241124_基于MindSpore学习Prompt Tuning
传统的NLP训练模式都是先在大量的无标注的样本上进行预训练,然后再使用有标注的样本进行有监督的训练,调整单一的线性成果而不是整个模型。
但在实际训练中发现,如果模型参数过大,在Fine Tune阶段成本较高。就是每次都要在一个参数很大的模型上进行微调。
于是产生了NLP的第四范式:不做Fine Tune,模型无监督训练好了就不改变了,而是给一些prompt
比如我要做一个情感分类,就先告诉他这是一个情感分类任务,然后再给具体任务
bert就是使用pre train和fine tune的模型,实现的目标是做类似于完形填空的任务和上下文联系任务
fine-tuning:通过改变模型结构,使模型适配下游任务
prompt learing:模型结构不变,通过重构任务描述,使下游任务适配模型
Prompt-Tuning步骤:
使用一个情感分类任务举例
构建模板:这一步是做完形填空的过程,比如I love this movies,拼接到原始文本中,获得Prompt-Tuning的输入:[I love this movies. overall, it was a [mask] movie]。这一步给模型模型就需要去填这个mask 的答案,模型会填进去很多可能的答案,每个答案对应一个分数,分数最高的是最后的答案。
标签词映射:在模型给出答案之后,比如模型给了个greet,因为我们是个情感分类任务,想要得到的结果只是两种,我们就要建立greet到positive的映射。如果是terrible,则认为是negative类。
Prompting中最主要的两个部分是template与verbalizer的设计
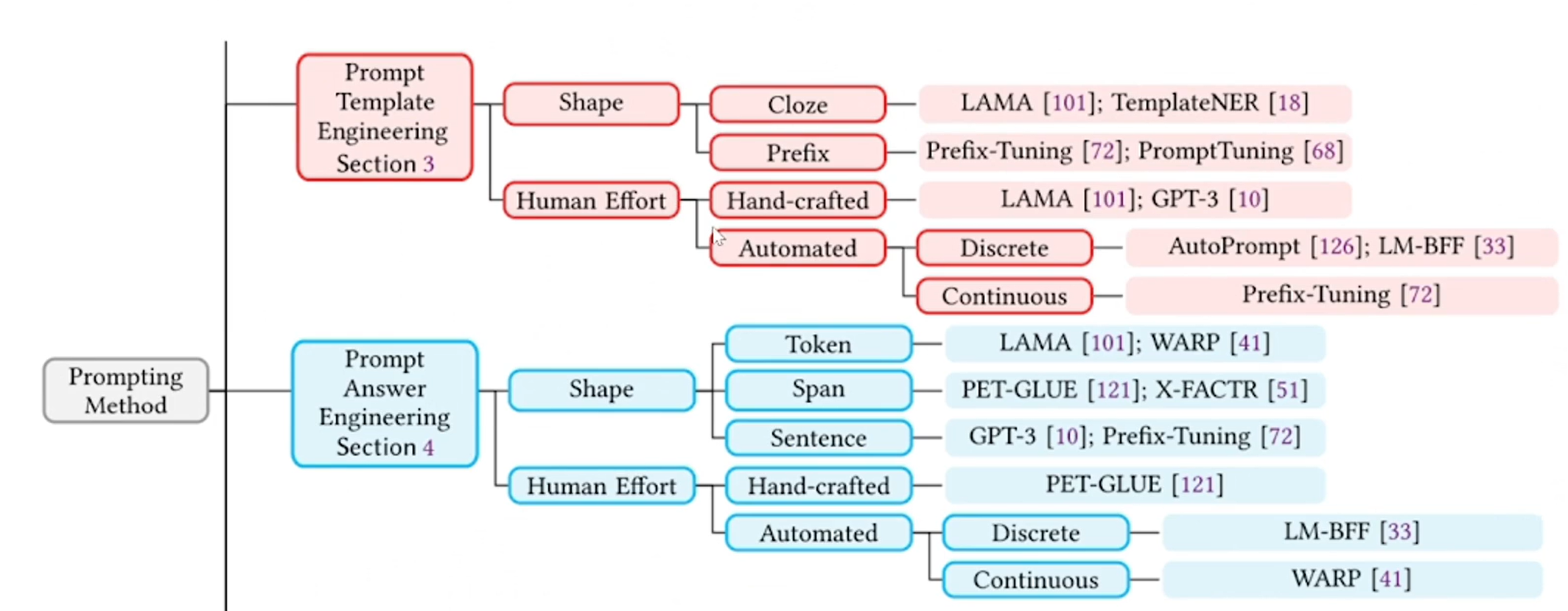
template可以基于任务类型和预训练模型选择(shape)或生成方式(huamn effort)进行分类
打卡截图: