文章目录
-
- 一、概述
- 二、支持的字段类型与使用限制
- 三、通用脚本
- 四、常见问题
-
- 1、读取多分隔符的CSV文件,出现脏数据如何处理?
- 2、读取OSS文件是否有文件数限制?
- 3、写入OSS,文件名出现随机字符串如何去除?
- [4、读取OSS数据报错:AccessDenied The bucket you access does not belong to you.](#4、读取OSS数据报错:AccessDenied The bucket you access does not belong to you.)
- 5、写入报错,转换类型失败
- 6、转换bigint类型失败
- [7、csv、text 如何选择](#7、csv、text 如何选择)
一、概述
数据集成是一个稳定高效、弹性伸缩的数据同步平台,致力于提供在复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动及同步能力。
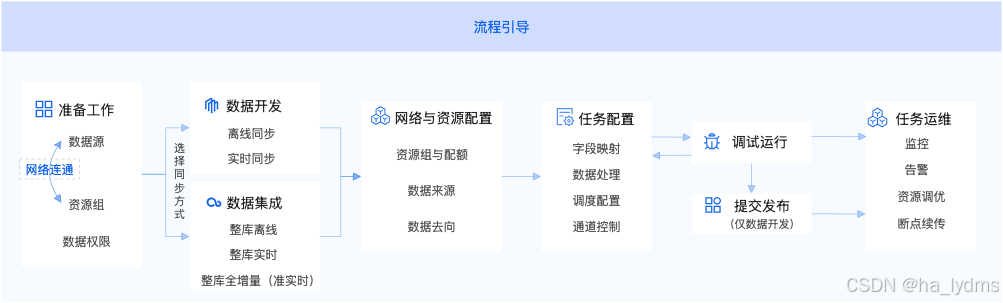
DataWorks数据集成提供的数据同步方式可从三个维度进行组合:同步时效、同步范围和数据策略。更详细的方案说明和推荐,请参见支持的数据源及同步方案。
- 同步时效:分为离线、实时。离线同步通过周期性调度任务实现小时或天级的数据迁移;实时同步则捕获源端变更数据(CDC),实现秒级延迟。
- 同步范围:分为单表、整库和分库分表。支持从单张表的精细化传输,到整个数据库或分库分表的批量迁移与合并。
- 数据策略:分为全量、增量和全增量。全量迁移所有历史数据,增量仅同步新增或变更的数据。全增量模式结合了两者,并根据数据源特性和时效性要求,提供离线、实时和准实时等多种实现方案。
| 方式 | 描述 |
|---|---|
| 离线 | 基于批量调度机制的数据传输方式,通过周期任务(小时/天级)将源数据全量 或增量迁移至目标端。 |
| 实时 | 通过流式处理引擎实时捕获源端变更数据(CDC日志),实现秒级延迟的数据同步。 |
| 单表 | 针对单张表的数据传输,支持精细化的字段映射与转换规则及控制配置。 |
| 整库 | 将源数据库实例内多张表结构及数据一次性迁移至目标端,支持自动建表。可单任务同步多张表,减少任务数量和资源消耗。 |
| 分库分表 | 将源端多个表结构一致的表写入目标端单表,自动识别分库分表路由规则,合并数据。 |
| 全量 | 一次性迁移源表所有历史数据,通常用于初始化数仓或数据归档。 |
| 增量 | 仅同步源端新增或变更的数据(如INSERT/UPDATE),数据集成支持离线和实时两种增量模式,分别通过设置数据过滤(增量条件)和读取源端CDC数据实现。 |
| 全增量 | 一次性全量同步历史数据后,自动衔接增量数据的写入。数据集成多种场景的全增量同步。根据数据来源和去向的数据源特性及时效性要求,按需选择使用。 离线场景 :一次性全量周期性增量。适用于对数据时效性要求不高,且源端表中有合适的增量字段(如modify_time)类型的数据源。 实时场景 :一次性全量实时增量。适用于对数据有比较高的时效性要求,且源端为消息队列或者支持开启CDC日志的数据库。 准实时场景:一次性全量入Base表,实时增量写入Log表,T+1将Log表的数据合并入Base表。准实时场景为实时场景的补充,适用于目标端不支持更新或者删除的表格式类型,如MaxCompute的常规类型表。 |
二、支持的字段类型与使用限制
1、离线读
OSS Reader实现了从OSS读取数据并转为数据集成协议的功能,OSS本身是无结构化数据存储。对于数据集成而言,OSS Reader支持的功能如下。
| 支持 | 不支持 |
|---|---|
• 支持TXT格式文件,且要求TXT中schema为一张二维表。 • 支持类CSV格式文件,自定义分隔符。 文本格式(TXT和CSV)支持gzip、bzip2和zip压缩。压缩时,一个压缩包不允许多文件打包压缩。 • 支持ORC、PARQUET格式。 • 支持多种类型数据读取(使用String表示),支持列裁剪、列常量。 • 支持递归读取、支持文件名过滤。 • 多个Object可以支持并发读取。 |
单个Object(File)不支持多线程并发读取。 单个Object在压缩情况下,从技术上无法支持多线程并发读取。 |
重要
准备OSS数据时,如果数据为CSV文件,则必须为标准格式的CSV文件。例如,如果列内容在半角引号(")内,需要替换成两个半角引号(""),否则会造成文件被错误分割。如文件存在多个分隔符,建议使用text类型。
OSS属于非结构化数据源,里面存放的都是文件类型数据,因此在使用同步时,需要先自行确认同步的字段结构是否符合预期。同理,非结构化数据源中数据结构发生变化时必须要在任务配置中重新确认字段结构,否则可能会造成同步数据错乱。2、离线写
OSS Writer实现了从数据同步协议转为OSS中的文本文件功能,OSS本身是无结构化数据存储,目前OSS Writer支持的功能如下。
| 支持 | 不支持 |
|---|---|
| 支持且仅支持写入文本类型(不支持BLOB,如视频和图片)的文件,并要求文本文件中的Schema为一张二维表。 支持类CSV格式文件,自定义分隔符。 支持ORC、PARQUET格式。 说明 脚本模式下支持SNAPPY压缩格式。支持多线程写入,每个线程写入不同的子文件。 文件支持滚动,当文件大于某个size值时,支持文件切换。 | 单个文件不能支持并发写入。 OSS本身不提供数据类型,OSS Writer均以STRING类型写入OSS对象。 如果OSS的Bucket存储类型为冷归档存储 ,则不支持写入。 单个Object(File)不超过100GB。 |
| 类型分类 | 数据集成column配置类型 |
|---|---|
| 整数类 | LONG |
| 字符串类 | STRING |
| 浮点类 | DOUBLE |
| 布尔类 | BOOLEAN |
| 日期时间类 | DATE |
三、通用脚本
1、离线读(Reader)
- Reader脚本Demo:通用示例
json
{
"type":"job",
"version":"2.0",//版本号。
"steps":[
{
"stepType":"oss",//插件名。
"parameter":{
"nullFormat":"",//定义可以表示为null的字符串。
"compress":"",//文本压缩类型。
"datasource":"",//数据源。
"column":[//字段。
{
"index":0,//列序号。
"type":"string"//数据类型。
},
{
"index":1,
"type":"long"
},
{
"index":2,
"type":"double"
},
{
"index":3,
"type":"boolean"
},
{
"format":"yyyy-MM-dd HH:mm:ss", //时间格式。
"index":4,
"type":"date"
}
],
"skipHeader":"",//类CSV格式文件可能存在表头为标题情况,需要跳过。
"encoding":"",//编码格式。
"fieldDelimiter":",",//字段分隔符。
"fileFormat": "",//文本类型。
"object":[]//object前缀。
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"stream",
"parameter":{},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":""//错误记录数。
},
"speed":{
"throttle":true,//当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,表示限流。
"concurrent":1 //作业并发数。
"mbps":"12",//限流,此处1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}- Reader脚本Demo:ORC或Parquet文件读取OSS
json
{
"stepType": "oss",
"parameter": {
"datasource": "",
"fileFormat": "orc",
"path": "/tests/case61/orc__691b6815_9260_4037_9899_****",
"column": [
{
"index": 0,
"type": "long"
},
{
"index": "1",
"type": "string"
},
{
"index": "2",
"type": "string"
}
]
}
}- 以Parquet文件格式读取OSS
json
{
"type":"job",
"version":"2.0",
"steps":[
{
"stepType":"oss",
"parameter":{
"nullFormat":"",
"compress":"",
"fileFormat":"parquet",
"path":"/*",
"parquetSchema":"message m { optional BINARY registration_dttm (UTF8); optional Int64 id; optional BINARY first_name (UTF8); optional BINARY last_name (UTF8); optional BINARY email (UTF8); optional BINARY gender (UTF8); optional BINARY ip_address (UTF8); optional BINARY cc (UTF8); optional BINARY country (UTF8); optional BINARY birthdate (UTF8); optional DOUBLE salary; optional BINARY title (UTF8); optional BINARY comments (UTF8); }",
"column":[
{
"index":"0",
"type":"string"
},
{
"index":"1",
"type":"long"
},
{
"index":"2",
"type":"string"
},
{
"index":"3",
"type":"string"
},
{
"index":"4",
"type":"string"
},
{
"index":"5",
"type":"string"
},
{
"index":"6",
"type":"string"
},
{
"index":"7",
"type":"string"
},
{
"index":"8",
"type":"string"
},
{
"index":"9",
"type":"string"
},
{
"index":"10",
"type":"double"
},
{
"index":"11",
"type":"string"
},
{
"index":"12",
"type":"string"
}
],
"skipHeader":"false",
"encoding":"UTF-8",
"fieldDelimiter":",",
"fieldDelimiterOrigin":",",
"datasource":"wpw_demotest_oss",
"envType":0,
"object":[
"wpw_demo/userdata1.parquet"
]
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"odps",
"parameter":{
"partition":"dt=${bizdate}",
"truncate":true,
"datasource":"0_odps_wpw_demotest",
"envType":0,
"column":[
"id"
],
"emptyAsNull":false,
"table":"wpw_0827"
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":""
},
"locale":"zh_CN",
"speed":{
"throttle":false,
"concurrent":2
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}2、离线写(Writer)
- Writer脚本Demo:通用示例
json
{
"type":"job",
"version":"2.0",
"steps":[
{
"stepType":"stream",
"parameter":{},
"name":"Reader",
"category":"reader"
},
{
"stepType":"oss",//插件名。
"parameter":{
"nullFormat":"",//数据同步系统提供nullFormat,定义哪些字符串可以表示为null。
"dateFormat":"",//日期格式。
"datasource":"",//数据源。
"writeMode":"",//写入模式。
"writeSingleObject":"false", //表示是否将同步数据写入单个oss文件。
"encoding":"",//编码格式。
"fieldDelimiter":","//字段分隔符。
"fileFormat":"",//文本类型。
"object":""//Object前缀。
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//错误记录数。
},
"speed":{
"throttle":true,//当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,表示限流。
"concurrent":1, //作业并发数。
"mbps":"12"//限流,此处1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}- 以ORC文件格式写入OSS
json
{
"stepType": "oss",
"parameter": {
"datasource": "",
"fileFormat": "orc",
"path": "/tests/case61",
"fileName": "orc",
"writeMode": "append",
"column": [
{
"name": "col1",
"type": "BIGINT"
},
{
"name": "col2",
"type": "DOUBLE"
},
{
"name": "col3",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "NONE",
"encoding": "UTF-8"
}
}- 以Parquet文件格式写入OSS
json
{
"stepType": "oss",
"parameter": {
"datasource": "",
"fileFormat": "parquet",
"path": "/tests/case61",
"fileName": "test",
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "SNAPPY",
"encoding": "UTF-8",
"parquetSchema": "message test { required int64 int64_col;\n required binary str_col (UTF8);\nrequired group params (MAP) {\nrepeated group key_value {\nrequired binary key (UTF8);\nrequired binary value (UTF8);\n}\n}\nrequired group params_arr (LIST) {\nrepeated group list {\nrequired binary element (UTF8);\n}\n}\nrequired group params_struct {\nrequired int64 id;\n required binary name (UTF8);\n }\nrequired group params_arr_complex (LIST) {\nrepeated group list {\nrequired group element {\n required int64 id;\n required binary name (UTF8);\n}\n}\n}\nrequired group params_complex (MAP) {\nrepeated group key_value {\nrequired binary key (UTF8);\nrequired group value {\nrequired int64 id;\n required binary name (UTF8);\n}\n}\n}\nrequired group params_struct_complex {\nrequired int64 id;\n required group detail {\nrequired int64 id;\n required binary name (UTF8);\n}\n}\n}",
"dataxParquetMode": "fields"
}
}四、常见问题
1、读取多分隔符的CSV文件,出现脏数据如何处理?
-
问题现象:
在配置离线同步任务从OSS、FTP等文件存储读取数据时,如果文件是CSV格式,并且使用了多个字符作为列分隔符(例如
|,、##、;;等),任务可能会因"脏数据"错误而失败。在任务的运行日志中,您会看到类似的IndexOutOfBoundsException(数组越界)错误,并产生脏数据。 -
原因分析:
DataWorks内置的
csv读取器 ("fileFormat": "csv") 在处理由多个字符组成的分隔符时存在限制,导致对数据行的列拆分不准确。 -
解决方案:
- 向导模式:将文本类型切换为text,并明确指定您的多字符分隔符。
- 脚本模式:将
"fileFormat": "csv"调整为"fileFormat": "text",并正确设置分隔符:"fieldDelimiter":"<多分隔符>", "fieldDelimiterOrigin":"<多分隔符>"。
2、读取OSS文件是否有文件数限制?
离线同步本身不限制OSS reader插件读取文件的个数,对文件读取的限制主要来自任务本身占用的资源CU,若一次性读取的文件太多,容易导致内存溢出。因此不建议将object参数配置为:*,防止出现1OutOfMemoryError: Java heap space1 报错。
3、写入OSS,文件名出现随机字符串如何去除?
OSS Writer写入的文件名,OSS使用文件名模拟目录的实现。OSS对于Object的名称有以下限制:使用"object": "datax",写入的Object以datax开头,后缀添加随机字符串。文件数由实际切分的任务数决定。
如果不需要后缀随机UUID,建议配置"writeSingleObject" : "true",详情请参见OSS数据源文档的writeSingleObject说明。
4、读取OSS数据报错:AccessDenied The bucket you access does not belong to you.
-
产生原因:
数据源配置的AccessKey账号没有该bucket的权限。
-
解决方案:
为OSS数据源配置的AccessKey账户授予该bucket读权限。
5、写入报错,转换类型失败
确认表结构的作用是确保源表与目标表字段结构匹配,避免因类型不一致导致写入失败。DataWorks同步OSS数据到MaxCompute时,会先在Reader端按配置解析OSS文件(如CSV/text),再将数据转换为目标表对应字段类型后写入MaxCompute。
6、转换bigint类型失败
- 若源数据数值超出BIGINT范围(-2^63 ~ 2^63-1),会导致同步失败。
- 建议先在OSS Reader中将字段类型设为STRING,再通过数据过滤或转换处理超限值,或在MaxCompute侧使用DECIMAL类型接收
7、csv、text 如何选择
在DataWorks OSS数据源配置中,CSV和text类型的主要区别在于数据解析方式:
- CSV类型要求标准格式(如引号内内容需转义),适合规范的表格数据;
- 而text类型支持自定义分隔符(如您使用的"||"),更适合多分隔符或非标准格式文件。当文件存在多个分隔符时,官方建议使用text类型以避免脏数据问题。