摘要
预测玩家何时会离开游戏为延长玩家生命周期和增加收入贡献创造了独特的机会。玩家可以被激励留下来,战略性地与公司组合中的其他游戏交叉链接,或者作为最后的手段,通过游戏内广告传递给其他公司。本文重点预测休闲社交游戏中高价值玩家的流失,并尝试评估可以从预测流失模型中获得的业务影响。我们比较了四种常见分类算法在两个拥有数百万玩家的休闲社交游戏中的预测性能。此外,我们实现了一个隐马尔可夫模型,以明确处理时间动态。我们发现神经网络在曲线下面积(AUC)方面实现了最佳预测性能。此外,为了评估流失预测的业务价值,我们在其中一款游戏上设计并实施了A/B测试,使用免费游戏内货币作为激励来留住玩家。测试结果表明,在预测的流失事件发生前不久联系玩家显著提高了与玩家沟通的有效性。结果还显示,发放免费游戏内货币对玩家的流失率或货币化没有显著影响。这表明,只有通过在流失事件发生前显著改变玩家的游戏体验才能留住玩家,并且交叉链接可能是应对流失玩家的更有效措施。
I. 引言
社交游戏是一种通过社交网络促进玩家互动的在线游戏,通常具有多人和异步游戏机制。社交游戏传统上以浏览器游戏的形式实现,但最近在移动设备上有了显著增长。过去几年中,社交游戏行业经历了快速增长,2012年估计收入为54亿欧元,预计2016年收入为107亿欧元。到2016年,社交游戏预计将占据视频游戏市场的近50% 1。相比传统核心游戏,休闲游戏的特点是较短的游戏时长、更简单的规则和较低的投入要求。
大多数社交休闲游戏采用"免费增值"商业模式。免费增值(或免费游戏)意味着游戏免费提供给玩家,玩家可以通过应用内购买升级和特殊物品、解锁额外功能或加快进度。免费进入游戏极大地促进了玩家获取,但只有少数玩家会在应用内购买上花费真实货币------对于大多数社交休闲游戏来说,这一比例远低于10%。免费增值模式与客户之间建立了一种非合同关系,玩家离开游戏非常容易。社交游戏开发者的主要目标之一是延长玩家在游戏中的生命周期,以增加玩家基础和货币化潜力。预测用户何时离开游戏的能力为调整游戏体验以延长用户在游戏中的生命周期或在另一款游戏中激发新的生命周期提供了机会。为此,玩家可以被激励继续玩游戏,与公司组合中的其他游戏交叉链接,甚至交叉销售给其他公司。本文设计、实现并评估了基于两个Wooga大型社交游戏中玩家游戏活动数据的高价值玩家流失预测模型,并在其中一款游戏中测试了激励作为应对高价值玩家流失的方法。
选择的两款实时游戏是《Diamond Dash iOS》和《Monster World Flash》。图1和图2展示了这两款游戏的截图。《Diamond Dash》是一款类似于《俄罗斯方块》或《宝石迷阵》的移动设备方块拼图游戏。玩家必须在指定时间内尽快清除相同颜色的钻石以打破高分记录。清除的钻石将从顶部补充。游戏中还有多种能加快清除速度的能量提升或助推器,使玩家可以获得更高的分数并享受更刺激的游戏体验。《Monster World》是一款Facebook上的农场游戏,模拟经营一个高度个性化的花园。玩家种植和收获作物以获得硬币和其他游戏内货币。随着玩家通过各种等级,他们有机会扩展和美化他们的花园,并解锁新的游戏功能。与《Diamond Dash》不同,《Monster World》由玩家需要完成的任务驱动,需要玩家更频繁的互动和参与。


在本文中,我们定义了研究中两款游戏的高价值玩家细分和流失事件。此外,我们将流失预测表述为一个二分类问题。然后我们比较了四种不同分类算法的预测性能,并尝试使用隐马尔可夫模型(HMM)探索时间序列数据的时间动态。为了评估流失预测模型的业务影响,我们设计并在两款实时游戏之一上实施了A/B评估。
II. 文献综述
在各个领域中,已经进行了大量的研究工作 2, 3, 4, 5, 6 来研究客户流失并探索不同的建模技术以提高预测性能。
许多机器学习算法,如决策树、逻辑回归和神经网络,已被应用于流失预测问题。2 提出了一种基于神经网络的方法来预测蜂窝网络服务中的客户流失,并声称在探索不同神经网络拓扑时,中等规模的神经网络在客户流失预测中表现最佳。3 比较了支持向量机、逻辑回归和随机森林在报纸订阅数据集上的表现,报告称随机森林的预测能力在所研究的数据集中优于其他算法。类似的算法比较研究在一家付费电视公司中进行,包括从马尔可夫链模型中获得的客户流失概率估计作为流失预测模型的额外预测变量,并报告了改进的预测性能 4。5 声称神经网络在预测性能上优于其他流失预测模型。类似的结果可以在 6 和 7 中找到。
最近的研究 8, 9 也尝试通过社交网络挖掘或用社交网络统计数据扩展传统的机器学习技术来进行流失预测。社交网络分析也被用于预测移动网络中的客户流失 8。其基本思想是,如果客户在社交图中的邻居已经流失,那么该客户流失的概率会增加。9 构建了一个混合预测模型,将传统的表格流失模型与社交网络特征相结合,并报告称传统的表格流失模型仍然表现最佳。
据我们所知,只有一项其他研究 13 调查了免费游戏中的流失预测。然而,在进行这项研究时,该研究尚未发表。两项相关的研究工作 10, 11 关注于大型多人在线角色扮演游戏中的流失预测。10 提出了一种基于社会影响的方法,该方法应用了修改后的扩散模型与不同的传统分类器。玩家之间的社交关系通过玩家共同完成的任务数量来表征。11 提出了参与度、热情和持久性这三个语义维度,以构建用于流失预测建模的派生特征,并基于标记时间序列簇的加权距离提出了一种混合分类方法。12 采用了不同的方法,应用了生命周期分析技术在五款第一人称射击游戏的数据上。12 得出结论,普通玩家对游戏的兴趣随着一个非齐次泊松过程而变化。因此,玩家初始游戏行为的数据可以用来预测他们何时停止游戏。
我们的主要贡献是:据我们所知,与 13 一起,我们是第一个彻底研究免费休闲社交游戏中流失预测可行性的人。其次,我们是第一个评估高价值玩家流失预测对大型休闲社交游戏的业务影响------对玩家沟通、流失率和收入的影响。由此,我们发现了一些从纯数据分析角度无法发现的业务问题。第三,我们探索了在流失预测的传统分类模型中添加隐马尔可夫模型(HMM)特征的价值。
III. 问题定义
A. 定义高价值玩家
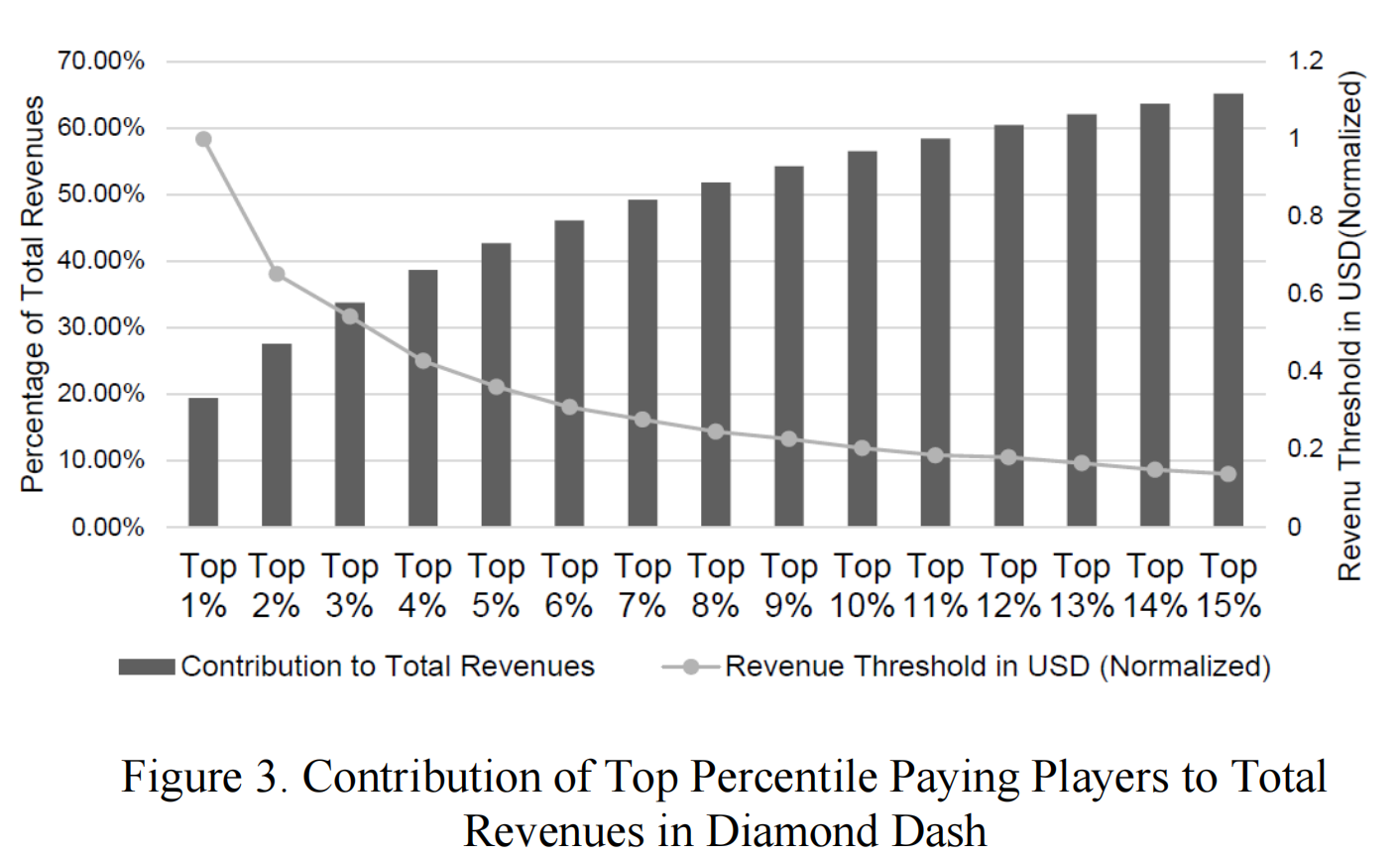
"高价值玩家"这个术语相当模糊。为了更精确地定义高价值玩家,我们研究了《Diamond Dash》中前百分比付费玩家对总收入的贡献,如图3所示。前7%的付费玩家贡献了大约50%的总收入。最低收入门槛(玩家要进入前百分比所需的最低收入)在前10%的付费玩家以下开始趋于平缓。进一步扩展百分比时,玩家变得越来越同质化。前10%似乎涵盖了所有具有异常高价值的玩家,这导致我们采用以下定义:
定义1:在第 t=0 天(观察时间)游戏中的高价值玩家是指在第 t = -90 天到第 t = -1 天之间按每个玩家产生的收入降序排列的所有付费玩家中排名前10%的玩家。
B. 定义活跃度
由于我们希望在实际流失事件发生之前接触到玩家,预测应针对活跃的高价值玩家。我们定义活跃的高价值玩家如下:
定义2:在第 t=0 天的活跃高价值玩家是指在第 t = -14 天到第 t = -1 天之间至少玩过一次游戏的高价值玩家。
C. 定义流失
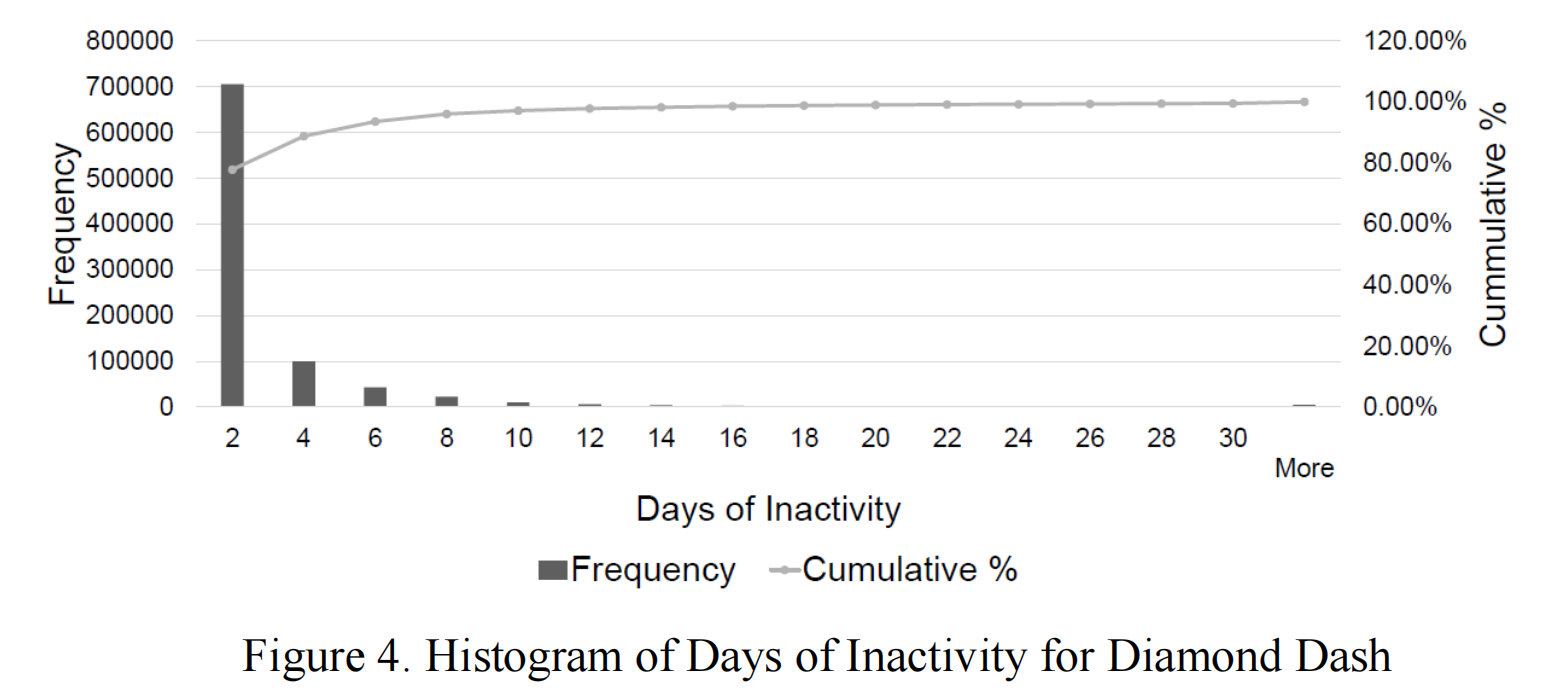
"玩家流失"定义为永久离开游戏的玩家。这一决定可能是有意识或无意识的,由外部或内部原因驱动。在实践中,我们需要一个不活跃天数的阈值,以明确定义玩家的流失。我们考虑了《Diamond Dash》中高价值玩家在登录之间的不活跃天数分布。例如,如果一个高价值玩家在第 t = 1 天和第 t = 3 天玩了游戏,然后在第 t = 7 天再次玩游戏,这就给出了两个不活跃天数的样本:一个是 3 - 1 - 1 = 1 天,另一个是 7 - 3 - 1 = 3 天。图4显示了不活跃天数的分布直方图和累积分布曲线。数据显示,少于2%的高价值玩家在超过14天的时间内未登录游戏。因此,14天的不活跃是流失的良好指标。根据这一定义,98%的被定义为流失的玩家确实流失了。
定义3:如果一个活跃的高价值玩家在第 t=0 天开始在第 t=0 天到第 t=6 天之间的任何一天连续14天不活跃,则认为该玩家在第 t=0 天流失。
D. 问题陈述
我们将流失预测问题建模为一个二分类任务,其目标是为每个玩家分配一个流失或不流失的标签。我们在之前观察到的玩家行为的标记数据上训练各种分类器,预测玩家在该天之后的一周内是否会流失。我们使用AUC(接收者操作特征曲线下的面积)进行性能比较,因为它允许我们在所有可能的分类阈值下比较模型。ROC曲线通常在图表中显示,横轴为假阳性率(FPR),纵轴为真阳性率(TPR)。分类器性能可以通过不同的TPR和FPR组合以及不同的阈值选择进行比较。由于AUC是ROC曲线下的面积,当AUC为1时,分类器表现完美,ROC曲线沿图表的左边界和上边界运行。无论阈值如何,分类的TPR为1,FPR为0。当ROC曲线从左下角到右上角对角线时,AUC为0.5,反映了随机分类的情况。总结来说,我们的问题是找到最正确地为玩家分配流失标签的分类器,在所有可能的分类阈值下最大化AUC。
IV. 建模
A. 数据集
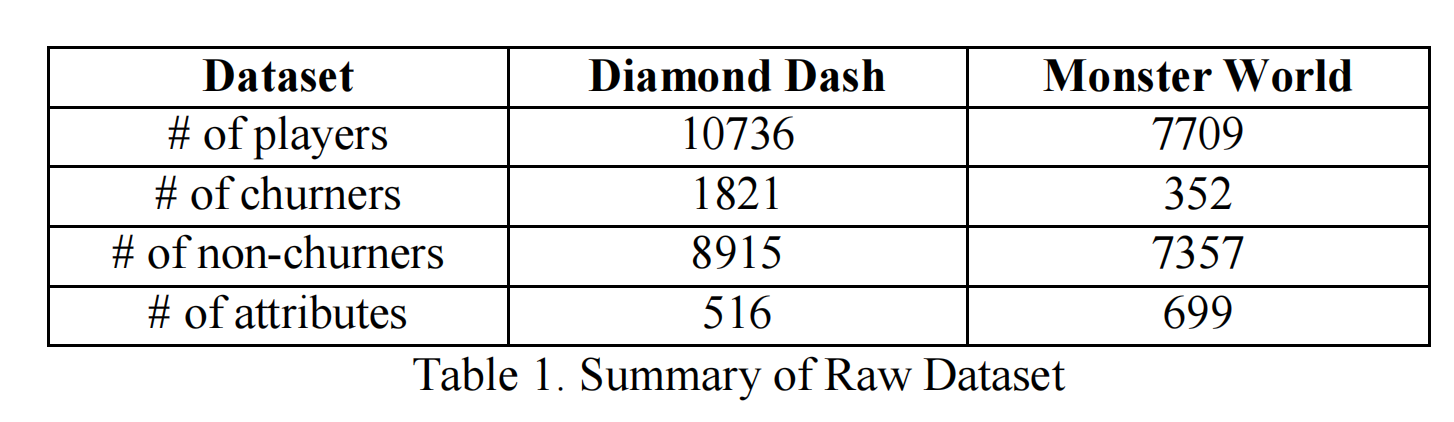
对于《Diamond Dash》和《Monster World》,我们提取了高价值玩家在2013年7月1日和8月1日这两个观察日的相关历史跟踪数据。然后,我们构建了两个标记数据集来建立流失预测模型。表1显示了原始数据集的摘要。数据主要有三类:第一类是游戏内活动跟踪数据,例如每天登录的时间序列或准确度时间序列;第二类是与收入相关的跟踪数据,例如玩家产生收入的时间序列;第三类是玩家档案数据,例如玩家玩游戏的时间长度和玩家来自哪个国家。我们通过应用Box-Cox变换处理数据,以减轻数据集的高度正偏。由于我们使用的算法通常在标准化数据集上表现更好,我们在数据准备阶段进一步对数据进行了中心化和缩放处理。
B. 特征选择
准备好的数据集包括数百个属性,并不是所有属性都对预测有用。为了确定用于预测的属性集,我们进行了系列特征选择程序。在特征选择过程中,我们使用了10折交叉验证的逻辑回归来估计不同特征集的AUC表现。我们实验了时间序列的长度,消除了与其他时间序列高度相关的时间序列,并应用了前向特征选择。表2总结了最终模型的特征集。经验实验表明,仅使用流失事件前14天的历史数据在AUC方面能获得最佳预测性能。

C. 离线评估
我们比较了神经网络(NN)、逻辑回归(Logistic)、决策树(DT)和支持向量机(SVM)的最佳预测性能。对于SVM,我们使用了径向基函数内核,并通过10折交叉验证应用参数网格搜索来调整超参数。我们实验了100种C(范围从0到5)和gamma(范围从0.2到5)的组合,步长为二次方。神经网络采用了简单的单隐藏层网络拓扑。隐藏节点数设为属性数和类别数之和除以二再加一。对于神经网络,我们也使用了10折交叉验证的参数网格搜索,尝试了学习率和动量的100种组合(范围从0.5到1.0)。
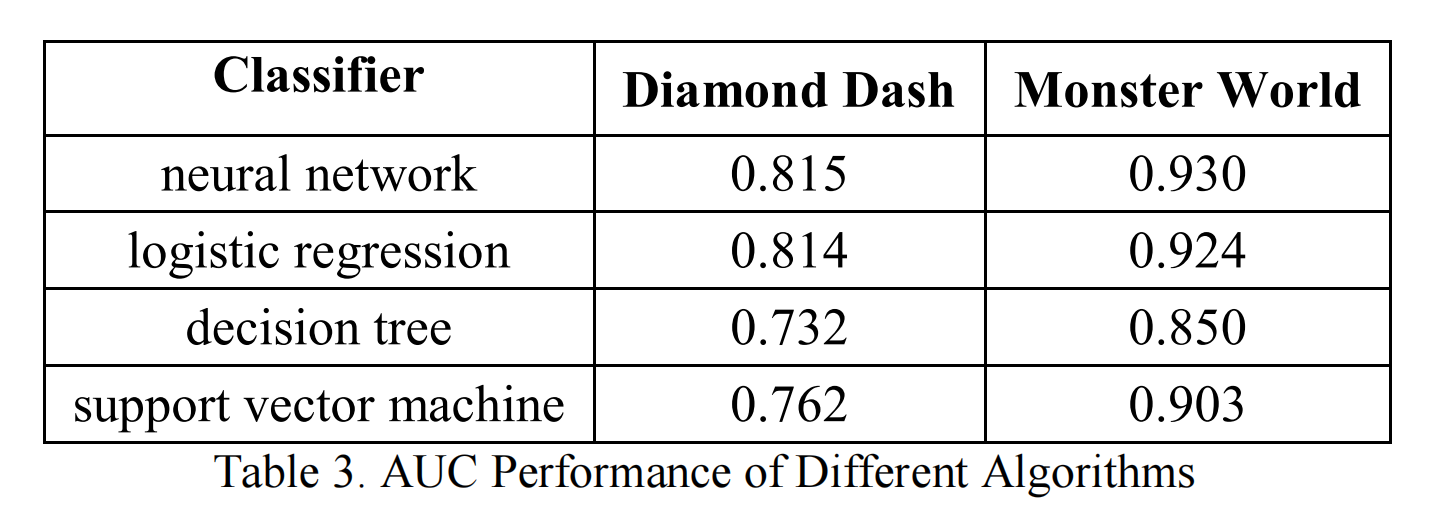
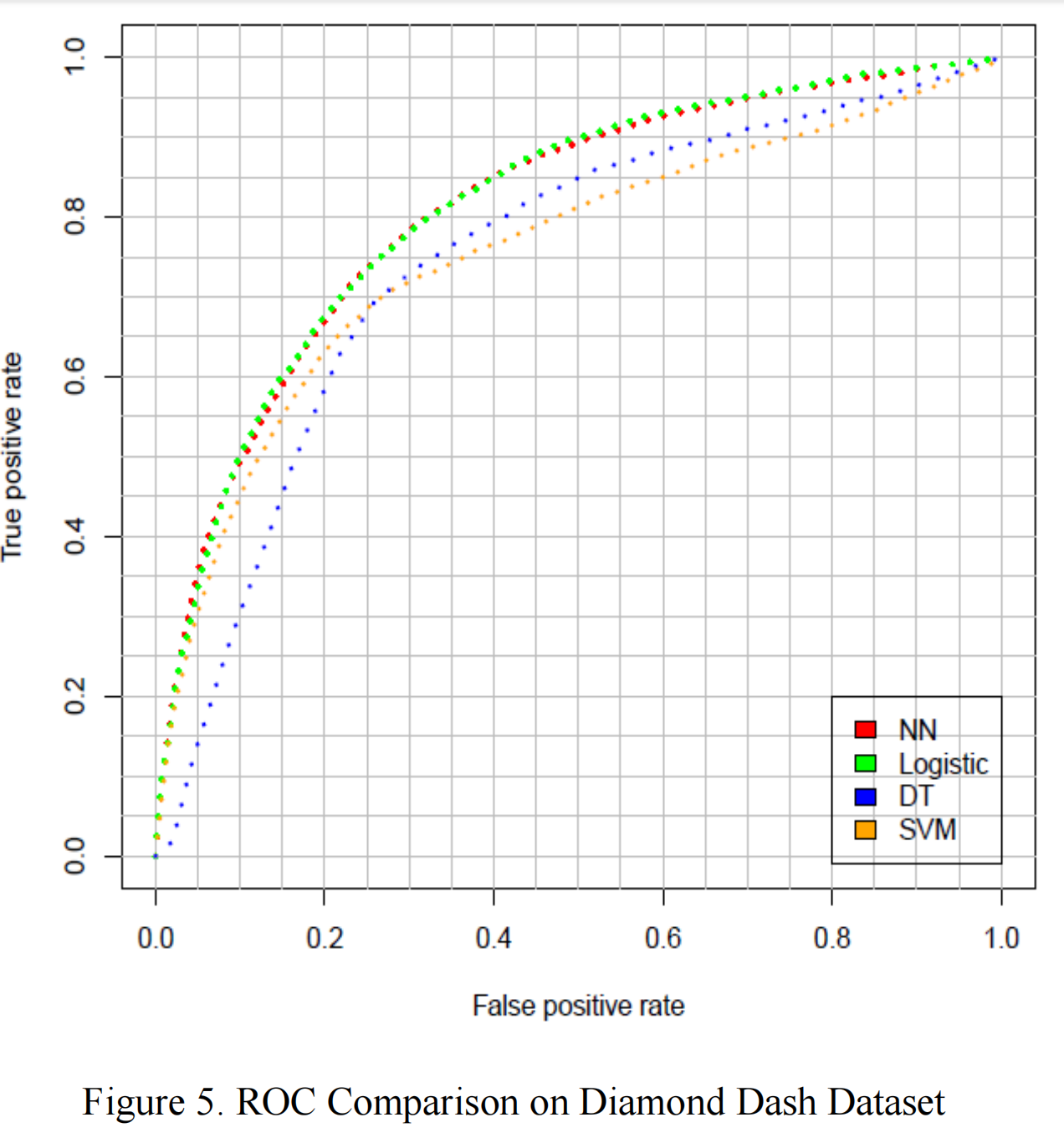
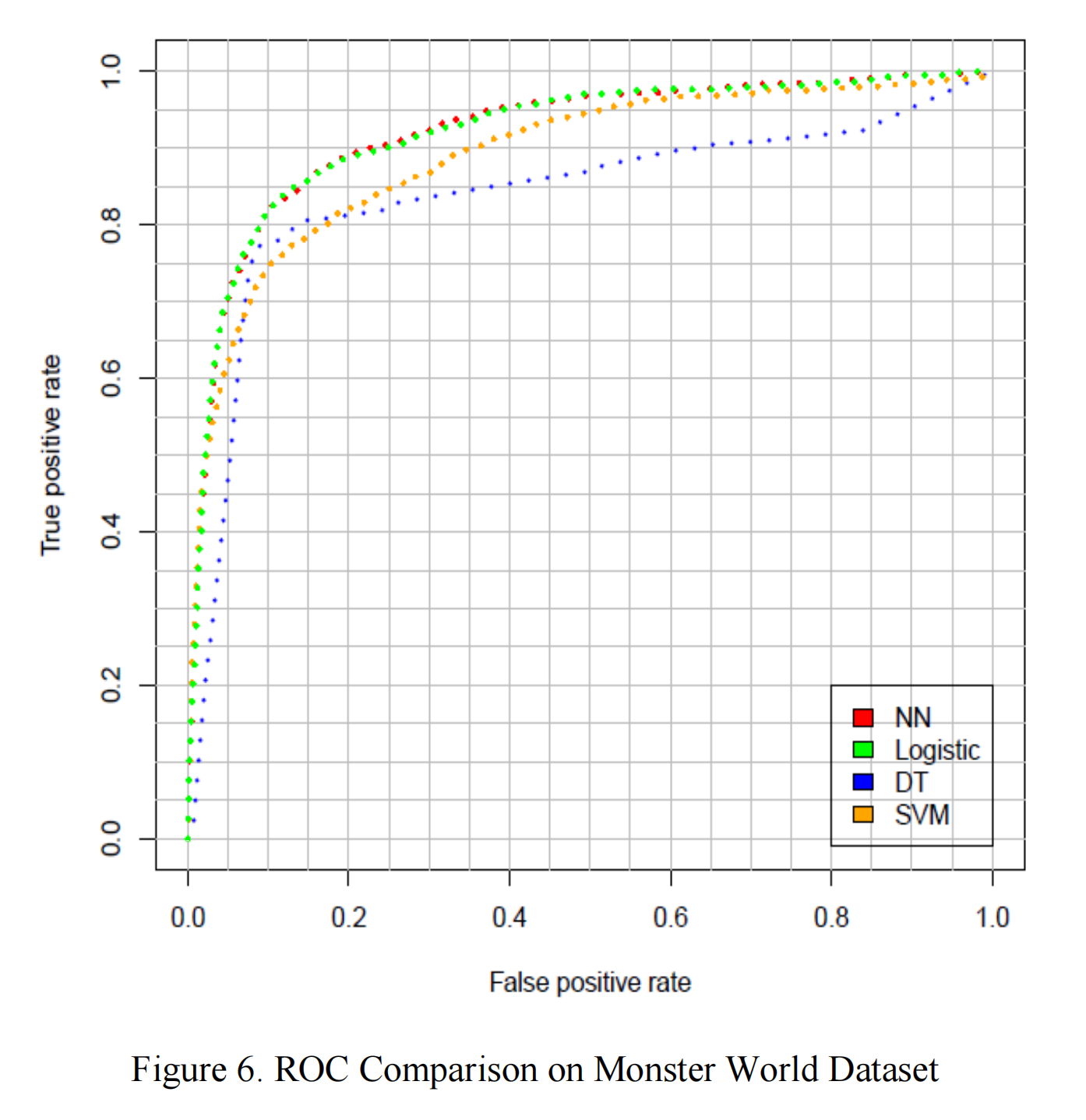
表3报告了不同算法在两个数据集上的平均AUC表现。图5和图6显示了上述四种算法的ROC曲线。结果在两个数据集上是一致的。神经网络和逻辑回归的表现相同,但如果纯粹基于AUC比较,神经网络略胜一筹。SVM和决策树的表现不太令人满意。SVM在低FPR(假阳性率)时表现更好,而决策树在FPR高于25%时表现更好。对于我们来说,低FPR更重要,因为我们认为干扰非流失玩家比忽视一些流失玩家更有害。因此,SVM比决策树更受青睐。在AUC方面,SVM也优于决策树。
D. 预测性能比较
图7显示了神经网络在《Diamond Dash》和《Monster World》数据上的ROC曲线比较。相同的预测建模技术在《Monster World》上表现明显优于《Diamond Dash》。具体来说,如果我们将FPR(即我们在预测的流失列表中包含的实际非流失用户的百分比)固定在5%,我们在《Monster World》上可以达到超过70%的TPR(真正率)。因此,我们可以覆盖到超过70%的真正流失用户,而在《Diamond Dash》上,在相同的FPR下,我们只能覆盖到35%的真正流失用户。
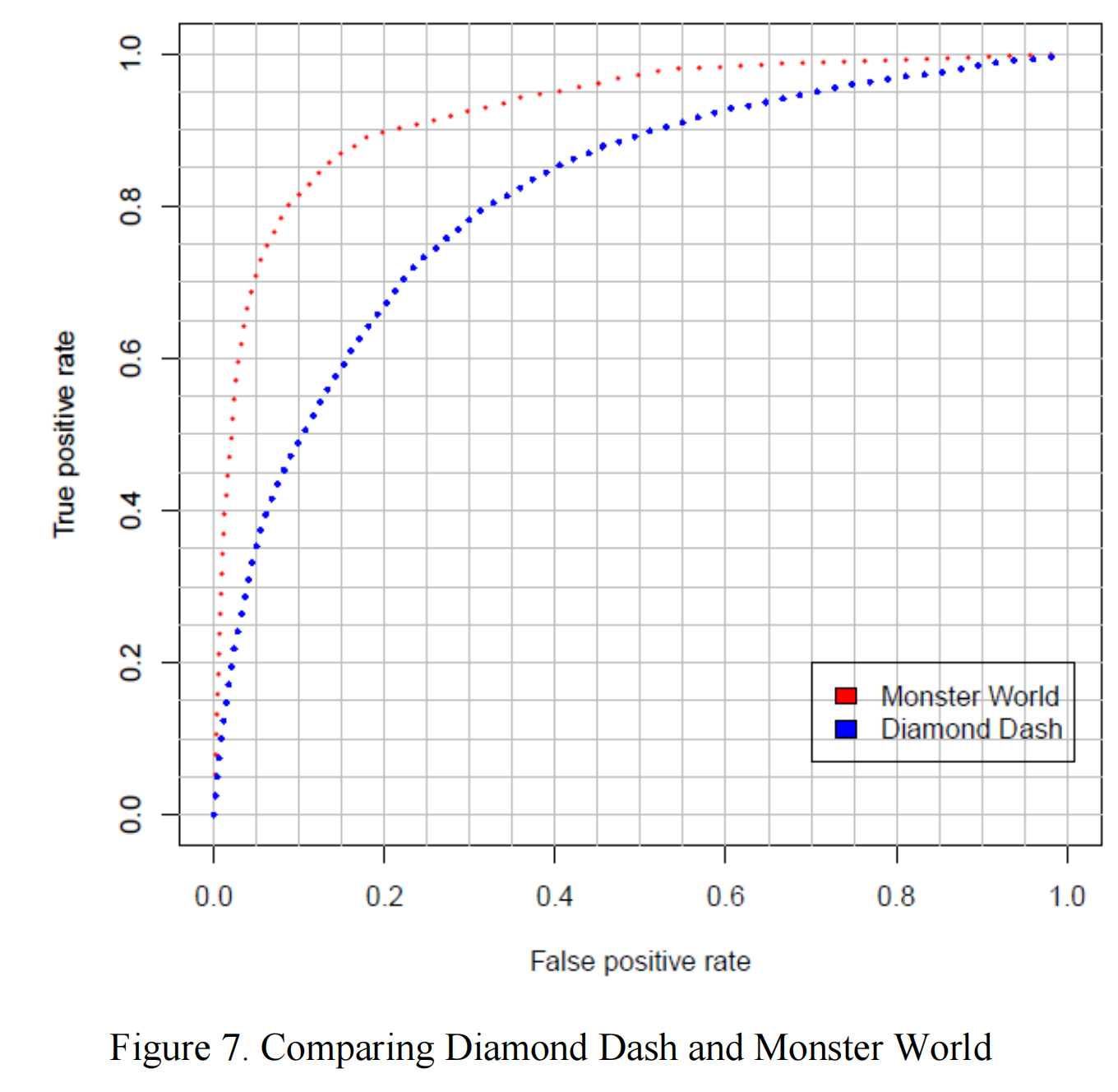
这种差异的直观解释是游戏的性质不同。尽管《Monster World》是一款休闲游戏,但它需要玩家更频繁的互动,并且更具吸引力。它在核心的种植机制之外还有许多附加功能,包括制作和销售产品、抽奖、水下花园以及像访问朋友的花园这样的深度社交功能。而《Diamond Dash》则完全专注于相同核心机制的限时回合。它不需要玩家投入大量精力,允许更随意的互动。《Diamond Dash》中的每用户每天登录次数显著低于《Monster World》,同一玩家的会话间隔可能会持续几天。因此,《Diamond Dash》中游戏内活动的行为模式不如《Monster World》明显,显得更随机,包含的关于即将发生流失事件的结构化信息更少。
E. 结合神经网络和HMM
尽管前面讨论的建模技术已经提供了相当不错的预测性能,但所有这些技术的一个共同问题是它们没有明确考虑时间序列属性的时间动态。如果我们改变时间序列中数据点的顺序,结果预测不会受到影响,因为这些算法没有考虑属性的时间顺序。Wooga的数据库中有高质量的历史跟踪数据,可以追溯到几个月甚至几年。为了更好地利用这些数据中可能存在的信息,我们将注意力转向HMM(隐马尔可夫模型)。我们将从HMM获得的结果包含在神经网络中,以进一步提高预测性能。
我们选择使用《Monster World》数据集将用户的每日登录时间序列建模为一个隐马尔可夫过程,因为之前证明该数据集更适合流失预测。研究的数据是《Monster World》每日登录时间序列的所有实例,这些数据经过数据清洗步骤但没有进行数据变换。这是因为数据变换会以一种使其无法用于拟合HMM的方式改变数据。
HMM的训练数据可以表示为向量
L = L 1 , L 2 , ... , L n T L = L1,L2,...,Ln^T L=L1,L2,...,LnT
其中每个
L i = L i ( − 60 ) , L i ( − 59 ) , ... , L i ( − 1 ) Li= Li(-60), Li(-59),..., Li(-1) Li=Li(−60),Li(−59),...,Li(−1)
是玩家在第 t = -60 天到第 t = -1 天之间的每日登录时间序列,n是数据集中的实例数量。
我们还对模型做了以下假设:
- 登录时间序列的实例是相互独立的,这是一个有效的假设,因为每个实例都是某个不同用户的观察值。
- 所有登录时间序列的实例都是由一个单一的底层隐马尔可夫过程生成的。因此,我们假设HMM描绘了一个平均用户的随机行为。
- HMM的发射分布遵循泊松分布。登录时间序列中的每个值都是记录登录事件数量的非负整数。
基本上,模型设置反映了玩家在某个日期的实际登录情况取决于该日期玩家的状态。一个隐藏且不可观察的状态过程是一个马尔可夫链过程。实际观察到的登录值遵循泊松分布,其中泊松分布的均值取决于玩家在每个日期的状态。
通过HMM,我们利用了更多的历史数据并考虑了时间动态。然而,HMM的设置难以与我们的流失定义相协调,不能直接用于预测。为了利用我们构建的HMM,我们使用它来提取新特征,并将这些特征添加到神经网络中。这个想法是,这将增强预测性能。我们遵循Burez和van den Poel的方法4,他们将从马尔可夫链模型中提取的特征纳入神经网络以提高预测性能。
通过HMM,我们为每个实例 i i i计算了以下概率作为新特征添加到神经网络中:
p i = p 0 , p 1 , ... , p 13 pi = p0, p1, ..., p13 pi=p0,p1,...,p13
其中
p k = P r ( L i ( k ) = 0 ∣ L i = l i ) pk = Pr(Li(k)= 0|Li = li) pk=Pr(Li(k)=0∣Li=li)
基本上, p i pi pi是一个向量,其中元素 p k pk pk是给定观察序列 L L L到 t = − 1 t = -1 t=−1,玩家 i i i在日期 t = k t=k t=k不玩游戏的概率。
在HMM的设置下,概率 p k pk pk可以使用以下公式轻松计算:
p k = ( α Г k + 1 P ( 0 ) 1 ' ) / ( α 1 ' ) pk=(\alphaГ^{k+1}P(0)1')/(\alpha1') pk=(αГk+1P(0)1')/(α1')
其中 α \alpha α表示 t = − 1 t=-1 t=−1时HMM的前向概率, Г Г Г是HMM的转移矩阵, P ( 0 ) P(0) P(0)是一个对角矩阵,其中第 m m m个对角元素是给定隐藏状态为 m m m时观察到0的概率。上述公式的详细数学证明可以在14中找到。
然后,我们将新特征 p i pi pi添加到经过变换的《Monster World》数据集中,并在新的特征集上应用神经网络建模。具有新特征集的模型的AUC值为0.923,相比我们使用旧特征集时达到的0.930,预测性能有所下降。包含HMM特征似乎导致了过拟合,从而由于交叉验证中的样本外性能较差而降低了AUC。仅使用HMM特征进行预测的AUC为0.915。因此,我们没有在最终提出的预测模型中包含HMM结果。
V. 业务影响
从机器学习的角度来看,我们已经构建了一个令人满意的流失预测模型。在现实中,通常会有在模型构建过程中无法预见的业务和/或技术问题。解决这些问题的一种方法是将预测模型小规模地集成和部署。在本节中,我们讨论了将预测模型推广到《Monster World》时获得的结果。
我们实施了一个A/B评估,以评估在玩家沟通、流失率和收入方面的业务影响。这些维度定义了模型用例的强度。
A. A/B测试设置
研究对象是游戏《Monster World》的玩家。所有活跃玩家被随机分配到三个测试组A、B和C。A组和B组各包括大约40%的总玩家基数,C组包括大约20%的总玩家基数。对于A组(启发式组),在流失事件发生后(14天未活跃),我们向高价值玩家发送了大量的免费游戏内货币,价值超过10美元。我们称之为启发式组,因为这种措施可以在没有任何预测模型的情况下采取。礼物通过Facebook应用通知和电子邮件发送。对于B组(预测组),在A组的启发式流失管理政策基础上,我们使用流失预测模型获得仍然活跃但即将流失的高价值玩家列表,并向这个选择性列表的玩家发送激励。对于C组(对照组),没有采取任何措施来处理流失的高价值玩家。
这个A/B测试的目的是验证预测模型是否具有超出没有任何预测努力的实际业务影响。通过关键绩效指标(KPI)评估业务影响。对于给定的用例,最重要的是高价值玩家流失率和收入,以及电子邮件活动点击率和Facebook通知点击率,以衡量与玩家沟通的有效性。
KPI定义如下:
定义4. 流失率(CR)
C R = 1 -- # active high-value players # high-value players CR = 1 -- \frac{\# \text{active high-value players}}{\# \text{high-value players}} CR=1--#high-value players#active high-value players
定义5. 每日收入(DR)
D R = total revenues from players in a group during a day DR = \text{total revenues from players in a group during a day} DR=total revenues from players in a group during a day
定义6. 电子邮件点击率(CTR)
C T R = # gifts claimed by email # emails delivered CTR = \frac{\# \text{gifts claimed by email}}{\# \text{emails delivered}} CTR=#emails delivered#gifts claimed by email
定义7. Facebook点击率(CTI)
C T I = # gifts claimed by notification # notifications seen by players CTI = \frac{\# \text{gifts claimed by notification}}{\# \text{notifications seen by players}} CTI=#notifications seen by players#gifts claimed by notification
B. A/B测试结果
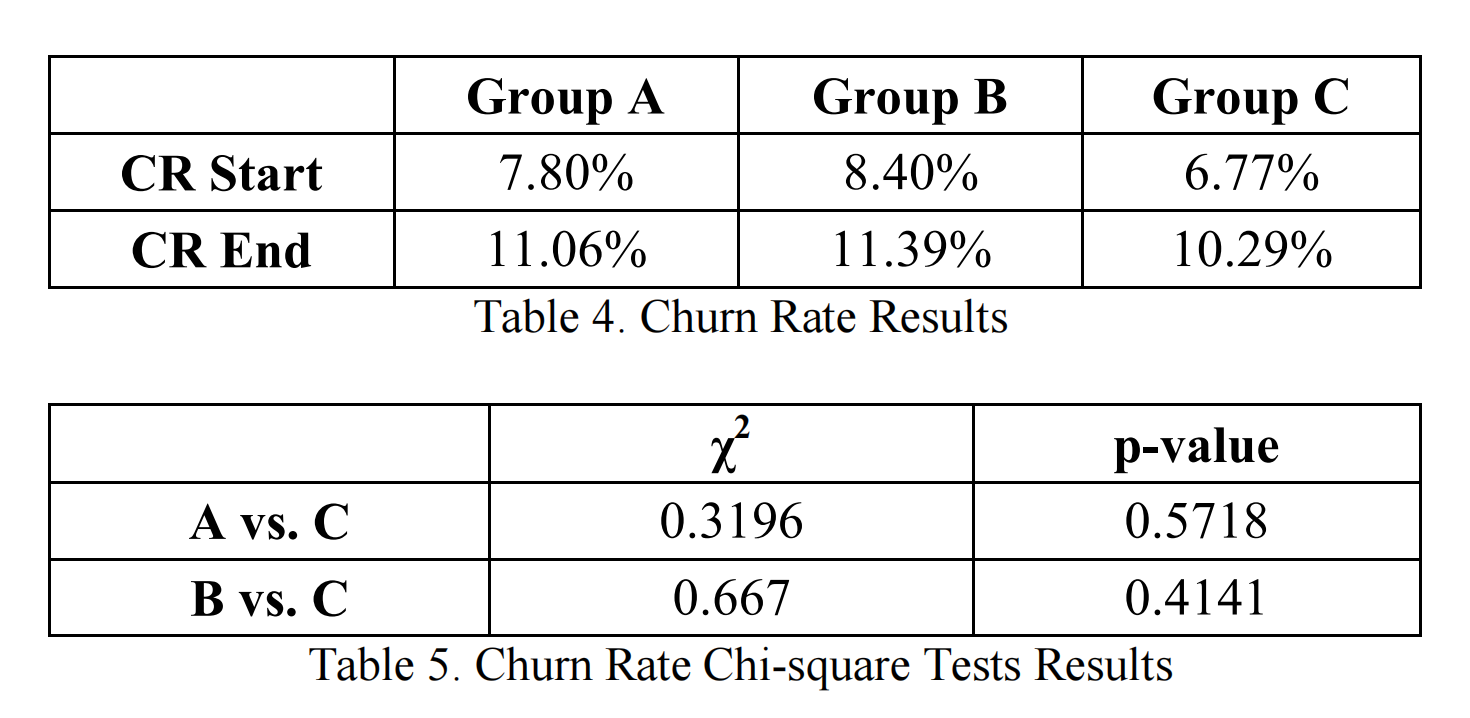
表4显示了在测试开始和结束时不同组的高价值玩家流失率。可以看到,在测试期间,所有三个测试组的高价值玩家流失率都大幅上升。这是因为《Monster World》是一款老游戏(超过三年),现在处于生命周期的末期。基于玩家流失是伯努利随机变量的假设,我们应用卡方检验来找出组间是否存在显著差异。表5显示了流失率的卡方检验结果。零假设是A组和C组以及B组和C组在测试结束时的流失率相等。由于两个p值都远大于0.05,没有强有力的统计证据表明任何一种流失管理政策对流失率有积极影响。然而,比较测试开始和结束时的流失率增长,我们看到B组的流失率增长略微较慢。这可以解释为预测流失管理政策更高效的指示性证据。我们稍后将概述这种更高效的可能原因。
历史上,研究中的游戏的归一化每日总收入遵循高斯分布并且方差接近相等。基于此假设,我们进行了两样本t检验,以测试不同测试组间每日收入是否存在显著差异。零假设是A组和C组以及B组和C组的归一化每日收入均值相等。结果如表6所示。由于两个p值都远大于0.05,我们无法拒绝均值相等的零假设。因此,没有统计学证据表明不同的流失管理政策对每日收入有影响。因此,预测模型对收入没有正面影响。这些结果相当令人失望。然而,对于业务影响的最后一个KPI,预测模型确实产生了不同的结果。对于A组(启发式组),电子邮件活动的CTR为2.35%。对于B组,采用预测流失管理政策,相同值为11.90%。
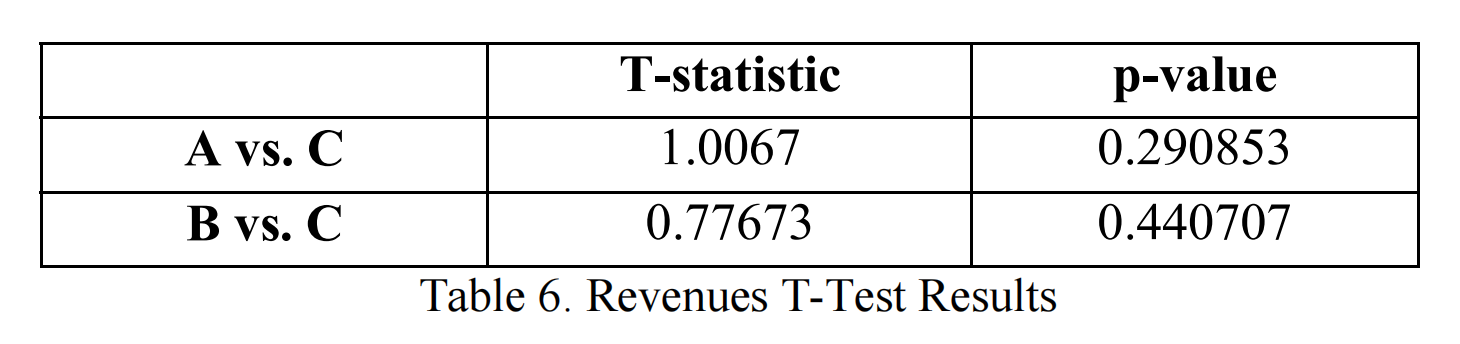
表7显示了比较A组和B组电子邮件CTR的卡方检验结果。p值小于0.05。这表明使用预测模型可以提高电子邮件营销的有效性,并抓住机会在高价值玩家仍然对游戏感兴趣时与他们联系。
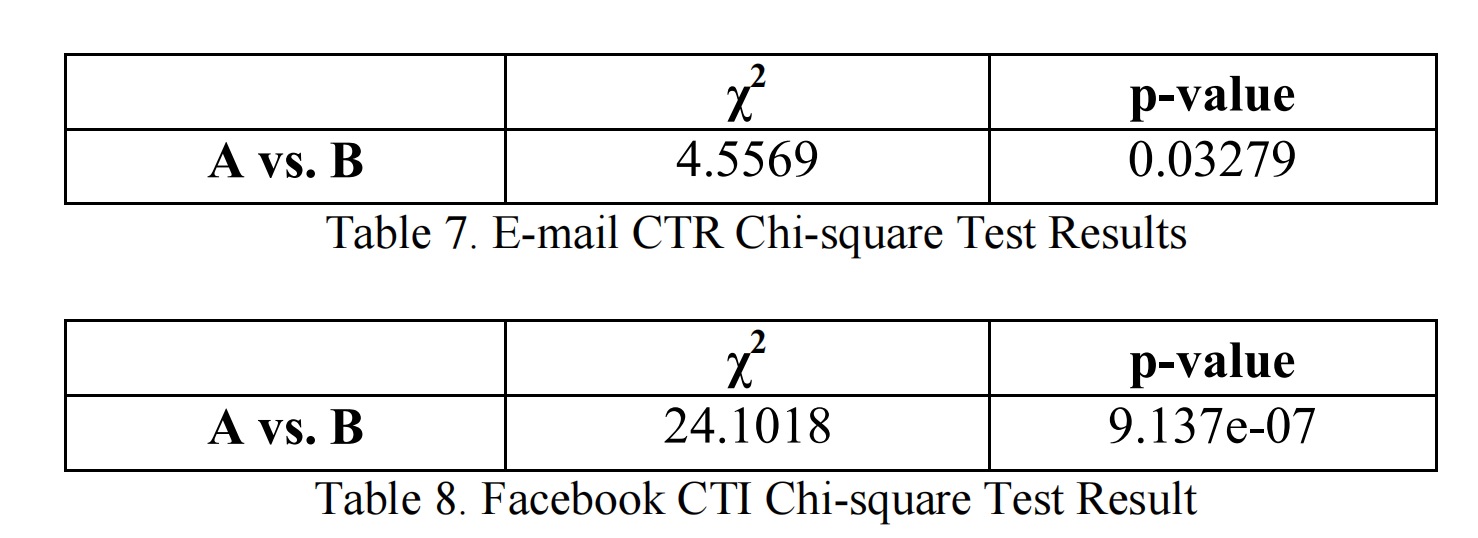
我们还进一步比较了A组和B组的电子邮件活动漏斗。图8展示了组间的差异。在漏斗的顶部是我们发送的电子邮件。在下一层,由于只有大约90%的记录电子邮件地址是有效的,我们在投递阶段失去了大约10%的玩家。在下一层"已打开"中,我们已经看到了明显的打开率差异。最后,对于预测组,我们的点击率平均是启发式组的五倍。当我们使用主动预测流失管理政策时,领取礼物链接的玩家数量是启发式组的四倍。类似地,对于A组,Facebook通知的CTI为8.66%,而对于B组则为31.48%。对两个组进行卡方检验的p值约为0,因此B组在统计上表现显著更好。
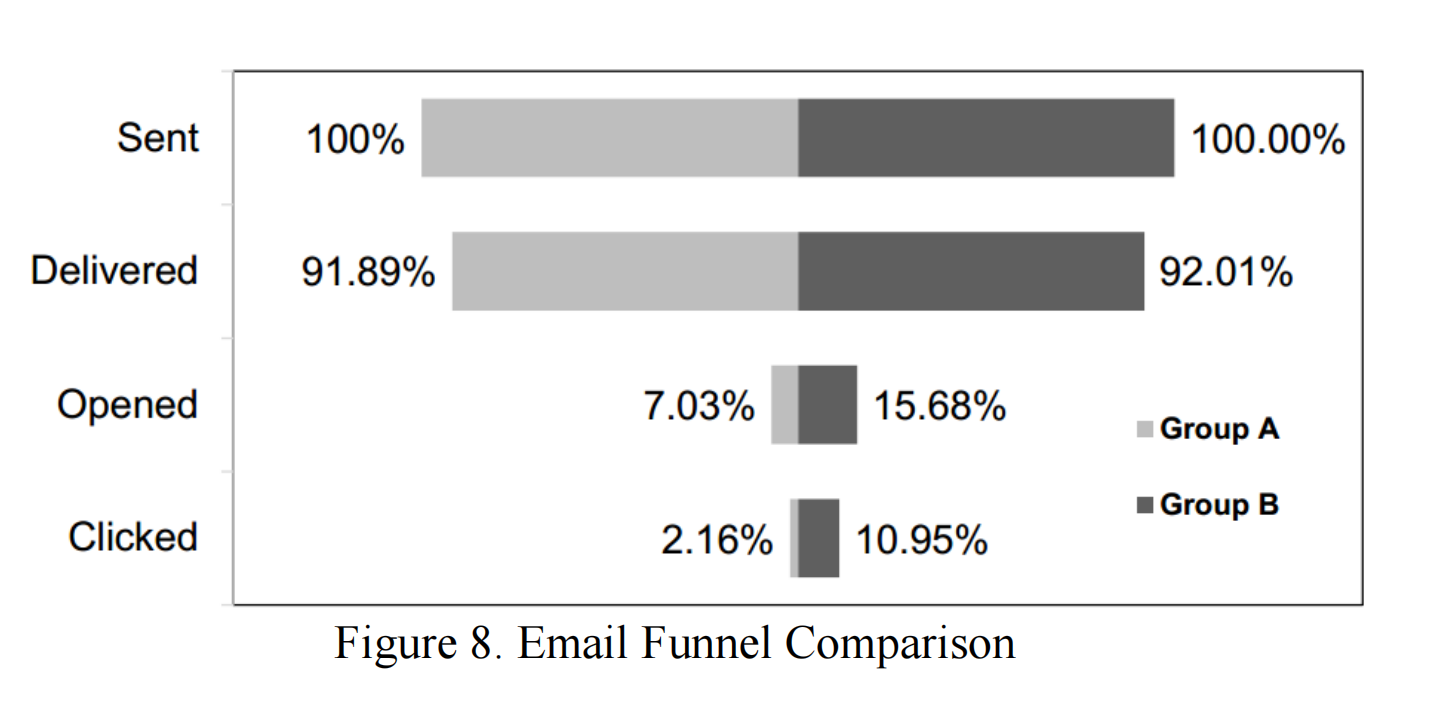
图9展示了A组和B组之间Facebook通知漏斗的比较。第一步总结了我们通过Facebook发送通知的所有玩家。在下一层,投递率已经存在差异,因为我们无法向已经卸载游戏的玩家发送通知。在下一层"已发布"中,我们进一步失去了玩家。原因是如果玩家屏蔽了我们的通知,Facebook将不会向玩家发布任何通知。
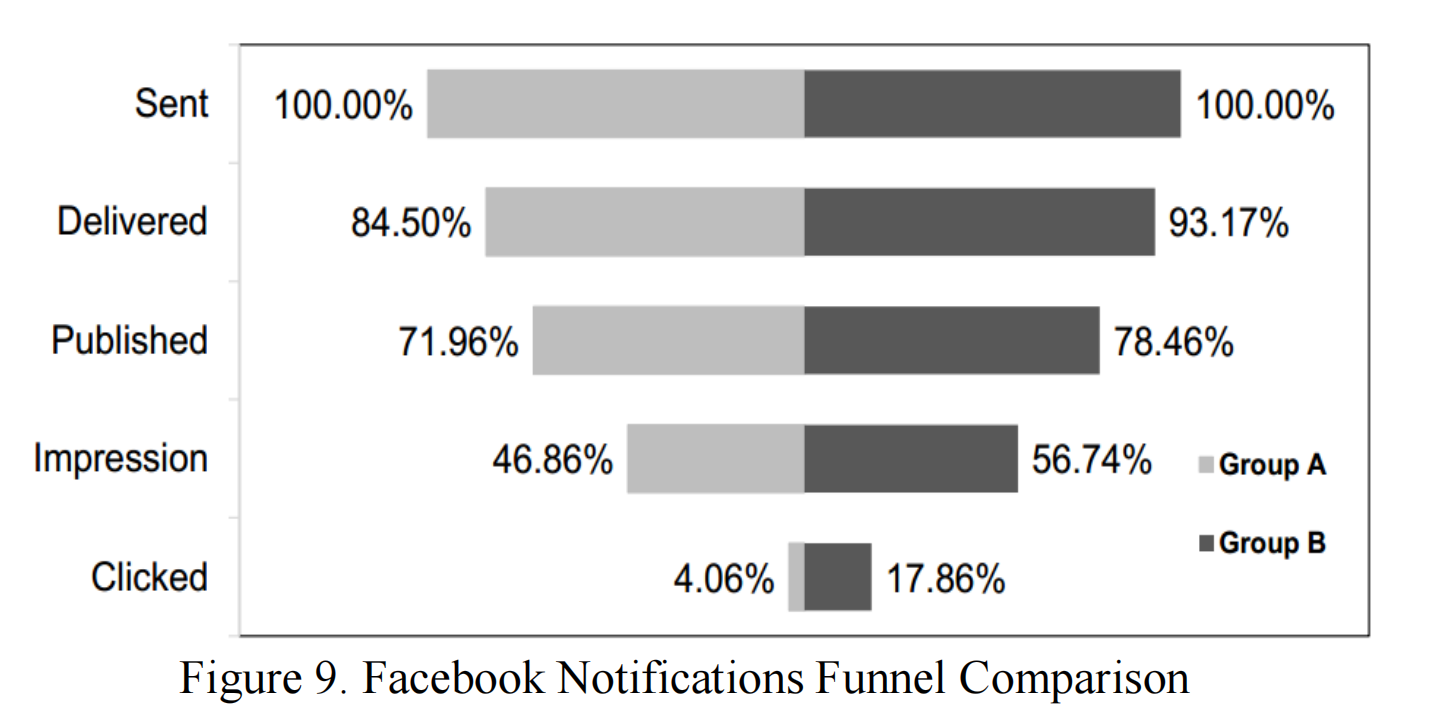
对于A组和B组,在这一步的百分比损失大致相等。在曝光层面,对于A组,只有46.86/71.96 = 65.12%的已发布通知被玩家看到,而对于B组,56.74/78.46 = 72.31%的已发布通知被玩家看到。在最后一步,我们见证了通知点击率的显著提升。在预测流失管理政策组(即B组)中,通知被领取的概率是启发式组的三倍。
对这些结果的合理批评是,预测组取得的良好CTR是由组内的假阳性数量驱动的,即那些并未即将流失但被预测为即将流失的玩家。当训练和测试我们的算法时,我们在重复和样本外测试中始终达到了超过40%的精度。假设在A/B评估中使用的预测具有相同的精度,最多60%的联系高价值玩家可能是实际未流失的。在之前针对同一游戏的高价值玩家的电子邮件礼物活动中,我们观察到的CTR约为10%。假设在预测的流失玩家中的假阳性具有类似的CTR,那么真正的阳性,即即将流失的玩家,具有大致相同的CTR,因为总体CTR超过10%。因此,在流失即将发生前不久联系高价值玩家似乎与他们完全活跃时联系一样有效。并且远比在流失事件发生后联系他们更有效,在这种情况下我们观察到的CTR约为2%。因此,流失预测的价值在于使我们能够在玩家游戏生命周期的最后阶段与他们联系。成功在玩家生命周期中期进行交叉链接可能对发送游戏有害,因为这可能会缩短玩家在该游戏中的生命周期。另一方面,交叉链接那些处于生命周期末期并且无论如何都会离开发送游戏的玩家几乎没有成本。
VI. 结论
在本文中,我们提供了高价值玩家细分的定量定义,定义了流失事件,并将流失预测表述为二元分类问题。我们提取了相关的游戏内活动跟踪数据,进行了系列数据预处理程序,并获得了两个高质量的数据集。我们选择了Wooga的两款游戏《Diamond Dash》和《Monster World》作为研究对象,这两款游戏各自拥有数百万玩家,用户基数庞大且生命周期长。我们比较了四种不同的分类算法,并尝试通过从隐马尔可夫模型中提取的特征将时间动态包含在分类中。为了评估流失预测的业务影响,我们在预测性能显著更好的游戏《Monster World》上设计并实施了一次A/B测试。
实验表明,具有精细调整学习率和动量的单隐层神经网络在AUC方面优于其他学习算法。这在我们研究的两个数据集中是一致的。对于《Diamond Dash》,我们能够达到0.815的AUC,而对于《Monster World》,我们能够达到高达0.930的AUC。使用相同的建模技术,《Monster World》数据集的响应比《Diamond Dash》数据集更好,这表明对高度休闲游戏的流失预测更为困难。我们认为,这很可能是因为高度休闲游戏中的行为模式不太明显,因为玩家需要的承诺和参与度较低。
A/B测试结果表明,向流失和已流失的高价值玩家发送大量免费游戏内货币(货币价值约10美元)并不会显著影响流失率。这表明高度参与的玩家在其生命周期结束时无法通过简单的激励措施来挽留。与反应性流失管理政策相比,利用预测模型的政策将沟通渠道的有效性提高了四到五倍。对于电子邮件活动,点击率从2.4%提高到12%。对于Facebook通知,点击到展示率从8.7%提高到31.5%。
对如何处理休闲社交游戏中的流失玩家进行彻底评估对行业和研究同样具有高度价值。我们研究的一个可能扩展是调查跨链接到公司组合中的其他(理想情况下相似的)游戏。这似乎是应对玩家流失比激励更有前途的方法。我们讨论的另一个选项是探索更深层次的游戏机制,并以保持玩家对游戏兴趣的方式改变他们的游戏体验。在方法论上,可以更详细地审查玩家流失前的时间动态。尽管HMM特征的集成未能改善模型的预测性能,但隐马尔可夫状态可能是可操作的客户细分的一个有益框架。最后,未来的研究可以有益地解决浏览器与移动休闲社交游戏流失的算法预测性能差异问题。
致谢
我们要向Wooga公司致以诚挚的感谢,感谢他们提供相关玩家数据,并允许我们在如此愉快和充满活力的环境中合作。我们还要感谢Jan Miczaika、Thomas Leclerc、Maciej Zak、Pia Simonsen、Robert Wolf、Markus Steinkamp、Armin Feistenauer以及其他多位同事在我们研究过程中的帮助。
REFERENCES
1 iDate, Markets and Trends 2012-2016, market research report, [Retrieved
from http://www.idate.org/en/Research-store/Social-Gaming 778.html
on February 9th 2014].
2 A. Sharma, and P. K. Panigrahi, "A Neural Network based Approach for
Predicting Customer Churn in Cellular Network Services," International
Journal of Computer Applications, Vol. 27(11), pp. 975-8887, August
3 K. Coussement, and D. Van den Poel, "Churn prediction in subscription
services: An application of support vector machines while comparing
two parameter-selection techniques," Expert Systems with Applications,
Vol. 34(1), pp. 313-327, January 2008.
4 J. Burez, and D. Van den Poel, "CRM at a pay-TV company: Using
analytical models to reduce customer attrition by targeted marketing for
subscription services," Expert Systems with Applications, Vol. 32(2),
pp. 277-288, 2007.
5 T. Iwata, K. Saito, and T. Yamada, "Recommendation method for
extending subscription periods," KDD '06: Proceedings of the 12th
ACM SIGKDD international conference on Knowledge discovery and
data mining, pp- 574-579, 2006.
6 J. Hadden, A. Tiwari, R. Roy, and D. Ruta, "Churn prediction: Does
technology matter," International Journal of Intelligent Technology,
Vol. 1(1), pp. 104-110, 2006.
7 J. Hadden, A. Tiwari, R. Roy, and D. Ruta, "Churn Prediction using
complaints data," Enformatika, Vol. 13, 2006.
8 K. Dasgupta, R. Singh, B. Viswanathan, D. Chakraborty, S. Mukherjea,
A. A. Nanavati, and A. Joshi, "Social ties and their relevance to churn in
mobile telecom networks," in EDBT '08: Proceedings of the 11th
international conference on Extending database technology, (New
York,NY, USA), pp. 668--677, ACM, 2008.
9 P. Kusuma, D. Radosavljevic, F. W. Takes, and P. W. H. van der Putten,
"Combining Customer Attributes and Social Network Mining for
Prepaid Mobile Churn Prediction," Proceedings of the 22nd Belgian
Dutch Conference on Machine Learning (Benelearn), pp. 50-58, 2013.
10 J. Kawale, A. Pal, and J. Srivastava, "Churn prediction in MMORPGs: a
Social Influence Based Approach," CSE '09: International Conference
on Computational Science and Engineering, Vol. 4, pp. 423-428, August
11 Z. H. Borbora, and J. Srivastava, "User behavior modeling approach for
churn prediction in online games," International Conference on Social
Computing (SocialCom) 2012, pp. 51-60, September 2012.
12 C. Bauckhage, K. Kersting, and R. Sifa, "How Players Lose Interest in
Playing a Game: An Empirical Study Based on Distributions of Total
Playing Times," Proceedings of the Conference on Computational
Intelligence and Games (CIG), 2012.
13 F. Hadiji, R. Sifa, A. Drachen, C. Thurau, K. Kersting, and C.
Bauckhage, "Predicting Player Churn in the Wild," Proceedings of the
Conference on Computational Intelligence and Games (CIG), 2014.
14 W. Zucchini, and I. L. MacDonald, Hidden markov models for time
series: An Introduction Using R. Boca Raton, FL: Chapman &
Hall/CRC, 2009.