在 AI 原生开发时代,Claude Code 作为高效 AI 代码助手,凭借强大的编码能力、上下文感知能力,擅长基于规范生成定制化可运行代码,尤其在 Claude Opus 4.5 版本升级后,其编程准确率与效率大幅提升,成为开发者提升编码效率的核心工具;而 OpenSpec 作为 API 规范管理核心,恰好能串联起「规范定义 → AI 代码生成 → 迭代优化」的全链路。本文将详解如何将 OpenSpec 深度集成到 Claude Code 中,拆解 OpenSpec 核心命令用法、联动逻辑,以及这套组合为研发带来的核心价值,同时补充 OpenSpec 常用命令用途、团队文档维护方法及中文配置技巧,助力开发者实现高效、规范、协同的开发闭环,同时覆盖老项目增量开发场景(如图书统计功能),确保新功能安全落地、不影响原有逻辑。
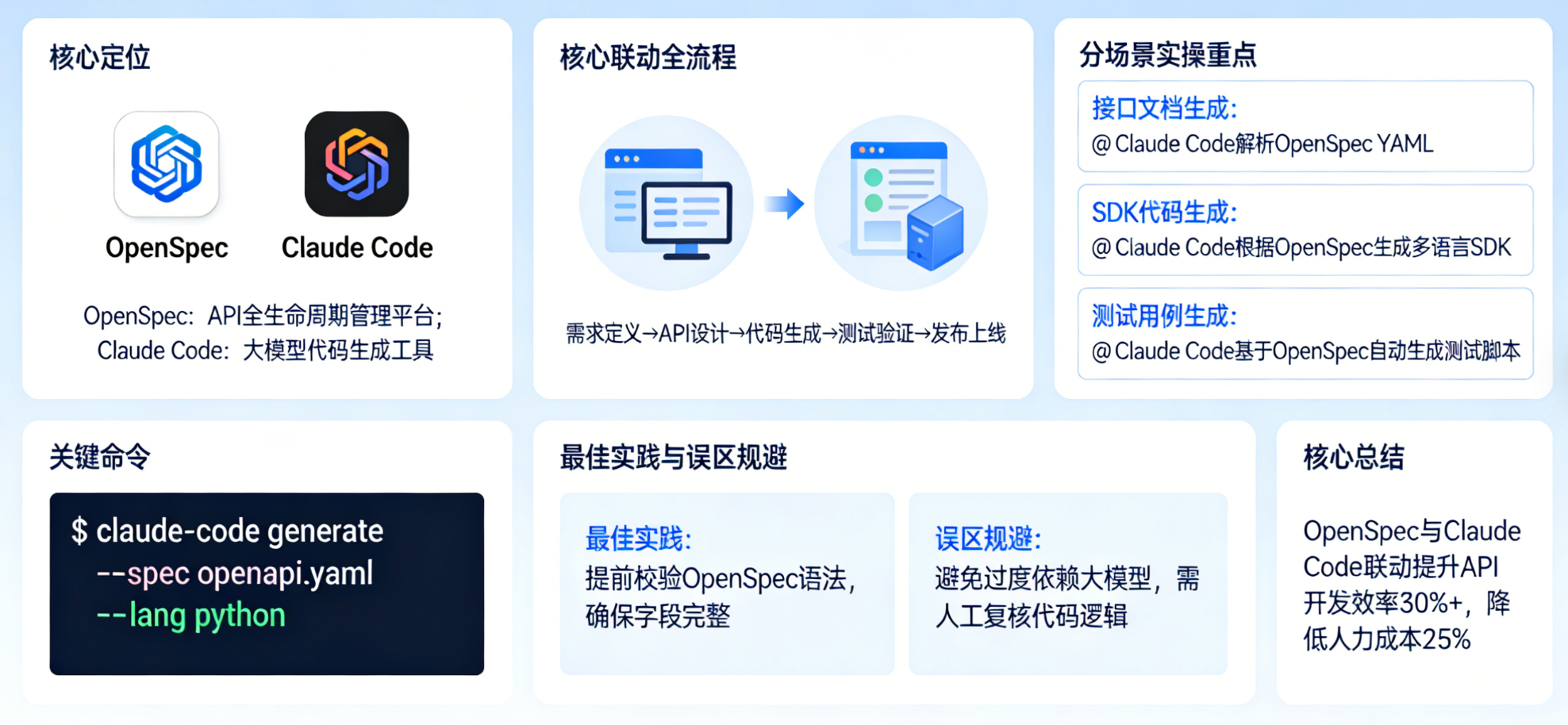
一、两者核心定位:为什么要联动使用?
在展开实操前,先明确 OpenSpec 与 Claude Code 两者的定位与协同逻辑------二者并非独立工具,而是形成「规范枢纽 + 智能代码助手」的黄金组合,精准解决研发中「规范混乱、编码低效、代码与文档脱节」的痛点,结合 Claude Code 的强大编码能力,可实现生产效率的大幅提升。
1. 各工具核心定位与能力
| 工具 | 核心定位 | 核心能力 | 解决的核心痛点 |
|---|---|---|---|
| OpenSpec | API 规范管理枢纽 | 定义/验证 OpenAPI 规范、同步项目上下文、生成接口文档、联动 AI 代码工具 | 接口规范不统一、文档维护成本高、AI 生成代码无统一规范参考 |
| Claude Code | 智能代码助手 | 基于规范/指令生成定制化代码、迭代优化代码、修复 Bug、解析项目结构,支持自定义工作流封装,可读取 OpenSpec 同步的上下文信息,尤其擅长复杂系统代码编写与漏洞修复。 | 手动编码效率低、代码风格不统一、重复编码工作量大、复杂编码问题难以快速解决 |
2. 联动核心价值
两者联动的核心是「以 OpenSpec 规范为唯一数据源」,让 Claude Code 基于统一规范生成代码,实现「规范定义 → AI 代码生成 → 迭代优化」的一站式闭环,结合 Claude Code 的强大性能,具体价值体现在三点:
-
规范统一:OpenSpec 定义的 API 规范成为 Claude Code 生成代码的唯一标准,彻底解决「文档与代码两张皮」问题,确保代码与接口规范高度一致;
-
效率倍增:Claude Code 基于 OpenSpec 规范一键生成符合自定义架构的代码,结合其「计划模式」可精准规划代码结构并执行,减少 80% 以上的重复编码工作,尤其 OpenSpec 与 Claude Opus 4.5 联动时,生产效率可提升 220%;
-
协同顺畅:开发者可通过 OpenSpec 统一规范,Claude Code 基于规范上下文生成符合要求的代码,支持多会话并行开发,同时可通过指令迭代优化,减少代码返工成本,适配团队协同开发场景,也能安全支撑老项目增量开发。
二、OpenSpec 核心命令详解:用途、团队文档维护及中文配置
OpenSpec 是整个联动流程的「核心枢纽」,所有操作围绕「API 规范文件(api-spec.yaml/json)」展开,其核心命令可覆盖「规范初始化 → 验证 → 上下文同步 → 文档生成 → 代码骨架生成」全场景,既是联动 Claude Code 的关键,也是团队维护文档、提升协同效率的核心工具,同时能为老项目增量开发提供规范支撑。以下将详细拆解常用命令的用途、团队文档维护流程,以及 OpenSpec 中文配置方法,确保新手也能快速上手。
(一)OpenSpec 常用命令详解(附核心用途)
OpenSpec 的命令简洁且功能明确,核心常用命令共 6 个,覆盖「项目初始化 → 规范维护 → 文档生成 → 调试」全场景,适配个人开发、团队协同及老项目增量开发,每个命令的核心用途、实操方式及注意事项如下,可直接在终端执行:
| 常用命令 | 核心用途 | 实操命令 | 注意事项 |
|---|---|---|---|
| openspec init | 项目初始化,生成规范文件、配置文件,集成 Claude Code,搭建基础环境;老项目接入时可初始化规范文件,不影响原有代码 | openspec init(终端直接执行,按向导配置) | 集成工具选择 Claude Code,规范路径建议默认;老项目接入时不修改原有目录结构 |
| openspec validate | 验证规范文件合法性,避免文档与代码脱节;老项目新增规范后必做,排查语法错误 | openspec validate api-spec.yaml | 修改规范后需重新执行,老项目新增规范时仅验证新增部分,不影响老规范 |
| openspec refresh-context | 同步规范与文档上下文,供 Claude Code 读取,同步团队规范;老项目新增规范后同步,确保 AI 识别新需求 | openspec refresh-context | 修改规范/文档后必执行,否则上下文失效;老项目同步时不覆盖原有上下文 |
| openspec generate html | 生成可视化接口文档,供团队查阅、维护;老项目新增功能后更新文档,不覆盖老文档内容 | openspec generate html api-spec.yaml -o docs | 输出到 docs 文件夹,便于团队共享;老项目更新时直接覆盖原有 HTML,保留历史版本可备份 |
| openspec serve | 启动本地调试服务器,验证文档与代码一致性;老项目可同时测试新、老接口,确保无影响 | openspec serve api-spec.yaml --port 3000 | 端口可自定义,避免与其他服务冲突;老项目测试时优先验证老接口,再测试新接口 |
| openspec generate server/client | 生成代码骨架,减少重复编码,辅助文档落地;老项目新增功能时生成独立骨架,不触碰老代码 | openspec generate server express api-spec.yaml -o server | 支持多技术栈,可按需选择;老项目生成时指定独立目录,避免与老代码混淆 |
(二)团队成员如何通过命令维护文档
团队协作中,文档维护的核心是「统一规范、实时同步、可追溯」,OpenSpec 的命令可实现标准化维护流程,无需手动整理文档,所有成员按以下步骤操作,即可确保接口文档统一、同步,适配团队协同场景,同时支撑老项目增量规范的维护:
-
规范创建与初始化(由负责人执行) :负责人通过
openspec init初始化项目,配置好规范路径、集成 Claude Code,生成 api-spec.yaml 基础文件;老项目接入时,初始化规范文件后,补充原有接口规范,再将项目提交到团队代码仓库,供所有成员拉取。 -
规范修改与验证(成员操作) :成员拉取代码后,若需修改接口规范(如新增接口、调整参数),直接编辑 api-spec.yaml 文件,修改完成后,执行
openspec validate api-spec.yaml验证规范合法性,避免语法错误;老项目新增规范时,仅编辑新增内容,不修改原有规范。 -
上下文与文档同步(成员操作) :规范修改并验证通过后,执行
openspec refresh-context,将修改后的规范同步到团队共享上下文(.claude/ 文件夹),同时执行openspec generate html api-spec.yaml -o docs,重新生成可视化文档,确保文档与规范一致;老项目同步时,仅同步新增规范上下文,不覆盖原有上下文。 -
提交与同步(成员操作) :将修改后的 api-spec.yaml、docs 文件夹及 .claude/ 文件夹提交到代码仓库,备注修改内容(如「新增 /books/statistics 统计接口,更新文档」),其他成员拉取代码后,无需额外操作,执行
openspec refresh-context即可同步最新规范与文档。 -
文档查阅与调试(所有成员) :成员可直接打开 docs 文件夹中的 index.html 文件,查看最新可视化接口文档;若需验证文档与代码的一致性,执行
openspec serve api-spec.yaml --port 3000,启动调试服务器,测试接口是否符合文档规范;老项目调试时,需同时测试新、老接口,确保互不影响。
补充说明:团队可约定「规范修改后必须执行 validate 和 refresh-context 命令」,避免出现规范与文档、代码脱节的情况;同时,可通过代码仓库的提交记录,追溯每一次规范与文档的修改,便于协同管理;老项目维护时,需额外约定「新增规范与老规范隔离,不修改原有规范内容」。
(三)OpenSpec 中文配置方法(新手友好)
OpenSpec 默认是英文界面(终端提示、交互式向导),对于习惯中文的开发者,可通过简单配置实现全中文显示,配置过程无需复杂操作,全程终端执行,步骤如下(适配所有系统,老项目接入时同样适用):
-
查看当前语言配置 :执行以下命令,查看 OpenSpec 当前的语言设置(默认是 en 英文):
# 查看 OpenSpec 语言配置 openspec config get locale -
设置中文语言(核心步骤) :执行以下命令,将 OpenSpec 的语言设置为中文(zh-CN),设置后立即生效,无需重启终端:
# 设置 OpenSpec 为中文 openspec config set locale zh-CN -
验证配置是否生效 :执行
openspec init或openspec validate命令,若终端提示、交互式向导均显示为中文,说明配置成功;若未生效,关闭终端重新打开即可。 -
重置为英文(可选) :若后续需要切换回英文,执行以下命令即可:
# 重置为英文 openspec config set locale en
关键说明:中文配置仅影响 OpenSpec 的终端提示、交互式向导等界面,不影响规范文件(api-spec.yaml)的内容,规范文件仍需按 OpenAPI 标准编写(支持中文注释、中文接口名称),不影响与 Claude Code 的联动,也不影响老项目原有代码的运行。
(四)基础安装与项目初始化(必做)
这是联动的基础,通过命令完成 OpenSpec 安装、项目初始化,并自动集成 Claude Code,确保两者可正常联动,适配 Claude Code 桌面端、终端等所有使用场景,同时适配老项目接入需求。
bash
# 1. 全局安装 OpenSpec(终端内直接执行)
npm install -g @fission-ai/openspec@latest
# 2. 进入项目目录(终端定位到所需项目根目录,老项目直接进入根目录即可)
# cd your-project(若未自动定位,手动输入)
# 3. 初始化项目(核心命令,自动生成规范文件+配置文件,集成 Claude Code)
openspec init初始化时会弹出交互式向导(中文配置后显示中文),按以下推荐配置操作(适配 OpenSpec + Claude Code 联动,老项目接入时同样适用):
-
项目名称:自定义(如 book-api),与实际项目名称保持一致,老项目直接使用原有项目名称;
-
OpenAPI 版本:选择 3.0.3(主流版本,完美兼容 Claude Code);
-
API 基础路径:如 http://localhost:3000/api(后续代码调试需用到,老项目与原有基础路径保持一致);
-
集成工具:选择 Claude Code(无需额外安装,初始化后自动关联);
-
规范文件路径:默认 ./api-spec.yaml(Claude Code 可直接识别读取,老项目初始化后,补充原有接口规范到该文件即可)。
初始化完成后,项目目录会自动生成 3 个核心文件/文件夹,均能被 Claude Code 自动识别,老项目接入时不会影响原有文件:
-
api-spec.yaml:OpenAPI 规范核心文件(后续所有操作的基础,也是 Claude Code 生成代码的核心参考;老项目需在此文件中补充原有接口规范,新增功能规范也在此文件中增量添加);
-
openspec.json:OpenSpec 项目配置文件(记录初始化参数,用于联动 Claude Code,不影响老项目运行);
-
.claude/:Claude Code 配置与上下文缓存文件夹(OpenSpec 同步的规范内容会存入此处,供 Claude Code 读取,实现上下文联动,老项目同步时仅添加新增规范上下文)。
(五)规范验证、上下文同步及其他补充命令
1. 规范验证(核心基础)
确保 OpenSpec 生成的规范文件无语法错误,避免 Claude Code 生成错误代码,这是联动的前提,也是保障代码质量的关键------尤其 Claude Code 具备强大的代码生成能力,规范的准确性直接决定代码可用性;老项目新增规范后,此步骤可排查新增内容的语法错误,不影响老规范。
bash
# 验证规范文件合法性(终端内执行)
openspec validate api-spec.yaml执行结果说明(中文配置后显示中文提示):
-
成功:终端输出 有效的 OpenAPI 规范,说明规范可正常被 Claude Code 识别读取;
-
失败:终端会精准提示错误位置(如语法错误、字段缺失),直接打开 api-spec.yaml,按提示修改即可,修改后重新验证;老项目验证失败时,优先检查新增规范内容,避免误改老规范。
2. 上下文同步(联动 Claude Code 的关键)
该命令的核心作用是将 OpenSpec 规范(api-spec.yaml)、项目设计文档(design.md)等内容,同步到 Claude Code 的缓存中,确保 Claude Code 生成代码时严格对齐规范,避免出现代码与规范不符的情况。这也是 Claude Code 能精准生成符合要求代码的核心前提,尤其适配其「计划模式」的精准执行需求;老项目新增规范后,同步上下文可让 Claude Code 识别新需求,不影响原有上下文内容。
bash
# 刷新项目上下文(终端内执行,必做)
openspec refresh-context关键说明:每次修改 api-spec.yaml 或 design.md 后,都需执行该命令,否则 Claude Code 会使用旧的规范内容,导致代码生成与规范不符。执行成功后,Claude Code 会自动更新上下文,无需重启工具,可直接调用生成代码;老项目同步时,仅更新新增规范相关的上下文,不覆盖原有上下文。
3. 文档与调试支持(适配 Claude Code 开发)
OpenSpec 提供两个核心命令,适配 Claude Code 生成代码后的文档查阅与调试场景,无需额外配置其他工具,提升开发闭环效率,同时适配老项目新功能调试需求:
bash
# 1. 生成可视化接口文档(可直接打开查看,供开发者参考,也可作为 Claude Code 代码校验依据)
openspec generate html api-spec.yaml -o docs
# 2. 启动本地调试服务器(供调试 Claude Code 生成的接口代码,模拟接口返回,验证代码可用性;老项目可同时测试新、老接口)
openspec serve api-spec.yaml --port 3000补充说明:启动调试服务器后,可直接通过该地址(http://localhost:3000/api)调试 Claude Code 生成的接口代码,验证返回结果是否与 OpenSpec 规范一致,快速定位代码问题;老项目调试时,建议先测试老接口,确认无异常后再测试新接口,确保新功能不影响原有逻辑。
4. 代码骨架生成(基础提效)
OpenSpec 可直接生成通用代码骨架,供 Claude Code 进一步优化完善,减少 AI 生成代码的工作量,适配 Claude Code 支持的所有主流技术栈(Java、Node.js、Python 等),尤其适合复杂项目的快速搭建,结合 Claude Code 的编码能力可实现快速落地;老项目新增功能时,生成的骨架会独立存放,不触碰老代码。
bash
# 生成 Express(Node.js)服务端骨架(输出到 server 文件夹,供 Claude Code 优化;老项目可指定独立文件夹,避免与老代码混淆)
openspec generate server express api-spec.yaml -o server
# 生成 JavaScript 客户端代码(输出到 client 文件夹,适配前端开发,供 Claude Code 完善)
openspec generate client javascript api-spec.yaml -o client三、OpenSpec 联动 Claude Code:从规范到代码的全流程实操(含老项目增量开发)
这是本文的核心------通过 OpenSpec 规范驱动 Claude Code 生成定制化可运行代码,全程无需切换多余工具,依托 OpenSpec 的规范管理与 Claude Code 的智能编码能力,实现「规范定义 → 代码生成 → 验证优化」的闭环,既适配新项目快速开发,也适配老项目增量开发(如图书统计功能),确保新功能安全落地、不影响老代码。核心逻辑:OpenSpec 提供规范与上下文,Claude Code 基于规范生成符合要求的代码,两者协同提升编码效率与代码质量。
前置准备(必做)
-
Claude Code 已安装并启动(桌面端、终端版均可,确保可正常调用);
-
已完成 OpenSpec 项目初始化,且 api-spec.yaml 已定义核心接口(新项目直接定义,老项目需补充原有接口规范);
-
已执行 openspec validate 和 openspec refresh-context,确保规范有效且已同步到 Claude Code 上下文;老项目需额外确认原有规范无异常,新增规范已验证通过。
(一)新项目实操:从规范到代码全流程(以 Node.js+Express 图书管理为例)
步骤 1:确认 OpenSpec 规范
找到项目目录中的 api-spec.yaml 文件并打开,定义图书管理核心接口(如 GET /books、POST /books、GET /books/{id} 等),确保规范无语法错误(可再次执行 openspec validate api-spec.yaml 验证)。规范的完整性直接决定 Claude Code 生成代码的精准度,建议按清晰的接口定义编写,便于 Claude Code 理解。
步骤 2:用 OpenSpec 同步上下文(关键)
在终端中执行以下命令,将 OpenSpec 规范同步到 Claude Code 缓存,确保 Claude Code 能读取最新的规范内容,这是避免代码与规范脱节的核心步骤:
bash
openspec refresh-context执行成功后,终端会提示「Context refreshed successfully」(中文配置后显示「上下文刷新成功」),此时 Claude Code 已能读取最新的 api-spec.yaml 规范,可直接调用生成代码。
步骤 3:调用 Claude Code,基于 OpenSpec 生成代码
这是核心步骤------直接调用 Claude Code,通过明确指令驱动其基于 OpenSpec 规范生成代码,无需手动编码,两种常用方式(适配不同使用场景),可结合 Claude Code 的「计划模式」提升代码生成精准度:
方式 1:通过 Claude Code 聊天模式(图形化,推荐)
-
打开 Claude Code 客户端(桌面端),唤起聊天面板;
-
在聊天框中输入指令,明确要求「基于 OpenSpec 规范生成代码」,指令模板如下(可直接复制修改,结合 Claude Code 调教技巧优化指令,提升代码质量):
`基于当前项目 OpenSpec 生成的 api-spec.yaml(图书管理 API 规范),生成 Node.js+Express 代码:
-
架构:controller、service、dao、common 四层(文件夹);
-
实现 api-spec.yaml 中所有 /books 接口(GET /books、POST /books、GET /books/{id}),严格匹配规范中的请求参数、响应格式和状态码;
-
代码直接生成到当前项目目录中,包含必要的依赖配置(如 package.json)和启动文件(app.js);
-
遵循 DRY 原则,避免代码重复,保持代码可维护性与灵活性,添加清晰注释,同时进行安全审查,避免引入漏洞;
-
生成前先规划代码结构,生成后提供简单的测试方法,确保代码可直接运行。
`
-
发送指令后,Claude Code 会基于 OpenSpec 同步的上下文,生成符合要求的代码,同时可根据其「计划模式」生成 plan.md 文件,供开发者确认后再执行生成,确保代码结构符合预期;
-
生成完成后,代码会自动输出到项目目录中,无需手动复制粘贴。
方式 2:通过终端调用 Claude Code(适合终端爱好者)
-
在终端中启动 Claude Code(终端版),确保已关联当前项目;
-
输入指令(与方式 1 指令一致,可简化),示例:
基于当前项目的 api-spec.yaml 规范,生成 Node.js+Express 四层架构代码,实现所有 /books 接口,生成到项目目录,确保可直接运行。 -
执行指令后,Claude Code 会快速生成代码,生成完成后终端会提示「Code generated successfully」,同时可并行开启其他会话,进行代码优化或 Bug 修复。
步骤 4:验证与优化代码
-
启动本地调试服务器(执行 openspec serve api-spec.yaml --port 3000);
-
运行 Claude Code 生成的代码(如 Node.js 项目执行 npm install && node app.js);
-
测试接口(如 curl http://localhost:3000/api/books),验证返回结果是否与 OpenSpec 规范一致;
-
若代码存在问题(如接口参数不匹配、逻辑错误),直接在 Claude Code 中补充指令(如「修正 GET /books/{id} 参数类型,匹配 api-spec.yaml 的整数定义」),Claude Code 会基于 OpenSpec 规范快速修正,无需手动修改代码,尤其擅长复杂漏洞的修复。
(二)老项目增量开发:新增图书统计功能(不影响老代码)
老项目改造的核心风险是「破坏现有逻辑、引入兼容性问题」,因此需严格遵循「规范隔离、代码增量、边界约束」的原则,通过 OpenSpec 增量定义规范,再驱动 Claude Code 增量开发,确保新功能(图书统计)与老代码完全隔离。以下是完整实操流程:
1. 核心前提:明确开发边界(关键,避免影响老代码)
在开始编码前,必须与 Claude Code 明确三大边界,从根源上避免破坏老代码:
-
功能边界 :仅新增「图书统计」相关接口(如
/books/statistics),不修改现有/books、/books/{id}等老接口的逻辑、入参、出参; -
代码边界:统计功能独立封装为新模块,仅新增 3 个独立文件,不触碰老项目任何现有文件:
-
controller/BookStatisticsController.js:统计接口控制器,仅调用统计服务;
-
service/BookStatisticsService.js:统计业务逻辑,不依赖老业务代码;
-
dao/BookStatisticsDao.js:统计数据访问层,仅查询统计数据,复用老项目的数据库连接工具。
-
-
依赖边界 :统计功能仅依赖老项目的公共工具类 (如
common/Result.js、common/DbUtil.js),不直接依赖老项目的业务逻辑层代码(如BookService.js、BookDao.js),避免耦合。
2. 步骤 1:OpenSpec 增量新增统计功能规范
老项目的 api-spec.yaml 已存在图书相关老规范,我们仅增量新增统计接口规范,不修改任何老内容,确保规范隔离,为 Claude Code 提供清晰的开发边界。
编辑 api-spec.yaml(新增统计规范)
yaml
# 老项目原有规范(保留不动,仅作参考)
# paths:
# /books:
# get: 老接口定义...
# /books/{id}:
# get: 老接口定义...
# 增量新增:图书统计相关规范(完全独立,不影响老规范)
components:
schemas:
# 图书统计结果模型(新增)
BookStatistics:
type: object
properties:
totalCount:
type: integer
description: 图书总数量
example: 100
availableCount:
type: integer
description: 可借阅图书数量
example: 80
borrowedCount:
type: integer
description: 已借阅图书数量
example: 20
categoryDistribution:
type: array
description: 分类分布(按分类统计数量)
items:
type: object
properties:
category:
type: string
example: "计算机"
count:
type: integer
example: 60
# 复用老项目的统一响应Result(无需重新定义,避免重复)
# 新增统计接口(完全隔离,不修改老接口)
paths:
# 老接口(保留不动,确保不被修改)
/books:
get:
summary: 获取图书列表(老接口,不修改)
# ... 老接口原有定义 ...
/books/{id}:
get:
summary: 获取单本图书详情(老接口,不修改)
# ... 老接口原有定义 ...
# 新增:图书统计接口
/books/statistics:
get:
summary: 获取图书统计信息(新增功能)
description: 统计图书总数量、可借阅/已借阅数量、分类分布,不影响现有图书查询逻辑
parameters:
- name: category
in: query
required: false
schema:
type: string
description: 按分类筛选统计(可选)
example: "计算机"
responses:
'200':
description: 统计成功(复用老项目Result响应格式)
content:
application/json:
schema:
$ref: '#/components/schemas/Result'
example:
code: 200
msg: "统计成功"
data:
totalCount: 100
availableCount: 80
borrowedCount: 20
categoryDistribution:
- category: "计算机"
count: 60
- category: "文学"
count: 40
'400':
description: 参数错误(复用老项目错误响应)
content:
application/json:
schema:
$ref: '#/components/schemas/ErrorResult'规范验证与上下文同步(必做步骤)
修改完规范后,必须执行以下命令,确保新增规范合法,且同步到 Claude Code 上下文,避免 AI 误读或使用旧规范:
bash
# 1. 验证新增规范合法性(重点检查新增接口的语法,不影响老规范)
openspec validate api-spec.yaml
# 成功提示:有效的OpenAPI规范
# 2. 同步上下文(让Claude Code识别新增的统计规范,不覆盖原有上下文)
openspec refresh-context
# 成功提示:上下文刷新成功3. 步骤 2:与 Claude Code 交互(增量开发,不碰老代码)
核心逻辑:通过精准指令约束 Claude Code 的开发范围,明确「仅新增、不修改」,让 AI 只生成统计功能的独立文件,全程不触碰老项目任何现有代码。以下是两种交互模式,适配不同使用习惯:
模式 1:Claude Code 聊天面板(图形化,新手友好)
-
打开 Claude Code 客户端(IDE 内或桌面端),唤起聊天面板;
-
输入精准增量开发指令 ,明确边界约束,模板如下(可直接复制使用):
基于当前项目 OpenSpec 新增的/books/statistics` 接口规范,增量开发图书统计功能,严格遵守以下规则,确保不影响老项目代码: -
完全隔离老代码:
- 不修改任何老项目核心文件(包括 BookController.js、BookService.js、BookDao.js、common 下的现有工具类);
- 仅新增以下 3 个独立文件到对应目录,不新增其他文件、不修改现有目录结构:
- controller/BookStatisticsController.js
- service/BookStatisticsService.js
- dao/BookStatisticsDao.js
-
功能实现要求:
- BookStatisticsController.js:接收
/books/statistics请求,调用服务层,返回 Result 响应(复用老项目 common/Result.js); - BookStatisticsService.js:实现统计逻辑(总数量、可借阅/已借阅、分类分布),包含参数校验,不依赖老业务代码;
- BookStatisticsDao.js:编写统计数据查询 SQL/方法,复用老项目 common/DbUtil.js 数据库连接工具,不修改数据库原有表结构。
- BookStatisticsController.js:接收
-
依赖约束:
- 仅依赖 common/Result.js(统一响应)、common/DbUtil.js(数据库工具),不依赖任何其他业务模块;
-
代码风格:与老项目保持一致(变量命名、注释格式、缩进),添加清晰注释,便于后续维护;
-
落地要求:直接生成上述 3 个文件到项目对应目录,无需输出到 design.md,确保代码可直接运行,同时提供简单的测试方法。
`
-
发送指令后,Claude Code 会基于 OpenSpec 的统计规范,仅生成新增的 3 个文件,全程不触碰老代码;若 AI 生成过程中出现偏离边界的情况,可补充指令(如「不要修改 BookController.js,仅新增统计相关文件」),AI 会快速修正。
模式 2:Claude Code 终端指令(终端党适用)
在 Claude Code 终端模式中,输入简化指令,核心约束不变,示例如下:
text
基于 api-spec.yaml 中新增的 /books/statistics 接口规范,增量开发图书统计功能:
1. 仅新增 controller/BookStatisticsController.js、service/BookStatisticsService.js、dao/BookStatisticsDao.js 三个文件;
2. 不修改任何老项目现有文件,不依赖老业务代码;
3. 仅依赖 common/Result.js 和 common/DbUtil.js;
4. 代码风格与老项目一致,直接生成文件到对应目录,确保可运行。关键交互约束(确保 AI 不碰老代码)
| 约束要点 | 指令表述示例 | 作用 |
|---|---|---|
| 明确不修改老代码 | 「不修改任何老项目核心文件,仅新增独立文件」 | 从根源限制 AI 开发范围,避免误改老代码 |
| 明确新增文件路径 | 「仅在 controller/、service/、dao/ 下新增对应文件」 | 让 AI 精准生成文件位置,避免乱改目录或覆盖老文件 |
| 明确依赖范围 | 「仅依赖 common 下的公共工具,不依赖其他业务代码」 | 防止 AI 引入不必要的耦合,避免影响老业务逻辑 |
| 明确复用老结构 | 「复用老项目的 Result 响应格式、数据库连接工具」 | 确保新功能与老项目兼容,减少适配成本 |
4. 步骤 3:安全落地与验证(双重保障,确保无影响)
Claude Code 生成新代码后,必须通过「目录检查+双接口测试+边界测试」,确保新功能独立运行,不影响老项目现有逻辑,这是老项目增量开发的关键环节。
步骤 1:目录结构检查(确认无老代码修改)
查看项目目录,确保只有新增文件,无任何老文件被修改,目录结构示例如下(老文件均未改动):
text
your-old-project/
├── controller/
│ ├── BookController.js # 老文件,未修改
│ └── BookStatisticsController.js # 新增文件
├── service/
│ ├── BookService.js # 老文件,未修改
│ └── BookStatisticsService.js # 新增文件
├── dao/
│ ├── BookDao.js # 老文件,未修改
│ └── BookStatisticsDao.js # 新增文件
├── common/
│ ├── Result.js # 老文件,仅引用,未修改
│ └── DbUtil.js # 老文件,仅引用,未修改
└── api-spec.yaml # 仅增量新增统计规范,未修改老接口步骤 2:双接口测试(新功能+老功能,验证无影响)
通过 OpenSpec 启动调试服务器,同时测试新统计接口和老接口,确保二者互不干扰、均能正常运行:
bash
# 1. 启动 OpenSpec 调试服务器(指定端口,避免冲突)
openspec serve api-spec.yaml --port 3000
# 成功提示:Server running at http://localhost:3000
# 2. 测试新统计接口(验证新功能是否正常)
curl "http://localhost:3000/api/books/statistics?category=计算机"
# 预期结果:返回规范中定义的统计数据,状态码 200
# 3. 测试老接口(关键!验证老功能是否不受影响)
curl "http://localhost:3000/api/books"
curl "http://localhost:3000/api/books/1"
# 预期结果:返回原有图书列表/单本图书详情,无报错、无数据异常步骤 3:边界测试(避免隐性问题)
为彻底确保安全,补充 2 个边界测试,排查隐性问题:
-
参数异常测试 :传入无效分类(如
category=不存在的分类),验证接口返回规范定义的 400 错误,且不影响老接口运行; -
并发测试:同时请求新统计接口和老接口,验证两者均能正常响应,无数据冲突、无响应超时,确保系统稳定性。
bash
# 1. 参数异常测试(验证接口容错性,不影响老功能)
curl "http://localhost:3000/api/books/statistics?category=不存在的分类"
# 预期结果:状态码 400,返回规范中定义的错误提示(如{"code":400,"msg":"分类参数无效","data":null}),老接口仍可正常访问
# 2. 并发测试(验证系统稳定性,避免新功能占用资源导致老接口异常)
# 终端1:持续请求统计接口(模拟高并发场景)
while true; do curl "http://localhost:3000/api/books/statistics?category=计算机"; sleep 0.1; done &
# 终端2:同时持续请求老图书列表接口
while true; do curl "http://localhost:3000/api/books"; sleep 0.1; done &
# 预期结果:两个终端均能持续返回正常数据,无报错、无响应延迟,终端执行 Ctrl+C 可终止测试补充说明:边界测试需结合老项目实际场景调整,若老项目存在数据库并发限制,可在测试时增加数据库连接数监控,确保新统计接口的查询操作不占用过多数据库资源,避免影响老接口的数据库访问性能。
5. 进阶:若需扩展公共工具(最小化影响)
若统计功能需要新增工具方法(如数据格式转换、批量统计辅助逻辑),且现有公共工具(common/Result.js、common/DbUtil.js)无法满足需求,需遵循「最小化侵入」原则,不修改原有公共文件,而是新增独立工具文件,避免影响老项目依赖原有工具的逻辑,具体操作如下:
-
新增独立工具文件 :在
common/目录下新增StatisticsUtil.js,仅封装统计功能所需的工具方法(如分类数据格式化、统计结果校验),不修改Result.js、DbUtil.js原有代码; -
指令约束 Claude Code :若需 Claude Code 生成该工具文件,需补充指令(示例):
新增 common/StatisticsUtil.js 工具文件,仅封装统计功能所需的工具方法(如分类数据格式化、统计结果校验),不修改 common 目录下任何现有文件;工具方法仅供新增的统计模块使用,不被老业务模块调用,代码风格与老项目公共工具保持一致。 -
验证无影响:新增工具文件后,重新测试老接口,确保老业务模块未引用该新增工具,且老接口运行正常,无依赖异常。
关键原则:新增公共工具仅服务于新增统计功能,不与老业务耦合,避免因工具扩展导致老项目出现兼容性问题。
6. 老项目增量开发常见问题与解决方案
结合 OpenSpec 与 Claude Code 联动场景,老项目增量开发中易出现「规范同步不及时、AI 误改老代码、新老接口冲突」等问题,以下是高频问题及对应解决方案,适配实操场景:
| 常见问题 | 问题原因 | 解决方案 |
|---|---|---|
| Claude Code 误改老文件 | 指令边界不清晰,未明确「仅新增、不修改」,或 AI 未读取到最新上下文 | 1. 指令中明确标注「不修改任何老文件,仅新增指定文件」;2. 执行 openspec refresh-context 同步最新上下文;3. 生成后先检查目录,若误改立即通过 Claude Code 指令还原(如「还原 BookController.js 到修改前状态」) |
| 新接口与老接口路径冲突 | OpenSpec 新增规范时,路径未避开老接口,或规范定义有误 | 1. 新增接口路径前,检查老项目接口列表,避免重复(如老接口为 /books,新增为 /books/statistics,避免重名);2. 执行 openspec validate 验证规范,排查路径冲突;3. 若冲突,修改新增接口路径,重新同步上下文 |
| 统计接口查询缓慢,影响老接口 | 统计查询未优化,占用过多数据库资源,与老接口抢占资源 | 1. 让 Claude Code 优化统计 SQL(如添加索引、限制查询范围);2. 新增统计接口添加缓存逻辑(复用老项目缓存工具);3. 监控数据库连接数,避免统计查询占用过多连接 |
| Claude Code 生成代码与老风格不一致 | 指令未明确代码风格要求,AI 未识别老项目代码风格 | 1. 指令中补充老项目代码风格描述(如「变量采用小驼峰命名,注释用 // 单行注释,缩进为 4 个空格」);2. 粘贴一段老项目代码示例,让 AI 参考风格;3. 生成后让 AI 按老风格优化代码 |
四、联动实操总结与最佳实践
OpenSpec 与 Claude Code 联动的核心价值,在于「用规范约束 AI,用 AI 落地规范」,既解决了 AI 生成代码无统一标准、效率低下的问题,也解决了规范与代码脱节、团队协同困难的痛点,同时为老项目增量开发提供了安全、高效的解决方案。结合前文实操,总结核心要点与最佳实践,助力开发者快速落地、规避风险:
(一)核心实操总结
-
新项目开发:OpenSpec 初始化 → 定义规范 → 验证同步 → Claude Code 生成代码 → 测试优化,全程遵循「规范先行」,确保代码与规范一致;
-
老项目增量开发:明确边界 → OpenSpec 增量规范 → 验证同步 → Claude Code 增量生成 → 三重验证(目录+双接口+边界),核心是「隔离老代码、最小化侵入」;
-
关键命令 :
openspec init(初始化)、openspec validate(规范验证)、openspec refresh-context(上下文同步),三者是联动的核心,缺一不可; -
AI 交互关键:指令需清晰、边界需明确,尤其老项目开发,需反复强调「不修改老代码、仅新增独立文件」,避免 AI 偏离开发范围。
(二)最佳实践建议
-
规范管理 :团队约定 OpenAPI 规范编写标准,每次修改规范后,必须执行
validate和refresh-context命令,确保规范同步到 Claude Code,避免「文档与代码两张皮」; -
AI 指令优化:与 Claude Code 交互时,指令需包含「规范依据、架构要求、边界约束、风格要求」,结合 Claude Code 的「计划模式」,先让 AI 生成代码计划,确认后再执行生成,提升代码精准度;
-
老项目保障:增量开发前,先梳理老项目接口与目录结构,明确新增功能边界;生成代码后,必须测试老接口,确保无影响;优先复用老项目公共工具,不轻易修改原有文件;
-
效率提升:结合 OpenSpec 代码骨架生成功能,先生成基础骨架,再让 Claude Code 优化完善,减少 AI 生成工作量;同时利用 Claude Code 多会话并行能力,同步进行代码生成与优化;
-
中文适配:新手建议配置 OpenSpec 中文界面,降低操作门槛;规范文件可添加中文注释、中文接口名称,不影响与 Claude Code 的联动,提升团队可读性。
(三)常见误区规避
-
误区 1:忽略规范验证,直接让 Claude Code 生成代码 → 规避:先执行
openspec validate,确保规范无错误,否则会导致 AI 生成错误代码; -
误区 2:修改规范后不同步上下文 → 规避:每次修改 api-spec.yaml 后,必须执行
openspec refresh-context,否则 Claude Code 会使用旧规范,导致代码与规范不符; -
误区 3:老项目增量开发时,让 AI 修改现有文件 → 规避:指令中明确「仅新增、不修改」,生成后检查目录,确保无老文件被改动;
-
误区 4:过度依赖 AI 生成,不进行测试 → 规避:AI 生成代码后,必须通过 OpenSpec 调试服务器测试,验证接口与规范一致,同时排查隐性问题。
综上,OpenSpec 与 Claude Code 的联动,本质是「规范驱动 AI,AI 赋能开发」,无论是新项目快速落地,还是老项目安全增量开发,这套组合都能大幅提升编码效率、保证代码质量、降低团队协同成本。只要遵循「规范先行、边界清晰、验证到位」的原则,就能快速上手,实现高效、规范的 AI 原生开发闭环。