目录
[1. 基本概念](#1. 基本概念)
[2. string 存储方式](#2. string 存储方式)
[3. 支持的数据类型](#3. 支持的数据类型)
[4. 与 MySQL 的对比](#4. 与 MySQL 的对比)
[5. 性能考虑](#5. 性能考虑)
[1. 通用命令](#1. 通用命令)
[1.1 字符串的存储方式](#1.1 字符串的存储方式)
[1.2 常见命令](#1.2 常见命令)
[String 的内部编码方式](#String 的内部编码方式)
[String 类型的具体应用场景](#String 类型的具体应用场景)
[1. 缓存 (Cache) 功能](#1. 缓存 (Cache) 功能)
[2. 计数 (Counter) 功能](#2. 计数 (Counter) 功能)
[3. 共享会话 (Session)](#3. 共享会话 (Session))
[Cookie 和 Session](#Cookie 和 Session)
[4. 示例:手机验证码](#4. 示例:手机验证码)
1.前言
1. 基本概念
- Key :Redis 中所有的
key都是字符串。 - Value :
value的类型可以是多种多样的,包括字符串、整数、列表、哈希表等。
2. string 存储方式
- 二进制存储 :Redis 中的字符串直接按照二进制数据的方式存储,不会进行任何编码转换。存入的是什么,取出的还是什么。
- 避免乱码 :由于不进行编码转换,Redis 遇到乱码问题的概率较低。
3. 支持的数据类型

- 文本数据:
-
- 普通的文本字符串
- JSON
- XML
- 整数:可以存储整数,Redis 会自动识别并优化存储。
- 二进制数据:
-
- 图片
- 视频
- 音频
4. 与 MySQL 的对比
- 字符集:MySQL 默认的字符集是拉丁文,插入中文会失败,存在乱码问题
- 二进制数据 :Redis 可以存储二进制数据,但音视频等数据体积较大,Redis 对
string类型的大小限制为最大 512M。
5. 性能考虑
- 单线程模型:Redis 采用单线程模型,希望进行的操作都能比较快速。因此,不建议存储过大或处理时间过长的数据。
2.命令
1. 通用命令
1.1 字符串的存储方式
- Redis 中的
key数据类型是一个string,但value的数据结构可以是多种多样的。 - 存储方式:Redis 存储字符串时,直接存储字符串的二进制数据,不会进行编码转换。
- 适用场景 :可以存储字符串、图片、视频、音频等二进制数据。
- 限制:Redis 为了保证存储和获取数据的高效性,一般不存储超过 512M 的数据。
1.2 常见命令
set
- 命令 :
set key value [ex seconds|px milliseconds] [nx|xx] - 功能:设置键值对,并可设置过期时间和条件。
由于set默认情况下就是设置一个string,所以没有什么其它的特殊语法,此处介绍两个选项。
- EX seconds:以秒为单位,设置超时时间
- PX milliseconds:以毫秒为单位,设置超时时间
- NX:如果key不存在才设置,如果存在返回nil
- XX:如果key存在就更新,如果不存在返回nil
注意:通过XX更新后,原先的过期时间会失效,数据类型也有可能变化
-
示例:
set key1 value1 ex 10
ttl key1 # 返回剩余时间
set key1 value2 nx # key 存在时不设置
set key1 value2 xx # key 存在时覆盖

get
- 命令 :
get key - 功能:获取键对应的值,值必须是字符串类型。
- 示例:不对应的报错

mset
-
命令 :
mset key1 val1 key2 val2 ... -
功能:一次性设置多个键值对。
-
示例:
mset key1 val1 key2 val2 key3 val3
mget
-
命令 :
mget key1 key2 ... -
功能:一次性获取多个键对应的值。
-
示例:
mget key1 key2 key3
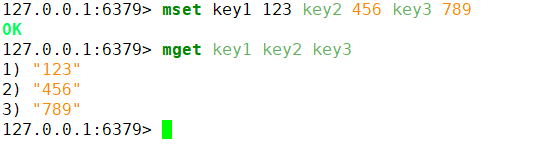
-
多次 GET****和单词 MGET****比较:使用
MGET/MSET可有效减少网络时间,性能较高
综上: 学会使⽤批量操作,可以有效提⾼业务处理效率
- 注意:每次批量操作所发送的键的数量也不是⽆节制的,否则可能造成单⼀命令执⾏时间过⻓,导致Redis阻塞
下面将介绍 2 个针对 set 的一些常见用法, 进行了缩写.
- 之所以这样, 就是为了让操作更符合人的直觉. (使用者的门槛就越低, 要背的东西就越少)
- 编程语言中, 很多的关键词, 都是和自然语言相关的~~
- 后续咱们去设计一些 库, 设计一些工具, 代码给别人使用的时候, 也要尽量符合直觉~~不要设计的 "反人类" / "反直觉"
setnx
-
命令 :
setnx key value -
功能 :如果键不存在,则设置键值对。可以理解为 no exist 设置~
-
示例:
setnx key1 value1 # 返回 0,因为 key1 已存在
setex
-
命令 :
setex key seconds value -
功能:设置键值对并指定过期时间(秒)。
-
示例:
setex key4 10 value4
ttl key4 # 返回剩余时间
数字操作
由于string内部还可以存储数字,所以Redis还提供了数字操作的命令。
时间复杂度:O(1)
incr
-
命令 :
incr key -
功能:将键的值加1,如果键不存在则创建键并初始化为0。
-
示例:
set key1 1
incr key1 # 返回 2
incr key2 # 返回 1,因为 key2 不存在
incrby
-
命令 :
incrby key increment -
功能:将键的值增加指定的整数。
-
示例:
incrby key2 7 # 返回 8
decr
-
命令 :
decr key -
功能:将键的值减1,如果键不存在则创建键并初始化为0。
-
示例:
decr key2 # 返回 7
decrby
-
命令 :
decrby key decrement -
功能:将键的值减少指定的整数。
-
示例:
decrby key2 1 # 返回 6
incrbyfloat
-
命令 :
incrbyfloat key increment -
功能:将键的值增加指定的浮点数。
-
示例:
set key1 1
INCRBYFLOAT key1 0.5 # 返回 1.5

注意
- Redis存储整数,是直接使用int类型存的,而存储小数,本质上是当作字符串来存储
- Redis的int比较方便算术运算
- 小数意味着每次进行算术运算,都需要把字符串转成小数,进行运算,再把结果转回字符串保存
很多存储系统和编程语⾔内部使⽤CAS机制实现计数功能,会有⼀定的CPU开销
- 但在Redis中完全不存在这个问题,因为Redis是单线程架构,任何命令到了Redis服务端都要顺序执⾏
- 由于Redis处理命令的时候,是单线程模型,多个客户端同时针对同一个key进行INCR等操作,不会引起"线程安全"问题
append
-
命令 :
append key value -
功能 :将值追加到键的现有值末尾。
-
示例:
append key2 aaaaa # 返回 11
get key2 # 返回 "value2aaaaa"
getrange
- 命令 :
getrange key start end - 功能 :获取键值在指定范围内的子字符串。
- 下标是 0, len-1
注意:
-
如果字符串中保存的是汉字,此时进行字串切分,切出来的很可能不是完成的汉字,因为 redis 是以字节为单位的
-
其中redis的
getrange操作与python一样是支持负数下标的,其中-1表示倒数第一个字符串.-2表示倒数第二个字符串 -
示例:
set key2 helloworld
getrange key2 1 4 # 返回 "ello"

setrange
-
命令 :
setrange key offset value -
功能 :从指定偏移量开始设置键值的一部分。
-
注意:针对不存在的
key,也可以操作,不过会把offset之前的内容填充成**0x00** -
示例:
set key3 value
setrange key3 2 aaaaaaaa # 返回 10
get key3 # 返回 "vaaaaaaaaa"
strlen
-
命令 :
strlen key -
功能 :获取键值的字节长度。
-
示例:
strlen key2 # 返回 6

命令小结

String 的内部编码方式
-
raw :最基本的形式,类似 Java 中的
byte[]数组。 -
int :当值是整数时,直接用
int类型存储。 -
embstr :当字符串较短时,使用优化的
embstr存储。 -
Redis会根据当前值的类型和长度 动态决定****使用哪种内部编码实现
整形
set key 2333
OK
object encoding key
"int"短字符串
set key "hello"
OK
object encoding key
"embstr"⼤于39个字节的字符串
set key "one string greater than 39 bytes ........"
OK
object encoding key
"raw
思考:
- 某个业务场景,有很多很多的 key,类型都是 string,但是每个 value 的 string 长度都是 100 左右。
- 更关注整体的内存空间。因此,这样的字符串使用 embstr 来存储也不是不能考虑。
上述效果具体怎么实现?
-
先看 redis 是否提供了对应的配置项,可以修改 39 这个数字。
-
如果没有提供配置型,就需要针对 redis 源码进行魔改。
为啥很多大厂,往往是自己造轮子,而不是直接使用业界成熟的呢?
- 开源的组件,往往考虑的是通用性。
- 但是大厂往往会遇到一些极端的业务场景,
- 往往就需要根据当前的极端业务,针对上述的开源组件进行定制化。
- 大厂造轮子,不仅仅是为了 kpi~
之后准备的两个轮子项目:
- rpc 框架
- raft 源码
String 类型的具体应用场景
- 缓存功能 :作为缓存层,提高读写速度,减轻后端数据库压力。
- 计数功能:实现快速计数,如视频播放次数统计。
- 共享会话:集中管理用户会话,支持分布式系统。
- 手机验证码:存储验证码,设置过期时间,确保安全性。
下面将进行详细的介绍
3.应用场景
1. 缓存 (Cache) 功能
- Redis+MySQL 组成的缓存存储架构
- Redis 作为缓冲层,MySQL 作为存储层,大多数请求的数据从 Redis 中获取。由于 Redis 支持高并发,缓存通常能加速读写并降低后端压力。
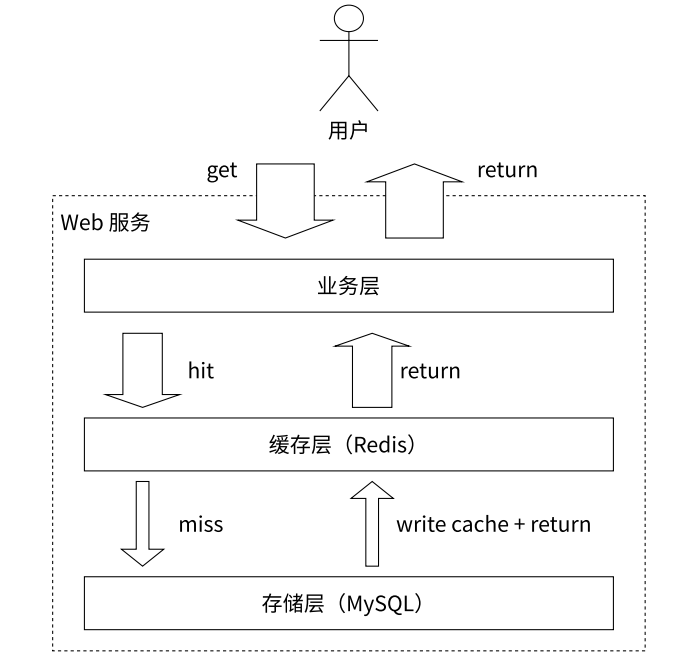
模拟业务数据访问过程
-
根据用户 uid 获取用户信息
UserInfo GetUserInfo(long uid) {
// 根据 uid 得到 Redis 的键
String key = "user:info:" + uid;// 尝试从 Redis 中获取对应的值 String value = Redis 执行命令:get key; // 如果缓存命中 (hit) if (value != null) { // 假设用户信息按照 JSON 格式存储 UserInfo userInfo = JSON 反序列化 (value); return userInfo; } // 如果缓存未命中 (miss) if (value == null) { // 从数据库中,根据 uid 获取用户信息 UserInfo userInfo = MySQL 执行 SQL:select * from user_info where uid = <uid>; // 如果表中没有 uid 对应的用户信息 if (userInfo == null) { 响应 404; return null; } // 将用户信息序列化成 JSON 格式 String value = JSON 序列化 (userInfo); // 写入缓存,为了防止数据腐烂 (rot),设置过期时间为 1 小时 (3600 秒) Redis 执行命令:set key value ex 3600; // 返回用户信息 return userInfo; }}
注意:
- Redis 没有表、字段等命名空间,键名没有强制要求(除了一些特殊字符)。
- 设计合理的键名 ,有利于防止键冲突和项目的可维护性。推荐使用 "业务名:对象名:唯一标识:属性" 作为键名。
- 例如:MySQL 的数据库名为
vs,用户表名为user_info,键名可以是"vs:user_info:2333"或"vs:user_info:2333:name"。 - 如果当前 Redis 只会被一个业务使用,可以省略业务名,如
"user:2333:friends:messages:6666"可以被"u:2333:fr:m:666"代替。 - 简写的原因:键名过长会影响 Redis 性能,网络传输需要成本
思考:
Redis 缓存策略
- 热点数据: 经常用来存储频繁被访问的数据。
- 缓存定义: 结合业务场景有很多种方式。
- 把最近使用到的数据作为热点数据。(隐含了一层假设:某个数据一旦被用到了,那么很可能在这段时间就会反复用到)
存在一个明显的问题:
随着时间的推移,肯定会有越来越多的 key 在 redis 上访问不到,从而从 mysql 读取并写入 redis 了。此时 redis 中的数据是不是就越来越多嘛??
- 过期时间: 在把数据写给 redis 的同时,给这个 key 设置一个过期时间。详见Redis#3 通用命令 | 数据类型 | 内部编码 | 单线程 | 快的原因 定时器部分的介绍
- 淘汰策略: Redis 也在内存不足的时候,提供了淘汰策略。(后面再说)
2. 计数 (Counter) 功能
- 应用场景 :许多应用使用 Redis 作为计数的基础工具,实现快速计数、查询缓存,数据可以异步处理或落地到其他数据源。

示例:统计视频播放次数
long IncrVideoCounter(long vid) {
String key = "video:" + vid;
long count = Redis 执行命令:incr key;
return count;
}- 注意 :实际开发一个成熟、稳定的计数系统面临更多挑战,如防作弊、按不同维度计数、避免单点问题、数据持久化到底层数据源等。
- 根据实际的业务需求设计场景
3. 共享会话 (Session)
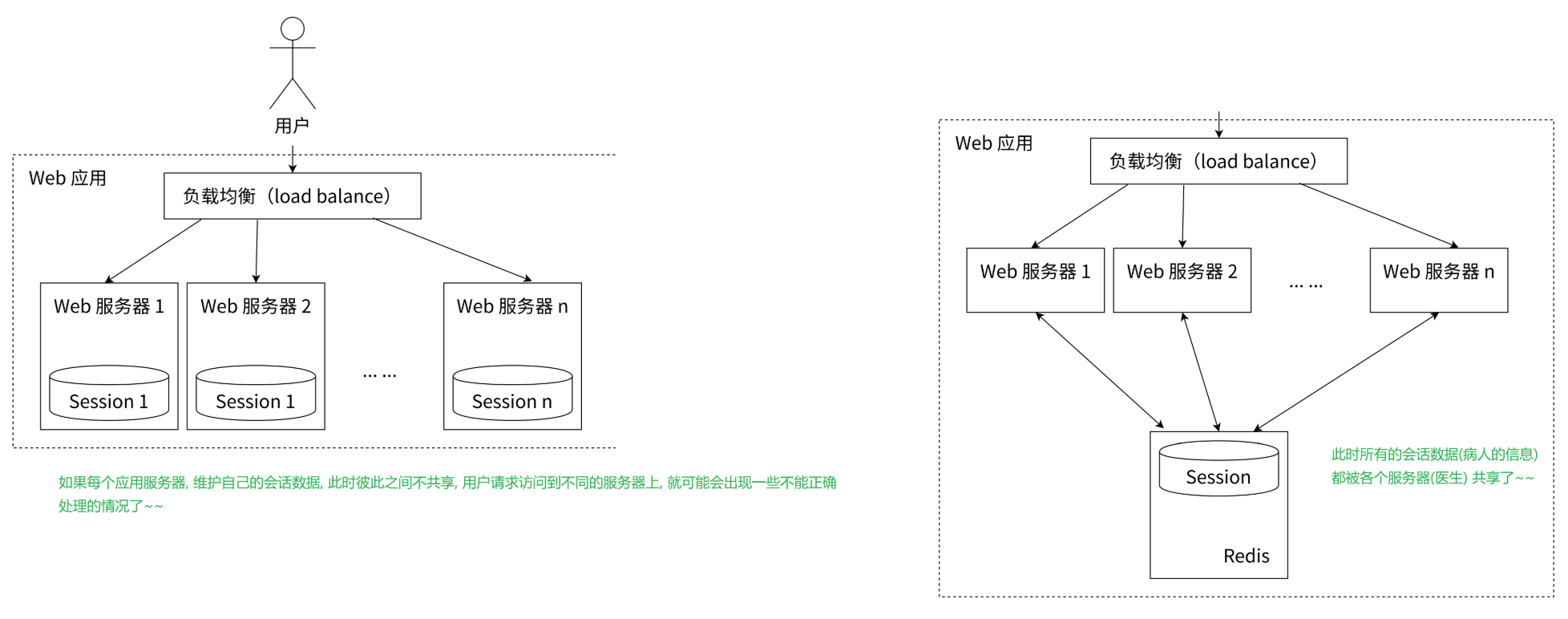
- 背景 :++分布式 Web 服务将用户的 Session 信息保存在各自的服务器中,负载均衡导致用户请求可能被分配到不同的服务器,造成用户需要重新登录的问题。++
生活中举例:
Cookie 和 Session
- Cookie: 浏览器存储数据的机制。
- Session: 服务器存储数据的机制。
实际案例:医院就诊
- 初次就诊:
-
- 我生病了,声带发炎,发烧到完全说不出话。
- 到医院挂号,挂了个专家号。
- 医生开了雾化理疗,先开了一周的药量,并建议一周后再来复查。
- 复查:
-
- 一周后去复查,发现初诊的医生不在。
- 新的医生之前没有给我看过病,不了解我的情况。
- 新医生通过刷我的就诊卡,看到了我之前的病例和治疗情况。
类比说明
- 病人:相当于客户端。
- 医生:相当于服务器。
- 就诊卡:相当于会话标识(如 Session ID)。
会话的概念
- 会话:客户端和服务端在交互过程中产生的专属于该客户端的中间状态数据。
- 目的:确保服务器能够识别和记住客户端的多次访问状态。
多服务器环境
- 多个医生:多个服务器。
- 负载均衡:服务器以负载均衡的方式提供服务。
- 问题:同一个客户端多次访问可能遇到不同的服务器。
- 解决方案:
-
- 共享会话数据 :就诊卡的使用,需要存在:使用一套系统记录客户端的会话数据,让多个服务器共享这些数据。
会话管理的重要性
- 一致性:确保客户端在多次访问中的一致性体验。
- 数据共享:多个服务器之间共享会话数据,避免因服务器切换导致的信息丢失。
解决方案
- 使用 Redis 集中管理 Session 信息,确保无论用户被均衡到哪台 Web 服务器上,都能从 Redis 中查询和更新 Session 信息。
4. 示例:手机验证码

- 用户在登录的时候,为了保证用户账号的安全,我们会使用验证码.
- 当用户登录的时候,redis就会在服务器中保存一个与用户对应的验证码,这个验证码具有过期时间(比如在5分钟内有效).
- 在用户输入验证码之后,会从redis中查询对应的键值对,校验用户的验证码.
- 当然为了用户反复接收验证码,导致redis压力过大,一般规定在一分钟之内,最多接收一次验证码,如果手机没有验证码,可以尝试在一分钟之后重新获取验证码.
此功能可以⽤以下伪代码说明基本实现思路:
String SendCapcha(String phoneNumber) {
String key = "shortMsg:limit:" + phoneNumber;
// 设置过期时间为 1 分钟
// 使用 NX,只在不存在 key 时才能设置成功
bool r = Redis 执行命令:set key ex 60 nx;
if (r == false) {
// 说明之前设置过该手机的验证码了
long c = Redis 执行命令:incr key;
if (c > 5) {
// 说明超过一分钟 5 次的限制了
// 限制发送
return null;
}
}
// 说明要么之前没有设置过手机的验证码;要么次数没有超过 5 次
String validationCode = 生成随机的 6 位数的验证码();
String validationKey = "validation:" + phoneNumber;
// 验证码 5 分钟内有效
Redis 执行命令:set validationKey validationCode ex 300;
// 返回验证码,随后通过手机短信发送给用户
return validationCode;
}
// 验证用户输入的验证码是否正确
bool VerifyCode(String phoneNumber, String validationCode) {
String validationKey = "validation:" + phoneNumber;
String value = Redis 执行命令:get validationKey;
if (value == null) {
// 说明没有这个手机的验证码记录,验证失败
return false;
}
if (value.equals(validationCode)) {
return true;
} else {
return false;
}
}