一、背景
目前需要将阿里云RDS数据库的数据同步到自建的StarRocks集群。之前使用DolphinScheduler通过定时调度Datax任务,将数据同步到StarRocks集群中,但是随着业务的发展,这种方式出现了三个问题:
1.为了满足系统三级等保的要求,阿里云RDS不再支持通过公网进行访问,只能在阿里云内网中进行访问。
2.随着业务的发展,批量的数据同步已经无法满足业务对数据更新频率的要求。
为了解决以上的问题,诞生了如下的数据同步架构。
二、数据同步架构
为了解决上面面临的问题,设计了如下的数据同步架构,来进行数据的实时同步。具体架构如下:
1.使用一台4C8G的阿里云服务器,该服务器可以访问内网的RDS服务器。
2.将KAFKA集群开通公网访问。
3.在这台阿里云服务器上面部署数据实时同步的脚步,一边实时读取RDS的binlog,将其解析加密之后发送到KAFKA中。
4.在公司内网环境中创建KAFKA CONNECTOR集群,创建connector将kafka数据解密之后同步到公司自建的StarRocks中。

三、现有方案的调研
建设初期调研了一些现在主流的方案,但是发现各个方案都存在一定的问题吗,从而选择了目前的这种方式,调用的现有解决方案有:
- Flink-CDC
Flink-CDC是目前最流行的实时数据同步方案,但是经过调研发现Flink集群所需资源太大,目前只有一台4C8G的阿里云服务器,而且这已经是能得到的最高配置。
用于目前业务的分库分表多种多样(按照范围分表, 按照组织分表,按照年度分表,按照月度分表,按照组织月度组合分表等等),业务表因为历史原因存在大量的字段不规范问题(全大写、全小写、驼峰、下划线等等),采用Flink-CDC如果分表建设task,则资源根本不够,如果耦合在一起,则需要进行大量的编码,后续修改复杂,因此放弃该方案。
- Apache SeaTunnel
Apache SeaTunnel是目前流行的另外一个实时数据同步工具,但是其目前无法支持表的模糊匹配,由于业务系统中存储多种方式的分库分表技术,而且分表数量巨大,有些表分表数量成百上千,有些按照组织分表的则是随时可能新增表,导致其很难进行兼容,需要进行上千张表的配置,基本没有可行性,所以放弃该方案。
四、核心步骤技术方案
- binlog实时消费
binlog的实时数据同步采用开源项目python-mysql-replication进行实现,python-mysql-replication是在PyMYSQL之上构建的MySQL复制协议的纯Python实现,通过其可以很简单的实时消费RDS数据库的binlog。
Pure Python Implementation of MySQL replication protocol build on top of PyMYSQL. This allows you to receive event like insert, update, delete with their datas and raw SQL queries.
- 数据加解密
为了保证数据在两个内网直接传输的安全,要求需要对进行传输的数据进行加密,经过调研之后选择了 AES-GCM对称加密,AES-GCM是一种 高效,支持硬件加速 ,适用于大数据量加密、文件加密、流加密 。
- 数据同步到StarRocks
从kafka消费数据到StarRocks,采用的使用StarRocks官方支持的starrocks-connector-for-kafka,但是由于我们的数据进行了加密操作,所以需要对该组件进行扩展,再其中加入进行数据解密的操作。
- kafka内外网映射
由于RDS和StarRocks在两个不同的内网之中,为了连通两个内网,使用kafka进行数据的中转操作。这就需要kafka能够提供公网的访问。通过配置不同的advertised.listeners来进行实现。
- 批量同步
在进行一张历史已经存在的表数据同步的时候,需要先同步历史已经存在的数据,然后再按照binlog实时进行新数据的同步工作,历史数据的同步采用DataX来进行同步。
- DataX写Kafka
DataX属于批量数据同步的组件,而Kafka属于流式数据同步的组件,两者的定位不一致,因此DataX官方并没有用于Kafka的Writer,这就需要我们自己进行扩展,编写Kafka-Writer,来进行支持。
- StarRocks表的增删改
StarRocks中存在主键表模型,该模型支持数据的增删改操作,同时starrocks-connector-for-kafka底层采用StreamLoad进行实现,StreamLoad支持通过在数据中增加对应的__op字段来支持对表的数据进行增删改。
- 分库分表的支持
系统存在多种方式的分库分表,由于分库分表之后的主键可能重复,因此可以在数据同步的时候,对分库分表进行分析,设计以 (表名,原表主键) 或者 (库名,表名,原表主键)作为对应StarRocks表的主键,来进行对应的支持操作。
五、数据同步过程说明
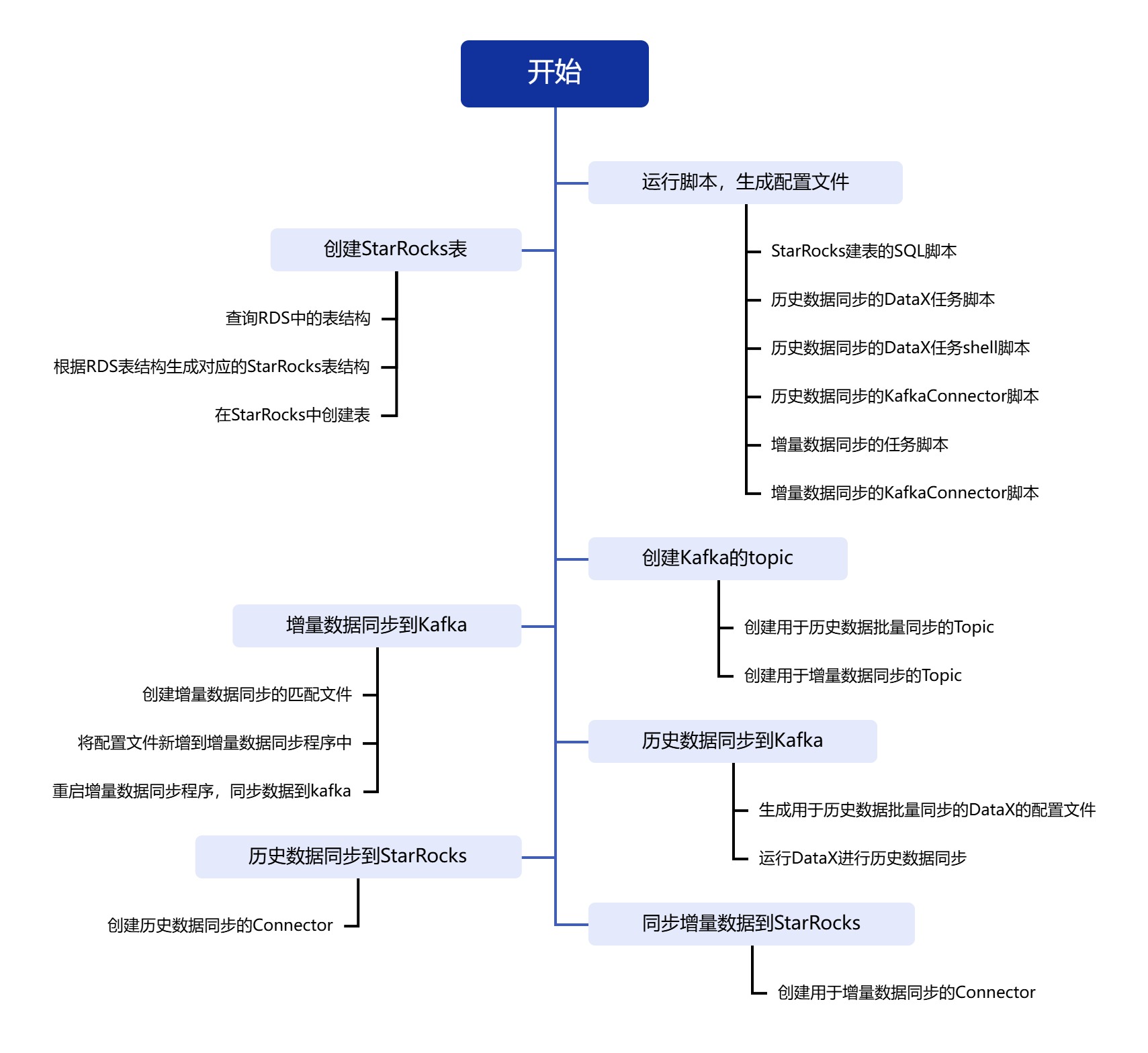
下面以一张已经存在的表如何进行数据同步为例,进行整个数据同步过程的说明:
- 根据要同步的RDS中表的结构信息,在StarRocks中创建对应的表。
- 在kafka中创建对应的进行历史批量数据同步的topic和binlog增量同步的topic。
- 在进行增量同步的脚步中新增这张表的binlog同步配置,将binlog数据写入用于增量同步的kafka的topic中。
- 使用DataX将历史数据全量同步到用于批量同步的kafka的topic中。
- 创建用于同步历史数据到StarRocks表中的Connector,消费批量topic中的数据。
- 根据DataX返回的同步数据量和StarRocks中已经接收到的数据量进行比对,如果一致则表明历史数据已经全部同步完成,此时可以删除删除用于历史数据同步的topic和Connector,也可以保留不管。
- 创建用于增量同步的Connector,消费binlog数据,实时接入StarRocks。
六、具体的实现
- DataX的kafkawriter实现
java
public class KafkaWriter extends Writer {
public static class Job extends Writer.Job {
private static final Logger logger = LoggerFactory.getLogger(Job.class);
private Configuration conf = null;
@Override
public List<Configuration> split(int mandatoryNumber) {
List<Configuration> configurations = new ArrayList<Configuration>(mandatoryNumber);
for (int i = 0; i < mandatoryNumber; i++) {
configurations.add(conf);
}
return configurations;
}
private void validateParameter() {
this.conf.getNecessaryValue(Key.BOOTSTRAP_SERVERS, KafkaWriterErrorCode.REQUIRED_VALUE);
this.conf.getNecessaryValue(Key.TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE);
}
@Override
public void init() {
this.conf = super.getPluginJobConf();
logger.info("kafka writer params:{}", conf.toJSON());
this.validateParameter();
}
@Override
public void destroy() {
}
}
public static class Task extends Writer.Task {
private static final Logger logger = LoggerFactory.getLogger(Task.class);
private static final String NEWLINE_FLAG = System.getProperty("line.separator", "\n");
private Producer<String, String> producer;
private String fieldDelimiter;
private Configuration conf;
private Properties props;
private AesEncryption aesEncryption;
private List<String> columns;
@Override
public void init() {
this.conf = super.getPluginJobConf();
fieldDelimiter = conf.getUnnecessaryValue(Key.FIELD_DELIMITER, "\t", null);
columns = conf.getList(Key.COLUMN_LIST, new ArrayList<>(), String.class);
props = new Properties();
props.put("bootstrap.servers", conf.getString(Key.BOOTSTRAP_SERVERS));
props.put("acks", conf.getUnnecessaryValue(Key.ACK, "0", null));//这意味着leader需要等待所有备份都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的保证。
props.put("retries", conf.getUnnecessaryValue(Key.RETRIES, "5", null));
props.put("retry.backoff.ms", "1000");
props.put("batch.size", conf.getUnnecessaryValue(Key.BATCH_SIZE, "16384", null));
props.put("linger.ms", 100);
props.put("connections.max.idle.ms", 300000);
props.put("max.in.flight.requests.per.connection", 5);
props.put("socket.keepalive.enable", true);
props.put("key.serializer", conf.getUnnecessaryValue(Key.KEYSERIALIZER, "org.apache.kafka.common.serialization.StringSerializer", null));
props.put("value.serializer", conf.getUnnecessaryValue(Key.VALUESERIALIZER, "org.apache.kafka.common.serialization.StringSerializer", null));
producer = new KafkaProducer<String, String>(props);
String encryptKey = conf.getUnnecessaryValue(Key.ENCRYPT_KEY, null, null);
if(encryptKey != null){
aesEncryption = new AesEncryption(encryptKey);
}
}
@Override
public void prepare() {
AdminClient adminClient = AdminClient.create(props);
ListTopicsResult topicsResult = adminClient.listTopics();
String topic = conf.getNecessaryValue(Key.TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE);
try {
if (!topicsResult.names().get().contains(topic)) {
new NewTopic(
topic,
Integer.parseInt(conf.getUnnecessaryValue(Key.TOPIC_NUM_PARTITION, "1", null)),
Short.parseShort(conf.getUnnecessaryValue(Key.TOPIC_REPLICATION_FACTOR, "1", null))
);
List<NewTopic> newTopics = new ArrayList<NewTopic>();
adminClient.createTopics(newTopics);
}
adminClient.close();
} catch (Exception e) {
throw new DataXException(KafkaWriterErrorCode.CREATE_TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE.getDescription());
}
}
@Override
public void startWrite(RecordReceiver lineReceiver) {
logger.info("start to writer kafka");
Record record = null;
while ((record = lineReceiver.getFromReader()) != null) {
if (conf.getUnnecessaryValue(Key.WRITE_TYPE, WriteType.TEXT.name(), null)
.equalsIgnoreCase(WriteType.TEXT.name())) {
producer.send(new ProducerRecord<String, String>(this.conf.getString(Key.TOPIC),
Md5Encrypt.md5Hexdigest(recordToString(record)),
aesEncryption ==null ? recordToString(record): JSONObject.toJSONString(aesEncryption.encrypt(recordToString(record))))
);
} else if (conf.getUnnecessaryValue(Key.WRITE_TYPE, WriteType.TEXT.name(), null)
.equalsIgnoreCase(WriteType.JSON.name())) {
producer.send(new ProducerRecord<String, String>(this.conf.getString(Key.TOPIC),
Md5Encrypt.md5Hexdigest(recordToString(record)),
aesEncryption ==null ? recordToJsonString(record) : JSONObject.toJSONString(aesEncryption.encrypt(recordToJsonString(record))))
);
}
producer.flush();
}
}
@Override
public void destroy() {
if (producer != null) {
producer.close();
}
}
/**
* 数据格式化
*
* @param record
* @return
*/
private String recordToString(Record record) {
int recordLength = record.getColumnNumber();
if (0 == recordLength) {
return NEWLINE_FLAG;
}
Column column;
StringBuilder sb = new StringBuilder();
for (int i = 0; i < recordLength; i++) {
column = record.getColumn(i);
sb.append(column.asString()).append(fieldDelimiter);
}
sb.setLength(sb.length() - 1);
sb.append(NEWLINE_FLAG);
return sb.toString();
}
/**
* 数据格式化
*
* @param record 数据
*
*/
private String recordToJsonString(Record record) {
int recordLength = record.getColumnNumber();
if (0 == recordLength) {
return "{}";
}
Map<String, Object> map = new HashMap<>();
for (int i = 0; i < recordLength; i++) {
String key = columns.get(i);
Column column = record.getColumn(i);
map.put(key, column.getRawData());
}
return JSONObject.toJSONString(map);
}
}
}进行数据加密的实现:
java
public class AesEncryption {
private SecretKey secretKey;
private static final int GCM_TAG_LENGTH = 16; // 16字节 (128位)
public AesEncryption(String secretKey) {
byte[] keyBytes = hexStringToByteArray(secretKey);
this.secretKey = new SecretKeySpec(keyBytes, 0, keyBytes.length, "AES");
}
public ResultModel encrypt(String data) {
try {
byte[] nonce = new byte[GCM_TAG_LENGTH];
new SecureRandom().nextBytes(nonce);
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
GCMParameterSpec gcmSpec = new GCMParameterSpec(GCM_TAG_LENGTH * 8, nonce);
cipher.init(Cipher.ENCRYPT_MODE, secretKey, gcmSpec);
byte[] encryptedBytes = cipher.doFinal(data.getBytes());
return new ResultModel(bytesToHex(nonce), bytesToHex(encryptedBytes));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 将 16 进制字符串转换为字节数组
*/
private byte[] hexStringToByteArray(String s) {
int len = s.length();
byte[] data = new byte[len / 2];
for (int i = 0; i < len; i += 2) {
data[i / 2] = (byte) ((Character.digit(s.charAt(i), 16) << 4)
+ Character.digit(s.charAt(i + 1), 16));
}
return data;
}
// 将字节数组转换为 16 进制字符串
public static String bytesToHex(byte[] bytes) {
StringBuilder hexString = new StringBuilder();
for (byte b : bytes) {
String hex = Integer.toHexString(0xff & b);
if (hex.length() == 1) hexString.append('0');
hexString.append(hex);
}
return hexString.toString();
}
}- starrocks-connector-for-kafka的实现
java
package com.starrocks.connector.kafka.transforms;
public class DecryptJsonTransformation <R extends ConnectRecord<R>> implements Transformation<R> {
private static final Logger LOG = LoggerFactory.getLogger(DecryptJsonTransformation.class);
private AesEncryption aesEncryption;
private interface ConfigName {
String SECRET_KEY = "secret.key";
}
public static final ConfigDef CONFIG_DEF = new ConfigDef()
.define(ConfigName.SECRET_KEY, ConfigDef.Type.STRING, ConfigDef.Importance.HIGH, "secret key");
@Override
public R apply(R record) {
if (record.value() == null) {
return record;
}
String value = (String) record.value();
try {
String newValue = aesEncryption.decrypt(value);
JSONObject jsonObject = JSON.parseObject(newValue, JSONReader.Feature.UseBigDecimalForDoubles);
return record.newRecord(record.topic(), record.kafkaPartition(), record.keySchema(), record.key(), null, jsonObject, record.timestamp());
} catch (Exception e) {
return record;
}
}
@Override
public ConfigDef config() {
return CONFIG_DEF;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
final SimpleConfig config = new SimpleConfig(CONFIG_DEF, map);
String secretKey = config.getString(ConfigName.SECRET_KEY);
aesEncryption = new AesEncryption(secretKey);
}
}
java
public class AesEncryption {
private SecretKeySpec secretKey;
public AesEncryption(String secretKey) {
byte[] keyBytes = hexStringToByteArray(secretKey);
this.secretKey = new SecretKeySpec(keyBytes, "AES");
}
public String encrypt(String data) {
try {
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
cipher.init(Cipher.ENCRYPT_MODE, secretKey);
byte[] encryptedBytes = cipher.doFinal(data.getBytes());
return Base64.getEncoder().encodeToString(encryptedBytes);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public String decrypt(String encryptedData) throws Exception {
JSONObject jsonMessage = JSONObject.parseObject(encryptedData);
byte[] ciphertext = hexStringToByteArray(jsonMessage.getString("ciphertext"));
byte[] nonce = hexStringToByteArray(jsonMessage.getString("nonce"));
return decryptData(ciphertext, nonce);
}
/**
* 使用 AES-GCM 解密数据
* @param ciphertext 密文
* @param nonce 随机 IV(nonce)
* @return 解密后的明文
* @throws Exception
*/
private String decryptData(byte[] ciphertext, byte[] nonce) throws Exception {
// 创建 GCMParameterSpec 对象,用于解密时的认证标签验证
GCMParameterSpec gcmSpec = new GCMParameterSpec(128, nonce); // 128 位标签
// 创建 AES Cipher 对象,设置为解密模式
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
cipher.init(Cipher.DECRYPT_MODE, secretKey , gcmSpec);
// 解密数据
// 2. 拼接ciphertext和tag
byte[] decryptedData = cipher.doFinal(ciphertext);
// 返回解密后的明文
return new String(decryptedData);
}
/**
* 将 16 进制字符串转换为字节数组
*/
private byte[] hexStringToByteArray(String s) {
int len = s.length();
byte[] data = new byte[len / 2];
for (int i = 0; i < len; i += 2) {
data[i / 2] = (byte) ((Character.digit(s.charAt(i), 16) << 4)
+ Character.digit(s.charAt(i + 1), 16));
}
return data;
}
}- Kafka的公网配置
Kafka的内外网配置,只需要修改kafka/config下面的server.properties文件中的如下配置即可。
properties
# 配置kafka的监听端口,同时监听9093和9092
listeners=INTERNAL://kafka节点3内网IP:9093,EXTERNAL://kafka节点3内网IP:9092
# 配置kafka的对外广播地址, 同时配置内网的9093和外网的19092
advertised.listeners=INTERNAL://kafka节点3内网IP:9093,EXTERNAL://公网IP:19092
# 配置地址协议
listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
# 指定broker内部通信的地址
inter.broker.listener.name=INTERNAL- Kafka-Connector的部署流程
a. 创建一个目录,来存放connect的
shell
# 创建文件
mkdir /opt/kafka-connect
# 将connect文件解压到该目录中b. 修改kafka的配置文件config/connect-distributed.properties(以1台为例)
properties
# 配置kafka的地址信息
bootstrap.servers=192.168.20.41:9093,192.168.20.42:9093,192.168.20.43:9093
# 配置connect的地址
plugin.path=/vmimg/opt/kafka-connect/starrocks-kafka-connectorc. 启动connect(以1台为例)
shell
nohup bin/connect-distributed.sh config/connect-distributed.properties > start_connect.log 2>&1 &- 监听数据库binlog文件并加密发送到kafka
python
import os
import json
import binascii
import logging
import re
from typing import List, Dict
from datetime import datetime, date, timedelta
from decimal import Decimal
from Crypto.Cipher import AES
from pymysqlreplication import BinLogStreamReader
from pymysqlreplication.row_event import BINLOG
from kafka import KafkaProducer
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(lineno)d - %(message)s',
filename='mzt-stream-rds1.log',
filemode='w')
class TableConfig:
"""
表配置信息
"""
def __init__(self, key: str, topic: str, need_table: bool, complete_regex: bool, regex: str, column_mapping: dict ):
"""
:param key:表的唯一id
:param topic topic名单
:param need_table 是否需要将表名称作为一个字段写入表,用于解决分库分别问题
:param complete_regex 是否完全匹配还是正则匹配
:param regex 匹配表的正则表达式
:param column_mapping 列的对应关系
"""
self.key = key
self.topic = topic
self.need_table = need_table
self.complete_regex = complete_regex
self.regex = regex
self.column_mapping = column_mapping
class TableConfigReader:
"""
解析表的配置文件
"""
def __init__(self, directory_path: str):
"""
:param directory_path 配置文件的目录
"""
self.directory_path = directory_path
# 配置列表
self.table_config_list: List[TableConfig] = []
def read(self):
"""
读取所有的配置文件,转换为配置列表
"""
entries = os.listdir(self.directory_path)
# 过滤出所有文件
files = [entry for entry in entries if
os.path.isfile(os.path.join(self.directory_path, entry)) and entry.endswith(".json")]
logging.info(f"读取配置文件数量:{len(files)}")
for file in files:
file_path = os.path.join(self.directory_path, file)
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
json_data = json.loads(content)
self.table_config_list.append(TableConfig(json_data['key'], json_data['topic'], json_data['need_table'], json_data['complete_regex'], json_data['regex'], json_data['column_mapping']))
class PrefixTrie:
"""
用于匹配表名称
"""
def __init__(self, complete_regex_map: Dict[str, TableConfig], not_complete_list:List[TableConfig]):
"""
:param complete_regex_map 完全匹配的表配置信息字典
:param not_complete_list 正则匹配的列表
"""
self.complete_regex_map = complete_regex_map
self.not_complete_list = not_complete_list
def search(self, text):
if text in self.complete_regex_map.keys():
# 完全匹配
return self.complete_regex_map[text]
for data in self.not_complete_list:
# 正则匹配
match = re.match(data.regex, text)
if match:
return data
return None
class MysqlConfig:
"""
MYSQL的连接
"""
def __init__(self, host:str, port:int, user:str, password:str, service_id:int):
"""
:param host 数据库的host
:param port 数据库的port
:param user 数据库的user
:param password 数据库的password
:param service_id 数据库的server_id, 用于binlog同步
"""
self.host = host
self.port = port
self.user = user
self.password = password
self.service_id = service_id
class KafkaBinlogStreamer:
"""
真正的binlog消费
"""
def __init__(self, kafka_server: str, mysql_config:MysqlConfig, trie_tree: PrefixTrie, aes_key):
"""
:param kafka_server kafka的地址
:param mysql_config MYSQL的配置信息
:param trie_tree 名称匹配的信息
:param aes_key 数据加密的秘钥
"""
self.producer = self._init_kafka_producer(kafka_server)
self.mysql_config = mysql_config
self.stream = None
self.trie_tree = trie_tree
self.aes_key = aes_key
def _init_kafka_producer(self, kafka_server):
"""
初始化 Kafka Producer
:param kafka_server kafka的地址
"""
producer = KafkaProducer(
bootstrap_servers=kafka_server,
batch_size=16384, # 批量发送的大小(字节)
linger_ms=100, # 等待时间(毫秒),等待更多消息达到 batch_size
max_request_size=10485760, # 最大请求大小(字节)
acks=1, # 等待所有副本的确认
retries=3, # 重试次数
value_serializer=lambda v: json.dumps(v, default=self.json_serial, ensure_ascii=False).encode('utf-8')
)
logging.info("Kafka producer initialized.")
return producer
@staticmethod
def json_serial(obj):
"""
JSON serializer for objects not serializable by default json code
"""
if isinstance(obj, (datetime, date)):
return obj.strftime('%Y-%m-%d %H:%M:%S')
if isinstance(obj, Decimal):
return float(obj)
if isinstance(obj, bytes):
return obj.decode('utf-8')
if isinstance(obj, timedelta):
# 将 timedelta 类型转换为字符串格式
return str(obj)
if isinstance(obj, dict):
return {KafkaBinlogStreamer.json_serial(k): KafkaBinlogStreamer.json_serial(v) for k, v in obj.items()}
# 处理列表类型
if isinstance(obj, list):
return [KafkaBinlogStreamer.json_serial(item) for item in obj]
logging.warning(f"Type '{obj.__class__}' for '{obj}' not serializable")
return None
@staticmethod
def convert_bytes_keys_to_str(data):
"""
递归转换字典中的 bytes 键为 str
"""
if isinstance(data, dict):
# 将字典中的 bytes 类型的键转换为 str
return {
(k.decode('utf-8') if isinstance(k, bytes) else k): KafkaBinlogStreamer.convert_bytes_keys_to_str(v)
for k, v in data.items()
}
elif isinstance(data, list):
# 对列表中的每个元素递归转换
return [KafkaBinlogStreamer.convert_bytes_keys_to_str(item) for item in data]
elif isinstance(data, bytes):
# 对 bytes 类型的值进行转换
return data.decode('utf-8')
elif isinstance(data, datetime):
# 将 datetime 类型转换为 ISO 格式字符串
return data.strftime('%Y-%m-%d %H:%M:%S')
else:
return data
def build_message(self, binlog_evt, trie_tree: PrefixTrie):
"""
构建消息
:param binlog_evt binlog事件
:param trie_tree 匹配树
"""
schema = str(f"{getattr(binlog_evt, 'schema', '')}.{getattr(binlog_evt, 'table', '')}")
table_name = str(f"{getattr(binlog_evt, 'table', '')}")
# 获取配置
table_config = trie_tree.search(schema)
if table_config is None:
return None
topic = table_config.topic
if binlog_evt.event_type == BINLOG.WRITE_ROWS_EVENT_V1:
# Insert
data_rows = binlog_evt.rows
data_list = []
for data_row in data_rows:
data_list.append(self._map_columns(self.convert_bytes_keys_to_str(data_row['values']), table_name, table_config, 0))
return {'event': 'INSERT', 'headers': {'topic': topic}, 'data_list': data_list}
elif binlog_evt.event_type == BINLOG.UPDATE_ROWS_EVENT_V1:
# Update
data_rows = binlog_evt.rows
data_list = []
for data_row in data_rows:
data_list.append(self._map_columns(self.convert_bytes_keys_to_str(data_row['after_values']), table_name, table_config, 0))
return {'event': 'INSERT', 'headers': {'topic': topic}, 'data_list': data_list}
elif binlog_evt.event_type == BINLOG.DELETE_ROWS_EVENT_V1:
# Delete
data_rows = binlog_evt.rows
data_list = []
for data_row in data_rows:
data_list.append(self._map_columns(self.convert_bytes_keys_to_str(data_row['values']), table_name, table_config, 1))
return {'event': 'DELETE', 'headers': {'topic': topic}, 'data_list': data_list}
return None
@staticmethod
def _map_columns(values, table_name: str, table_config: TableConfig, op_data: int):
"""
对列名进行映射
:param values 数据
:param table_name 表名称
:param table_config 表的配置
:param op_data op操作
"""
column_mapping = table_config.column_mapping
need_table = table_config.need_table
mapped_values = {}
for column, value in values.items():
# 如果列名在映射字典中,则替换为映射的列名
if column in column_mapping:
mapped_column = column_mapping.get(column)
mapped_values[mapped_column] = value
if need_table:
mapped_values['table_name'] = table_name
mapped_values['__op'] = op_data
return mapped_values
def encrypt_data(self, data):
"""
使用 AES-GCM 加密数据
:param data 待加密数据
"""
cipher = AES.new(self.aes_key, AES.MODE_GCM)
ciphertext, tag = cipher.encrypt_and_digest(data.encode('utf-8'))
return {
'nonce': cipher.nonce.hex(),
'ciphertext': ciphertext.hex() + tag.hex()
}
def start_stream(self):
"""
开始监听 MySQL Binlog 流
"""
logging.info("Starting binlog stream...")
mysql_settings = {
'host': self.mysql_config.host,
'port': self.mysql_config.port,
'user': self.mysql_config.user,
'password': self.mysql_config.password,
}
self.stream = BinLogStreamReader(
connection_settings=mysql_settings,
server_id=self.mysql_config.service_id,
resume_stream=True,
blocking=True,
# only_events=[BINLOG.WRITE_ROWS_EVENT_V1, BINLOG.UPDATE_ROWS_EVENT_V1, BINLOG.DELETE_ROWS_EVENT_V1]
)
try:
for evt in self.stream:
msg = self.build_message(evt, self.trie_tree)
if msg:
topic = msg['headers']['topic']
data_list = msg['data_list']
for data_row in data_list:
try:
self.producer.send(topic, value=self.encrypt_data(json.dumps(data_row, default=self.json_serial, ensure_ascii=False)))
except Exception as e:
logging.info(e)
logging.info(topic)
logging.info(data_row)
raise e
except KeyboardInterrupt:
logging.info("Binlog stream interrupted by user.")
finally:
self.close()
def close(self):
"""
关闭资源
"""
if self.stream:
self.stream.close()
logging.info("Binlog stream closed.")
self.producer.close()
self.producer.flush()
logging.info("Kafka producer closed.")
if __name__ == "__main__":
# 读取表配置
BASE_PATH = "/opt/py38/data-job-stream"
CONFIG_PATH = BASE_PATH + "/" + "config/rds1"
table_config_data_list = TableConfigReader(CONFIG_PATH)
table_config_data_list.read()
complete_regex_table_dict = {}
not_complete_regex_table_dict_list = []
for table_config in table_config_data_list.table_config_list:
if table_config.complete_regex:
complete_regex_table_dict[table_config.key] = table_config
else:
not_complete_regex_table_dict_list.append(table_config)
# 构建 Trie 树
trie = PrefixTrie(complete_regex_table_dict, not_complete_regex_table_dict_list)
# 配置参数
KAFKA_SERVER = "ip:19092,ip2:19093,ip3:19094"
mysql_config = MysqlConfig("*.mysql.rds.aliyuncs.com", 3306, "username",
"password", 100)
# 对称加密的秘钥
hex_key = "6253c3d*************8b5deba549"
key_bytes = binascii.unhexlify(hex_key)
# 创建并启动 Kafka Binlog Streamer
streamer = KafkaBinlogStreamer(KAFKA_SERVER, mysql_config, trie, key_bytes)
streamer.start_stream()脚本中依赖的版本信息
plain
kafka_python==2.0.2
mysql_replication==0.45.1
pycryptodome==3.21.0七、配套生态脚本
- 批量与增量配置文件的生成
在同步一张新表的时候,可以修改改脚本中的RDS数据库的信息,运行该脚本,自动生成各个数据同步步骤的配置文件和脚本信息。
如果 数据库名称:test 表名称为:test_1, StarRocks中表名称为:ods_test_1, 运行该脚本之后会生成如下的文件
- test.test_1.json 该文件是用于binlog同步的配置文件。
- mzt_ods_cjm_all.test_1_connect.json 该文件是用于历史数据批量同步的KafkaConnector配置。
- mzt_ods_cjm_all.test_1_datax_config.json 该文件是用于历史数据批量同步的DataX配置。
- mzt_ods_cjm_all.test_1_datax_shell.sh 该文件是用于执行DataX任务的启动脚本。
- mzt_ods_cjm_stream.ods_test_1-connect.json 该文件是用于增量数据同步的KafkaConnector配置。
- ods_test_1_create_table.sql 该文件是用于在StarRocks中建表的SQL脚本文件。
python
import os
import shutil
import pymysql
import re
import json
class MySQLMATEDATA():
"""
mysql 列的元数据信息
"""
def __init__(self, column_name: str, is_nullable: str, data_type: str,character_maximum_length:
int,column_key: int, numeric_precision: int, comment: str):
"""
初始化
:param column_name 列名称
:param is_nullable 是否可以为空
:param data_type 字段类型
:param character_maximum_length 字符最大长度
:param column_key 键
:param numeric_precision 数字精度
:param comment 注释
"""
self.column_name = column_name
self.new_column_name = MySQLMATEDATA.camel_to_snake(self.column_name)
self.is_nullable = True if is_nullable == 'NO' else False
self.data_type = data_type
self.character_maximum_length = character_maximum_length
self.column_key = column_key
self.numeric_precision = numeric_precision
self.is_primary_key = True if column_key == 'PRI' else False
self.comment = comment
def transform_to_starrcocks(self) -> str:
"""
转换为StarRocks的列
:return: StarRocks的列
"""
column_str = self.new_column_name
if self.data_type == 'timestamp':
column_str += ' DATETIME '
else:
if self.character_maximum_length is not None:
column_str += ' ' + self.data_type + '( ' + str(self.character_maximum_length * 3) + ") "
elif self.numeric_precision is not None:
column_str += ' ' + self.data_type + '( ' + str(self.numeric_precision + 1) + ') '
else:
column_str += ' ' + self.data_type + ' '
if self.is_primary_key:
column_str += ' NOT NULL '
if self.comment is not None:
column_str += ' COMMENT "' + self.comment + '"'
return column_str + ','
def transform_to_datax(self) -> str:
"""
转换列名称为 DATAX 需要的列
:return: 新的列
"""
type = str(self.data_type).lstrip().lower()
if type == 'datetime' or type == 'timestamp':
return 'DATE_FORMAT('+ self.column_name + ', \'%Y-%m-%d %H:%i:%s\') AS ' + self.new_column_name
elif type == 'date' :
return 'DATE_FORMAT(' + self.column_name + ', \'%Y-%m-%d\') AS ' + self.new_column_name
return self.column_name
@staticmethod
def camel_to_snake(name):
"""
在大写字母前面加上下划线,并转换为小写
:param name: 列名称
:return: 新的列名称
"""
snake_case = re.sub(r'(?<!^)(?=[A-Z])', '_', name).lower()
return snake_case
class ConfigGeneral(object):
"""
数据同步相关的配置文件生成
"""
def __init__(self, database: str, table: str, topic: str, n_table: str, s_topic: str, mysql_host: str, mysql_port: int,
mysql_user: str, mysql_passwd: str):
"""
初始化
:param database mysql数据库名称
:param table mysql表名称
:param topic 批量同步的topic名称
:param n_table StarRocks表名称
:param s_topic 流式同步的topic的名称
:param mysql_host mysql的host
:param mysql_port mysql的port
:param mysql_user mysql的用户名
:param mysql_passwd mysql的密码
"""
self.database = database
self.table = table
self.topic = topic
self.n_table = n_table
self.s_topic = s_topic
self.mysql_host = mysql_host
self.mysql_port = mysql_port
self.mysql_user = mysql_user
self.mysql_passwd = mysql_passwd
self.column_list = []
self.jdbc_url = 'jdbc:mysql://{}:{}/{}?characterEncoding=utf-8&useSSL=false&tinyInt1isBit=false'.format(self.mysql_host, self.mysql_port, self.database)
def search_column_name(self):
"""
查询mysql中表的元数据
:return: 元数据列表
"""
sql ="""SELECT
COLUMN_NAME,
IS_NULLABLE,
DATA_TYPE,
CHARACTER_MAXIMUM_LENGTH,
COLUMN_KEY,
NUMERIC_PRECISION,
COLUMN_COMMENT
FROM information_schema.`COLUMNS`
WHERE table_schema='{}' AND table_name = '{}'
ORDER BY ORDINAL_POSITION ASC""".format(self.database, self.table)
table_name_list = []
conn = pymysql.connect(host=self.mysql_host,
port=self.mysql_port,
user=self.mysql_user,
passwd=self.mysql_passwd,
db=self.database,
charset='utf8',
connect_timeout=200,
autocommit=True,
read_timeout=2000
)
with conn.cursor() as cursor:
cursor.execute(query=sql)
while 1:
res = cursor.fetchone()
if res is None:
break
table_name_list.append(MySQLMATEDATA(res[0], res[1], res[2], res[3], res[4], res[5], res[6]))
self.column_list = table_name_list
conn.close()
def create_all_datax_config(self) -> str:
"""
生成DATAX的配置文件
:return: 配置文件地址
"""
datax_config ={
"job":{
"setting" :{
"speed":{
"channel":1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "",
"password": "",
"column": [],
"connection": [
{
"table": [],
"jdbcUrl": []
}
],
}
},
"writer": {
"name": "kafkawriter",
"parameter": {
"bootstrapServers": "IP1:19092,IP2:19093,IP3:19094",
"topic": "",
"ack": "all",
"batchSize": 1000,
"retries": 3,
"keySerializer": "org.apache.kafka.common.serialization.StringSerializer",
"valueSerializer": "org.apache.kafka.common.serialization.StringSerializer",
"fieldDelimiter": ",",
"writeType": "json",
"topicNumPartition": 1,
"topicReplicationFactor": 1,
"encryptionKey": "6253c3************a549",
"column": []
}
}
}
]
}
}
new_column_name_list =[]
new_column_name_list1 =[]
for column in self.column_list:
new_column_name = column.new_column_name
new_column_name_list.append(column.transform_to_datax())
new_column_name_list1.append(new_column_name)
datax_config['job']['content'][0]['reader']['parameter']['column'] = new_column_name_list
datax_config['job']['content'][0]['writer']['parameter']['column'] = new_column_name_list1
datax_config['job']['content'][0]['reader']['parameter']['connection'][0]['table'] = [self.table]
datax_config['job']['content'][0]['reader']['parameter']['connection'][0]['jdbcUrl'] = [self.jdbc_url]
datax_config['job']['content'][0]['writer']['parameter']['topic'] = self.topic
with open('config/' + self.topic + '_datax_config.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(datax_config, ensure_ascii=False, indent=2))
return self.topic + '_datax_config.json'
def create_all_datax_shell(self, config_path: str):
"""
生成DATAX的执行脚本文件
:param config_path: 配置文件的路径
:return: 脚本文件路径
"""
text = """python3 /opt/datax-k/bin/datax.py {} """.format(config_path)
with open('config/' + self.topic + '_datax_shell.sh', 'w', encoding='utf-8') as f:
f.write(text)
return self.topic + '_datax_shell.sh'
def create_all_connect(self) -> str:
"""
生成全量同步的kafka-connect的配置文件
:return: 配置文件路径
"""
connect_config = {
"name": "",
"config": {
"connector.class": "com.starrocks.connector.kafka.StarRocksSinkConnector",
"topics": "",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "true",
"value.converter.schemas.enable": "false",
"starrocks.http.url": "IP1:8050,IP2:8050,IP3:8050",
"starrocks.topic2table.map": "",
"starrocks.username": "",
"starrocks.password": "",
"starrocks.database.name": "ods_cjm",
"sink.properties.strip_outer_array": "true",
"sink.properties.columns": "",
"sink.properties.jsonpaths": "",
"transforms": "decrypt",
"transforms.decrypt.type": "com.starrocks.connector.kafka.transforms.DecryptJsonTransformation",
"transforms.decrypt.secret.key": "6253****************a549"
}
}
connect_config['name'] = self.topic + "-connect"
connect_config['config']['topics'] = self.topic
connect_config['config']['starrocks.topic2table.map'] = self.topic + ":" + self.n_table
connect_config['config']['sink.properties.columns'] = ",".join(list(map(lambda x: x.new_column_name ,self.column_list)))
connect_config['config']['sink.properties.jsonpaths'] = '[' + (",".join(list(map(lambda x : ("\"$." + x.column_name + "\"") ,self.column_list)))) + "]"
with open('config/' + self.topic + '_connect.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(connect_config, ensure_ascii=False, indent=2))
return self.topic + '_connect.json'
def search_table_create_sql(self):
"""
生成StarRocks的建表语句
:return: 文件路径
"""
table_sql_list = " CREATE TABLE " + self.n_table +" (" + "\n"
primary_key = ''
for column in self.column_list:
table_sql_list = table_sql_list + column.transform_to_starrcocks() +"\n"
if column.is_primary_key:
primary_key = column.column_name
table_sql_list = table_sql_list +")\n"
table_sql_list = table_sql_list +"PRIMARY KEY ("+ primary_key+")\n"
table_sql_list = table_sql_list +"DISTRIBUTED BY HASH ("+ primary_key+");\n"
with open('config/' + self.n_table + '_create_table.sql', 'w', encoding='utf-8') as f:
f.write(table_sql_list)
return self.n_table + '_create_table.sql'
def create_stream_config(self):
"""
生成mysql binlog同步的配置文件
:return: 文件路径
"""
config = {
"key": "",
"topic": "",
"need_table": False,
"complete_regex": True,
"regex": "",
"column_mapping": {}
}
column_mapping = {}
for column in self.column_list:
column_mapping[column.column_name] = column.new_column_name
config['column_mapping'] = column_mapping
config['key'] = self.database + '.' + self.table
config['topic'] = self.s_topic
with open('config/' + self.database + '.' + self.table + '.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(config, ensure_ascii=False, indent=2))
def create_stream_connect(self):
"""
生成流式同步的kafka-connector的配置文件
:return: 文件路径
"""
connect_config = {
"name": "",
"config": {
"connector.class": "com.starrocks.connector.kafka.StarRocksSinkConnector",
"topics": "",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "true",
"value.converter.schemas.enable": "false",
"starrocks.http.url": "IP1:8050,IP2:8050,IP3:8050",
"starrocks.topic2table.map": "",
"starrocks.username": "",
"starrocks.password": "",
"starrocks.database.name": "ods_cjm",
"sink.properties.strip_outer_array": "true",
"sink.properties.columns": "",
"sink.properties.jsonpaths": "",
"transforms": "decrypt",
"transforms.decrypt.type": "com.starrocks.connector.kafka.transforms.DecryptJsonTransformation",
"transforms.decrypt.secret.key": "6253********549"
}
}
connect_config['name'] = self.s_topic + "-connect"
connect_config['config']['topics'] = self.s_topic
connect_config['config']['starrocks.topic2table.map'] = self.s_topic + ":" + self.n_table
connect_config["config"]["sink.properties.columns"] = ",".join(list(map(lambda x : x.new_column_name ,self.column_list))) +",__op"
connect_config["config"]["sink.properties.jsonpaths"] = '[' + (",".join(list(map(lambda x : ("\"$." + x.new_column_name + "\"") ,self.column_list)))) + ",\"$.__op\"]"
with open('config/' + self.s_topic + '-connect.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(connect_config, ensure_ascii=False, indent=2))
return self.s_topic + '_connect.json'
def delete_all_files_in_folder(folder_path):
"""
删除某个文件夹下面的所有文件
:param folder_path: 文件夹路径
:return: NONE
"""
# 检查文件夹是否存在
if not os.path.exists(folder_path):
print("文件夹不存在")
return
# 遍历文件夹中的所有文件和子文件夹
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
try:
# 如果是文件,则删除
if os.path.isfile(file_path) or os.path.islink(file_path):
os.remove(file_path)
print(f"删除文件: {file_path}")
# 如果是子文件夹,则删除子文件夹及其内容
elif os.path.isdir(file_path):
shutil.rmtree(file_path)
print(f"删除文件夹及其内容: {file_path}")
except Exception as e:
print(f"删除时出错: {file_path},错误信息: {e}")
if __name__ == '__main__':
delete_all_files_in_folder("config")
DATABASE = 'hydra_marketing'
TABLE ='t_data_overview'
TOPIC ='mzt_ods_cjm_all.' + TABLE
NEW_TABLE = 'ods_marketing_t_data_overview'
STREAM_TOPIC = "mzt_ods_cjm_stream." + NEW_TABLE
MYSQL_HOST = ""
MYSQL_PORT = 3306
USER_NAME = ""
PASSWD=""
config = ConfigGeneral(DATABASE,TABLE, TOPIC, NEW_TABLE, STREAM_TOPIC, MYSQL_HOST, MYSQL_PORT, USER_NAME, PASSWD)
config.search_column_name()
config.search_table_create_sql()
config_path = config.create_all_datax_config()
config.create_all_datax_shell(config_path)
config.create_all_connect()
config.create_stream_config()
config.create_stream_connect()- Kafka-Connector操作脚本
该脚本包含了Kafka Connector操作的各个API,可以很方便的进行Kafka Connector相关的操作或者各个任务的状态查询。
python
import json
import requests
from typing import List, Mapping
class KafkaConnectAll:
"""
KAFKA Connect 相关操作
"""
def __init__(self, base_url: str):
"""
初始化
:param base_url: kafka-connector的地址
"""
self.base_url = base_url
def query_all(self) -> List[str]:
"""
查询全部的connector
:return: connector名称列表
"""
url = self.base_url + '/connectors'
data_json = requests.get(url).json()
for data in data_json:
print(data)
return data_json
def delete_connector(self, connector_name: str):
"""
删除指定的connector
:param connector_name: connector名称
:return: None
"""
url = self.base_url + '/connectors/' + connector_name
requests.delete(url)
def query_status(self, connector_name: str) -> Mapping[str, str]:
"""
查询指定connector的状态
:param connector_name: connector名称
:return: 状态信息
"""
url = self.base_url + '/connectors/' + connector_name + '/status'
result = requests.get(url)
connect_state = result.json()['connector']['state']
task_states = []
for task in result.json()['tasks']:
task_states.append({
'id': task['id'],
'state': task['state'],
})
print("connector状态", connect_state)
print("tasks状态", task_states)
return {
"connector_status": connect_state,
"task_states": task_states
}
def create_connector(self, connector_config: json):
"""
创建connector
:param connector_config: 配置文件
:return: NONE
"""
url = self.base_url + '/connectors'
headers = {"Content-Type": "application/json"}
try:
# 发送 POST 请求创建 Connector
response = requests.post(url, headers=headers, data=json.dumps(connector_config))
if response.status_code == 201:
print("Connector 创建成功")
print(response.json())
elif response.status_code == 409:
print("Connector 已经存在")
else:
print(f"Connector 创建失败,状态码: {response.status_code}")
print(response.json())
except Exception as e:
print(f"请求失败: {e}")
def query_connector(self, connector_name: str) -> json:
"""
查询指定的connector
:param connector_name: connector名称
:return: 内容
"""
url = self.base_url + '/connectors/' + connector_name
result = requests.get(url).json()
print(json.dumps(result, indent=4))
return result
def query_connector_config(self, connector_name: str) -> json:
"""
查询指定connector的配置文件
:param connector_name: connector名称
:return: 配置
"""
url = self.base_url + '/connectors/' + connector_name + "/config"
result = requests.get(url).json()
print(json.dumps(result, indent=4))
return result
def update_connector_config(self, connector_name: str, connector_config: json):
"""
修改指定connector的配置
:param connector_name: 指定connector名称
:param connector_config: 配置
:return: NONE
"""
url = self.base_url + '/connectors/' + connector_name + "/config"
headers = {"Content-Type": "application/json"}
try:
# 发送 POST 请求创建 Connector
response = requests.put(url, headers=headers, data=json.dumps(connector_config))
if response.status_code == 201:
print("Connector 更新成功")
print(response.json())
elif response.status_code == 409:
print("Connector 已经存在")
else:
print(f"Connector 更新失败,状态码: {response.status_code}")
print(response.json())
except Exception as e:
print(f"请求失败: {e}")
def query_connectors_task(self, connector_name: str) -> List[int]:
"""
查询指定connector的task列表
:param connector_name: 指定connector名称
:return: taskId列表
"""
url = self.base_url + '/connectors/' + connector_name + '/tasks'
result = requests.get(url).json()
print(json.dumps(result, indent=4))
task_id = []
for task in result:
task_id.append(task['id']['task'])
return task_id
def query_connectors_tasks_status(self, connector_name: str, task_id: int) -> json:
"""
查询task的状态
:param connector_name: 指定connector的名称
:param task_id: task id
:return: 结果
"""
url = self.base_url + '/connectors/' + connector_name + '/tasks/' + str(task_id) + '/status'
result = requests.get(url).json()
print(json.dumps(result, indent=4))
return result
def pause_connector(self, connector_name: str):
"""
暂停connector
:param connector_name: connector 名称
:return: NONE
"""
url = self.base_url + '/connectors/' + connector_name + '/pause'
requests.put(url).json()
def resume_connector(self, connector_name: str):
"""
恢复
:param connector_name: connector名称
:return: NONE
"""
url = self.base_url + '/connectors/' + connector_name + '/resume'
requests.put(url).json()
def restart_connector(self, connector_name: str):
"""
重启
:param connector_name: connector名称
:return: NONE
"""
url = self.base_url + '/connectors/' + connector_name + '/restart'
requests.post(url).json()
def restart_connector_task(self, connector_name: str, task_id: int):
"""
重启task
:param connector_name: connector名称
:param task_id: task id
:return: NONE
"""
url = self.base_url + '/connectors/' + connector_name + '/tasks/' + str(task_id) + '/restart'
requests.post(url).json()
if __name__ == '__main__':
base_url = 'http://IP:8083'
kafka_connector_all = KafkaConnectAll(base_url)
kafka_connector_all.query_connectors_tasks_status('user_sys_org-connect', 0)- StarRocks表最新日期检测脚本
该脚本用于检测StarRocks各个表中的最新的数据的时间,可以用于判断当前数据同步是否正常时使用。
python
import pymysql
from typing import Tuple
import json
class StarRocksTableCheck:
"""
starrocks表数据最新日期检测
"""
def __init__(self, host: str, port: int, user: str, password: str, database: str):
"""
初始化
:param host: 数据库host
:param port: 数据库端口
:param user: 数据源用户名称
:param password: 数据库用户密码
:param database: 数据库名称
"""
self.host = host
self.port = port
self.user = user
self.password = password
self.database = database
# 数据库连接
self.conn = None
def connect(self) -> None:
"""
创建连接
:return: None
"""
self.conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.password,
db=self.database,
charset='utf8',
connect_timeout=200,
autocommit=True,
read_timeout=2000
)
def close(self) -> None:
"""
关闭数据库连接
:return: NONE
"""
self.conn.close()
def query(self, table: str, time_filed: str) -> Tuple[str, str]:
"""
查询最大日期
:param table: 数据表名称
:param time_filed: 时间字段名称
:return: 表名称-最新时间
"""
sql = "SELECT MAX({}) AS MAX_TIME FROM {}".format(time_filed, table)
with self.conn.cursor() as cursor:
cursor.execute(query=sql)
while 1:
res = cursor.fetchone()
if res is None:
break
print('{} {}'.format(table, res[0]))
return str(res[0]), str(res[1])
class ReaderFile:
"""
读取文件
"""
def __init__(self,file_path: str):
"""
初始化
:param file_path: 文件路径
"""
self.file_path = file_path
def read_file_content(self) -> str:
"""
读取文件内容
:return: 文件内容
"""
with open(self.file_path, 'r', encoding='utf-8') as file:
content = file.read()
return content
if __name__ == '__main__':
starRocksTableCheck = StarRocksTableCheck("ip", 9030, "username", "password", "ods_cjm")
starRocksTableCheck.connect()
try:
content = ReaderFile(r'E:\pycode\python_scripts_new\超级码\stream\config\starrocks_table.json').read_file_content()
for table in json.loads(content):
table_name = table['TABLE_NAME']
column_name = table['COLUMN_NAME']
starRocksTableCheck.query(table_name, column_name)
finally:
starRocksTableCheck.close()表信息的配置文件,配置需要检测的表和对应的时间字段。
json
[
{
"TABLE_NAME": "ods_codemanager_codeapply",
"COLUMN_NAME": "create_date"
},
{
"TABLE_NAME": "ods_t_integral_account",
"COLUMN_NAME": "update_time"
}
]- 增量同步任务检测脚本
该脚本用于检测当前的数据同步任务脚本是否正常运行,未运行可以直接启动脚本,可以配置crontab实现服务的异常终止直接启动操作,可以加入消息告警。
shell
#!/bin/bash
# 要检测的 Python 脚本列表
PROCESS_LIST=("mzt-transform-stream-kafka-rds1.py" "mzt-transform-stream-kafka-rds2.py")
# 启动命令列表
START_CMD_LIST=(
"nohup python3 mzt-transform-stream-kafka-rds1.py > /opt/py38/data-job-stream/nohup1.out 2>&1 &"
"nohup python3 mzt-transform-stream-kafka-rds2.py > /opt/py38/data-job-stream/nohup2.out 2>&1 &"
)
# 目录
BASE_PATH="/opt/py38/data-job-stream"
# 虚拟环境路径
VENV_PATH="/opt/py38/bin/activate"
# 检测进程是否存在
check_process() {
local process_name="$1"
if pgrep -f "$process_name" > /dev/null; then
echo "$(date) - 进程 '$process_name' 正在运行。"
return 0
else
echo "$(date) - 进程 '$process_name' 未运行。"
return 1
fi
}
# 启动进程
start_process() {
local start_cmd="$1"
echo "$(date) - 正在启动命令: $start_cmd"
# 进入目录
cd "$BASE_PATH" || exit 1
# 激活虚拟环境
source "$VENV_PATH"
# 执行启动命令
eval "$start_cmd"
if [ $? -eq 0 ]; then
echo "$(date) - 命令启动成功。"
else
echo "$(date) - 命令启动失败!"
fi
}
# 主逻辑
for index in "${!PROCESS_LIST[@]}"; do
process_name="${PROCESS_LIST[$index]}"
start_cmd="${START_CMD_LIST[$index]}"
echo "----- 检测进程:$process_name -----"
if ! check_process "$process_name"; then
start_process "$start_cmd"
fi
done- 增量同步的配置文件示例
这是一个用于增量数据同步的配置文件,其配置了具体的某张表的增量数据同步规则。
json
{
"key": "app.device",
"topic": "mzt_ods_cjm_stream.ods_device",
"need_table": false,
"complete_regex": true,
"regex": "",
"column_mapping": {
"Id": "id",
"CompanyName": "company_name",
"CompanyId": "company_id",
"SecretKey": "secret_key",
"Brand": "brand",
"ModelType": "model_type",
"Enable": "enable",
"CreateTime": "create_time",
"UpdateTime": "update_time"
}
}| KEY | 说明 |
|---|---|
| key | 表的唯一id,用于匹配binlog日志,组成为库.表 或者 模糊匹配开头 |
| topic | 数据写入的kafka的topic名称 |
| need_table | 列中是否需要加入表明,如何为true,则列中会加入一个字段table_name,值为当前RDS中表的名称,用于解决分库分表的问题 |
| complete_regex | 是否完整匹配表名称,如果为true,则根据key完整匹配表名称,用于解决分库分表的问题, 如果为false,则根据regex的值进行正常匹配 |
| regex | 匹配binlog表的正则表达式 |
| column_mapping | 表的列字段的映射,key为RDS中表字段名称。value为StarRocks中表字段的名称 |
- kafkaConnector的配置示例
json
{
"name": "mzt_ods_cjm_stream.ods_device-connect",
"config": {
"connector.class": "com.starrocks.connector.kafka.StarRocksSinkConnector",
"topics": "mzt_ods_cjm_stream.ods_device",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "true",
"value.converter.schemas.enable": "false",
"starrocks.http.url": "IP1:8050,IP2:8050,IP3:8050",
"starrocks.topic2table.map": "mzt_ods_cjm_stream.ods_device:ods_device",
"starrocks.username": "",
"starrocks.password": "",
"starrocks.database.name": "ods_cjm",
"sink.properties.strip_outer_array": "true",
"sink.properties.columns": "id,company_name,company_id,secret_key,brand,model_type,enable,create_time,update_time,__op",
"sink.properties.jsonpaths": "[\"$.id\",\"$.company_name\",\"$.company_id\",\"$.secret_key\",\"$.brand\",\"$.model_type\",\"$.enable\",\"$.create_time\",\"$.update_time\",\"$.__op\"]",
"transforms": "decrypt",
"transforms.decrypt.type": "com.starrocks.connector.kafka.transforms.DecryptJsonTransformation",
"transforms.decrypt.secret.key": "6253******a549"
}| KEY | 说明 |
|---|---|
| name | kafka connector的唯一名称 |
| config.connector.class | 连接器 默认值 |
| config.topics | 要消费的topic列表,多个使用,分隔 |
| config.key.converter | key的转换器,保持默认 |
| config.value.converter | value的转换器,保持默认 |
| config.key.converter.schemas.enable | 是否需要转换key |
| config.value.converter.schemas.enable | 是否需要转换value |
| config.starrocks.http.url | StarRocks用于streamLoad的地址 |
| config.starrocks.topic2table.map | topic与表的映射, 格式为 topic名称:表名, 多个直接使用,分隔 |
| config.starrocks.username | StarRocks的用户名 |
| config.starrocks.password | StarRocks的密码 |
| config.starrocks.database.name | StarRocks数据库的名称 |
| config.sink.properties.strip_outer_array | 是否展开JSON数组 |
| config.sink.properties.columns | 列字段的列表 |
| config.sink.properties.jsonpaths | JSON字段的列表,可列字段的列表一一对应 |
| config.transforms | 数据的转换器 |
| config.transforms.decrypt.type | 转换器的实现类 |
| config.transforms.decrypt.secret.key | 数据解密的秘钥 |
八、备注
- python-mysql-replication python实现的用于binlog同步的库。
- starrocks-connector-for-kafka Kafka Connector是StarRocks数据源连接器
- DataX 批量数据同步工具
- kafka-console-ui Kakfa可视化控制台
- StarRocks-kafka-Connector 通过kafkaConnector导入数据到StarRocks
- StreamLoad实现数据增删改
- Kafka Connector的API列表
| 方法 | 路径 | 说明 |
|---|---|---|
| GET | /connectors | 返回活动连接器的列表 |
| POST | /connectors | 创建一个新的连接器; 请求主体应该是包含字符串name字段和config带有连接器配置参数的对象字段的JSON对象 |
| GET | /connectors/ | 获取有关特定连接器的信息 |
| GET | /connectors/{name}/config | 获取特定连接器的配置参数 |
| PUT | /connectors/{name}/config | 更新特定连接器的配置参数 |
| GET | /connectors/{name}/status | 获取连接器的当前状态,包括连接器是否正在运行,失败,已暂停等,分配给哪个工作者,失败时的错误信息以及所有任务的状态 |
| GET | /connectors/{name}/tasks | 获取当前为连接器运行的任务列表 |
| GET | /connectors/{name}/tasks/{taskid}/status | 获取任务的当前状态,包括如果正在运行,失败,暂停等,分配给哪个工作人员,如果失败,则返回错误信息 |
| PUT | /connectors/{name}/pause | 暂停连接器及其任务,停止消息处理,直到连接器恢复 |
| PUT | /connectors/{name}/resume | 恢复暂停的连接器(或者,如果连接器未暂停,则不执行任何操作) |
| POST | /connectors/{name}/restart | 重新启动连接器(通常是因为失败) |
| POST | /connectors/{name}/tasks/{taskId}/restart | 重启个别任务(通常是因为失败) |
| DELETE | /connectors/ | 删除连接器,停止所有任务并删除其配置 |
- 加密算法参考
| 加密类型 | 推荐算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 对称加密 | AES-GCM, ChaCha20 | 高效,支持硬件加速 | 需要安全管理密钥 | 大数据量加密、文件加密、流加密 |
| 非对称加密 | RSA, ECDSA | 无需共享密钥,高安全性 | 速度慢,不适合大数据加密 | 密钥交换、数字签名 |
| 流加密 | ChaCha20 | 高效,低延迟 | 不适合文件加密 | 实时通信、视频流加密 |
| 哈希算法 | SHA-256, BLAKE3 | 不可逆,速度快 | 不能用于加解密 | 数据校验、数字签名 |
九、踩坑记录
- python虚拟环境pip报错,没有SSL模块。
解决:使用支持http的pip源进行安装
shell
pip3 install pymysql -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com- DATAX同步时间戳字段,Kafka中为数字,无法写入StarRocks的datetime类型字段中。
解决:在DATAX的同步字段映射中,使用DATA_FORMAT将其转换为字符串。
shell
"column": [
"id",
"name",
"DATE_FORMAT(timestamp_column, '%Y-%m-%d %H:%i:%s') AS timestamp_column"
],- AES-GCM在python端和Java端的实现问题。
解决:在python中加密会生成(nonce, chiphertext, tag)三元组信息,但是Java中解密会报错,在python中将 ciphertext和tag拼接起来,在Java中可以直接解密。
python
def encrypt_data(self, data):
"""使用 AES-GCM 加密数据"""
cipher = AES.new(self.aes_key, AES.MODE_GCM)
ciphertext, tag = cipher.encrypt_and_digest(data.encode('utf-8'))
return {
'nonce': cipher.nonce.hex(),
'ciphertext': ciphertext.hex() + tag.hex()
}
java
public String decrypt(String encryptedData) throws Exception {
JSONObject jsonMessage = JSONObject.parseObject(encryptedData);
// 解析密文、认证标签和 IV
byte[] ciphertext = hexStringToByteArray(jsonMessage.getString("ciphertext"));
byte[] nonce = hexStringToByteArray(jsonMessage.getString("nonce"));
return decryptData(ciphertext, nonce);
}- BigDecimal字段类型,starrocks-connector-for-kafka无法解析报错。
解决:在starrocks-connector-for-kafka中进行解密的时候,FastJSON配置将BigDecimal转换为Double类型。
java
public R apply(R record) {
if (record.value() == null) {
return record;
}
String value = (String) record.value();
try {
String newValue = aesEncryption.decrypt(value);
// 转换BigDecimal为Double
JSONObject jsonObject = JSON.parseObject(newValue, JSONReader.Feature.UseBigDecimalForDoubles);
return record.newRecord(record.topic(), record.kafkaPartition(), record.keySchema(), record.key(), null, jsonObject, record.timestamp());
} catch (Exception e) {
return record;
}
}- 自定义打包的starrocks-connector-for-kafka,kafka Connector无法加载。
解决:必须使用Java8进行打包,使用了Java21打包,导致无法加载。
- 使用最新版的python-mysql-replication读取binlog,解析不到表字段。
解决:不要使用最新版本,使用0.45.1版本,可参考:issue#612
- python3.6无法运行python-mysql-replication。
解决:python-mysql-replication不支持python3.6,至少需要3.7版本,本项目使用3.8.4版本
- python JSON转换不支持byte,日期格式。
解决:自定义python的JSON转换格式。
python
def convert_bytes_keys_to_str(data):
if isinstance(data, dict):
# 将字典中的 bytes 类型的键转换为 str
return {
(k.decode('utf-8') if isinstance(k, bytes) else k): KafkaBinlogStreamer.convert_bytes_keys_to_str(v)
for k, v in data.items()
}
elif isinstance(data, list):
# 对列表中的每个元素递归转换
return [KafkaBinlogStreamer.convert_bytes_keys_to_str(item) for item in data]
elif isinstance(data, bytes):
# 对 bytes 类型的值进行转换
return data.decode('utf-8')
elif isinstance(data, datetime):
# 将 datetime 类型转换为 ISO 格式字符串
return data.strftime('%Y-%m-%d %H:%M:%S')
else:
return data- 设置python-mysql-replication的only_events导致消费不到任何binlog。
解决:经过测试,最终舍弃该参数的配置。
- 脚本运行过程中占用内存过大,导致其被系统kill
解决:可以手动触发GC垃圾回收,主动回收释放内存
python
gc.collect()十、目前数据同步情况
| 指标KEY | 指标值 |
|---|---|
| RDS实例数 | 2 |
| 同步逻辑表数量 | 56 |
| 同步物理表数量 | 5274 |
| 数据延迟 | 1分钟以内 |