**论文速读|**MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
论文信息:

简介:
本文的背景是多模态大型语言模型(MLLMs )的快速发展,这些模型在理解和响应视觉输入方面展现出了增强的能力,通常被称为多模态"指令遵循"。随着这些模型的进步,需要有相应的基准测试来衡量它们在遵循复杂指令方面的能力。现有的基准测试主要分为固定形式的视觉问答(VQA)和自由形式的对话,但这些测试通常只粗略评估模型对指令的遵循能力,对于精确遵循复杂指令的能力评估较少。本文的动机是创建一个新的基准测试MIA-Benc h ,以推动MLLMs 在实际应用中的精确性和可靠性,确保模型输出不仅符合指令的一般意图,而且完全匹配提供的确切规格。通过建立更严格的标准,作者希望推动模型精度和可靠性的边界,并为未来的MLLM训练方法提供指导。
论文方法:

本文提出了MIA-Bench,这是一个新的基准测试,专门设计用来评估MLLMs严格遵循"指令遵循"的能力。
MIA-Bench包含400个精心制作的图像-提示对,覆盖了动物、食物、地标、体育、艺术、景观、文本等多样化的图像内容,以覆盖真实世界场景的广泛范围。
这些提示具有不同的复杂性级别,并且是组合性的,包含五个基础指令类别,旨在探究模型的语言灵活性、语法准确性和描述忠实度。包括描述、长度限制、提及、类型、语法、数学、视角和OCR(光学字符识别)等子指令类别。
论文实验:
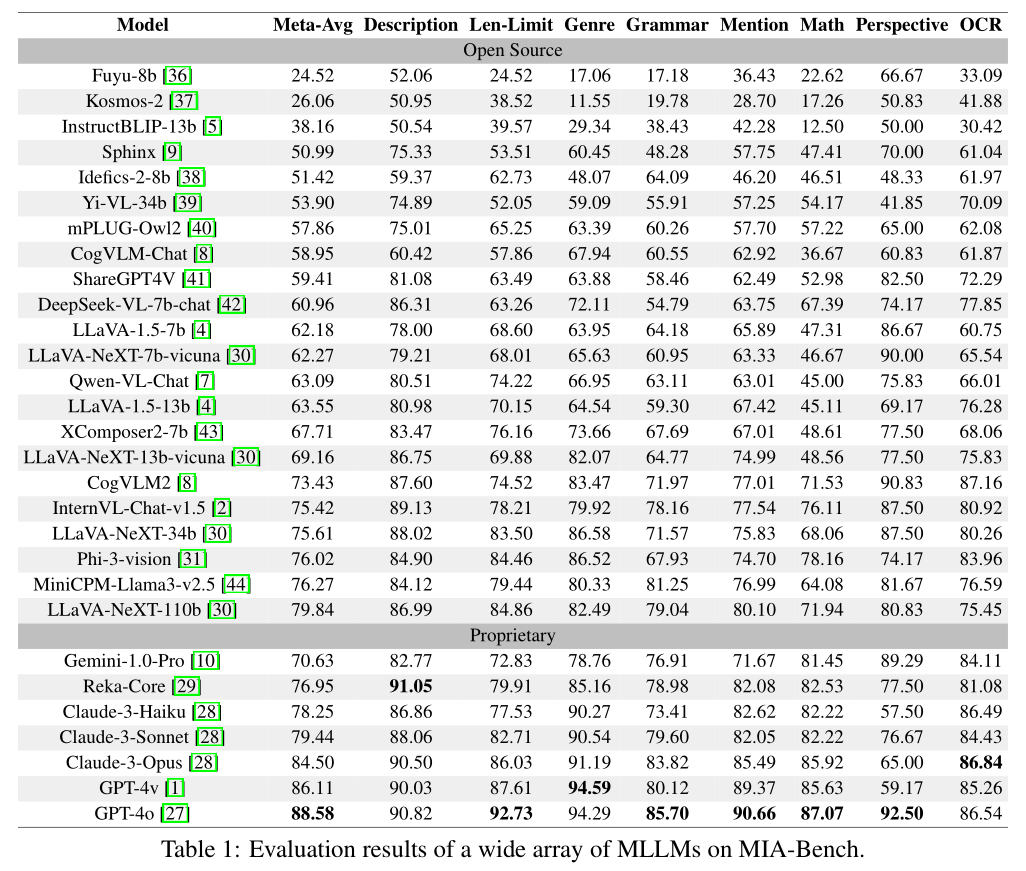
根据Table 1,论文的实验部分主要涉及了对多模态大型语言模型(MLLMs)在MIA-Bench基准测试上的性能评估。
实验共评估了29个流行的MLLMs,包括封闭源模型(如GPT-4o、Gemini Pro、Claude-3、Reka)和开源模型(如LLaVANeXT、Intern-VL-Chat-1.5、CogVLM2、Phi-3-Vision)。
评估指标涵盖了多个方面,包括模型对指令的描述能力(Description)、长度限制(Length Limit)、提及(Mention)、类型(Genre)、语法(Grammar)、数学(Math)、视角(Perspective)和光学字符识别(OCR)。
GPT-4o模型在整体上表现最佳,总分为88.58,显示出在不同指令遵循类别中的优越性。Reka模型在描述内容的准确性方面表现最好,分数超过90,表明这些模型在生成连贯且上下文适宜的文本方面表现良好。
在类型(Genre)类别中,GPT-4v和GPT-4o表现出色,分数超过94,显示出对语言细微差别的卓越掌握。
GPT-4o在语法(Grammar)类别中得分最高,为85.70,表明其在语法正确性和句子结构方面符合特定指令要求的能力较强。在尊重规定长度限制方面,GPT-4o得分为92.73,这对于需要简洁精确回答的任务至关重要。