要求:
从kafka的topic-car中读取卡口数据,将超速车辆写入mysql的t_monitor_info表
当通过卡口的车速超过该卡口限速的1.2倍 就认定为超速。
G107


1)卡口数据格式如下:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `action_time` long --摄像头拍摄时间戳,精确到秒, `monitor_id` string --卡口号, `camera_id` string --摄像头编号, `car` string --车牌号码, `speed` double --通过卡口的速度, `road_id` string --道路id, `area_id` string --区域id, |
区域ID代表:一个城市的行政区域。
摄像头编号:一个卡口往往会有多个摄像头,每个摄像头都有一个唯一编号。
道路ID:城市中每一条道路都有名字,比如:蔡锷路。交通部门会给蔡锷路一个唯一编号。
kafka数据格式:
{"action_time":1682219447,"monitor_id":"0001","camera_id":"1","car":"豫A12345","speed":34.5,"road_id":"01","area_id":"20"}
{"action_time":1682219447,"monitor_id":"0001","camera_id":"1","car":"豫A12345","speed":80,"road_id":"01","area_id":"20"}
{"action_time":1682219447,"monitor_id":"0002","camera_id":"1","car":"豫A12345","speed":84.5,"road_id":"01","area_id":"20"}
{"action_time":1682219447,"monitor_id":"0002","camera_id":"1","car":"豫A12345","speed":150,"road_id":"01","area_id":"20"}MySQL建表语句
DROP TABLE IF EXISTS `t_speeding_info`;
CREATE TABLE `t_speeding_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`car` varchar(255) NOT NULL,
`monitor_id` varchar(255) DEFAULT NULL,
`road_id` varchar(255) DEFAULT NULL,
`real_speed` double DEFAULT NULL,
`limit_speed` int(11) DEFAULT NULL,
`action_time` bigint(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;导入包:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
<!-- 指定mysql-connector的依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.48</version>
</dependency>
</dependencies>复习FastJson的使用:
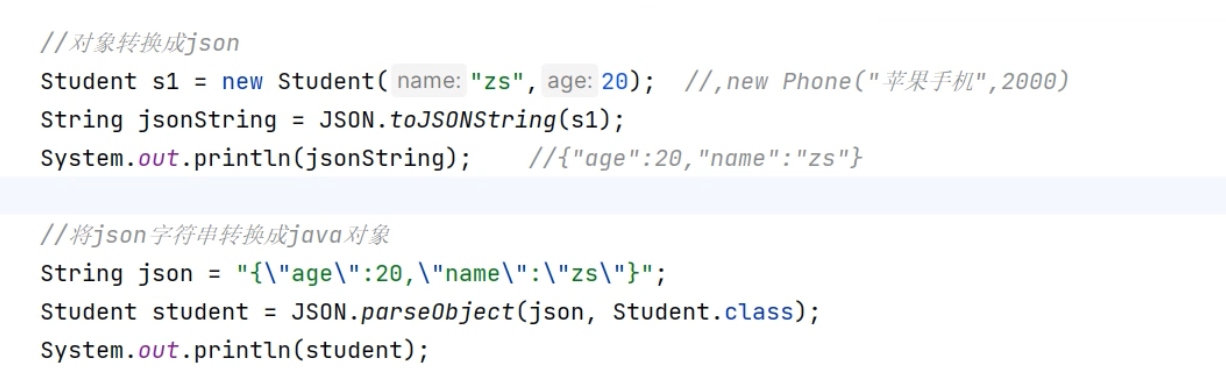
假如需求再次升级,给定一个监控设备表:
DROP TABLE IF EXISTS `t_monitor_info`;
CREATE TABLE `t_monitor_info` (
`monitor_id` varchar(255) NOT NULL,
`road_id` varchar(255) NOT NULL,
`speed_limit` int(11) DEFAULT NULL,
`area_id` varchar(255) DEFAULT NULL,
PRIMARY KEY (`monitor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--导入数据
INSERT INTO `t_monitor_info` VALUES ('0000', '02', 60, '01');
INSERT INTO `t_monitor_info` VALUES ('0001', '02', 60, '02');
INSERT INTO `t_monitor_info` VALUES ('0002', '03', 80, '01');
INSERT INTO `t_monitor_info` VALUES ('0004', '05', 100, '03');
INSERT INTO `t_monitor_info` VALUES ('0005', '04', 0, NULL);
INSERT INTO `t_monitor_info` VALUES ('0021', '04', 0, NULL);
INSERT INTO `t_monitor_info` VALUES ('0023', '05', 0, NULL);
启动集群:
1) start-dfs.sh
2) zk.sh start
3) kf.sh start
4) start-cluster.sh
5) historyserver.sh start
kafka-topics.sh --bootstrap-server bigdata01:9092 --create --partitions 1 --replication-factor 3 --topic topic-car
通过黑窗口发送消息:
kafka-console-producer.sh --bootstrap-server bigdata01:9092 --topic topic-car
思路整理:
创建一个存放mysql数据的实体类,把从mysql中读取的数据存入这个类对象中(一个类对象中存储的是一条mysql中的数据),然后把这些数据放入list集合中;接着读取kafka中的json数据,解析json数据并放入另一个新建的类对象中。取出存储mysql数据的集合中的"限速"字段,把他放入存储Kafka数据的类对象中,然后对kafka中的数据进行筛选过滤。最后将符合条件的数据放入mysql数据库中。
代码实现:
java
package com.bigdata.Day03;
import com.alibaba.fastjson.JSON;
import com.mysql.jdbc.PreparedStatement;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
import org.apache.htrace.fasterxml.jackson.databind.JsonNode;
import org.apache.htrace.fasterxml.jackson.databind.ObjectMapper;
import java.io.Serializable;
import java.lang.management.MonitorInfo;
import java.sql.*;
import java.util.ArrayList;
import java.util.Objects;
import java.util.Properties;
//创建实体类,用于存储从mysql中读取的数据
@Data
@NoArgsConstructor
@AllArgsConstructor
class monitorInfo implements Serializable{
private String monitorId;
private String roadId;
private int limitSpeed;
private String areaId;
}
//存储从kafka中读取的数据
@Data
@NoArgsConstructor
@AllArgsConstructor
// {"action_time":1682219447,"monitor_id":"0001","camera_id":"1","car":"豫A12345","speed":34.5,"road_id":"01","area_id":"20"}
class CarInfo implements Serializable {
private long actionTime;
private String monitorId;
private String cameraId;
private String car;
private double speed;
private String roadId;
private String areaId;
// 这个属性不属于这里,但是可以使用
private int limitSpeed;
}
public class zuoye_1122 {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//连接kafka
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "bigdata01:9092");
properties.setProperty("group.id", "g1");
//kafka数据源
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("car",new SimpleStringSchema(),properties);
//获取kafka数据源
DataStreamSource<String> dataStreamSource2 = env.addSource(kafkaSource);
//获取mysql数据源
//2. 注册驱动(安转驱动) 此时这句话可以省略 如果书写的话,mysql8.0 带 cj
Class.forName("com.mysql.jdbc.Driver");
//3. 获取数据库连接对象 Connection
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb01","root","root");
String sql = "select * from `t_monitor_info`";
PreparedStatement statement = (PreparedStatement) conn.prepareStatement(sql);
// 此处的返回值是 影响的行数
ResultSet resultSet = statement.executeQuery();
ArrayList<monitorInfo> list = new ArrayList<>();
while(resultSet.next()){
// 根据列名获取列的数据
String monitorId = resultSet.getString("monitor_id");
String roadId = resultSet.getString("road_id");
int speedLimit = resultSet.getInt("speed_limit");
String areaId = resultSet.getString("area_id");
list.add(new monitorInfo(monitorId,roadId,speedLimit,areaId));
}
System.out.println(list);
//将kafka中的json字符串转换为java对象
SingleOutputStreamOperator<CarInfo> chaosuCar = dataStreamSource2.map(new MapFunction<String, CarInfo>() {
@Override
public CarInfo map(String s) throws Exception {
CarInfo carInfo = JSON.parseObject(s, CarInfo.class);
return carInfo;
}
}).map(new MapFunction<CarInfo, CarInfo>() {
@Override
public CarInfo map(CarInfo carInfo) throws Exception {
for (int i = 0; i < list.size(); i++) {
if(Objects.equals(list.get(i).getMonitorId(),carInfo.getMonitorId())){
carInfo.setLimitSpeed(list.get(i).getLimitSpeed());
System.out.println(carInfo);
}
}
return carInfo;
}
}).filter(new FilterFunction<CarInfo>() {
@Override
public boolean filter(CarInfo carInfo) throws Exception {
return carInfo.getSpeed() > carInfo.getLimitSpeed()*1.2;
}
});
JdbcConnectionOptions jdbcConnectionOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/mydb01")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("root")
.build();
chaosuCar.addSink(JdbcSink.sink(
"insert into t_speeding_info values(null,?,?,?,?,?,?)",
new JdbcStatementBuilder<CarInfo>() {
@Override
public void accept(java.sql.PreparedStatement preparedStatement, CarInfo carInfo) throws SQLException {
preparedStatement.setString(2,carInfo.getMonitorId());
preparedStatement.setString(1,carInfo.getCar());
preparedStatement.setDouble(4,carInfo.getSpeed());
preparedStatement.setString(3,carInfo.getRoadId());
preparedStatement.setDouble(5,carInfo.getLimitSpeed());
preparedStatement.setLong(6,carInfo.getActionTime());
}
}, JdbcExecutionOptions.builder().withBatchSize(1).build(),jdbcConnectionOptions
));
//5. execute-执行
env.execute();
}
}