导读
淘宝闪购从25年春天的横空出世,到秋天"第一杯奶茶"的火爆,再到今天成为广大消费者即时生活服务的日常,业务团队取得了巨大的突破,背后自然少不了技术团队的支撑。经过一年多的探索实践,闪购大数据团队沉淀了以Paimon为底座,流、批、分析多引擎协作的Lakehouse架构。本文介绍阿里云 Serverless Spark + Paimon在淘宝闪购大数据湖仓场景的应用。
一、业务介绍
淘宝闪购是阿里巴巴旗下的即时零售业务,也是目前电商领域非常热门的"风口"之一。淘宝闪购零售业务是淘宝闪购重要的生态体系之一,业务覆盖了餐饮外商品的外卖业务,包括超市便利、看病买药、水果买菜、鲜花潮玩、酒水饮料、食品百货、手机数码等众多品类和消费场景。


淘宝闪购零售数据团队是淘宝闪购DIC(数据智能中心)下负责零售业务的数据团队。在2025年5月闪购业务快速发展的背景下,零售数据团队也面临着业务快速增长带来的数据体量和业务诉求对实时数据更强烈的压力,零售业务特殊场景,基础商品量级大,观测维度多,在大盘观测、多端流量调配及权益补充等场景下业务对多维分析和实验效果回收有更高时效的要求。在淘宝闪购数据团队长时间探索ALake积累的湖仓一体背景下,闪购初期零售数据的整体实时架构便融合了湖仓一体架构,快速支撑了业务在闪购上线初期快速看数和策略调整的诉求,经过多轮的技术探索,逐步形成了Flink+Paimon+Spark+StarRocks的技术架构,Spark在其中扮演了非常关键的角色,在应用端使用Spark在营销特征生产、零售流量多维分析、AB实验效果回收等场景上均得到了效率和稳定性的提升。
本文将主要分享零售数据团队在实时湖仓探索中在Spark应用落地的一些实践总结。
二、淘宝闪购零售数据实时架构演进之路
2.1 烟囱式开发的实时链路
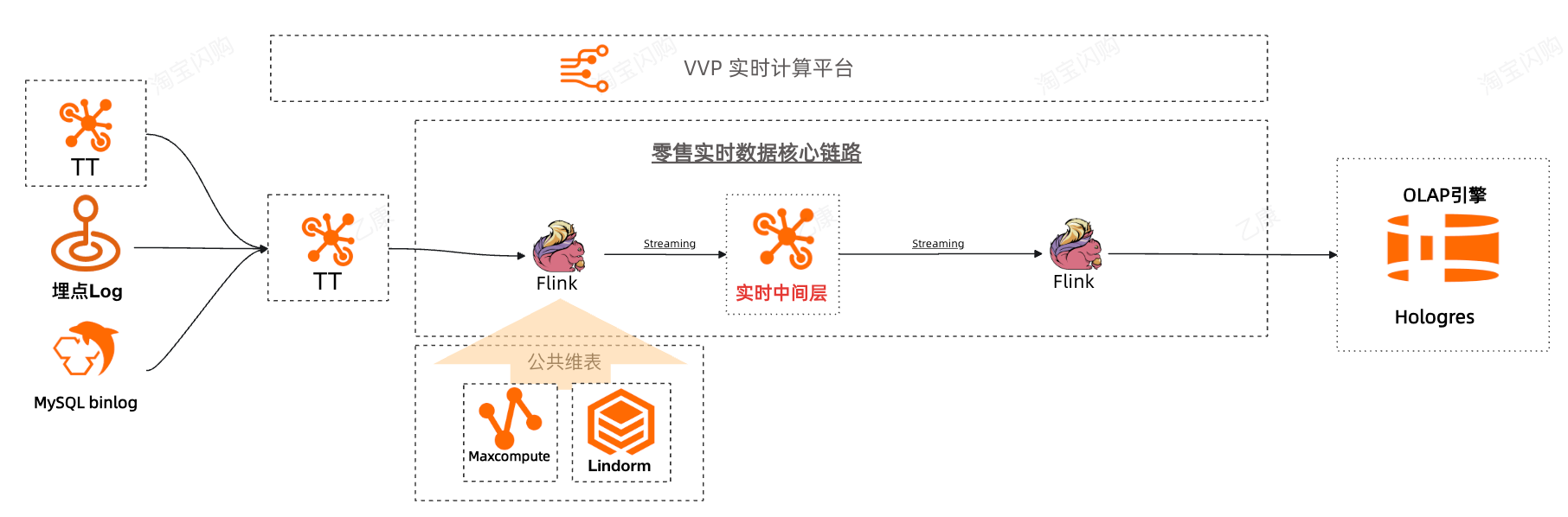
主要应用场景:零售商家数据看板、实时分析。在此阶段遇到的问题主要是烟囱式开发,开发和维护成本较高。我们在实时中间层的沉淀上基本满足诉求,但是在应对业务多维分析需求时,原先架构的开发成本和数据核对的成本比较高,无法支撑快速迭代的业务诉求。
2.2 引入湖仓Paimon + StarRocks,实时分析提效初见成效
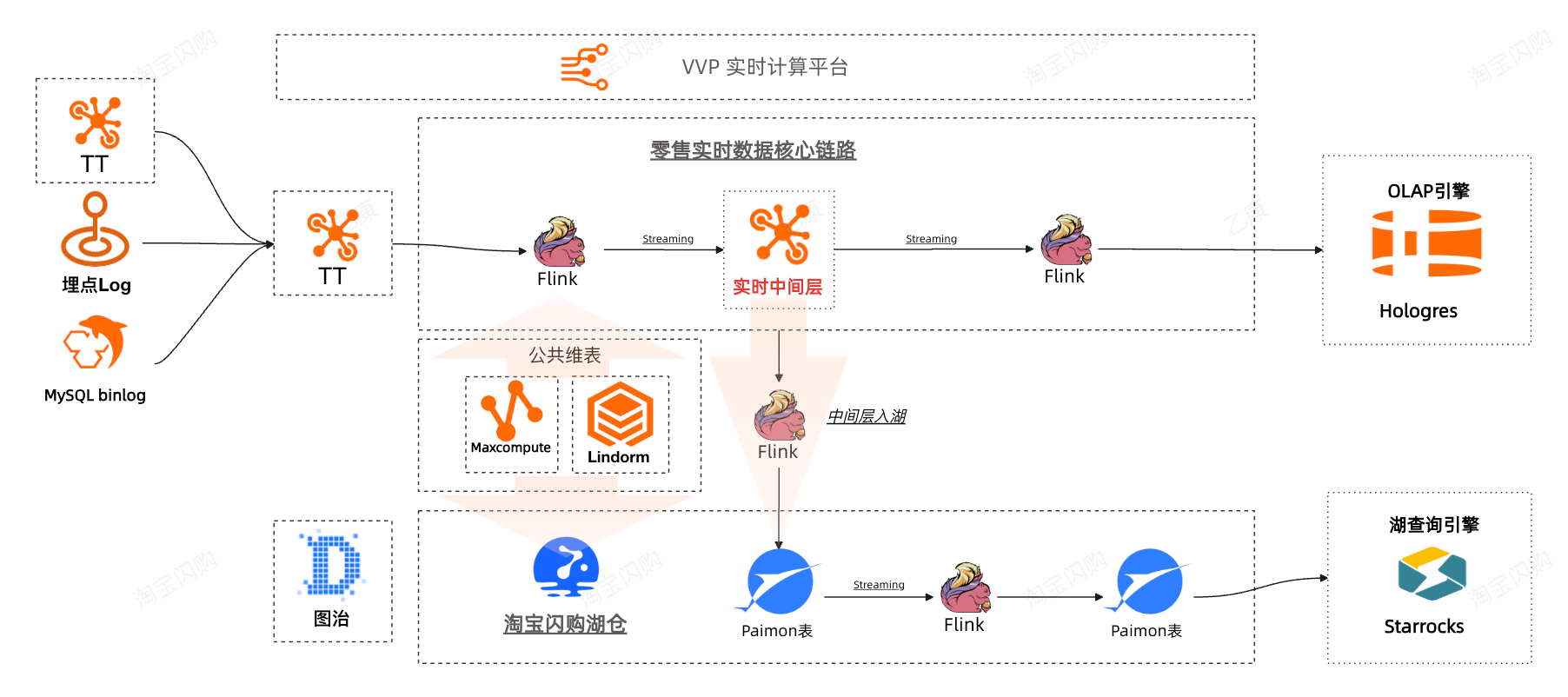
在引入了湖仓之后,实时主要技术架构升级到TT+Flink+Paimon+StarRocks,主要应用场景:商家端应用、实时分析。
在湖仓一体的背景下,闪购初期我们选择了StarRocks查询引擎搭建FBI看板,快速响应了业务快速迭代的看数需求。在此场景下遇到的问题如下:
-
维表引入效率低
由于湖仓在零售数据团队的引入处于初期,比较多的底层依赖公共层表都在ODPS中,在FBI引入StarRocks直查分析的情况下没有办法直接关联,所以StarRocks的物化没有办法实现比较多的维度聚合场景。
-
需求迭代快,时效容忍度高
闪购上线初期,市场竞争激烈,业务需求的变化也快,对数据产出的时间要求也高,但是对于实时性的要求不是很高,所以对开发效率提了比较大的挑战。
-
流量数据量级大,分析维度多,Cube计算数据膨胀大,数据产出延迟大
与餐饮外卖场景不同,零售场景下业务需要关注到商家行业、城市、品牌、业态等多维度的流量和交易转化分析,应用场景主要是在快速增长的流量下做大盘观测、分行业运营、流量策略调整、权益补充等场景上,初期的技术方案是Flink+Paimon+StarRocks,但是在基础流量量级上,Cube膨胀倍数达到万倍,在对比之下,StarRocks更适合在中等规模的数据聚合,在大Cube的规模下StarRocks的多维表物化视图无法稳定产出,导致数据时效性受到极大的影响,零售流量分析在淘宝闪购上线初期StarRocks物化视图的成功率约40%~60%,在高峰期的数据延迟能达到3h以上。
2.3 引入批处理引擎Spark,实现流批一体,提升稳定性和效率,应用场景更丰富
为了解决以上的一些难题,我们联合了阿里云EMR Serverless Spark团队和爱橙ALake Spark团队合作,引入Spark引擎通过批处理实现准实时物理物化,补充当前在湖仓的技术栈上的缺口,经过近半年的应用实践,达成了在数据稳定产出上的目标,同时在产出时效性得到了大大提升。
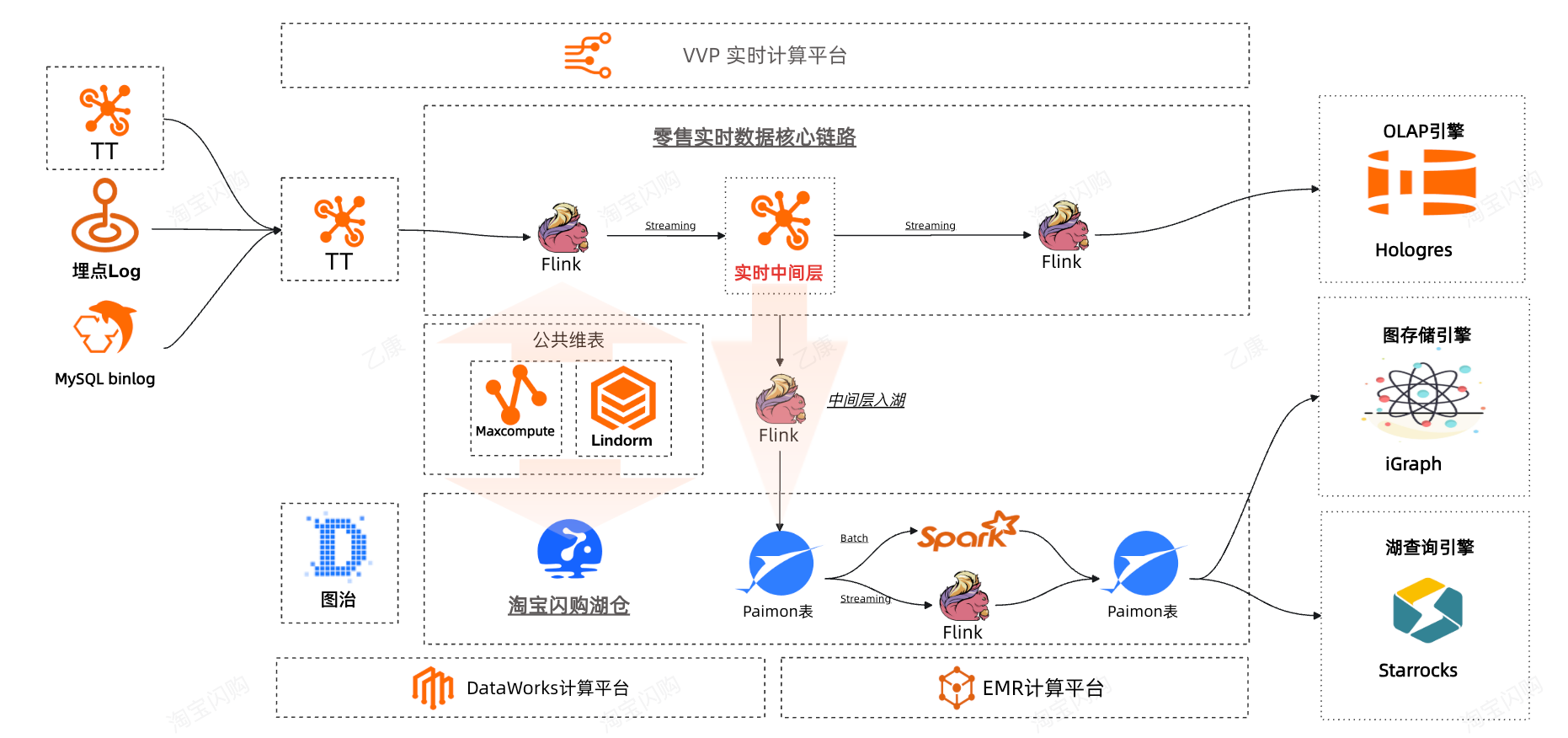
闪购的批处理场景选择了ALake Spark,主要考虑因素是ALake Spark跟Paimon的集成非常成熟。与其他具有私有格式的引擎不同,DLF Paimon表是ALake Spark的"内表",支持Paimon的全部特性,包括读写全类型表(Append表,PK表,Object表,Format表),支持ACID、Schema Evolution、Time Travel、Call Procedure等湖表特性,支持列裁剪、谓词下推、基于统计信息的Plan调整、z-order等查询优化,以及支持DV和Variant类型等高级特性。此外,ALake通过跟阿里云EMR团队合作,引入Fusion和Celeborn等重要组件,大幅提升Spark的性能、稳定性和弹性,成为湖上批处理的首选引擎。主要概况以下几点:
(1)数据湖的无缝集成。ALake Spark跟Paimon的集成非常成熟,尤其是对DV表的支持更佳,开启 Paimon 表的 Deletion-Vectors 属性后,Spark的读写性能能提升约3-5倍;同时支持ACID、Schema Evolution、Time Travel、Call Procedure等湖表特性。
(2)Variant高效JSON数据存储和读写支持,让复杂文本的读取和计算效率得到大大的提升。在测试场景中,读取性能在关闭和开启Shredding配置下分别提升1.7倍和12倍。
(3)稳定性强,解释性高。ALake通过跟阿里云EMR团队合作,引入Fusion和Celeborn等重要组件,大幅提升Spark的性能、稳定性,这也是在闪购初期我们对实时/批处理引擎比较大的考量。并且可解释性强,数据核验的效率非常高,有助于提升效率。
(4)调优空间大,效率高。支持列裁剪、谓词下推、基于统计信息的Plan调整、z-order等查询优化方案,我们在Spark测试过程中发现对任务的调优可以获得指数级的效率提升收益,对数据的产出时效有极大的提升,最大能提升90%以上的任务运行效率。
(5)开发和运维的成本低。技术栈比较成熟,无需手动管理和复杂的基础设施搭建,即可快速启动任务开发,大大减少在闪购势如破竹的背景下快速迭代的学习成本,真正实现了流批一体,提升了整个团队的开发效率。
最终Spark在淘宝闪购零售数据多个场景中应用:AB实验回收分析、实时流量分析、营销批信号和特征生产等。整个开发成本平均提升30%~40%的效率,数据产出稳定性提升90%以上;同时,通过Spark调优带来的效率提升最高达到了92%。
三、Spark + Paimon重要特性详解
3.1 Delete Vector
在Delete Vector(DV)之前,Paimon支持两种数据合并方式:Copy on Write(COW)和Merge on Read(MOR)。COW模式在更新时需重写整个数据文件,导致写放大和高延迟,难以支持高频流式写入;而MOR虽写入高效,但读取时需做文件合并,带来显著的读开销,且对计算引擎集成不友好。DV引入了新的机制:写入时记录被删除的数据,读取时过滤。DV既保留了MOR写入高效性,又减少了COW的合并开销,从而更好地支持流批一体场景。下面以PK介绍DV的整体设计。
在delete和update时,生成delete file并记录被删除record:
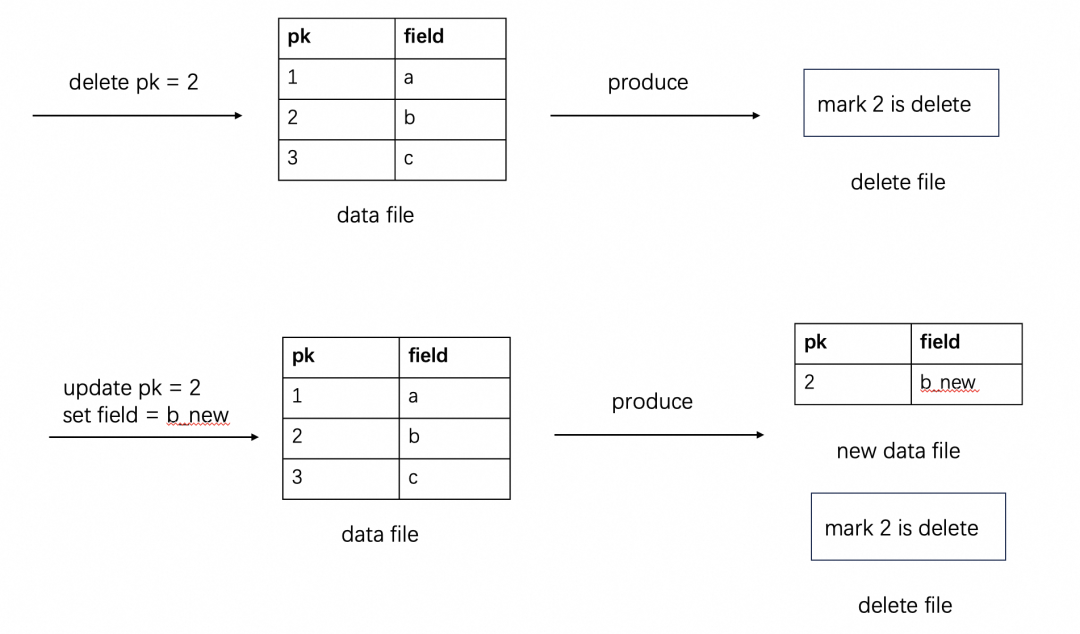
DV file具体编码如下,逻辑上记录每个文件被删除的record的rowid,物理上以bitmap存储在index file meta和index file中,读表时过滤掉delete file记录的record。
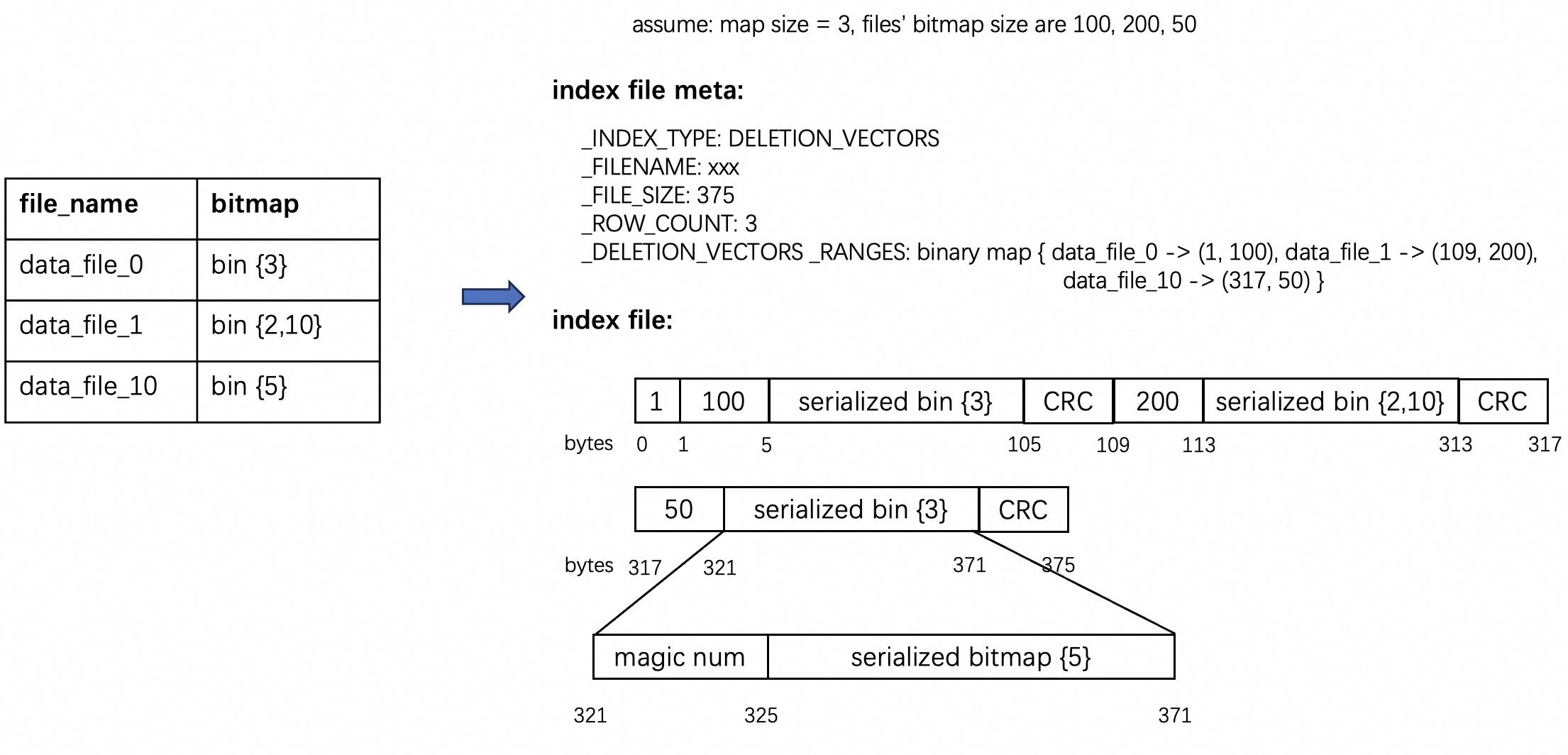
对比5亿条数据(20%重复率)的主键表入湖后查询,开启DV比关闭DV性能提升3-5倍。
3.2 Variant
Json数据在闪购业务中使用非常广泛,但Json解析的性能经常成为瓶颈。针对这个问题,ALake Spark结合Paimon推出了Variant类型,通过牺牲一次写性能,大大加速高频的读性能。
Variant的整体思路是写时解析Json的Schema并以自描述可索引的方式存储Schema和数据,只需在写入时做一次完整解析和编码,换取读取时媲美结构化数据的性能。Variant的编码格式如下:
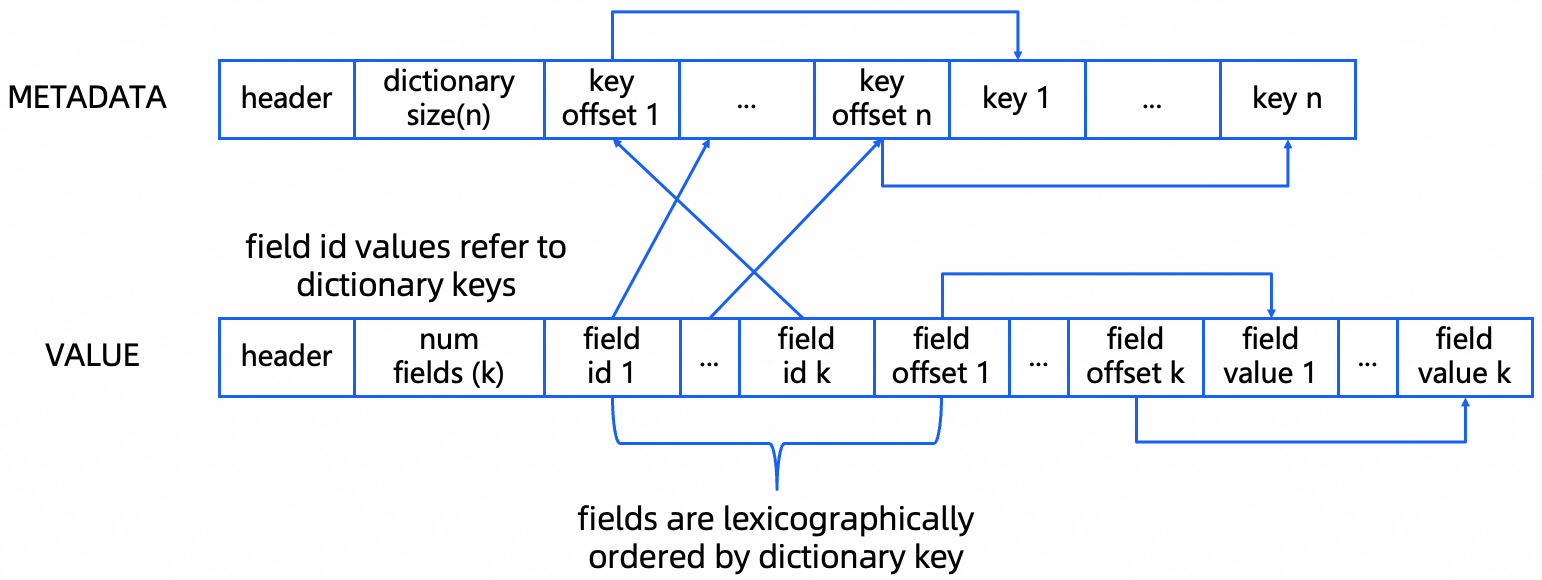
Variant的Metadata字段存储的是去重之后的key,Value的filed id部分存储的是按照key字典排序之后的id,每个id指向其对应的key,从而支持快速二分查找所需要的key。Value的field offset和field value部分存储value的偏移和具体的值。针对嵌套结构,field value递归存储上述结构(Metadata + Value字段)。
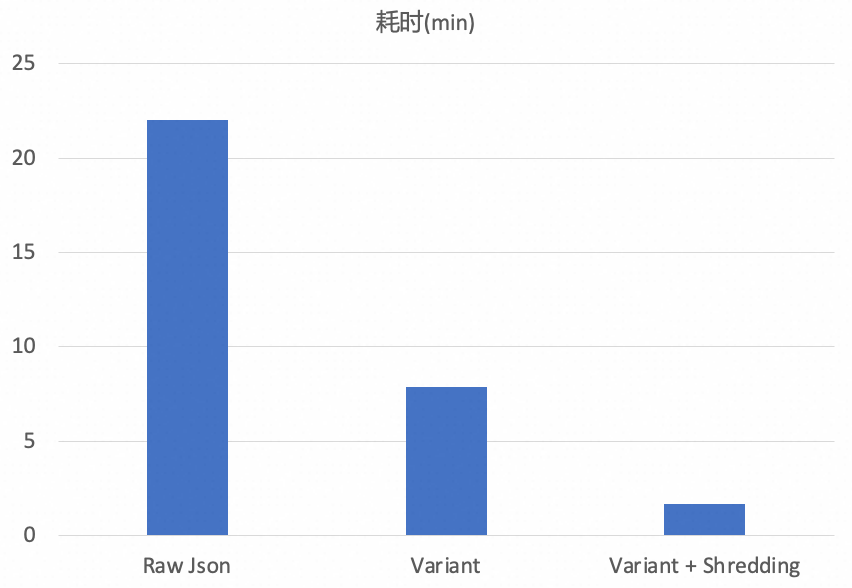
针对结构相对固定的Variant数据,ALake Spark + Paimon还支持了Shredding,即采样出固定的字段,并以struct的方式存储,从而进一步加速解析过程。
在测试场景中,读取性能在关闭和开启Shredding配置下分别提升1.7倍和12倍:
3.3 Fusion + Celeborn
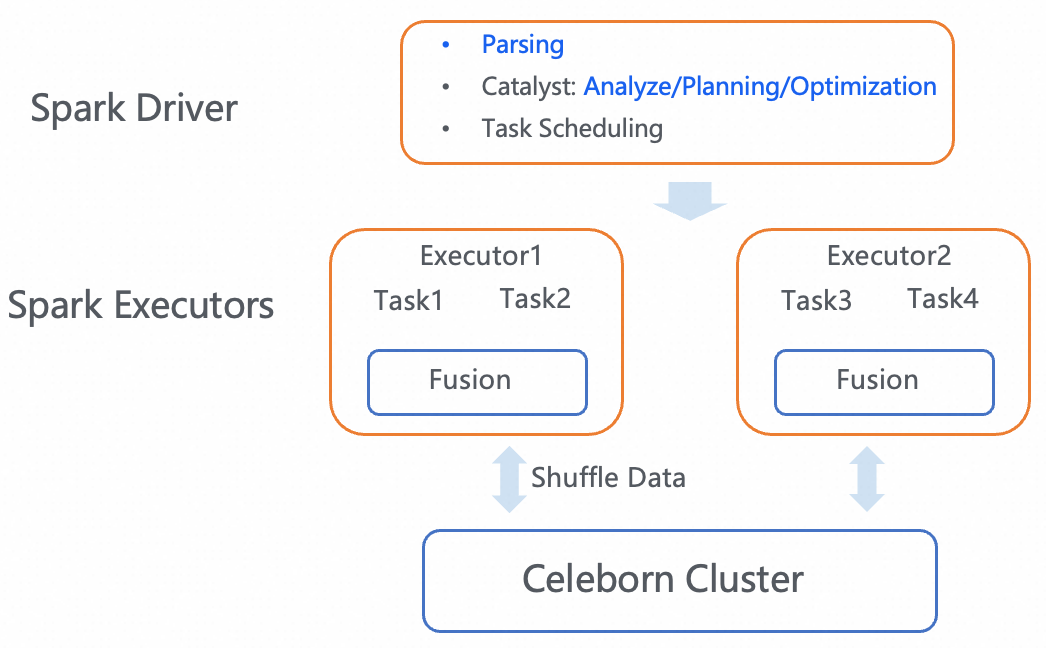
Fusion是ALake Spark跟阿里云EMR Serverless Spark团队合作引入的向量化SQL执行引擎,使用C++ 向量化技术重写了Spark SQL Engine。除了语言层面,Fusion的主要特点是把原有的行式计算转变成列式计算,从而更易于SIMD加速,更加CPU Cache友好,结合异步&合并IO等优化,在CPU密集型作业上相比Java Engine有数倍性能提升。
Apache Celeborn是阿里云EMR Serverless Spark团队捐赠给ASF的顶级项目,目前已经是Spark Remote Shuffle Service的事实标准。Celeborn主要解决的问题是大Shuffle作业的稳定性、弹性和性能问题,主要技术手段是远程存储和Shuffle数据重组,彻底解决重Shuffle作业经常出现的FetchFailure异常,生产作业极端情况有数量级的性能提升。
Fusion + Celeborn 的架构如下:
4、Spark + Paimon在闪购的应用
4.1 流批一体,营销实时特征生产提效
随着闪购市场的竞争日益激烈,对用户的精细化运营变得越来越关键,同时也对营销算法提出了新的挑战,以前的离线特征已经无法满足业务策略快速迭代的诉求,算法团队也对特征的时效性提出了更高的要求。
之前的实时特征生产流程如下所示,在算法侧离线特征重要性评估之后,向数据团队提特征生产需求,在数据和算法开始梳理和对齐口径开始,针对某一批实时特征的开发和上线,结合数据验证,理论上需要2个星期以上的时间,而且还不包含全链路的质量保障工作,如果遇到比较极端的序列型特征,Flink SQL还没有办法支持,需采用DataStreaming的方案实现,开发时长甚至会达到1个月以上,主要的时间是花在了特征开发阶段。
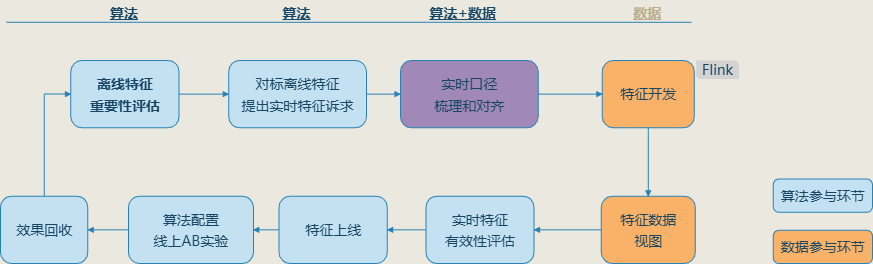
在接入湖仓之后,我们采用了新的实时特征生产模式,新的生产模式核心思想是逐步提升特征的时效性,优先生产分钟级时效的特征,根据分钟级特征的重要性表现,决定是否转向实时生产的模式。
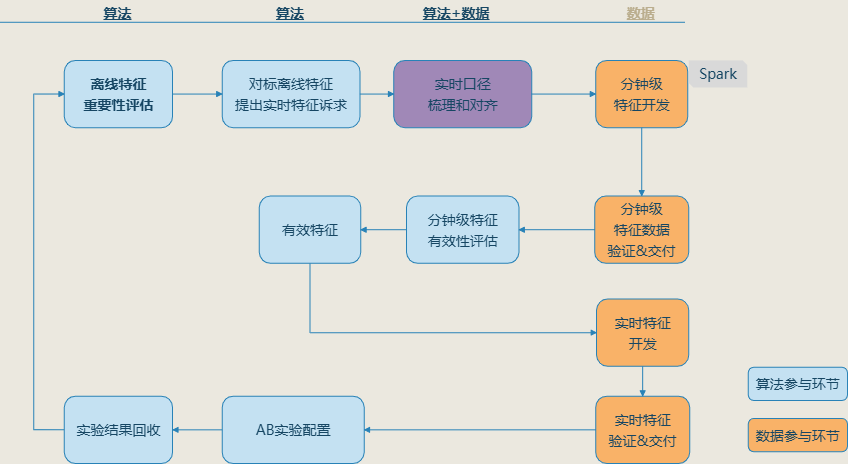
新的实时特征生产流程如下所示:
此生产模式下的数据链路如下:
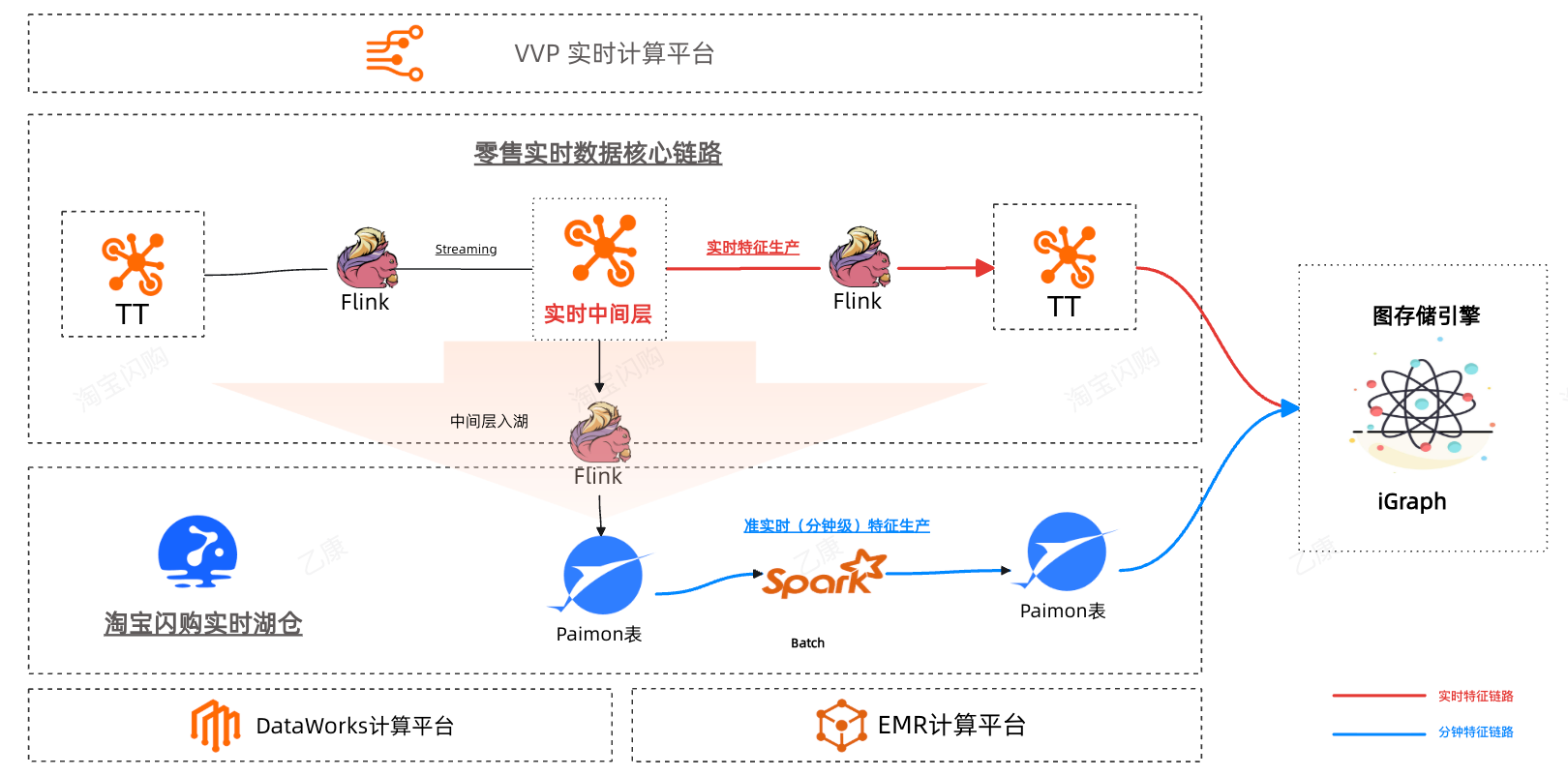
零售数据团队营销特征生产的提效成果:Spark生产单个特征的效率至少是原先的 3倍以上,实时特征有效比例20%,在整个特征生产到算法实验链路上,至少能提升40%的效率,同时在资源成本上也有约20%的节省。
4.2 流量&营销多维分析
如前文所述,在零售EAT&夏战的大范围作战中,对于时效性的要求越来越高,高时效的数据应用在大盘观测、流量调配、策略调整、权益补充等多个场景中。因此,业务侧与管理层对于数据的实时性有更高的期待和更多的要求,原有的技术架构与人力无法匹配快速迭代的需求。从维度上看,零售场景下业务需要关注到商家行业、城市、品牌、业态、类目等多维度的流量和交易转化分析,如果再配合营销超算同学做算法AB实验的回收,数据需要再加入实验信息、端、用户分层、笔单分层、券维度等等实验所需维度,在实验效果回收时需要cube做数据多维分析数据量膨胀近万倍,传统生产逻辑已无法满足算法侧及时回收数据的强诉求。
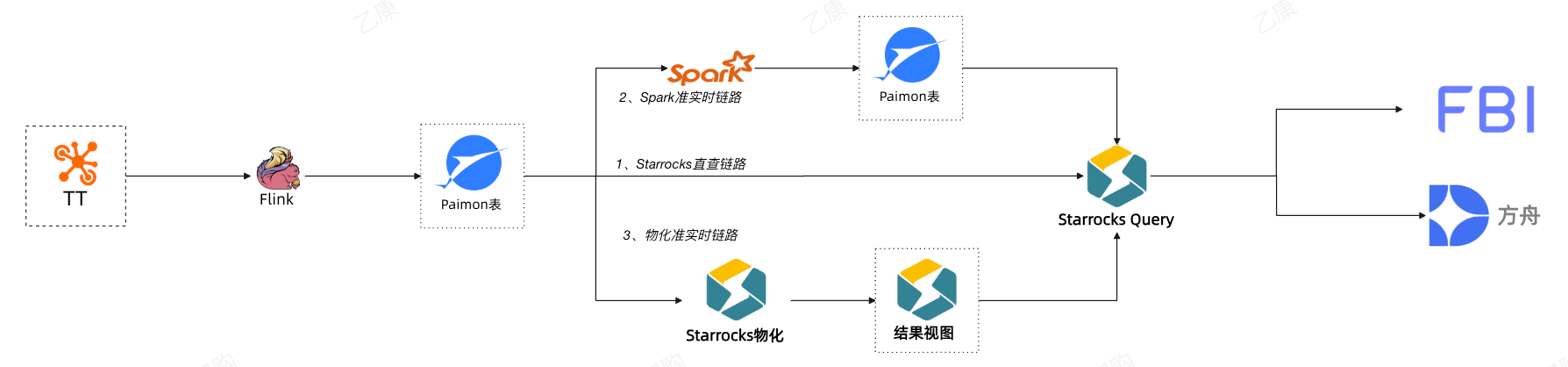
在实时&准实时分析上形成3套分析范式:
| 序号 | 分析框架 | 场景/示例 |
|---|---|---|
| 1 | Paimondetail+StarRocks | 中小数据规模实时分析,例如零售实时营销 |
| 2 | Paimon+StarRocks MVsum+StarRocks | 中等数据规模实时分析,例如零售多维实时AB实验分析 |
| 3 | Paimon+Sparksum+StarRocks | 大批量数据准实时分析,例如零售多维实时流量分析 |
数据湖技术的落地带来了新的可能。我们通过Spark+Paimon的结合的方式并进行合理的执行计划优化,使回收数据的时效性达到半小时/10分钟级,大大提高算法实验回收效率,为营销和搜推赋能。
4.3 Spark治理和调优最佳实践应用
Spark在应用上调优和治理的空间是比较大的,尤其是针对大量级数据的聚合查询。以下是我们在实践过程中总结的调优案例,对我们运算效率和资源利用均有特别大的提升。总的来说,Spark的核心调优原则总结为2条:
(1)问题导向
-
先通过 SparkUI 定位瓶颈(Stage 执行时间、Task 分布、数据输入量),再针对性优化。
-
关键指标:Stage 执行时长、Task 耗时方差、Shuffle 数据量、内存溢出(OOM)日志。
(2)分级优化
-
优先级:参数调优 → 执行计划优化 → 存储层优化(湖表结构调整)。
-
4.3.1 数据倾斜治理(最高频问题)
(1)诊断方法
-
SparkUI 观察:
-
某 Stage 执行时间远超其他 Stage(如占总耗时 80%+)。
-
同 Stage 下 Task 耗时方差极大(如 90% Task 耗时 <1min,个别 Task >30min)。
-
Shuffle Read/Write 数据量异常(如某 Task 读取数据量是平均值的 100 倍+)。
-
-
定位倾斜算子:
-
通过
SQL / DataFrame查看 Stage 对应的 SQL 逻辑(如 JOIN、GROUP BY)。 -
检查输入数据量差异(如大表 7.5 亿 vs 小表 400 万)。
-
(2)治理方案
| 场景 | 解决方案 | 关键参数/操作 | 效果 |
|---|---|---|---|
| 通用倾斜 | 开启自适应倾斜处理 | spark.sql.adaptive.skewJoin.enabled=true spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes=256MB |
拆分倾斜分区,避免单 Task 过载 |
| 大表 JOIN 小表 | 强制 MapJoin(避免 Shuffle) | SQL 中添加 /*+ MAPJOIN(small_table) */ Hint |
消除 Shuffle,提速 85%+ |
| 倾斜 Key 预处理 | 对倾斜 Key 单独处理(如加随机前缀) | CONCAT(key, '_', FLOOR(RAND() * 10)) |
|
| 分桶不合理 | 调整Paimon表分桶数 | 分桶设置黄金公式 : 推荐分桶数 = 分区数据量 (GB) / 2 示例:单分区数据 864GB → 分桶数设为 432 |
解决底层数据分布不均 |
4.3.2 执行计划优化(CUBE/维度展开场景)
(1)问题特征
-
维度组合爆炸(如 4 维度展开 200+ 倍)。
-
单 Stage 内完成数据读取 + 维度计算,Task 并发度不足。
(2)优化方案
| 步骤 | 操作 | 原理 |
|---|---|---|
| 1. 增加并发度 | 在维度展开前插入hint repartition(N) |
将计算拆分到更多 Task,避免单 Task 负载过重 |
| 2. 确定 N 值 | 按数据量级尝试:N = 数据量 × (20/50/100) 示例:900 万数据 → 试 400 |
通过 SparkUI 观察 Task 均衡性调整 N |
| 3. 验证效果 | 检查新 Stage 是否存在倾斜 + 总耗时下降 | 目标:Task 耗时标准差 < 20% |
优化效果 :CUBE 作业从 90min优化至8min,性能提升 92.7%。
4.3.3 湖表存储层优化(终极手段)
(1)适用场景
-
参数调优后性能仍不达标。
-
分区数据量与分桶数严重不匹配(如 1TB 数据仅 10 个桶)。
(2)优化步骤

-
分桶数量调整
-
计算公式:
分桶数 = 分区数据量 (GB) / 2
-
-
分桶键选择
-
主键表:默认使用主键(无需显式设置)。
-
非主键表:选择高频 JOIN 或 GROUP BY 字段(如
user_id)。
-
-
关键配置示例
sql
TBLPROPERTIES (
'bucket' = 'xxx', -- 按数据量计算
'primary-key' = 'ds,user_id,order_id', -- 主键表必设
'deletion-vectors.enabled' = 'true' -- 启用删除向量加速查询
)4.3.4 总结调优流程图(实战指南)
Stage 耗时不均
维度计算慢
是
否
Task 数过少
分桶不合理
达标
未达标
任务执行慢
SparkUI诊断
检查数据倾斜
检查并发度
启用 skewJoin + MapJoin
检查分桶设置
增加 repartition
重建Paimon表
验证效果
完成
5、总结与未来展望
在淘宝闪购上线以来的这一段时间内,业务不断在创造一个又一个峰值,用户活跃度和订单量级都屡创新高,在这背后,数据团队始终以"稳定、高效、智能"为准则,在湖仓一体架构的基础上,深度融合流计算与批处理能力,构建起一套高弹性、低延迟、强一致的数据处理体系,作为核心计算引擎,阿里云 EMR Serverless Spark 在湖仓一体架构中扮演了关键角色,在湖仓流计算和批计算的共同加持下抗住了业务的压力,同时越来越多的业务场景应用快速落地。
未来,我们也会继续与阿里云EMR Serverless Spark团队和爱橙ALake Spark团队密切合作,在闪购业务上探索更多的使用场景,发挥Spark更大的价值。我们坚信,在AI与即时零售深度融合的时代浪潮下,Spark不仅是计算引擎,更是连接数据、智能与商业价值的关键桥梁。而淘宝闪购正成为这一桥梁上最活跃、最具创新力的先行者之一,欢迎大家到淘宝闪购下单。
鸣谢
感谢我们淘宝闪购-DIC零售数据团队慧航、圣俞、空竹、晚识、约理、鸢鸿、舫舟、量衡、清临等各位同学在湖仓应用的支持;
感谢淘宝闪购-DIC霄明、哲昆在零售数据团队在湖仓探索和Spark应用上的支持和帮助;
感谢爱橙湖仓团队无谓、其修、夷羿的大力支持;
感谢阿里云EMR Serverless Spark团队一锤、寻径、履霜、羊川、昕羽、羲羽、郑涛等同学的支持。