
在这个信息爆炸的时代,数据就是力量。尤其是对于开发者来说,获取并利用好数据,就意味着拥有更多的主动权和竞争力。
无论是用来训练大语言模型,还是用于增强检索生成(RAG),数据都扮演着至关重要的角色。而在这样一个数据为王的环境下,能够高效地抓取网页数据的工具就显得尤为重要了。
今天我想和大家分享一款我最近发现的宝藏开源工具:FireCrawl。

这款工具可谓是网页爬虫界的顶流,不仅功能强大,还非常好用,尤其是对于那些需要大量爬取和处理网页数据的项目,FireCrawl 简直就是神器。
FireCrawl 项目简介

Firecrawl 是一款开源、优秀、尖端的 AI 爬虫工具,专门从事 Web 数据提取,并将其转换为 Markdown 格式或者其他结构化数据。
Firecrawl 还特别上线了一个新的功能:LLM Extract,即利用大语言模型(LLM)快速完成网页数据的提取,从而转换为LLM-ready的数据。
所以无论你是需要为大语言模型(如 GPT)提供数据训练,还是需要为检索增强生成(RAG)获取高质量数据,FireCrawl 都能够为你提供全面的支持。
主要功能
-
强大的抓取能力:几乎能抓取任何网站的内容,无论是简单的静态页面,还是复杂的动态网页,它都能够应对自如。
-
智能的爬取状态管理:提供了分页、流式传输等功能,使得大规模网页抓取变得更加高效。此外,它还具备清晰的错误提示功能,让你在爬取过程中可以快速排查问题,保证数据抓取的顺利进行。
-
多样的输出格式:不仅支持将抓取的内容转换为 Markdown 格式,还支持将其输出为结构化数据(如 JSON)。
-
增强 Markdown 解析:优化 Markdown 解析逻辑,能够输出更干净、更高质量的文本。
-
全面的 SDK 支持:提供了丰富的 SDK,支持多种编程语言(如 Go、Rust 等),并全面兼容 v1 API。
-
快速收集相关链接:新增了/map 端点,可以快速收集网页中的相关链接。这对于需要抓取大量相关内容的用户来说,是一个极其高效的功能。
FireCrawl应用场景
1. 大语言模型训练
通过抓取海量网页内容并将其转换为结构化数据,FireCrawl 能够为大语言模型(如 GPT)提供丰富的训练数据。
这对于希望提升模型表现的开发者或企业来说,FireCrawl 是一个理想的工具。
2. 检索增强生成(RAG):
FireCrawl 可以帮助用户从不同网页中获取相关数据,支持检索增强生成(RAG)任务。这意味着你可以通过 FireCrawl 获取并整理数据,用于生成更加精确、更加丰富的文本内容。
3. 数据驱动的开发项目
如果你的项目依赖大量的网页数据,比如训练语言模型、构建知识图谱、数据分析等等,FireCrawl 是一个不二之选。
它可以帮助你快速获取所需数据,并将其转换为你需要的格式,无论是 Markdown 还是 JSON,都能轻松搞定。
4. SEO 与内容优化
对于那些需要进行 SEO 优化或内容监控的项目,FireCrawl 也非常适用。
你可以利用 FireCrawl 爬取竞争对手的网站内容,分析他们的 SEO 策略,或者监控网站内容的变化,帮助你优化自己的网站。
5. 在线服务与工具集成
FireCrawl 提供了易于使用且统一的 API,支持本地部署或在线使用。
你可以将 FireCrawl 无缝集成到现有的服务或工具中,如 Langchain、Dify、Flowise 等,进一步扩展其应用能力。
安装与使用
当然 FireCrawl 是支持本地部署的,通过源码进行部署安装服务,但是依赖的语言过多,不仅有Nodejs、Python,还有Rust!还是建议在线体验!
前置条件
需要先注册 Firecrawl 并获取 API key。
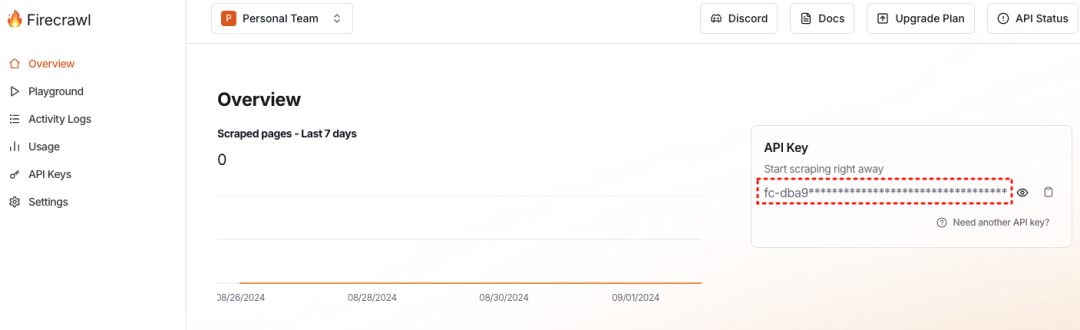
使用方式
官方项目中列了很多通过curl接口命令的方式,其实这样就有些繁琐!
我们可以通过各种API工具来进行请求,使用体验会更好一些。
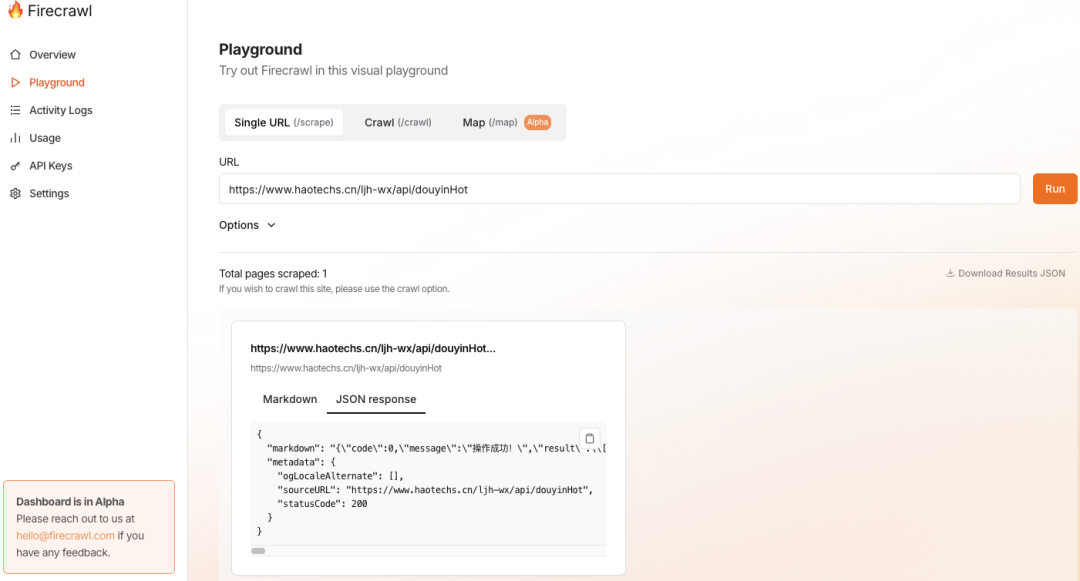
也可以通过官方部署的网页上功能来进行,效果会更加!
最后就是开发者常用的SDK方式,这里以Python语言为例:
- 安装 Python SDK
bash
pip install firecrawl-py- 调用接口,抓取目标网页数据
bash
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="YOUR_API_KEY")
crawl_result = app.crawl_url('mendable.ai', {'crawlerOptions': {'excludes': ['blog/*']}})
# Get the markdown
for result in crawl_result:
print(result['markdown'])- 要抓取单个 URL,需要使用 scrape_url 方法。将 URL 作为参数,并以字典形式返回抓取的数据。
bash
url = 'https://www.xxxx.com'
scraped_data = app.scrape_url(url)总结
作为一名开发者,我们都知道,一个好用的工具可以大大提高我们的工作效率,而 FireCrawl 就是这样一个值得推荐的工具。
无论你是需要爬取大量数据,还是需要将网页内容转换为文档,FireCrawl 都能够帮助你轻松实现这些需求。
开源地址:https://github.com/mendableai/firecrawl