说明
本文的数据集来源于英雄联盟评论数据集,旨在挖掘 英雄联盟评论数据中的主题兴趣标签。本次实验是基于LDA模型实现用户的兴趣建模,即从英雄联盟评论数据中生成用户感兴趣的标签。
本文 是基于英雄联盟的评论数据集,采用基于LDA主题生成模型,研发一种高效的兴趣标签生成模型。通过LDA主题模型,实现更准确、可靠的标签生成。同时,结合数据处理结束,对对英雄联盟等进行标签生成,并进行进一步的标签分类、聚类和热度分析,以揭示英雄联盟玩家用户兴趣和需求的深层信息。
需要用到的数据集和停用词表下载:英雄联盟评论数据集
目录
[1.1 依赖包安装](#1.1 依赖包安装)
[1.2 导入依赖包](#1.2 导入依赖包)
[2.1 数据加载](#2.1 数据加载)
[2.2 数据异常值处理](#2.2 数据异常值处理)
[2.3 中文文本处理](#2.3 中文文本处理)
[2.4 情感分析](#2.4 情感分析)
[2.5 jieba分词](#2.5 jieba分词)
[3.1 词语计数](#3.1 词语计数)
[3.2 词云图掩码图准备](#3.2 词云图掩码图准备)
[3.3 生成词云图](#3.3 生成词云图)
[3.4 文本频率表生成](#3.4 文本频率表生成)
[6.1 LDA模型评估与选择代码实现](#6.1 LDA模型评估与选择代码实现)
[6.2 代码详解](#6.2 代码详解)
[(1)函数定义 lda_model_values](#(1)函数定义 lda_model_values)
[(3)调用 lda_model_values 函数](#(3)调用 lda_model_values 函数)
[7.1 LDA主题建模实现](#7.1 LDA主题建模实现)
[7.2 上述代码详解](#7.2 上述代码详解)
[8.1 LDA模型主题关键词提取与导出实现](#8.1 LDA模型主题关键词提取与导出实现)
[8.2 代码详解](#8.2 代码详解)
[9.1 实现](#9.1 实现)
[9.2 代码详解](#9.2 代码详解)
[(1)启用Jupyter Notebook内嵌可视化](#(1)启用Jupyter Notebook内嵌可视化)
1、环境配置和导入依赖包
1.1 依赖包安装
此次实验是在notebook环境中实现的,首先要安装项目所需要的依赖包,例如:
python
!pip install gensim -i https://mirrors.aliyun.com/pypi/simple/
!pip install pyLDAvis -i https://mirrors.aliyun.com/pypi/simple/
!pip install snownlp -i https://mirrors.aliyun.com/pypi/simple/
!pip install wordcloud -i https://mirrors.aliyun.com/pypi/simple/
......需要什么依赖包就安装什么依赖包,就不一一列举出来了。
1.2 导入依赖包
在环境中导入依赖包:
python
import numpy as np
import pandas as pd
import jieba
import gensim
from gensim.models import LdaModel, CoherenceModel
from gensim.corpora import Dictionary
from gensim import corpora, models
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
from PIL import Image
import warnings
import codecs
import re
import time
import matplotlib
from snownlp import SnowNLP
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 忽略警告
warnings.filterwarnings("ignore")2、数据预处理
2.1 数据加载
首先是加载数据集,因为数据集存在一列"Unnamed:0"是多余的,所以需要删除掉该列,加载数据集并删除多余的列,如下::
python
df=pd.read_csv("../datasets/extopic.csv")
df = df.drop(columns=['Unnamed: 0'])
df- 运行结果如下:

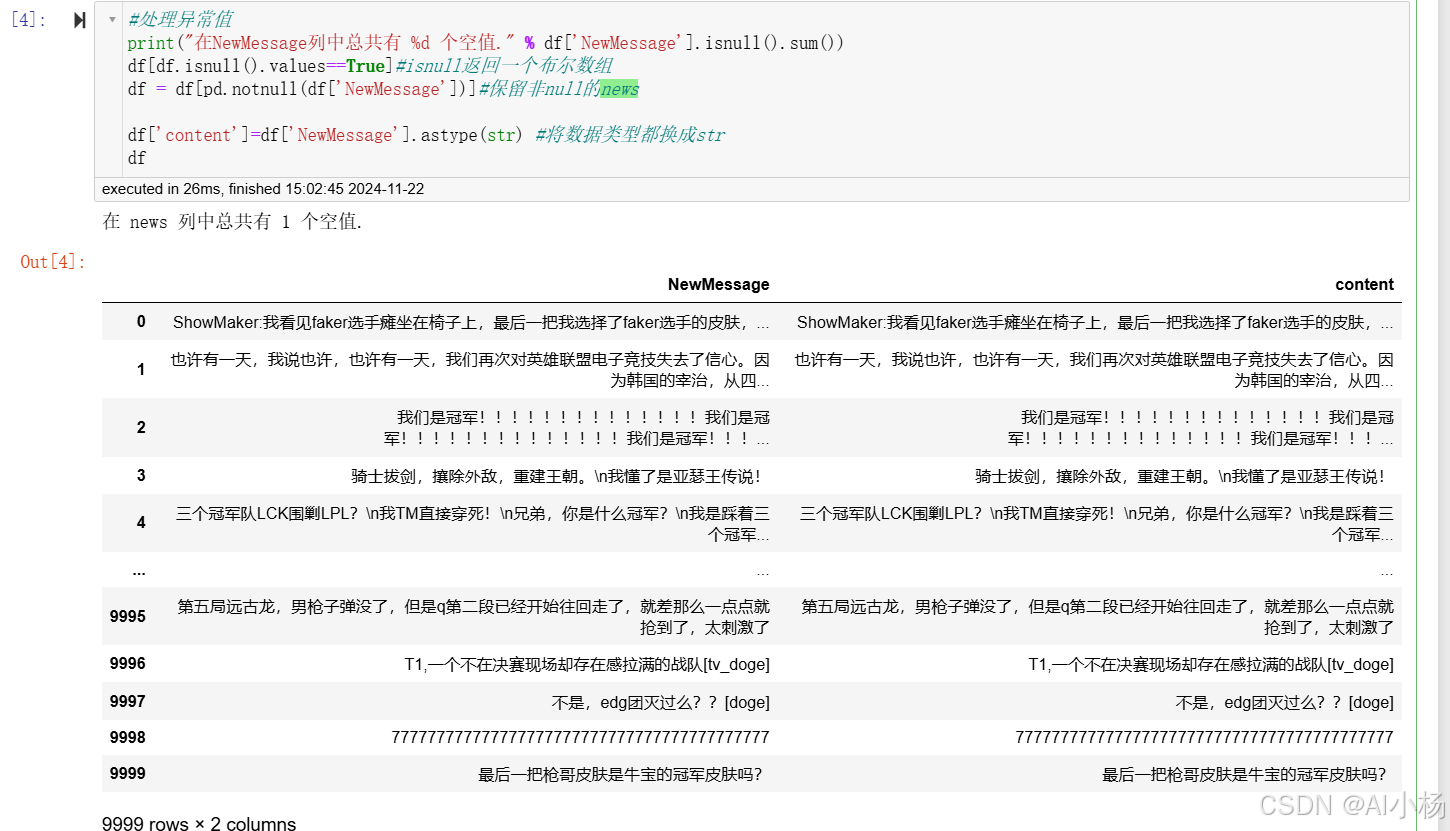
2.2 数据异常值处理
异常值处理:
python
#处理异常值
print("在NewMessage列中总共有 %d 个空值." % df['NewMessage'].isnull().sum())
df[df.isnull().values==True]#isnull返回一个布尔数组
df = df[pd.notnull(df['NewMessage'])]#保留非null的news
df['content']=df['NewMessage'].astype(str) #将数据类型都换成str
df- 运行截图
2.3 中文文本处理
中文文本处理,包括提取中文字符、过滤掉单个汉字以及去重,如下:
python
#中文文本处理
def extract_chinese(text):
chinese_pattern = re.compile(r'[\u4e00-\u9fa5]+')
chinese_words = chinese_pattern.findall(text)
return ' '.join(chinese_words)
df['content'] = df['content'].apply(extract_chinese)
df['content'] = df['content'].apply(lambda x: ' '.join([word for word in x.split() if len(word) > 1]))
df.drop_duplicates(inplace=True)
df.head()- 运行截图

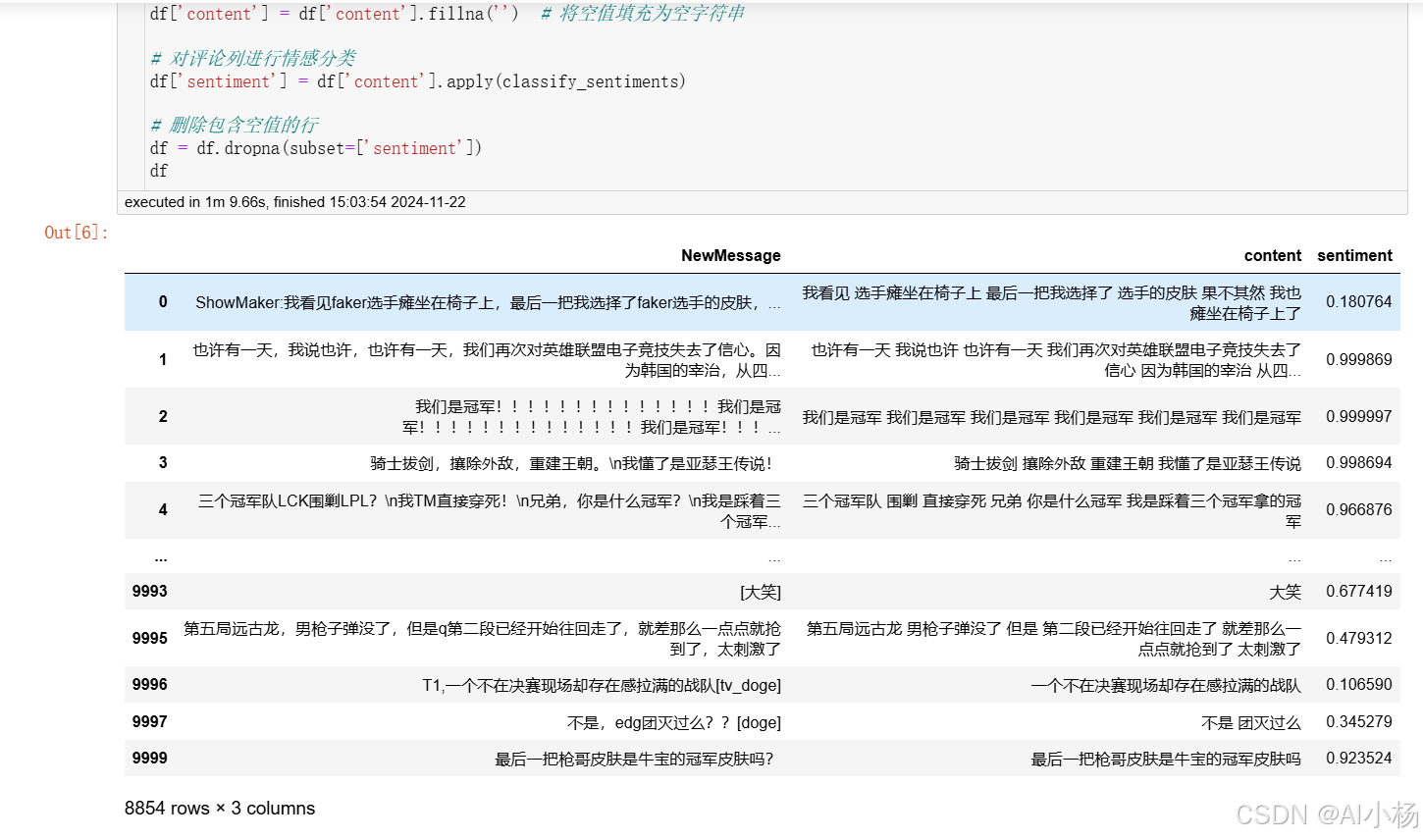
2.4 情感分析
情感分析,判断文本的情感方向:
python
# 定义情感分类函数
def classify_sentiment(sentiment):
if sentiment >= 0.5:
return 'positive'
else:
return 'negative'
def classify_sentiments(text):
if pd.isna(text) or text.strip() == '':
return None # 返回 None 或者其他默认值
s = SnowNLP(text)
sentiment = s.sentiments
return sentiment
# 处理空值
df['content'] = df['content'].fillna('') # 将空值填充为空字符串
# 对评论列进行情感分类
df['sentiment'] = df['content'].apply(classify_sentiments)
# 删除包含空值的行
df = df.dropna(subset=['sentiment'])
df - 运行截图
2.5 jieba分词
(1)文本处理结果查看
jieba分词前,我们可以查看每一个句子的完整句子,例如输出前5条句子的完整句子:
python
content = df['content'].values.tolist()
content[:5]- 运行截图

(2)jieba分词
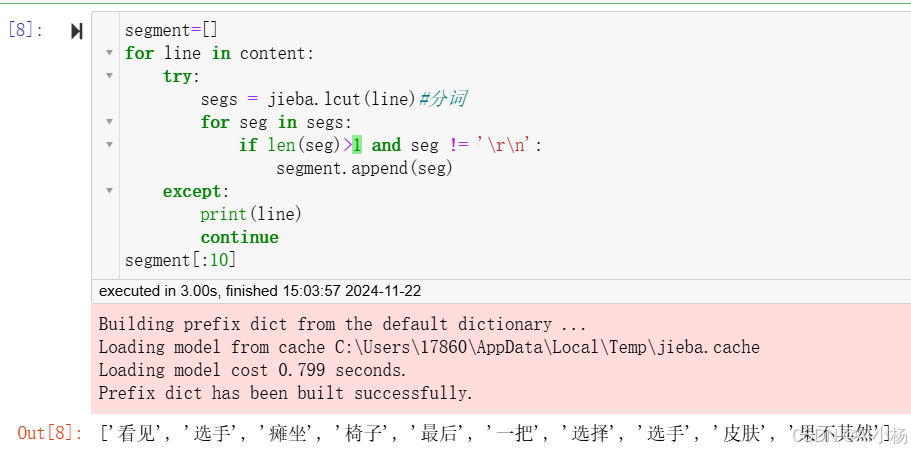
jieba分词并输出前十个词,如下:
python
segment=[]
for line in content:
try:
segs = jieba.lcut(line)#分词
for seg in segs:
if len(seg)>1 and seg != '\r\n':
segment.append(seg)
except:
print(line)
continue
segment[:10]- 运行截图
(3)停用词过滤
读取停用词表,然后停用词过滤,停用词表用的是这个:停用词表
- 停用词过滤如下:
python
# 读取停用词文件
try:
stopwords = pd.read_csv(r'../datasets/stop_words.txt', header=None, encoding='utf-8', names=['stopword'], on_bad_lines='skip')
except pd.errors.ParserError as e:
print(f"ParserError: {e}")
stopwords = pd.read_csv(r'../datasets/stop_words.txt', header=None, encoding='utf-8', names=['stopword'], delimiter='\t', on_bad_lines='skip')
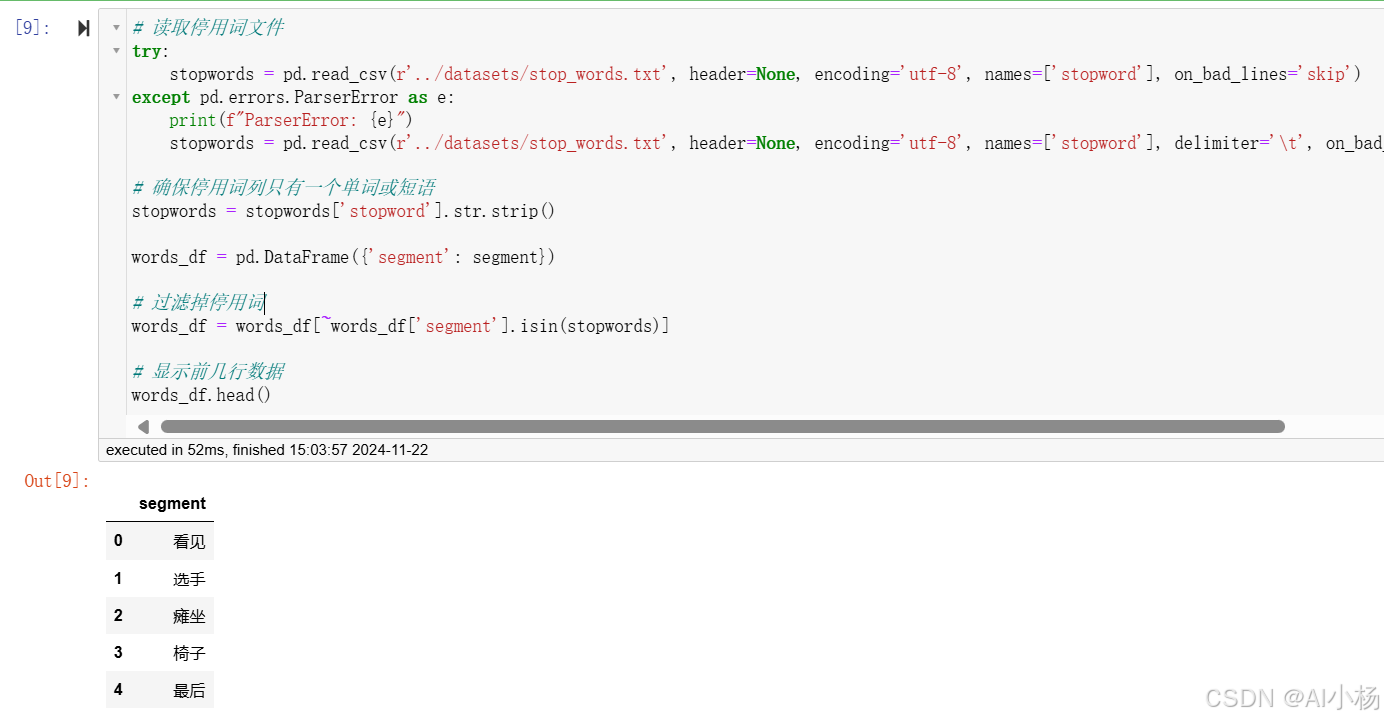
# 确保停用词列只有一个单词或短语
stopwords = stopwords['stopword'].str.strip()
words_df = pd.DataFrame({'segment': segment})
# 过滤掉停用词
words_df = words_df[~words_df['segment'].isin(stopwords)]
# 显示前几行数据
words_df.head()- 运行结果:
3、生成词云图
3.1 词语计数
接下来是对每一个词语进行统计计数,通过降序排列,按照数量从高到底的方式对词语进行排序,如下:
python
words_stat=words_df.groupby(by=['segment'])['segment'].agg([("计数",np.size)])
words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
words_stat.head()- 运行截图
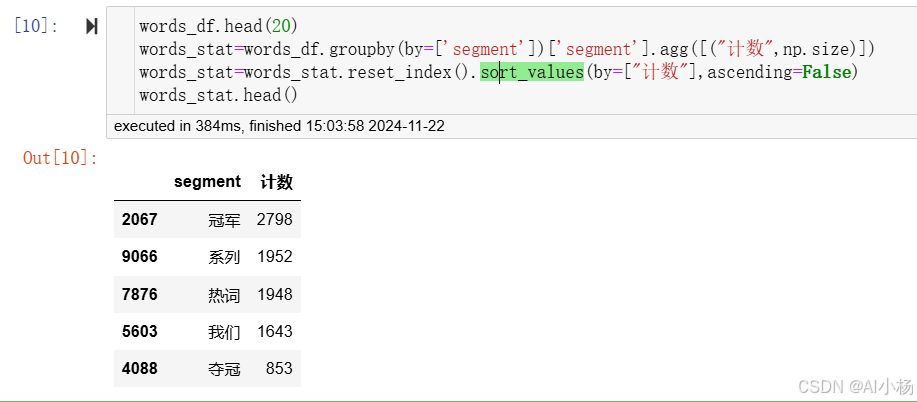
如上图可以发现,在所有词语中,"冠军"这一词出现的次数最多,出现了2798次,其次是"系列"。
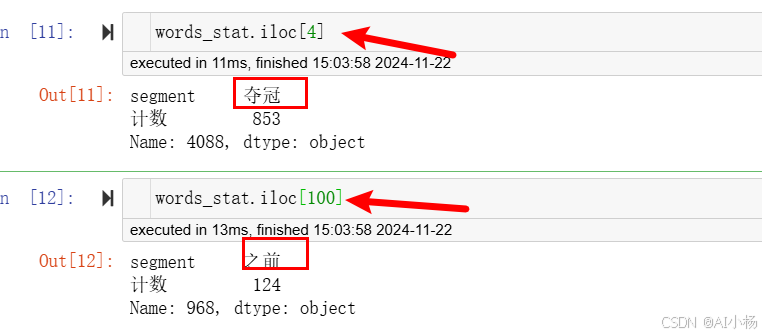
我们也可以单独查看排名,例如我想知道排名第四和第一百的是哪个词语,如下:
python
words_stat.iloc[4]
words_stat.iloc[100]- 结果:
3.2 词云图掩码图准备
生成词云图前要准备一张掩码图,掩码图的作用是指导词云图生成的形状,例如有中国地图形状的,有爱心形状的等等各种各样的图像。
那么词云图掩码图如何找呢?其实很简单,直接搜就可以搜出来,比如说搜:"词云图背景图":
我最终找到了一张哆啦A梦形状的背景图,例如说将其命名为"词云图掩码图.jpg"保存到指定位置,如下:

3.3 生成词云图
读取之前保存的词云图掩码图(背景图),然后创建词云对象,生成词云图,如下:
python
# 读取掩码图片
mask_pic = np.array(Image.open(r"../datasets/词云图掩码图.jpg"))
# 创建词云对象
wordcloud = WordCloud(
width=300,
height=200,
scale=4,
mask=mask_pic,
font_path='simhei.ttf',
background_color='white',
max_font_size=80
)
# 将词频数据转换为字典
word_frequence = {x[0]: x[1] for x in words_stat.head(220).values}
# 生成词云
wordcloud = wordcloud.fit_words(word_frequence)
# 显示词云图
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# 保存图片
wordcloud.to_file('词云.png')- 词云图结果展示:

3.4 文本频率表生成
此时可以对每个词语的频率生成一个表格吗,进行保存,如下:
python
words_stat.to_csv(r'../datasets/文本频率表.csv',index=False)- 就将文本频率表保存到指定位置了,文本频率表如下:

4、词频统计(TF-IDF)
基于TF-IDF的词频统计:计算每个特征词的平均TF-IDF权重
python
comments = content
segmented_comments = []
for comment in comments:
words = jieba.cut(comment)
filtered_words = [word for word in words if word not in stopwords]
segmented_comments.append(" ".join(filtered_words))
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
# 使用评论数据拟合TF-IDF向量化器并转换数据
tfidf_matrix = tfidf_vectorizer.fit_transform(segmented_comments)
# 获取特征词列表
feature_names = tfidf_vectorizer.get_feature_names_out()
# 将TF-IDF矩阵转换为DataFrame,并加上特征词作为列名
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names)
# 计算每个特征词的平均TF-IDF权重
avg_tfidf = tfidf_df.mean().sort_values(ascending=False)
print(avg_tfidf)
avg_tfidf.to_csv(r'../datasets/词语权重表.csv')- 每个特征词的TF-IDF权重:

5、构建词典和语料库
读取停用词文件,对文本进行预处理(包括分词和去除停用词),然后构建词典和语料库,以便后续进行主题建模任务。
- 构建词典和语料库:
python
stop_words_file = '../datasets/stop_words.txt'
stop_words = set()
with codecs.open(stop_words_file, 'r', 'utf-8') as f:
for word in f:
stop_words.add(word.strip())
texts = [list(filter(lambda x: x not in stop_words, jieba.cut(text.replace(" ", "").strip()))) for text in content]
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
corpus6、LDA模型评估与选择
6.1 LDA模型评估与选择代码实现
下列代码的主要目的是评估不同主题数量下的LDA(Latent Dirichlet Allocation)模型的表现。LDA是一种常用于文本数据的主题模型技术,它能够从文档集合中自动发现潜在的主题结构。通过调整模型中的主题数量,可以探索出最佳的主题数,从而优化模型的表现。
- 实现如下:
python
# 定义 LDA 模型评估函数
def lda_model_values(num_topics, corpus, dictionary, texts):#用于评估不同主题数量下的 LDA 模型的困惑度和一致性
x = [] # x轴
perplexity_values = [] # 困惑度
coherence_values = [] # 一致性
model_list = [] # 存储对应主题数量下的 LDA 模型,便于生成可视化网页
for topic in range(num_topics):
print("主题数量:", topic + 1)
lda_model = models.LdaModel(corpus=corpus, num_topics=topic + 1, id2word=dictionary, chunksize=2000, passes=20, iterations=400)
model_list.append(lda_model)
x.append(topic + 1)
perplexity_values.append(lda_model.log_perplexity(corpus))
coherencemodel = models.CoherenceModel(model=lda_model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
print("该主题评价完成\n")
return model_list, x, perplexity_values, coherence_values
# 调用准备函数
model_list, x, perplexity_values, coherence_values = lda_model_values(8, corpus, dictionary, texts)
# 绘制困惑度和一致性折线图
fig = plt.figure(figsize=(15, 5))
ax1 = fig.add_subplot(1, 2, 1)
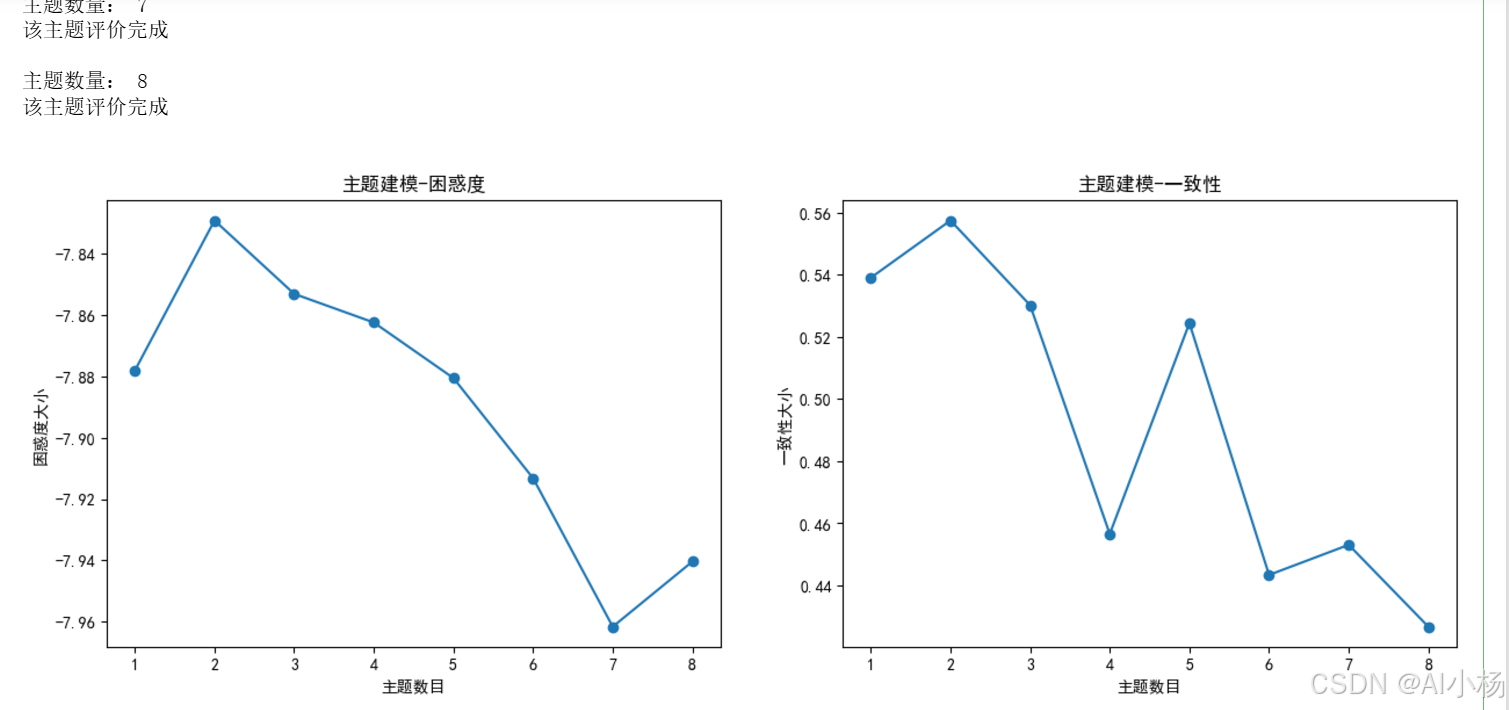
plt.plot(x, perplexity_values, marker="o")
plt.title("主题建模-困惑度")
plt.xlabel('主题数目')
plt.ylabel('困惑度大小')
plt.xticks(np.linspace(1, 8, 8, endpoint=True)) # 保证 x 轴刻度为 1
ax2 = fig.add_subplot(1, 2, 2)
plt.plot(x, coherence_values, marker="o")
plt.title("主题建模-一致性")
plt.xlabel("主题数目")
plt.ylabel("一致性大小")
plt.xticks(np.linspace(1, 8, 8, endpoint=True))
plt.show()- 运行截图:
6.2 代码详解
(1)函数定义 lda_model_values
此函数接收四个参数:
num_topics:想要尝试的最大主题数量。corpus:文档-词频矩阵,即每个文档中各单词出现的频率。dictionary:所有文档中出现的单词及其索引组成的字典。texts:原始文档列表,每个文档是一系列单词的列表。
(2)函数内部执行以下操作:
- 初始化三个列表分别存储主题数量、模型的困惑度和一致性值。
- 遍历从1到
num_topics的主题数量,对于每一个主题数量,创建一个LDA模型。 - 使用当前主题数量训练LDA模型,并计算模型的困惑度(log_perplexity)和一致性(coherence),然后将这些值添加到相应的列表中。
- 打印每一步的信息,以便追踪模型训练进度。
- 返回训练好的模型列表以及与之对应的主题数量、困惑度和一致性值列表。
(3)调用 lda_model_values 函数
这里调用了上面定义的函数,传入了最大主题数量为8,以及事先准备好的语料库、字典和文本数据。这会返回一系列模型及其评估指标。
(4)绘制图形
最后,使用matplotlib库绘制两个图表来直观展示不同主题数量下的模型表现:
- 第一个图表显示了主题数量与模型困惑度之间的关系。困惑度是衡量模型好坏的一个指标,通常情况下,困惑度越低,模型对未见过的数据的预测能力越强。
- 第二个图表展示了主题数量与模型一致性之间的关系。一致性衡量的是主题的可解释性或语义清晰度,值越高表示主题间的关系更加紧密,主题的可理解性越好。
这两个图表帮助研究者选择一个既能保持良好的预测性能又能确保主题清晰度的主题数量,从而优化LDA模型的应用效果。
7、LDA主题建模
7.1 LDA主题建模实现
在确定了最佳主题数量后,构建最终的LDA模型,并输出各个主题的关键术语以及每个文档最可能属于的主题。
代码实现:
python
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, passes = 10,random_state=42)
#将这里的num_topics换成上述观测到的最佳建模主题数,数值应该取困惑度小同时一致性高的拐点,注意纵坐标!!!
#每次生成的曲线图和LDA气泡图可能不一样,因为该算法为无监督算法,所以每次训练的语料不一样
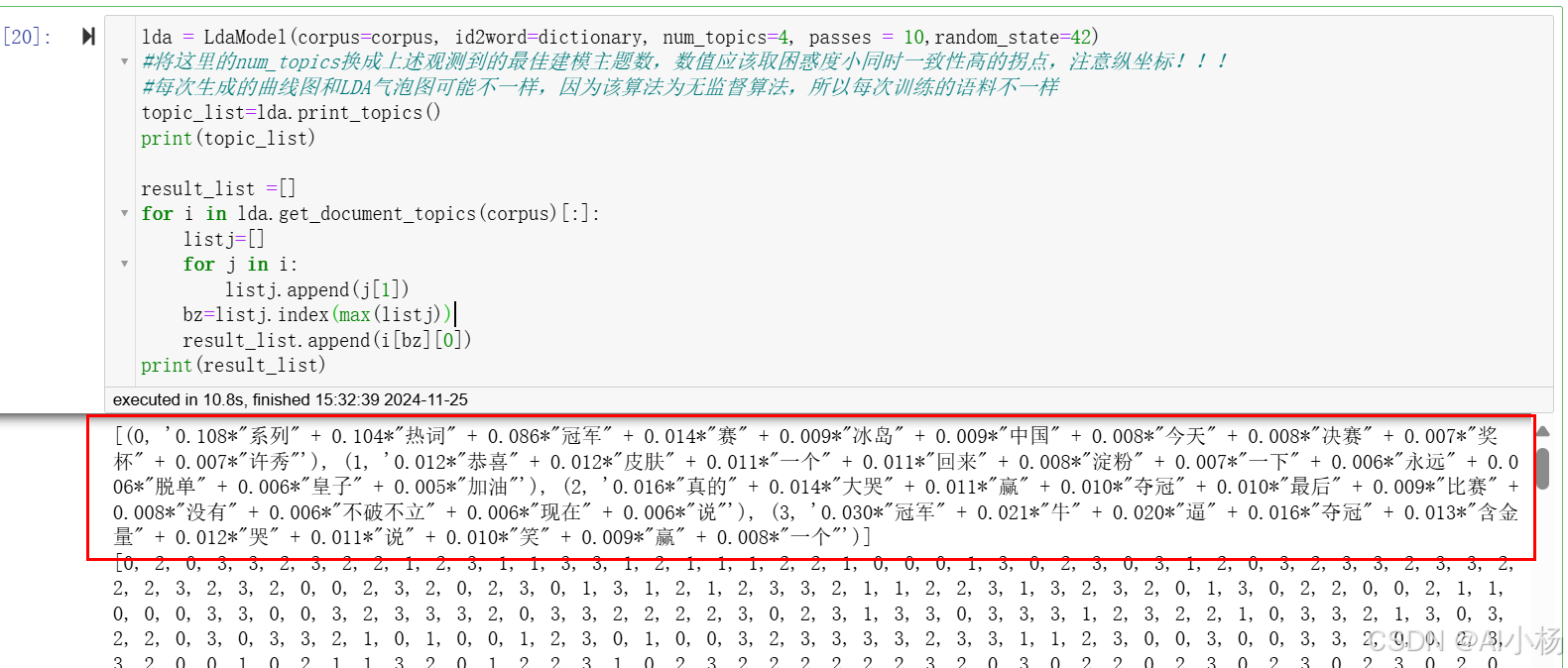
topic_list=lda.print_topics()
print(topic_list)
result_list =[]
for i in lda.get_document_topics(corpus)[:]:
listj=[]
for j in i:
listj.append(j[1])
bz=listj.index(max(listj))
result_list.append(i[bz][0])
print(result_list)- 运行截图:
7.2 上述代码详解
(1)构建LDA模型
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, passes=10, random_state=42)corpus:文档-词频矩阵。id2word:字典,包含文档中出现的所有单词及其对应的ID。num_topics:设置的主题数量,这里是一个示例值4,实际使用时应替换为你之前通过评估得到的最佳主题数量。passes:遍历整个语料库的次数,用来提高模型的稳定性。random_state:随机种子,确保每次运行结果的一致性。
(2)输出主题关键词
topic_list = lda.print_topics()
print(topic_list)
- 这段代码会打印出每个主题的前几个关键词及其权重。
print_topics()方法默认会显示每个主题的前10个关键词,可以通过传递额外的参数来改变这个数量。
(3)确定文档的主题归属
result_list = \[\]
for i in lda.get_document_topics(corpus)::
listj = \[\]
for j in i:
listj.append(j1) # 添加每个主题的概率值
bz = listj.index(max(listj)) # 找到概率最大的主题索引
result_list.append(ibz0) # 将该文档归类到概率最高的主题
print(result_list)
get_document_topics(corpus):获取每个文档在各个主题上的概率分布。- 对于每个文档,提取其在各个主题上的概率值,并找到其中的最大值,以此来决定该文档最有可能属于哪个主题。
result_list:最终存储每个文档最可能属于的主题编号。
(4)注意事项
- 主题数量的选择 :在实际应用中,
num_topics的值应当根据前面评估模型困惑度和一致性的结果来确定。通常会选择困惑度较低且一致性较高的主题数量作为最终模型的主题数量。 - 模型的非确定性 :由于LDA是一种无监督学习算法,每次训练的结果可能会有所不同,特别是在训练初期。为了减少这种不确定性,可以设置固定的随机种子(如代码中的
random_state=42)以确保实验的可重复性。 - 结果的解读:输出的主题关键词可以帮助理解每个主题的含义,而文档的主题归属则可以用于进一步的数据分析,比如聚类分析或者推荐系统等。
这段代码是一个完整的流程,从构建模型到输出结果,适用于文本数据的主题挖掘任务。
8、LDA模型主题关键词提取与导出
8.1 LDA模型主题关键词提取与导出实现
将LDA模型生成的主题和关键词信息整理成一个DataFrame,并导出为Excel文件以得到最终的兴趣标签。
- 代码实现:
python
topic_data = pd.DataFrame(columns=['主题', '关键词', '概率分数'])
for topic in topic_list:
topic_num, topic_terms = topic
terms = topic_terms.split('+')
for term in terms:
probability, word = term.split('*')
word = word.strip()
probability = probability.strip()
topic_data = pd.concat([topic_data, pd.DataFrame({'主题': [topic_num], '关键词': [word], '概率分数': [probability]})], ignore_index=True)
topic_data = topic_data.groupby('主题')['关键词'].apply(lambda x: ' '.join(x)).reset_index()
topic_data['关键词'] = topic_data['关键词'].replace('"', '', regex=True)
# 将 DataFrame 导出到 Excel 文件
topic_data.to_excel('../datasets/主题关键词概率分数.xlsx', index=False)- 找到生成的xlsx文件,如下:

可以看到基于英雄联盟评论数据集的兴趣主题标签就生成了。
8.2 代码详解
(1)初始化DataFrame
topic_data = pd.DataFrame(columns='主题', '关键词', '概率分数')
- 创建一个空的DataFrame,列名为'主题'、'关键词'和'概率分数'。
(2)处理主题和关键词
for topic in topic_list:
topic_num, topic_terms = topic
terms = topic_terms.split('+')
for term in terms:
probability, word = term.split('*')
word = word.strip()
probability = probability.strip()
topic_data = pd.concat(topic_data, pd.DataFrame({'主题': \[topic_num, '关键词': word, '概率分数': probability})], ignore_index=True)
topic_list:这是从LDA模型中获取的主题列表,每个元素是一个元组,包含主题编号和该主题的关键词及概率。topic_num, topic_terms = topic:将每个主题分解为主题编号和关键词字符串。terms = topic_terms.split('+'):将关键词字符串按+分割,得到每个关键词及其概率。probability, word = term.split('*'):将每个关键词字符串按*分割,得到概率和关键词。word = word.strip()和probability = probability.strip():去除关键词和概率两端的空白字符。pd.concat:将处理后的数据追加到DataFrame中。
(3)整合关键词
topic_data = topic_data.groupby('主题')'关键词'.apply(lambda x: ' '.join(x)).reset_index()
topic_data'关键词' = topic_data'关键词'.replace('"', '', regex=True)
groupby('主题')['关键词'].apply(lambda x: ' '.join(x)).reset_index():按主题分组,将每个主题的关键词合并成一个字符串。replace('"', '', regex=True):移除关键词字符串中的双引号。
(4)导出生成的用户兴趣标签
topic_data.to_excel('../datasets/主题关键词概率分数.xlsx', index=False)
to_excel:将DataFrame导出为Excel文件,路径为../datasets/主题关键词概率分数.xlsx,不保存索引。
9、LDA模型可视化与保存
9.1 实现
使用pyLDAvis库来可视化LDA模型,并将可视化结果保存为HTML文件。pyLDAvis是一个非常强大的工具,用于交互式地探索LDA模型的主题分布和关键词。
- 代码实现:
python
pyLDAvis.enable_notebook()
data = pyLDAvis.gensim.prepare(lda, corpus, dictionary)
pyLDAvis.save_html(data, '../datasets/topic.html')- 找到生成的topic.html,点击查看:
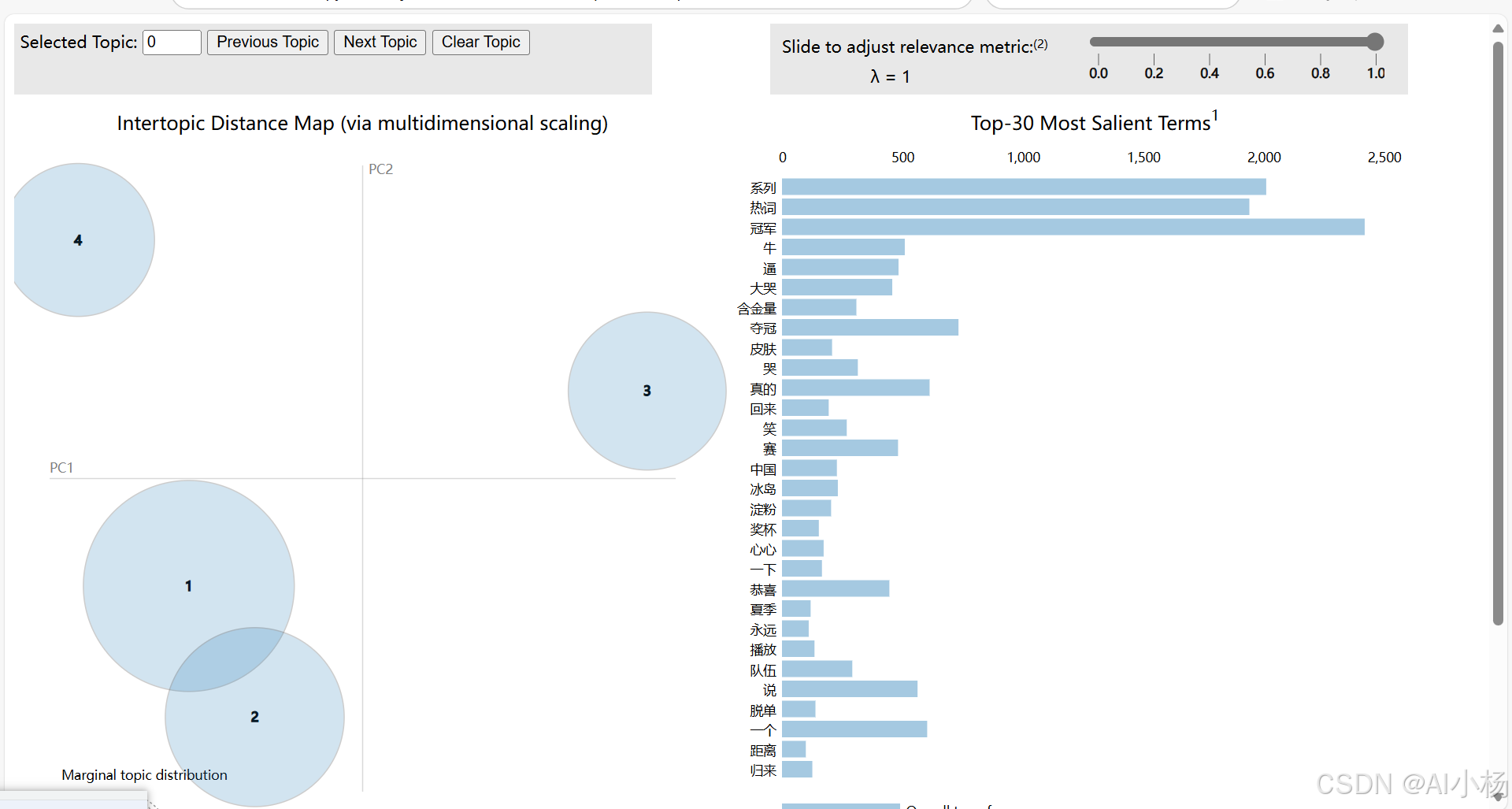
可以看到有四个主题,对应1、2、3、4四个圆圈,点击对应的主题可以看到对应的值的分布情况,如下:
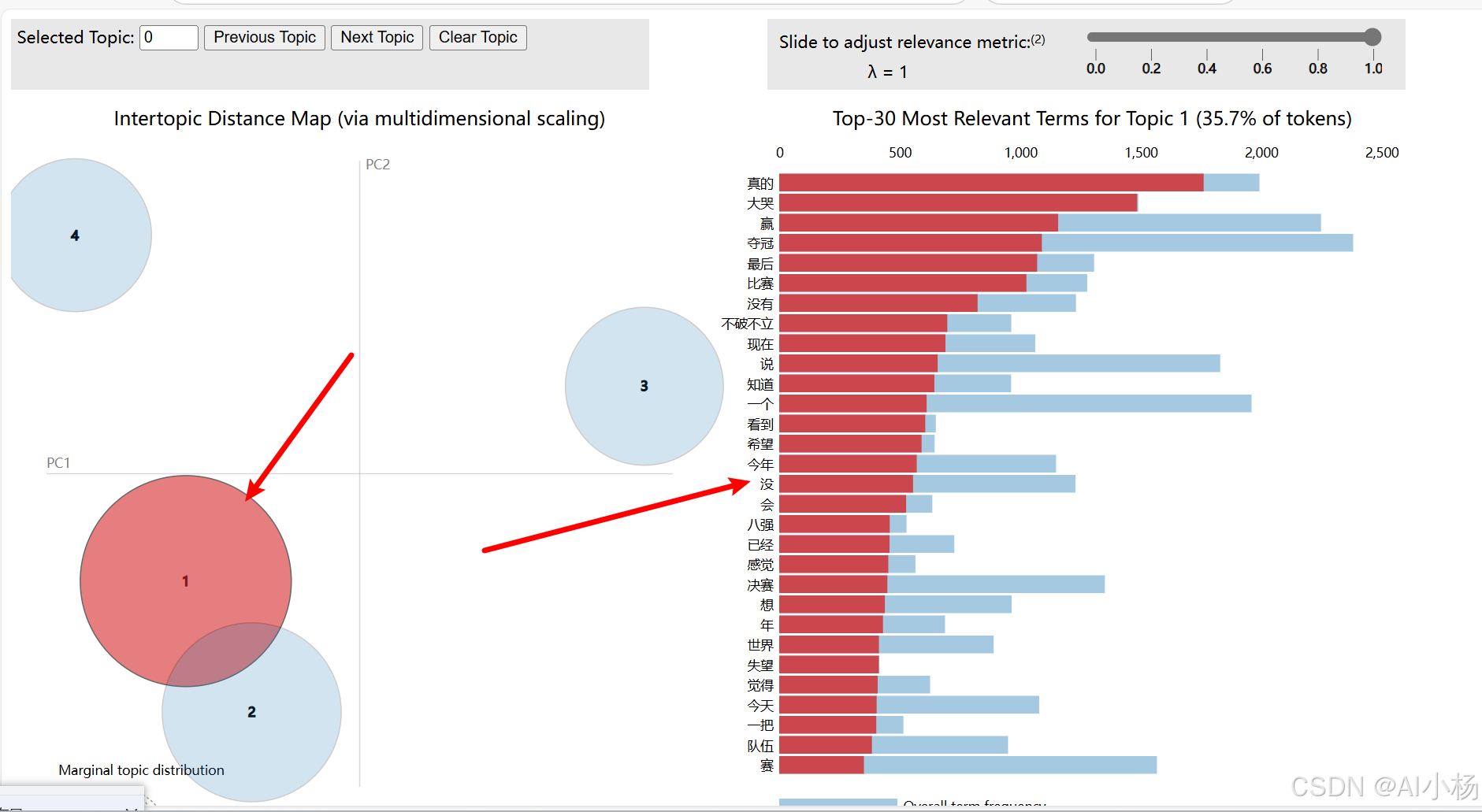
9.2 代码详解
(1)启用Jupyter Notebook内嵌可视化
pyLDAvis.enable_notebook()
这行代码启用Jupyter Notebook中的内嵌可视化功能,使得可以直接在Notebook中显示pyLDAvis生成的交互式图表。如果你不在Jupyter Notebook环境中运行代码,可以跳过这一步。
(2)准备可视化数据
data = pyLDAvis.gensim.prepare(lda, corpus, dictionary)
- lda:已经训练好的LDA模型。
- corpus:文档-词频矩阵。
- dictionary:包含所有单词及其索引的字典。
- prepare:这个函数将LDA模型、语料库和字典转换为pyLDAvis所需的格式,以便进行可视化。
(3)保存可视化结果为HTML文件
pyLDAvis.save_html(data, '../datasets/topic.html')
- save_html:将pyLDAvis生成的可视化结果保存为HTML文件,这样可以在浏览器中打开并查看。
- data:由prepare函数生成的可视化数据。
- '../datasets/topic.html':保存HTML文件的路径。
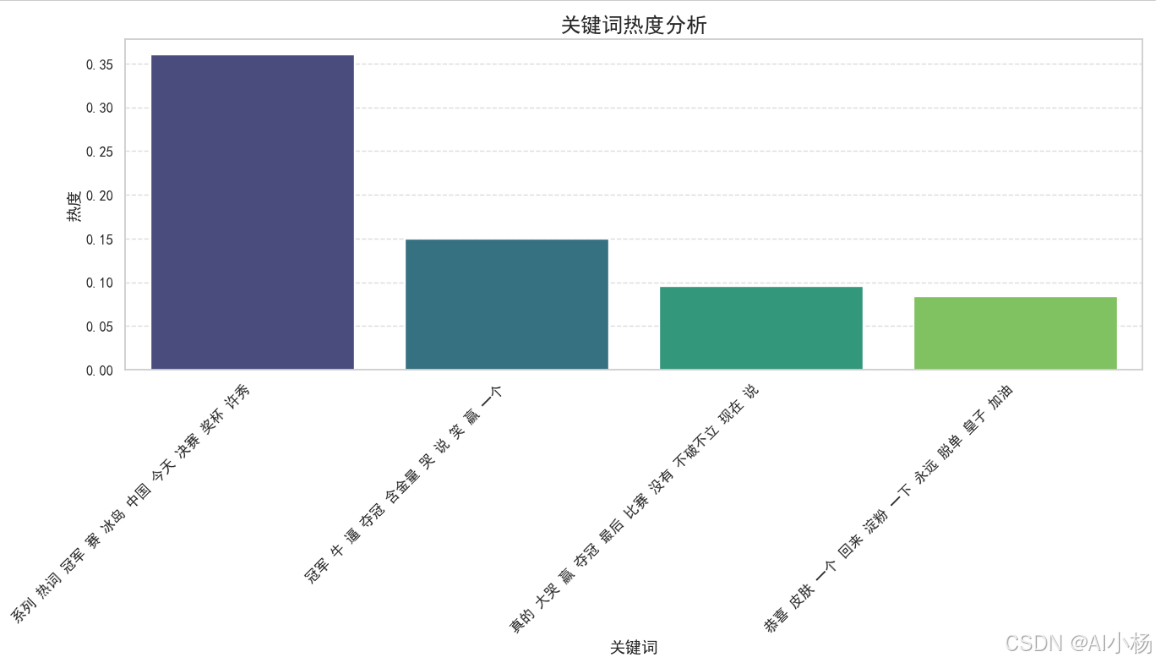
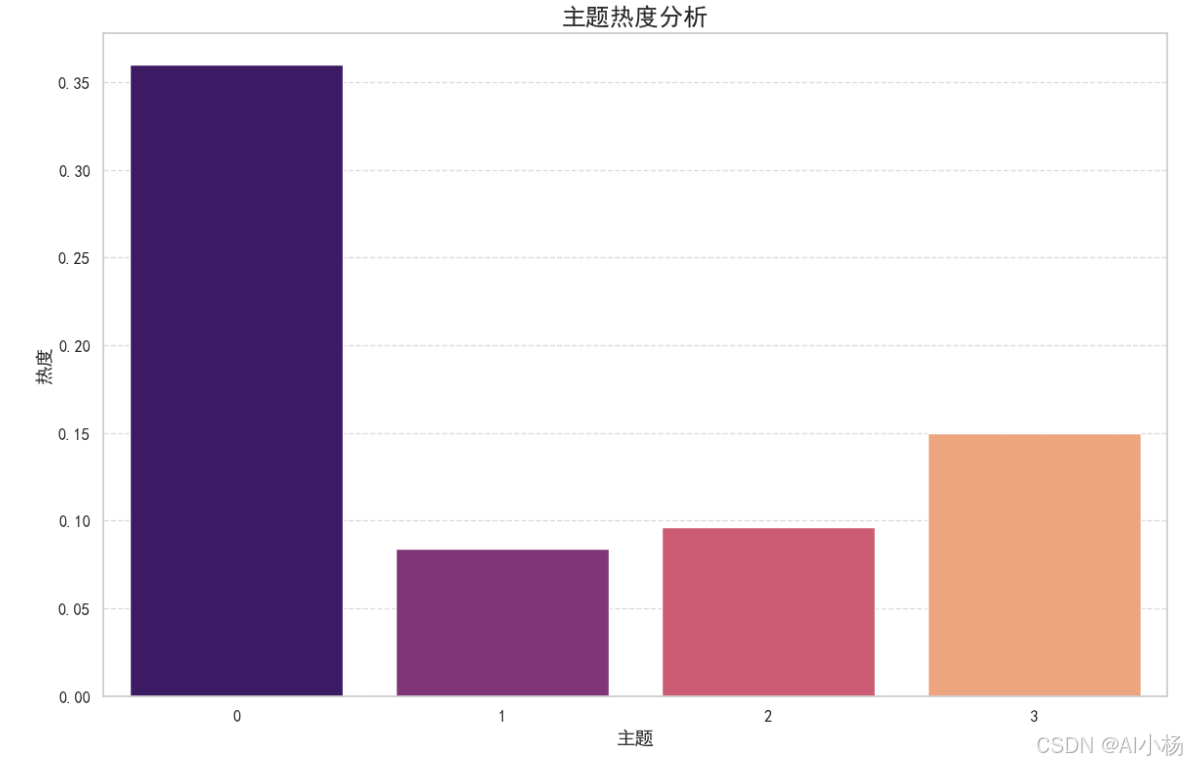
10、关键词热度分析
-
计算关键词热度:
- 计算每个关键词在所有主题中的总概率分数,作为关键词的热度。
- 使用Seaborn绘制关键词热度的条形图,展示前20个最热门的关键词。
-
计算主题热度:
- 计算每个主题的总概率分数,作为主题的热度。
- 使用Seaborn绘制主题热度的条形图,展示所有主题的热度。
-
实现
python
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from gensim.models import LdaModel
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
# 设置 Seaborn 风格
sns.set(style="whitegrid", font_scale=1.2)
# 设置 Matplotlib 字体以支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# # 训练 LDA 模型
# lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, passes=10, random_state=42)
# # 打印主题列表
# topic_list = lda.print_topics()
# print(topic_list)
# # 获取每个文档的主要主题
# result_list = []
# for i in lda.get_document_topics(corpus):
# listj = [j[1] for j in i]
# bz = listj.index(max(listj))
# result_list.append(i[bz][0])
# # 创建主题关键词概率分数 DataFrame
# topic_data = pd.DataFrame(columns=['主题', '关键词', '概率分数'])
# for topic in topic_list:
# topic_num, topic_terms = topic
# terms = topic_terms.split('+')
# for term in terms:
# probability, word = term.split('*')
# word = word.strip().strip('"') # 去除引号
# probability = float(probability.strip())
# topic_data = pd.concat([topic_data, pd.DataFrame({'主题': [topic_num], '关键词': [word], '概率分数': [probability]})], ignore_index=True)
# # 按主题聚合关键词
# topic_data = topic_data.groupby('主题').agg({'关键词': lambda x: ' '.join(x), '概率分数': 'sum'}).reset_index()
# # 将 DataFrame 导出到 Excel 文件
# topic_data.to_excel('../datasets/主题关键词概率分数.xlsx', index=False)
# # 生成 LDA 可视化
# pyLDAvis.enable_notebook()
# data = gensimvis.prepare(lda, corpus, dictionary)
# pyLDAvis.save_html(data, '../datasets/topic.html')
# # 显示 LDA 可视化
# pyLDAvis.display(data)
# 计算关键词热度
keyword_heat = topic_data.explode('关键词').groupby('关键词')['概率分数'].sum().reset_index()
keyword_heat.rename(columns={'概率分数': '热度'}, inplace=True)
# 计算主题热度
topic_heat = topic_data[['主题', '概率分数']].groupby('主题').sum().reset_index()
topic_heat.rename(columns={'概率分数': '热度'}, inplace=True)
# 可视化关键词热度
plt.figure(figsize=(14, 8))
sns.barplot(x='关键词', y='热度', data=keyword_heat.sort_values(by='热度', ascending=False).head(20), palette='viridis')
plt.title('关键词热度分析', fontsize=18)
plt.xlabel('关键词', fontsize=14)
plt.ylabel('热度', fontsize=14)
plt.xticks(rotation=45, ha='right', fontsize=12)
plt.yticks(fontsize=12)
plt.grid(True, axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
# 可视化主题热度
plt.figure(figsize=(12, 8))
sns.barplot(x='主题', y='热度', data=topic_heat.sort_values(by='热度', ascending=False), palette='magma')
plt.title('主题热度分析', fontsize=18)
plt.xlabel('主题', fontsize=14)
plt.ylabel('热度', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.grid(True, axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()- 结果如下: