训练的终结,而是呼唤更灵活、更具经济效益的创新方式。
四、Agent系统的未来:技术突破与深层反思
在大模型井喷式发展的2024-2024年,Agent系统已成为AI领域炙手可热的技术方向。承载了一定程度的算力经济学,作为一线的开源实践者,我认为当前对Agent的狂热中存在着诸多盲目性。表面上看,Agent通过模块组合和工具调用带来了AI交互范式的革命性转变,但深入技术内核,会发现这种创新很大程度上仍是表层的。这种表层创新固然为AI的应用带来了巨大便利,但也掩盖了底层技术栈中诸多亟待解决的根本性问题。
当回溯Agent技术发展的历程,不难发现一个有趣的现象:最初的Agent框架大多建立在简单的prompt编排和API调用基础上,这种架构在处理单一领域的特定任务时确实展现出了令人惊艳的效果。但随着应用场景的拓展和任务复杂度的提升,这种简单的架构开始显露出其局限性。特别是在处理需要深度推理、多轮交互和跨域协同的复杂任务时,现有Agent架构的脆弱性愈发明显。这种脆弱性不仅体现在任务完成的稳定性和可靠性上,更反映了当前Agent系统在认知架构层面的根本性不足。
1.架构创新的局限性
目前大多数Agent系统本质上还是在LLM基础上叠加了任务分解和工具调用层。虽然这种模式确实提升了AI系统的问题解决能力,但从技术本质看,这种"拼接式创新"存在明显的局限性:
推理能力的瓶颈:当前Agent的推理链路高度依赖LLM的in-context learning能力,缺乏真正的符号推理和因果理解
上下文隔离问题:多轮对话中的状态管理和上下文维护仍然是一个未解决的技术难题
工具调用的不确定性:缺乏可靠的执行验证机制,难以保证复杂任务的稳定性
2.涌现能力的迷思
业界普遍认为Agent系统通过组件组合产生了某种"涌现能力",但深入分析会发现:
能力边界的模糊:所谓的涌现能力往往是人为定义的,缺乏严格的理论支撑
扩展性的假象:简单的组件叠加并不能带来真正的能力跃迁,很多看似是涌现的能力实际上是LLM本身就具备的
可控性的挑战:随着组件的增加,系统的不确定性呈指数级增长,这与工业级应用的要求背道而驰
更深层次的问题在于,目前的Agent系统在处理复杂任务时,往往过度依赖底层大语言模型的in-context learning能力。这种依赖导致了一个看似矛盾的现象:Agent的能力边界实际上被其底层语言模型所限制,而非取决于其工具调用和任务规划能力。这一现象从根本上挑战了当前Agent架构的设计理念。在许多场景下,所谓的"Agent智能"很大程度上是在"假借"语言模型的泛化能力,而非源于Agent系统本身的架构创新。
在Scaling Law进入精细化调整阶段的技术背景下,Agent作为延续算力增长的关键载体,正面临着一个根本性的技术挑战:如何在确保安全性的同时,实现对庞大计算负载的高效支撑。从开源实践的深度来看,这个挑战比我们预想的要严峻得多。
现有的Agent架构在处理高强度计算任务时暴露出严重的安全漏洞。这些漏洞并非传统意义上的代码缺陷,而是源于系统架构层面的根本性缺陷。具体表现在以下几个方面:
首先是计算资源的越权调用问题。当前主流的Agent框架普遍采用基于LLM的决策机制来调度计算资源,这种机制在处理高并发计算时容易出现资源分配的混乱。例如,在一个典型的分布式训练场景中,我们观察到多个Agent节点之间的资源争用可能导致计算图的紊乱,进而引发严重的性能衰减甚至系统崩溃。这种问题在扩展到数千节点规模时表现得尤为明显。
其次是推理链路的不确定性放大。在大规模计算场景下,Agent的推理路径会随着任务复杂度的提升呈指数级增长。我们在实践中发现,即使是经过严格验证的推理模块,在组合使用时也可能产生难以预期的错误传播。特别是在处理需要深度优化的计算任务时,这种不确定性可能导致灾难性的资源浪费。
更关键的是并行计算下的状态一致性问题。传统的Agent框架在处理并行计算时,往往依赖简单的状态同步机制。然而,在大规模分布式环境中,这种机制的脆弱性被显著放大。
从实践中观察到,当系统负载达到一定程度时,状态不一致性可能导致计算结果的严重偏差,这对于精确计算而言是致命的。
从技术栈的角度分析,这些问题的根源在于当前Agent架构对计算范式的理解过于表层。大多数框架仍在用传统的任务调度思维来处理高度并行的计算需求,这种认知上的局限直接导致了系统在处理大规模计算时的效率低下和不稳定。
以下是一些浅表的解决方案计算图优化引擎:
构建支持动态重构的计算图系统引入细粒度的资源隔离机制实现跨节点的原子性保证
分布式状态管理:
设计更强大的一致性协议实现细粒度的状态追踪建立可验证的状态恢复机制
安全性形式化验证:
构建基于π演算的交互验证框架实现分布式场景下的死锁检测建立细粒度的权限控制体系
在当前Scaling Law缓步啪啪时期,Agent系统必须通过架构创新来支撑起更大规模的计算需求。这不仅是效率问题,更是架构安全性的根本挑战。也有必要重新思考Agent在大规模分布式计算中的角色定位。
五、Scaling Law的适应性进化:从规模扩展到多维优化
如果说过去几年AI的进步主要依赖于参数规模的简单堆叠,那么当前我们正进入一个需要更细致、更系统的优化阶段。这种转变不是因为Scaling Law失效,而是由于我们开始触及到了一个更深层的技术真相:模型规模的扩展必须与系统架构的优化形成良性互动,才能实现真正的能力提升。
在深入研究大量开源实践后,我们发现一个引人深思的现象:当模型规模达到一定程度后(通常在100B参数量级),简单增加参数量带来的收益开始显著降低。这种效率衰减不仅体现在计算资源的投入产出比上,更反映在模型对知识的吸收和泛化能力上。特别是在处理需要精确推理和深度理解的任务时,我们观察到模型的表现并不随参数规模线性提升,而是呈现出一种复杂的阶跃式进化模式。
这种现象促使我们重新思考Scaling Law的本质。传统的Scaling Law主要关注参数量、计算量与模型性能之间的幂律关系,但这种单一维度的度量已经无法完整描述当代AI系统的进化规律。我们需要构建一个更完整的理论框架,将架构创新、优化策略、数据质量等多个维度纳入考量。这个新的框架应该能够回答:为什么某些看似"小型"的模型(如70B级别)在特定任务上能够超越其更大规模的对手?为什么某些架构创新能带来超出参数规模预期的性能提升?
更具体地说,新一代的Scaling Law应该考虑以下关键维度:首先是计算效率维度,包括模型在不同精度下的表现特性、内存访问模式对性能的影响、以及分布式训练中的通信开销等。其次是优化策略维度,涵盖不同层次的量化方案、注意力机制的改进、以及模型压缩技术的应用等。最后是系统架构维度,需要考虑模型的可扩展性、容错能力、以及在实际部署环境中的稳定性等因素。
在实践层面,这种多维度的优化已经显示出令人瞩目的效果。例如,通过精心设计的混合精度训练策略,我们可以在保持模型性能的同时显著降低计算开销。又如,通过对注意力机制的深度优化,我们可以在不增加参数量的情况下提升模型的长序列处理能力。这些优化不是简单的工程技巧,而是对AIl系统本质的深层理解和改进。
在这个新阶段,数据质量和训练策略的重要性开始超越纯粹的规模扩展。我们发现,经过精心筛选和组织的高质量数据集,配合优化的训练范式,往往能够帮助相对"小型"的模型实现出人意料的性能。这种现象启示我们,未来的突破可能更多地来自于对训练过程的深入理解和优化,而不是简单地追求更大的模型规模。
六、开源社区的技术变革:从跟随到引领的范式转变
在经历了多轮大模型竞赛后,开源社区正在经历一场深刻的技术变革。这种变革不仅体现在技术方向的选择上,更深刻地反映了社区对AI发展本质的重新认知。如果说之前的开源实践更多地在跟随商业巨头的技术路线,那么现在我们正在见证一个更加自主、更具创新性的发展阶段。
深入观察当前开源社区的技术实践,我们可以发现一个显著的转变:技术探索正从"追求极限"转向"追求
本质"。这种转变首先体现在对模型架构的思考上。以LLaMA系列为例,其成功不仅在于模型本身的性能,更在于它开创性地展示了如何在有限资源约束下实现最优的架构设计。这种对架构本质的深入思考,远比简单的参数规模扩张更具启发性。
特别值得关注的是开源社区在分布式训练优化方面的创新。传统的数据并行和模型并行策略在超大规模模型训练中已经遭遇瓶颈,尤其是在通信开销和内存管理方面。面对这个挑战,开源社区提出了一系列创新性的解决方案。例如,通过精细的计算图分析和动态流水线策略,我们可以显著降低跨设备通信的开销;通过智能的存储管理和梯度压缩技术,我们能够在有限的显存条件下训练更大规模的模型。这些创新不是简单的工程优化,而是对分布式计算本质的深刻理解。
在训练策略层面,开源社区正在突破传统的范式限制。我们发现,模型的性能不仅取决于其规模和架构,更关键的是训练过程中的知识获取和组织方式。通过对预训练任务的重新设计,引入更多的结构化知识和推理任务,我们可以显著提升模型的理解能力和泛化性能。这种对训练范式的创新,正在成为开源社区的重要技术方向。
更深层次的变革体现在社区对AI系统可解释性和可控性的追求上。随着模型规模的增长,其决策过程的不透明性日益成为一个严重问题。开源社区正在这个方向上进行深入探索,试图构建更透明、可解释的AI系统。这种探索不仅涉及技术层面的创新,更涉及到AI系统设计理念的根本转变。
值得一提的是,开源社区在工程实践方面的积累正在形成独特的优势。通过大量的实践探索,我们积累了丰富的优化经验和工程智慧。这些经验不仅帮助我们更好地理解Al系统的行为特性,也为未来的创新奠定了坚实的基础。例如,在模型压缩和量化方面,开源社区的探索已经产生了多个突破性的成果,这些成果正在改变我们对模型效率的认知。
七、未来技术突破的关键路径:深度创新与工程实践的辩证统一
从科学发展的历史来看,任何重大突破都源于对既有理论框架的超越。站在2024年这个特殊的时间节点,我们正经历着人工智能发展的关键时期:一方面,以大规模预训练模型为代表的主流技术范式取得了前所未有的成功;另一方面,这个范式也暴露出一系列根本性的理论困境,这些困境不仅体现在工程实践中,更深刻地反映了我们对智能计算本质理解的局限。作为深度参与开源实践的研究者,我认为是时候重新审视这些核心问题,寻求更深层的理论突破。
一、现象观察与理论困境
在非线性动力学研究中,系统即将发生质变时往往会出现一系列特征性的信号。类似地,当前AI技术发展中也出现了多个值得深思的现象:
规模失效现象
在传统的Scaling Law框架下,模型性能应该随着参数规模的增长而持续提升。然而,我们观察到了一系列违反这一规律的现象:
小模型的反常表现:某些经过精心设计的70B规模模型,在特定任务上展现出超越175B模型的性能。这种"以小胜大"的现象严重挑战了我们对模型规模与能力关系的传统认知。
非线性断点:计算资源投入与性能提升之间的关系出现了多个无法用现有理论解释的非线性断点。这些断点的位置和特征表现出某种规律性,暗示着背后可能存在更深层的机制。
能力发展不均衡:某些高级认知能力(如逻辑推理)的提升与参数规模增长之间呈现出复杂的非线性关系,这种关系模式超出了现有理论的预测范围。
架构悖论
Transformer架构自2017年提出以来,一直是一个理论谜题:
简单性与强大能力的矛盾:这个本质上相对简单的注意力机制,为什么能够支撑如此复杂的认知功能?这种架构上的"简单性"是否暗示了我们忽略了某些关键的理论洞见?
规模迁移现象:相同的架构在不同规模下呈现出质的差异,这种差异不仅量上,更在本质上。这暗示着可能存在某种我们尚未认识到的规模效应机制。
能力涌现的不可预测性:某些复杂的认知能力(如抽象推理、类比理解)会在特定规模阈值后突然出现,但这些阈值的位置和出现的具体能力难以预测。
深层理论困境的本质分析当我们深入分析这些现象背后的原因,会发现当前的深度学习范式面临着几个根本性的理论挑战:
计算复杂度的理论约束
目前的注意力机制在理论上存在着不可逾越的复杂度边界:
二次方复杂度的本质限制:全局注意力机制的时间和空间复杂度都是序列长度的二次方,这不仅是工程实现的瓶颈,更反映了计算范式本身的局限。通过数学证明可以表明,在当前的注意力机制框架下,这个复杂度是理论下界,无法通过工程优化来实质性改善。
优化手段的局限性:目前广泛采用的各种优化技术(如分块注意力、稀疏注意力等)本质上都是在常数项上的改进,无法突破复杂度的理论上界。这些方法虽然在工程实践中取得了一定成功,但从根本上看仍然是对症治标。
长序列处理的瓶颈:这种复杂度约束直接限制了模型处理长序列和复杂结构化数据的能力,使得真正的长程依赖学习变得几乎不可能。
表征学习的深层困境
当前的神经网络在知识表征方面存在着本质性的缺陷:
统计关联的局限:模型在处理抽象概念时,过度依赖于训练数据中的统计关联,缺乏对概念本质的真正理解。这种依赖导致模型在面对分布外样本时表现不稳定。
知识组织的隐式性:神经网络中的知识是以分布式、隐式的方式存储的,这种存储方式虽然有利于模式识别,但严重阻碍了对知识的显式操作和推理。
符号推理能力的缺失:预训练-微调范式在处理需要精确推理的任务时表现出明显的脆弱性,这反映了当前模型缺乏真正的符号操作能力。
可解释性的根本缺失
黑箱特性不仅是工程层面的问题,更反映了理论框架的不完备:
决策过程的不透明:模型的决策过程完全隐藏在神经网络的权重分布中,我们无法追踪和验证具体的推理路径。
状态表征的模糊性:缺乏对模型内部状态的有效表征和解释机制,使得我们无法真正理解模型的"思维过程"。
可验证性的缺失:无法保证推理结果的可验证性和可重复性,这严重限制了模型在关键应用领域的部署。
涌现行为的不可控性
模型在规模增长过程中表现出的涌现行为,反映了我们对深度学习本质理解的不足:
规模阈值的不可预测:不同类型的涌现能力似乎有着不同的规模阈值,但我们无法从理论上预测这些阈值。
能力边界的模糊:难以准确定义和度量模型的能力边界,导致我们无法有效地指导模型设计和优化。稳定性问题:涌现能力的稳定性往往难以保证,同一能力可能在不同环境或任务中表现不一致。
动态系统理论视角的重新审视
为了更系统地理解和描述这些现象,我们需要从动态系统理论的视角重新构建理论框架。这种视角不仅能够统一解释已观察到的现象,还可能为未来的突破指明方向。
基础理论框架
plaintextCopy基本状态方程:
S(t+1)=F(S(t),W,I(t))
扩展动力学方程:dS/dt =F(S,W,I)+G(S,W)+η(t)
其中:
S:系统状态向量
W:参数空间
I:输入空间
F:非线性变换函数
G:内部动力学项
η:随机涨落项
这个框架揭示了几个关键的理论问题:
稳定性与复杂性的统一
基于注意力机制的序列处理模型。这种范式在处理结构化信息时已经表现出明显的局限性:计算复杂度的根本性约束
全局注意力机制的二次方复杂度不仅是工程实现的瓶颈,更是理论上的根本限制通过分块或稀疏化等优化手段只能在常数项上得到改善,无法突破复杂度的理论上界这种约束直接限制了模型处理长序列和复杂结构化数据的能力
表征学习的深层困境
当前架构在处理抽象概念和复杂关系时,往往依赖于隐式的统计关联缺乏显式的知识组织结构导致模型难以进行可靠的符号推理预训练-微调范式在处理需要精确推理的任务时表现出明显的脆弱性
对此,我们需要在以下方向进行范式级的创新:计算范式的重构
plaintextCopy传统范式:Sequence->Attention ->Hidden States ->Output
提出的新范式:
Input ->Knowledge Structuring ->Symbolic Reasoning ->Neural Processing ->Verifiable Output这种新的计算范式将带来几个关键优势:
可验证的推理链路
引入形式化方法验证推理过程实现精确的知识追踪和状态管理保证推理结果的可重复性
混合计算架构
将神经网络的模式识别能力与符号系统的精确推理相结合实现细粒度的资源调度和优化支持可控的知识迁移和复用
层级化的知识组织
构建显式的知识表示体系实现高效的知识检索和更新支持跨域知识的系统性整合
这种范式转变不仅能够解决当前面临的技术瓶颈,更重要的是为Al系统的可解释性和可控性提供了理论基础。特别是在处理需要精确推理的任务时,这种架构能够提供可验证的执行路径和明确的错误边界,这对于工业级应用而言是至关重要的。
当然,实现这种范式转变需要开源社区在工程实践中解决一系列具有挑战性的问题,包括但不限于:
如何设计高效的混合计算引擎
如何处理符号系统和神经网络之间的转换开销如何确保分布式环境下的一致性
如果说过去几年的AI进展主要体现在统计学习的规模化上,那么未来的突破必将发生在计算范式的本质重构上。基于开源社区的深度实践,我认为这种重构将围绕三个核心方向展开:神经-符号的深度融合、基于因果的推理机制、以及可验证的逻辑运算能力。
Neural-Symbolic Integration的理论基础
当前的深度学习模型,本质上是在高维概率空间中进行模式匹配。这种范式虽然在感知层面取得了巨大成功,但在推理能力上存在着根本性限制:
概率分布vs符号运算
plaintextCopy当前范式:Input ->Statistical Pattern ->Probability Distribution ->Output
提出的新范式:
Input ->Symbolic Abstraction ->Logical Reasoning ->Neural Verification ->Deterministic Output
这种新范式的核心在于:不是用神经网络来模拟符号运算,而是将符号计算作为一个独立的、可验证的计算层级。
基于因果结构的推理框架
要实现真正的推理能力,模型必须具备对因果关系的理解和操作能力:在Transformer中植入因果结构
注意力机制从相关性计算扩展到因果关系提取显式建模事件之间的因果依赖支持反事实推理的计算图结构
因果推理的形式化保证
plaintextCopy推理框架:
C(e1,e2)=P(e2|do(e1))-P(e2)其中:
C:因果效应强度
e1,e2:事件do():干预算子
可验证的逻辑运算系统
未来的Al系统必须具备可验证的逻辑运算能力:Reasoning Primitive的构建
基本逻辑运算器的形式化定义复杂推理的组合规则推理正确性的验证机制
强化学习在推理中的新角色
plaintextCopy目标转变:从:优化特定任务的策略到:学习通用的推理原语这种转变使得模型不仅能解决问题,更能理解和生成解决问题的方法。
实现路径
要实现这种范式转变,需要在以下几个层面进行突破:
架构层面
设计支持符号操作的神经网络结构实现可验证的推理控制流构建混合计算的调度机制
算法层面
plaintextCopy核心创新:
1.符号抽象机制
-语义特征提取
-概念形式化
-关系显式化
2.推理原语学习
-基本逻辑单元
-组合规则学习
-正确性验证
3.因果结构学习
-因果图构建
-干预效应评估
-反事实推理
理论保障
新范式的可行性建立在以下理论基础上:
可判定性保证
推理过程的形式化验证计算复杂度的理论边界正确性的数学证明
完备性要求
plaintextCopy理论框架需要证明:
1.表达完备性
-可以表达任意逻辑关系
-支持高阶推理
-具备抽象能力
2.计算完备性
-可以模拟图灵机
-支持递归计算
-保证确定性
这种范式转变不是简单的工程改进,而是对AI系统计算本质的重新思考。它将帮助我们突破当前深度学习的根本性限制,开创真正具备推理能力的Al系统。
六、未来技术突破的关键路径:从神经网络到神经-符号统一计算(续)
工程实现的关键挑战
从论证到实现,在工程层面我们面临几个关键挑战:
符号抽象层的实现
plaintextCopy核心机制:
1.语义概念提取
Input ->Neural Processing ->Symbolic Representation要求:
-保证抽象的一致性
-维持语义的完整性
-支持双向转换
2.关系结构构建
Entity ->Relation Detection ->Causal Graph关键点:
-显式的关系表示
-可验证的因果链路
-动态的图结构更新
推理系统的工程架构
新一代推理系统需要一个多层次的架构设计:
plaintextCopy系统分层:
L1:神经计算层
-特征提取
-模式识别
-概率估计
L2:符号转换层
-概念抽象
-关系提取
-规则生成
L3:逻辑推理层
-定理证明
-规则应用
-结果验证
L4:调度控制层
-计算资源分配
-推理策略选择
-结果一致性保证
因果推理的具体实现
在Transformer架构中植入因果结构的具体方案:plaintextCopy改进的注意力机制:Attention(Q,K,V)=softmax(QK^T//d+C)V
其中:
C:因果结构矩阵
-显式编码事件间的因果关系
-支持动态更新
-可进行干预操作
验证机制的系统设计
为确保推理的可靠性,需要建立完整的验证体系:
多层次验证框架
plaintextCopy验证层级:
1.语法验证
-推理步骤的形式正确性
-规则应用的合法性
-结论的格式一致性
2.语义验证
-推理链的完整性
-结论的合理性
-反例的检测
3.因果验证
-因果关系的一致性
-干预效果的合理性
-反事实推理的正确性
性能优化的技术路线
为了使系统在实际应用中可行,需要解决性能问题:
计算优化策略
plaintextCopy优化方向:
1.并行计算
-符号操作的并行化
-推理任务的分解
-验证过程的并行执行
2.缓存机制
-中间结果的重用
-常用推理路径的缓存
-验证结果的存储
3.调度优化
-资源的动态分配
-任务的优先级管理
-负载的均衡控制
开源实践的具体路径
作为开源社区的实践,我们建议按以下步骤推进:
plaintextCopy实施路线:
Phase 1:基础设施建设
-符号计算引擎
-推理原语库
-验证工具集
Phase 2:核心功能实现
-神经-符号转换器
-因果推理模块
-验证系统
Phase 3:性能优化
-分布式架构
-并行计算
-缓存系统
Phase 4:生态建设
-标准化接口
-评估基准
-示例应用
理论研究与工程实践的统一
最后,这种范式转变需要理论与实践的紧密结合:
研究方向
符号抽象的数学基础推理系统的复杂度理论验证机制的形式化方法
工程验证
概念验证原型
性能基准测试
实际应用案例
在技术发展的历史进程中,规模扩展从来都只是工具,而非终极目标。当今的AI技术已逐渐脱离了其最初的设计目的,沦为参数竞赛的试验场。然而,模型性能的提升不应只是简单的"更大、更快",更应该是"更聪明、更深刻"。这意味着我们需要从根本上重塑神经网络架构,以因果推理和符号推理为核心,构建一个真正具备认知能力的AI系统。
结语
回望人工智能领域的发展历程,Scaling Law作为指导大模型性能提升的重要法则,一直扮演着关键角色。然而,随着模型参数规模的无限扩张,我们开始触及到硬件资源和计算效率的天花板。这并非意味着Scaling Law的"终结",而是预示着技术发展的新起点。
当前,我们正处于一个需要重新审视计算范式的时代。简单依赖参数规模的增长已无法持续带来线性甚至指数级的性能提升。硬件的物理极限、算力的瓶颈,以及能耗的不断攀升,迫使我们寻找新的技术路径。在这一背景下,算法创新与硬件发展的协同变得尤为重要。混合精度训练、稀疏化技术、模块化架构等新兴技术,为我们打开了优化计算效率的新窗口。这些技术不仅仅是工程上的改进,更是对计算范式的重新定义。
与此同时,Agent系统的崛起为人工智能应用带来了新的可能性。然而,我们必须清醒地认识到,当前的Agent架构在处理复杂任务时,仍然过度依赖底层大模型的能力,缺乏对认知过程和推理机制的深层理解。这导致了在高并发和复杂任务环境下,Agent系统暴露出资源调度混乱、推理链路不稳定、状态一致
性难以保证等问题。要解决这些问题,我们需要在计算图优化、分布式状态管理和安全性验证等方面进行深度创新,从而实现系统架构的整体革新。
开源社区在这场技术变革中发挥着至关重要的作用。通过对模型架构、训练范式和系统优化的深入探索,开源实践者们正在引领从规模扩展到多维优化的范式转变。这种转变不仅体现在技术层面,更体现了对人工智能系统可解释性和可控性的深度追求。大量的实践证明,数据质量和训练策略的重要性已经开始超越单纯的参数规模扩张。高质量的数据集和优化的训练范式,往往能够使相对小型的模型在特定任务上取得超越更大模型的表现。
未来的技术突破,将源于对计算范式的重新定义、对知识表示和推理机制的革新,以及对系统架构的全面优化。具体而言,我们需要构建具有显式知识表示和符号推理能力的混合架构,以突破当前大模型在推理能力和可解释性方面的瓶颈。在训练范式上,探索层级化的学习框架,使模型能够从基础概念出发,逐步构建复杂的认知结构,从而具备更深层次的理解和推理能力。
工程实践的积累也是不可或缺的。优化计算图、改进分布式训练策略、加强状态管理和安全性验证,这些都是在大规模模型训练和部署中需要解决的实际问题。开源社区通过大量的实践探索,积累了丰富的经验,为未来的技术突破奠定了坚实的基础。
附录Agent技术近期演进路径:决策范式的三重交织
在当前开源社区的技术实践中,我们清晰地观察到了Agent技术呈现出三种典型的决策范式。这种分化不是偶然,而是AI系统在追求更高认知能力过程中的必然选择。作为深度参与开源实践的工程师,我认为有必要从计算理论的本质出发,重新审视这三种范式的深层逻辑。
一、预置范式(Human Pre-planned)的技术现状
当前主流的Agent实现大多采用这种范式,其本质是一个基于人类经验的确定性有限状态机:
plaintextCopySystem_Architecture ={
State_Space:Predetermined states,
Action_Space:Fixed tool set,
Transition_Rules:Human-defined logic,
Router:Deterministic FSM
}
从工程实践来看,这种范式在特定场景下表现出显著优势:
系统特性
行为可预测:状态转换路径完全确定
资源开销低:无需实时LLM推理
部署门槛低:架构简单,易于实现
实现细节
plaintextCopyRouter_Implementation ={State_Detection:Rule-based parsing,Tool_Selection:Predefined mapping,Error_Handling:Explicit fallbacks
}
典型应用场景
标准化业务流程特定领域的专业任务高可靠性要求的系统
然而,在大规模实践中,这种范式暴露出严重的理论缺陷:根本性限制
状态空间爆炸:工具集扩展导致状态数量指数增长
泛化能力受限:难以处理预设路径之外的场景
维护成本高:新增功能需要人工重新规划
系统瓶颈
plaintextCopyBottlenecks ={
Scalability:O(2^n)state combinations,Flexibility:Limited to predefined paths,Maintenance:Manual updates required
}
二、自主寻路范式(LLM Auto Router)的技术突破
以AutoGPT为代表的自主寻路Agent,标志着这个领域的首次理论突破。其核心是将路由决策建模为动态规划问题:
plaintextCopyRoute_Planning ={
Objective:max P(success|state,tools,path),Constraints:resource_limits,safety_bounds,Optimizer:LLM_based_planner
}
这种范式带来了革命性的技术创新:
架构创新
动态决策:实时规划最优路径
自适应学习:根据反馈优化策略
泛化能力:处理未见场景
技术实现
plaintextCopyLLM_Router ={
State_Analysis:Deep context understanding,Path_Planning:Multi-step reasoning,Execution_Monitor:Real-time adjustment}
核心突破
打破了预设路径的限制实现了真正的自主决策具备了持续学习能力
然而,大规模部署实践揭示了这种范式的深层次问题:理论困境
决策稳定性:难以保证一致的行为表现
资源开销:每个节点都需要LLM推理
安全边界:缺乏形式化的安全保证
工程挑战
plaintextCopyTechnical_Challenges ={Computation:High inference cost,Reliability:Inconsistent decisions,Monitoring:Complex state tracking
}
三、人机耦合范式(User Copilot)的技术创新
Copilot模式提供了一个优雅的解决方案,将人类决策作为系统的特殊算子:plaintextCopySystem_Model={
State:{Computational,Human},
Decision:λ(state)→{Auto,Human},
Execution:Hybrid control flow
}
这种设计带来了独特的技术优势:
架构特点
灵活干预:关键节点由人类控制
经验积累:持续优化决策模型
风险可控:双重安全保障
实现机制
plaintextCopyCopilot_Framework ={State_Monitor:Critical point detection,User_Interface:Interactive decision making,Learning_Module:Experience accumulation
}
应用价值
降低了自动化风险提供了人机协同范式支持渐进式优化
然而,实践中也面临着特有的挑战:技术难点
交互延迟:人类决策引入时间开销
一致性维护:多用户场景下的状态同步
经验泛化:个体经验的系统化提取
系统约束
plaintextCopySystem_Constraints ={
Response_Time:Human decision latency,State_Sync:Multi-user consistency,
Knowledge_Transfer:Experience formalization
}
四、当前技术发展的核心趋势
基于开源社区的实践观察,Agent技术正在经历快速的演进:架构融合
plaintextCopyTrend_Architecture ={
Multi_Modal_Router:Hybrid decision making,Adaptive_Control:Dynamic mode switching,Unified_State_Space:Integrated management}优化方向
决策效率:降低路由开销
系统稳定性:提升运行可靠性
安全保障:加强风险控制
创新重点
plaintextCopylnnovation_Focus={Router_Optimization:Efficient planning,State_Management:Reliable tracking,Security_Framework:Risk mitigation
}
五、近期技术突破的关键路径要在现有基础上实现实质性突破,需要在以下方向取得进展:
理论基础
plaintextCopyTheoretical_Advances ={Formal_Methods:Decision verification,Performance_Models:Efficiency analysis,Safety_Proofs:Security guarantees
}
工程实践
分布式架构:支持大规模部署
资源调度:优化计算效率
监控体系:保障运行稳定
生态建设
plaintextCopyEcosystem_Development ={Standard_Protocols:Interoperability,Tool_Integration:Unified interface,
Community_Collaboration:Shared resources}
六、技术展望与实践建议
基于当前的发展态势,我对Agent技术的近期演进提出以下建议:架构设计
plaintextCopyDesign_Principles ={Modularity:Flexible composition,Scalability:Efficient scaling,Reliability:Robust operation}
实现策略
渐进式改进:稳步优化现有系统
混合部署:多模式协同运行
持续监控:及时发现问题
发展路径
plaintextCopyDevelopment_Path={
Phase_1:Infrastructure enhancement,
Phase_2:Performance optimization,
Phase_3:Advanced features
}
七、统一计算框架的理论构建
要实现真正的范式突破,我们需要构建一个统一的元路由理论(Meta-Routing Theory):
plaintextCopyMeta_Framework =(2,「,δ,w,φ)where:
Z:Extended state space
「:Action manifold
δ:Transition operator
w:Route selection functional
φ:Verification mapper
Route_Selection:w(state,context)→optimal_path∈{
Static_Routes:FSM_based_paths,Dynamic_Routes:LLM_generated_paths,Hybrid_Routes:Human_augmented_paths,Meta_Routes:Composite_strategies}
这个理论框架需要解决的核心问题包括:
计算复杂性理论
plaintextCopyComplexity_Analysis={Time_Bounds:O(f(n))constraints,Space_Efficiency:Memory optimization,Parallel_Scalability:Distribution properties
}
形式化验证系统
决策正确性的数学证明状态转换的完备性保证安全性边界的形式化定义
认知架构设计
plaintextCopyCognitive_Architecture ={
Knowledge_Representation:Symbol-Neural fusion,Reasoning_Engine:Multi-paradigm inference,Learning_Framework:Experience abstraction}
八、深层系统重构的技术路径要实现这个理论框架,需要在以下方向取得突破:
计算引擎革新
plaintextCopyNext_Gen_Engine ={
Meta_Router:Context-aware selection,
State_Manager:Distributed consistency,
Verification_Layer:Formal proof system,
Components:{
Symbolic_Processor:Logic operations,
Neural_Core:Pattern recognition,
Hybrid_Controller:Integration layer
}
}
分布式架构设计
plaintextCopyDistributed_System ={
State_Synchronization:{
Protocol:Eventually consistent,
Recovery:Automatic failover,
Verification:Byzantine fault tolerance
},
Computation_Model:{
Parallel_Processing:SIMD optimization,
Memory_Management:Hierarchical caching,
Resource_Scheduling:Dynamic allocation
}
}
安全框架构建
plaintextCopySecurity_Framework ={
Formal_Verification:{
Property_Checking:Safety guarantees,
Model_Checking:Behavior validation,
Proof_Generation:Automated verification
},
Runtime_Protection:{
Boundary_Control:Action limitation,
State_Monitor:Anomaly detection,
Recovery_Mechanism:Fallback strategies
}
}
九、认知架构的根本性创新
未来的Agent系统需要突破当前的认知局限:
符号-神经融合计算
plaintextCopyHybrid_Computing ={
Symbol_System:{
Logic_Engine:Formal reasoning,
Knowledge_Base:Structured storage,
Rule_Processor:Inference control
},
Neural_System:{
Pattern_Recognition:Feature extraction,
Contextual_Learning:Experience accumulation,
Adaptive_Behavior:Dynamic adjustment
},
Integration_Layer:{
Translation_Module:Representation mapping,
Coordination_Engine:Process synchronization,
Optimization_Controller:Resource balancing
}
}
多模态推理机制
plaintextCopyReasoning_Framework ={
Deductive_Engine:Logical inference,
Inductive_Module:Pattern generalization,
Abductive_Processor:Hypothesis generation,
Integration:{
Mode_Selection:Context-based routing,
Result_Fusion:Evidence combination,
Confidence_Estimation:Uncertainty quantification
}
}
知识表征革新
plaintextCopyKnowledge_Architecture ={
Representation:{
Symbolic_Layer:Discrete concepts,
Neural_Layer:Continuous embeddings,
Hybrid_Layer:Integrated features
},
Operations:{
Abstraction:Concept formation,
Composition:Knowledge integration,
Inference:Logical deduction
}
}
十、工程实现的关键突破点
要将理论框架落地,需要解决以下核心问题:
计算效率优化
plaintextCopyPerformance_Engineering ={
Computation:{
Parallel_Processing:GPU optimization,
Memory_Management:Cache hierarchy,
I/O_Handling:Asynchronous operations
},
Algorithms:{
Route_Planning:Efficient pathfinding,
State_Tracking:Compact representation,
Decision_Making:Fast inference
}
}
系统可靠性保障
plaintextCopyReliability_Framework ={
Fault_Tolerance:{
Error_Detection:Real-time monitoring,
State_Recovery:Checkpoint restoration,
Failure_Isolation:Component containment
},
Consistency_Control:{
State_Synchronization:Global coordination,
Transaction_Management:ACID properties,
Version_Control:History tracking
}
}
安全性验证体系
plaintextCopySecurity_System={
Static_Analysis:{
Code_Verification:Property checking,
Resource_Bounds:Usage limitation,
Type_Safety:Interface validation
},
Dynamic_Monitoring:{
Behavior_Tracking:Action logging,
Anomaly_Detection:Pattern analysis,
Response_System:Automatic mitigation
}
}
十一、长期技术演进的理论基础
为了支撑这种范式转换,我们需要建立更深层的理论基础:
计算理论扩展
plaintextCopyTheoretical_Foundation ={
Computation_Model:{
Abstract_Machine:Extended automata,
Complexity_Classes:New hierarchies,
Verification_Theory:Proof systems
},
Mathematical_Framework:{
工LCategory_Theory:Morphism analysis,
Type_Theory:Dependent types,
Logic_Systems:Modal calculus
}
}
认知科学整合
plaintextCopyCognitive_Science={Mental_Models:{
Representation:Knowledge structures,
Processing:Information flow,
Learning:Adaptation mechanisms
},
System_Integration:{
Architecture:Component interaction,
Control:Decision processes,
Evolution:Adaptive behavior
}
}
形式化方法革新
plaintextCopyFormal_Methods={
Verification:{
Model_Checking:State exploration,
Theorem_Proving:Logical deduction,
Runtime_Verification:Dynamic checking },
Specification:{
Property_Language:Formal notation,
Behavioral_Models:System dynamics,
Correctness_Criteria:Safety properties
}
}
十二、未来发展的关键方向
理论突破
plaintextCopyTheoretical_Advances ={
Computation_Theory:{
New_Models:Hybrid computation,
Complexity_Analysis:Resource bounds,
Verification_Methods:Proof systems
},
Learning_Theory:{
Knowledge_Representation:Symbol-neural fusion,
Inference_Models:Multi-paradigm reasoning,
Adaptation_Mechanisms:Dynamic learning
}
}
技术创新
plaintextCopyTechnical_Innovation ={
Architecture:{
Component_Design:Modular systems,
Integration_Patterns:Hybrid approaches,
Scaling_Strategies:Distributed computing
},
Implementation:{
Performance_Optimization:Efficient processing,
Reliability_Engineering:Robust operation,
Security_Framework:Risk management
}
}
应用展望
plaintextCopyApplication_Prospects ={
Domains:{
Scientific_Computing:Complex simulation,
Business_Intelligence:Decision support,
System_Control:Autonomous operation
},
Capabilities:{
Reasoning:Advanced inference,
Learning:Continuous adaptation,
Collaboration:Human-Al integration
}
}
在这个长期的技术演进过程中,我们需要保持清醒的认知:真正的突破不仅需要工程创新,更需要理论基础的重构。开源社区的实践表明,范式转换往往始于对计算本质的深刻理解。期待看到更多围绕决策机制、知识表征、安全验证等核心问题的突破性工作,推动Agent技术向更高层次演进。这种理论框架的建立不仅有助于我们理解当前Agent技术的局限,更为未来的突破指明了方向。在开源社
区的持续探索中,我们期待看到更多在这些方向上的创新性工作,推动Agent技术迈向新的高度。