数据的定位
通过磁道和扇区定位到数据的位置
扇区为512字节

黄色地方数据位置为2磁道3扇区
黑色地方数据位置为1磁道1扇区

通过磁道和扇区还有偏移量定位到数据的位置

比如这里有一张表

bash
由id、name、no、address组成id为主键
列占有大小(字节)
id int 8
name varchar 40
no int 8
address varchar 72
一条记录就占了128个字节。
我们数据有1000条 1000 * 128 = 128,000B
那么是多少扇区呢? 128,000 / 512 = 250 个扇区
意味着我们把1000条数据存入需要250个扇区
如果数据没有索引就要全表扫描,最大读取次数就是250次IO非常慢。
这个时候就有了索引表

索引包括了主键的ID和数据表每个记录的地址。
地址可以通过int 表示。

索引项大小就是8 + 8 = 16B
索引也要存在磁盘上 1000 * 16 = 16000B
16000 / 512 约等于 31个扇区 意味着我们要拿31个扇区存储该索引。
这个时候我们有了索引就是走索引最坏情况就是全部扫了一遍最多31个扇区。
从之前的250个扇区到31个扇区加快了读写效率。
31(获得索引条目) + 1(转到特定块) = 32 个扇区
我们可以在索引上套索引不知道大家是否学习过二级页表。

二级索引可以覆盖一定范围比如id为1在二级索引包含一级索引的id1到id10
100 * 16 = 1600 1600 / 512 约等于4个扇区
那么这个范围一定是10吗?
一个扇区512字节,一个一级索引表项为16字节,512 / 16 = 32 个
意味着一个二级索引表项可以取到32个一级索引表项
一级索引有1000个索引表项 1000 / 32 约等于 31
那就说明二级索引只要有31个索引项就行
31 * 16 = 496 连一个扇区都没装满 只需要一次IO 就可以读取所有
一级索引二级索引都要保存在磁盘上

最后二级索引就变成这样了
那么访问过程是怎样的呢
比如id等于2的时候先一次查找二级索引(IO一次),通过二级索引找到一级索引(IO两次),一级索引里面有0到32范围可以通过二分查找到id等于2的索引,再通过一级索引找到数据(IO三次)
muitl-way search tree - 多路搜索树
原文在这我顺几张图懒得画了(bushi

- 每个节点最多有3个子节点
- 每个节点有2个key关键字

多路搜索树的问题
10 - way search tree
10 key(元素) 9 children(分支)
10 20 30 40 50
这个树就会一直这样连续下去因为没有规则的限制就没有任何意义。
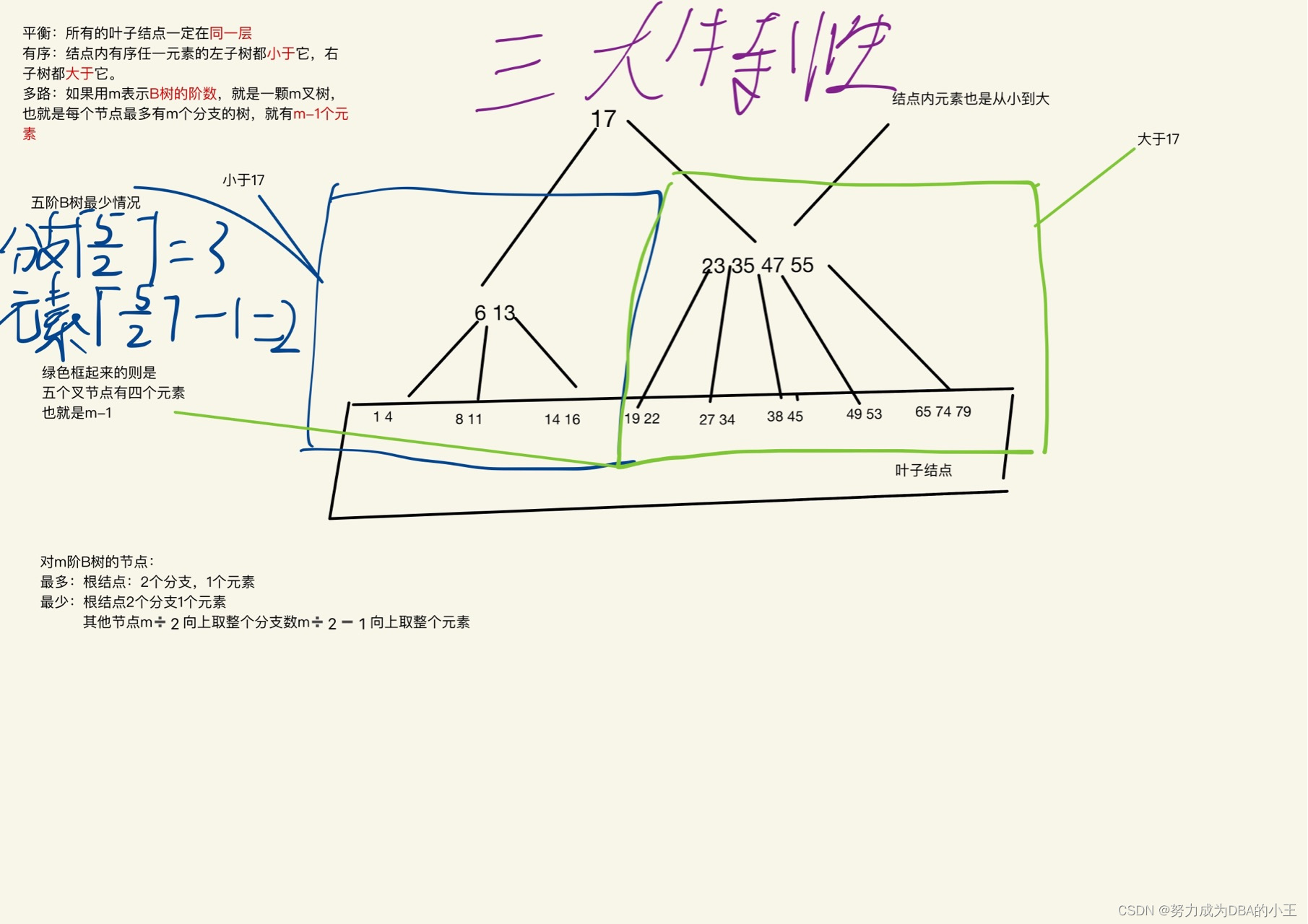
因此B树产生了 比如每个非根节点至少要有m/2向上取整个子节点

B树基础
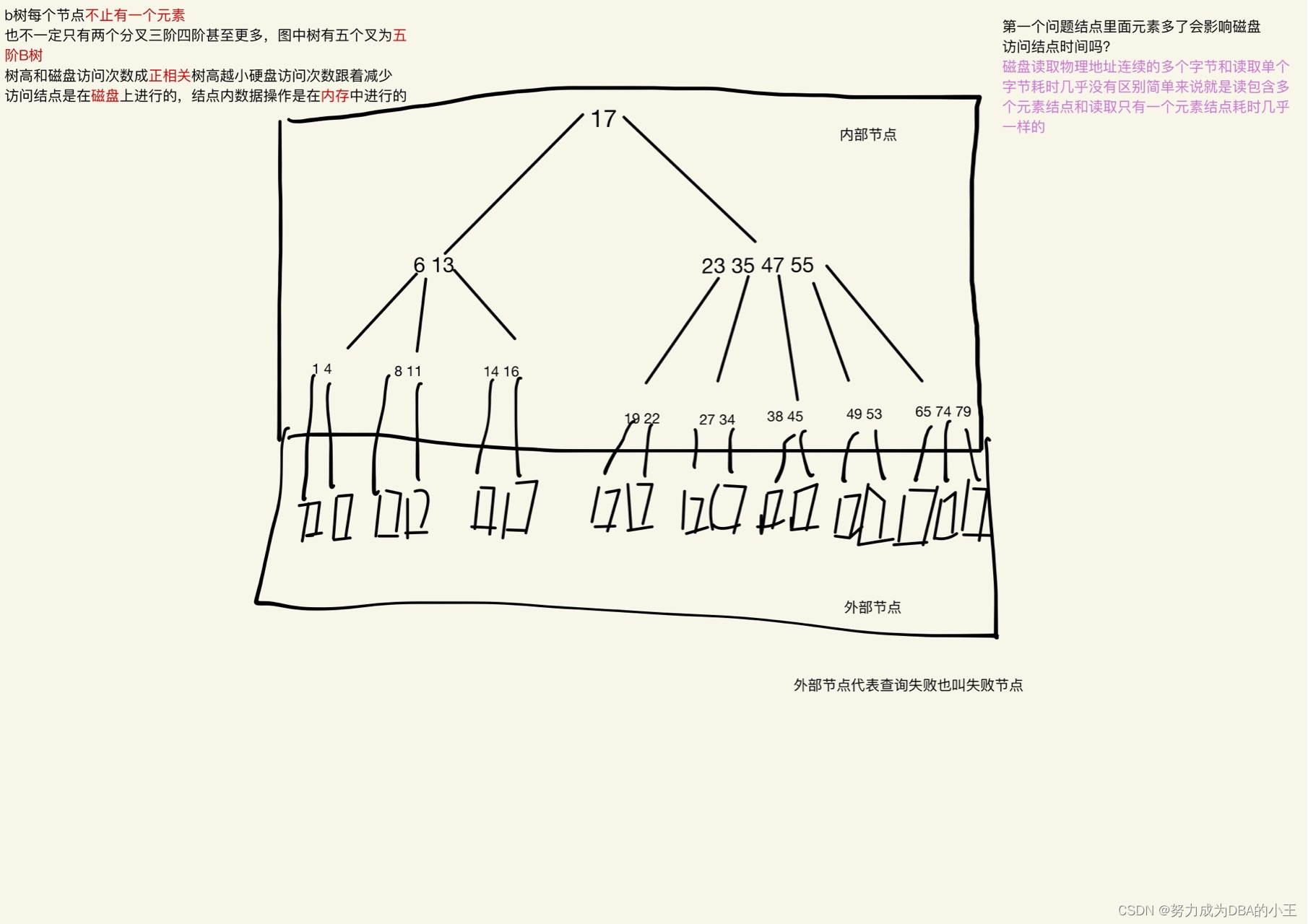
B树特性
B树查找数据
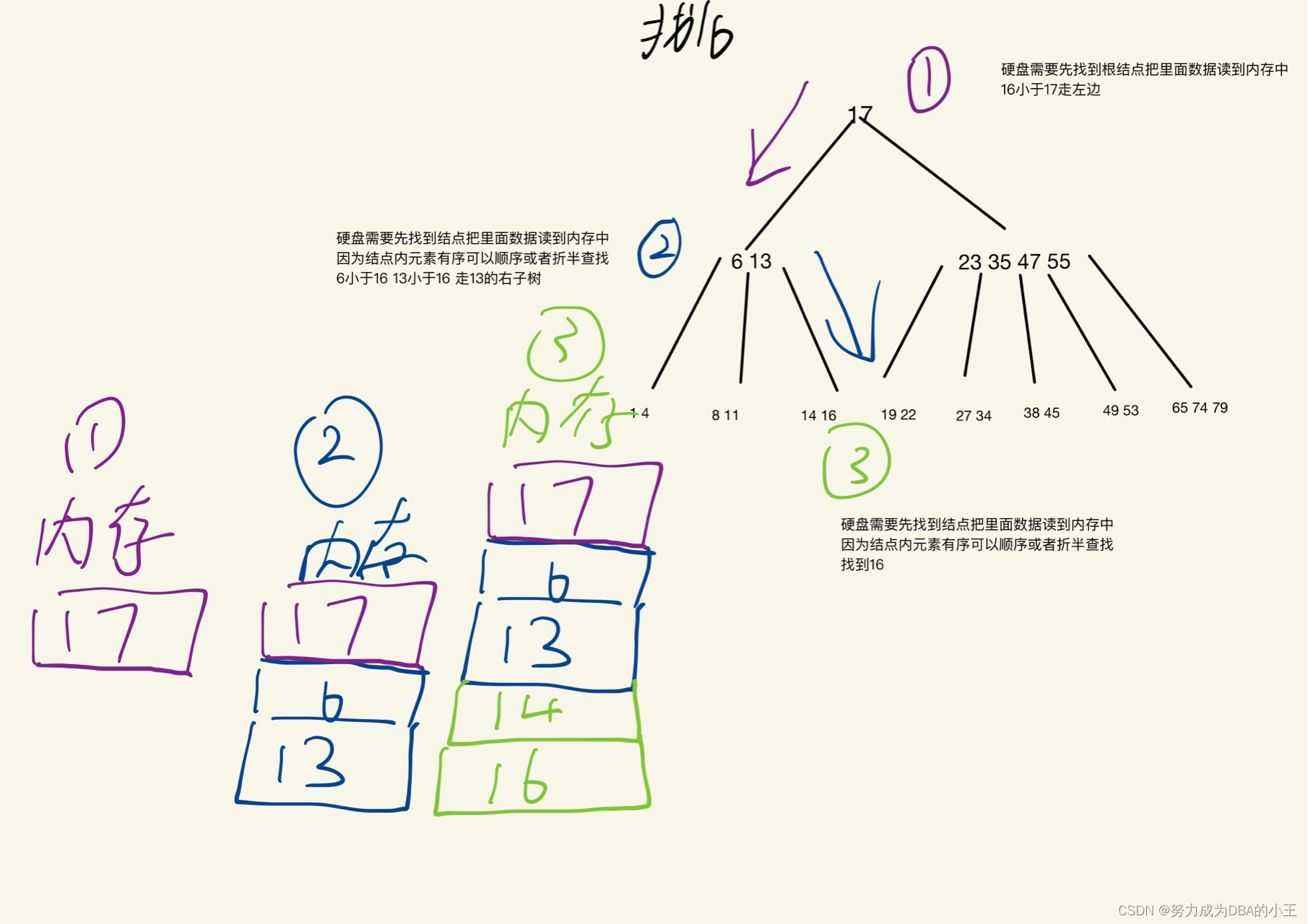
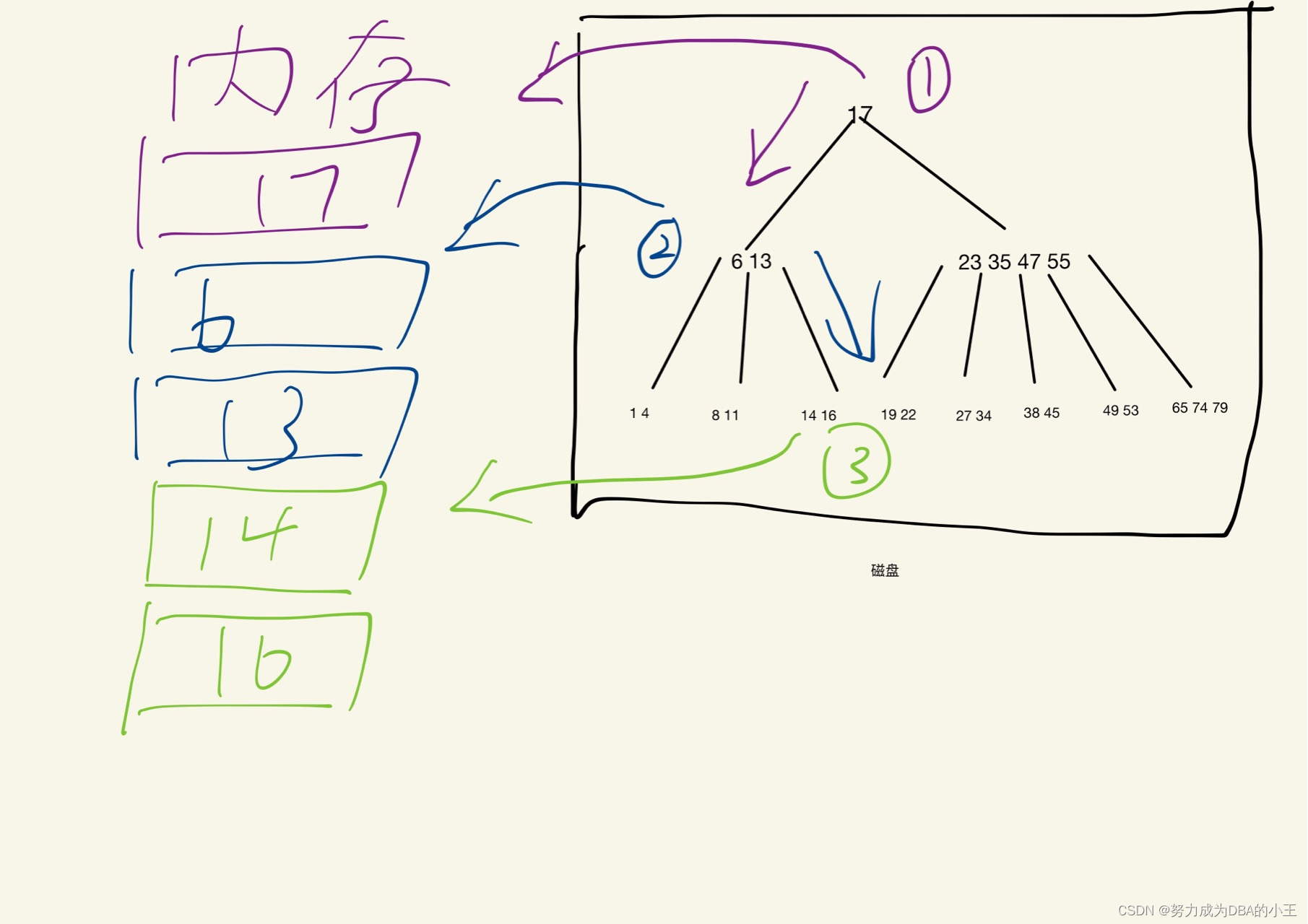
磁盘不会一次性把树都读入内存,而是用到则读。上图进行了三次磁盘的IO。可见树高和磁盘读写是正相关
B树插入
下图是三阶B树最多元素个数为 3(m) - 1 = 2
假如一个节点为3个元素 需要 3(m)/2 向上取整 = 2 把第二个元素上移分裂左右。
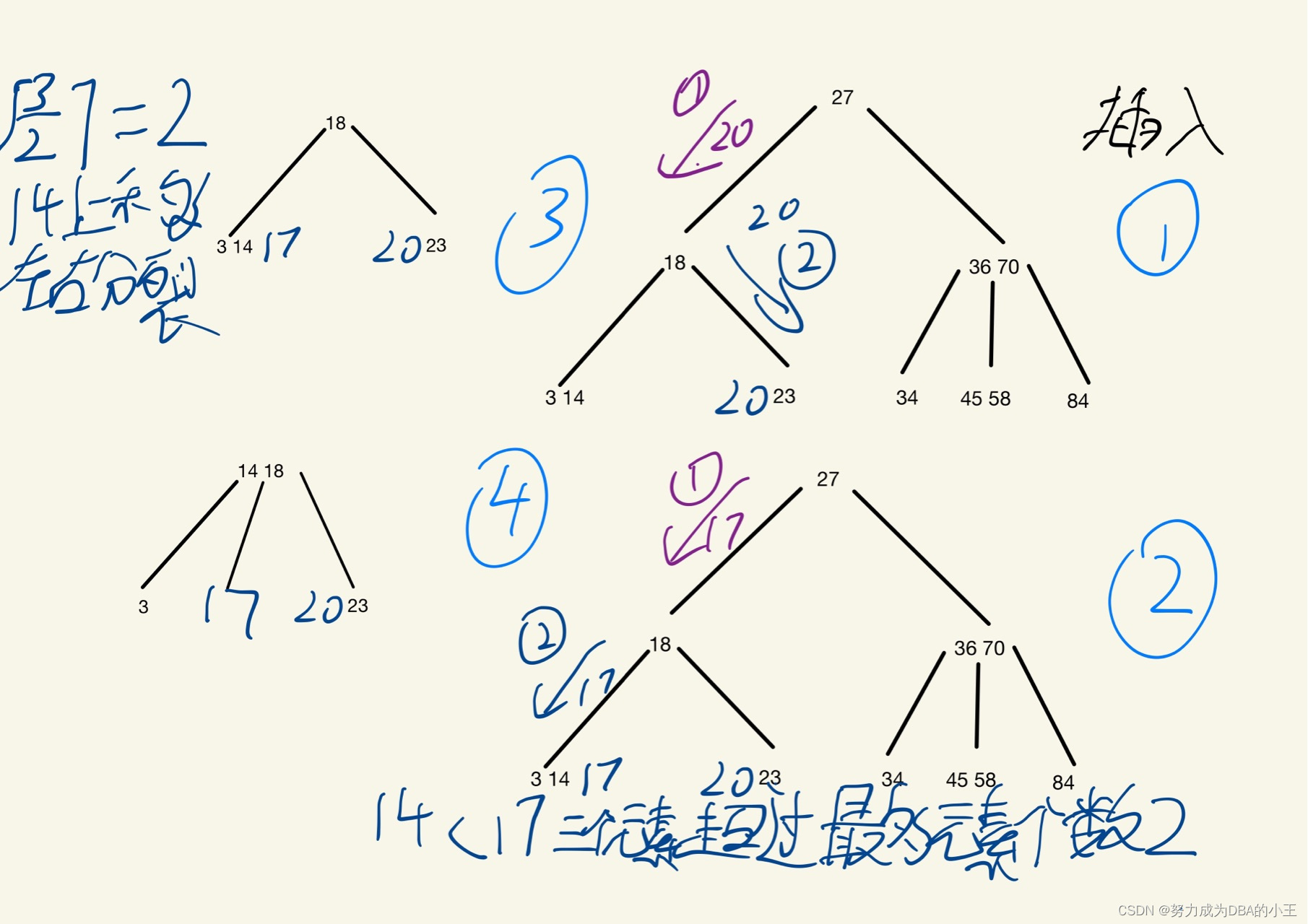
B树构建

B+树介绍
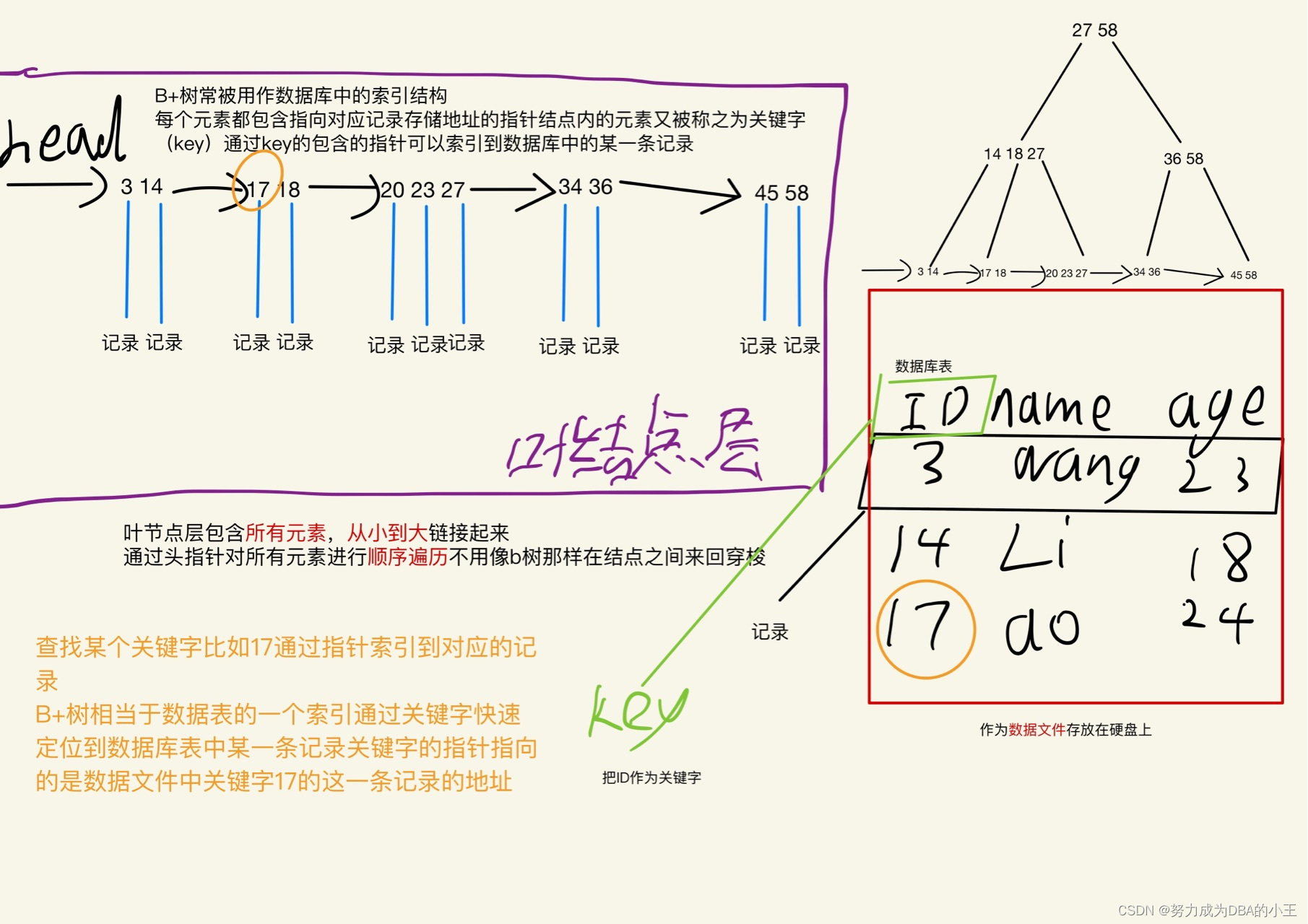
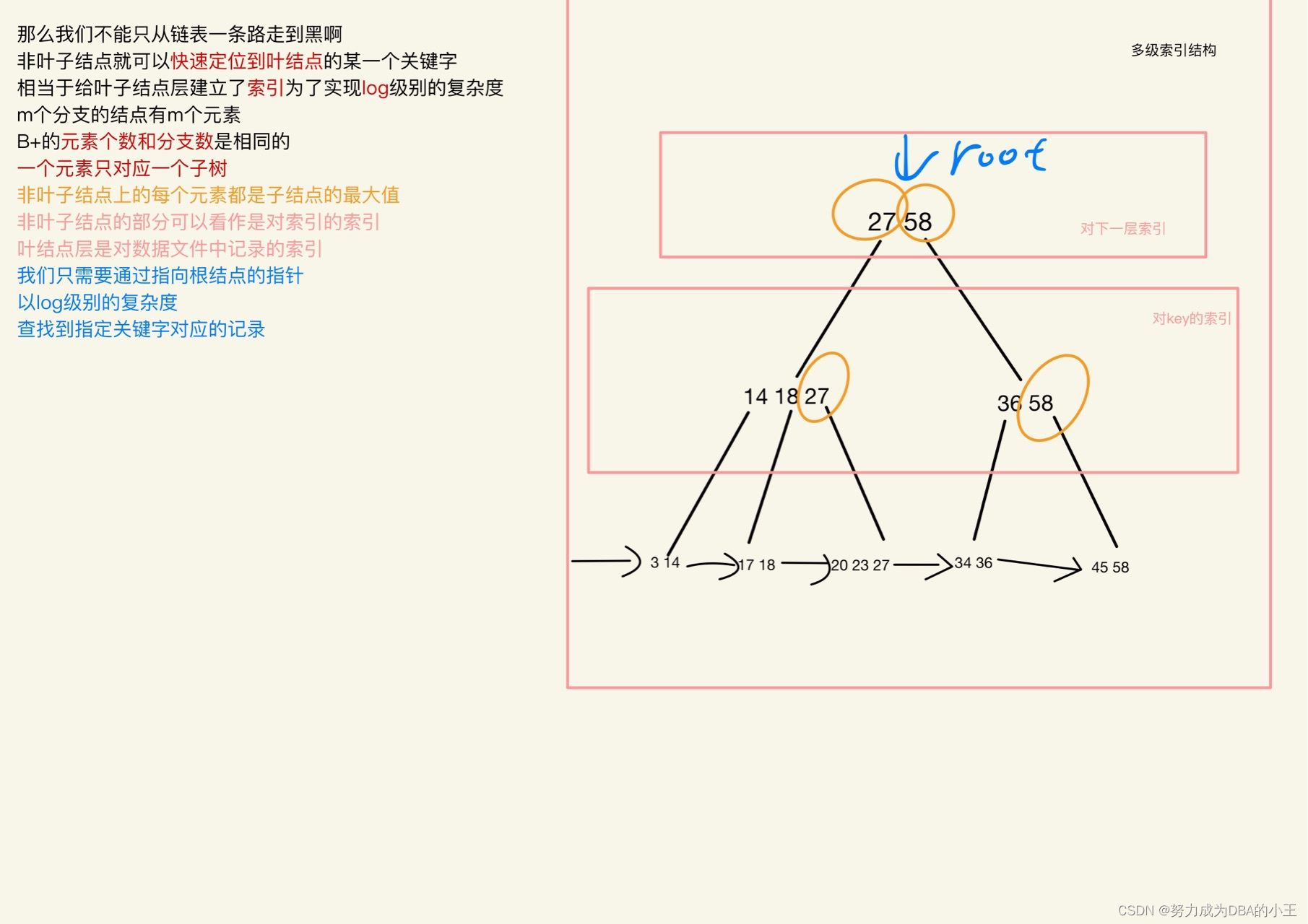
B树和B+树区别
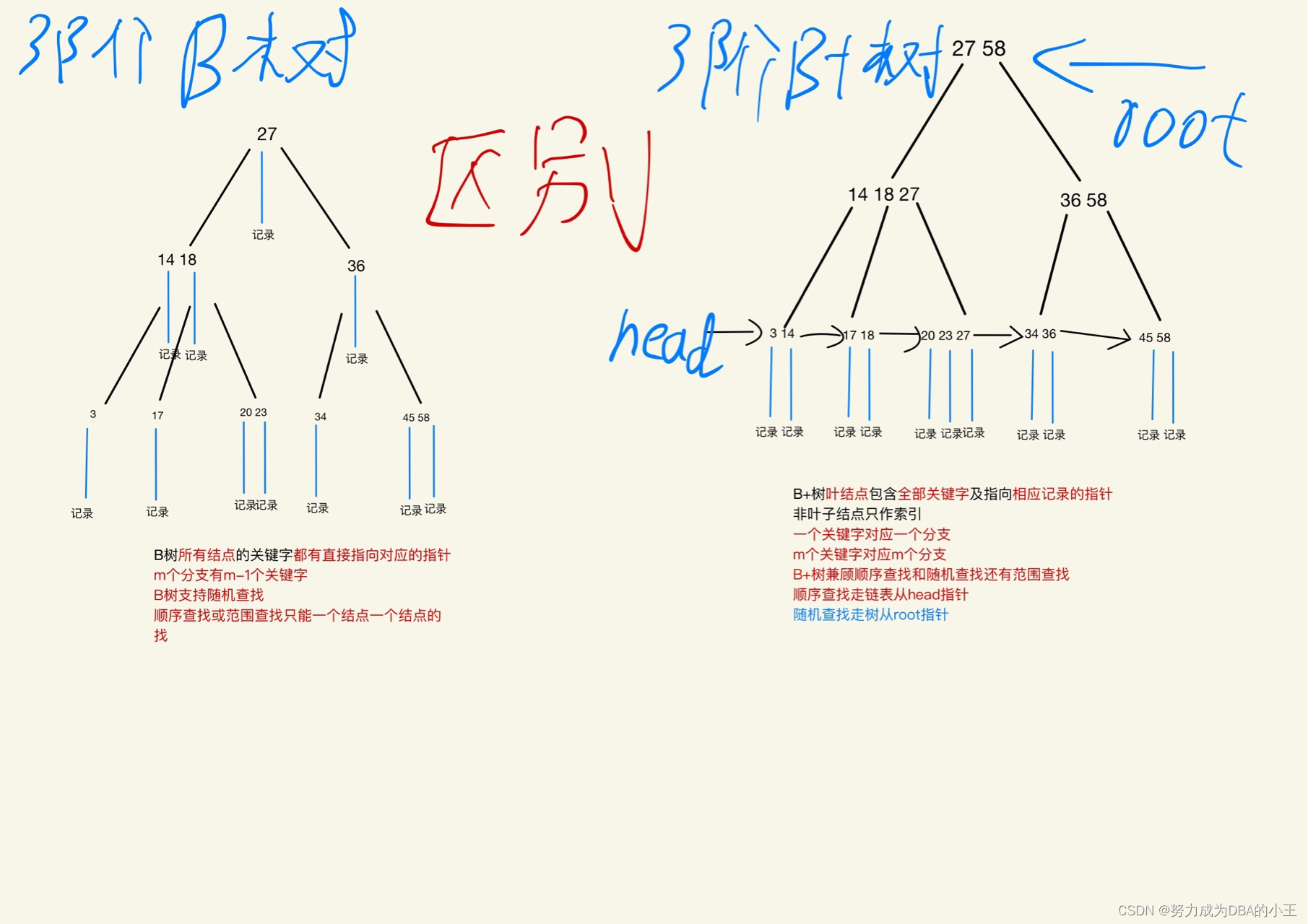
随机查找B+树
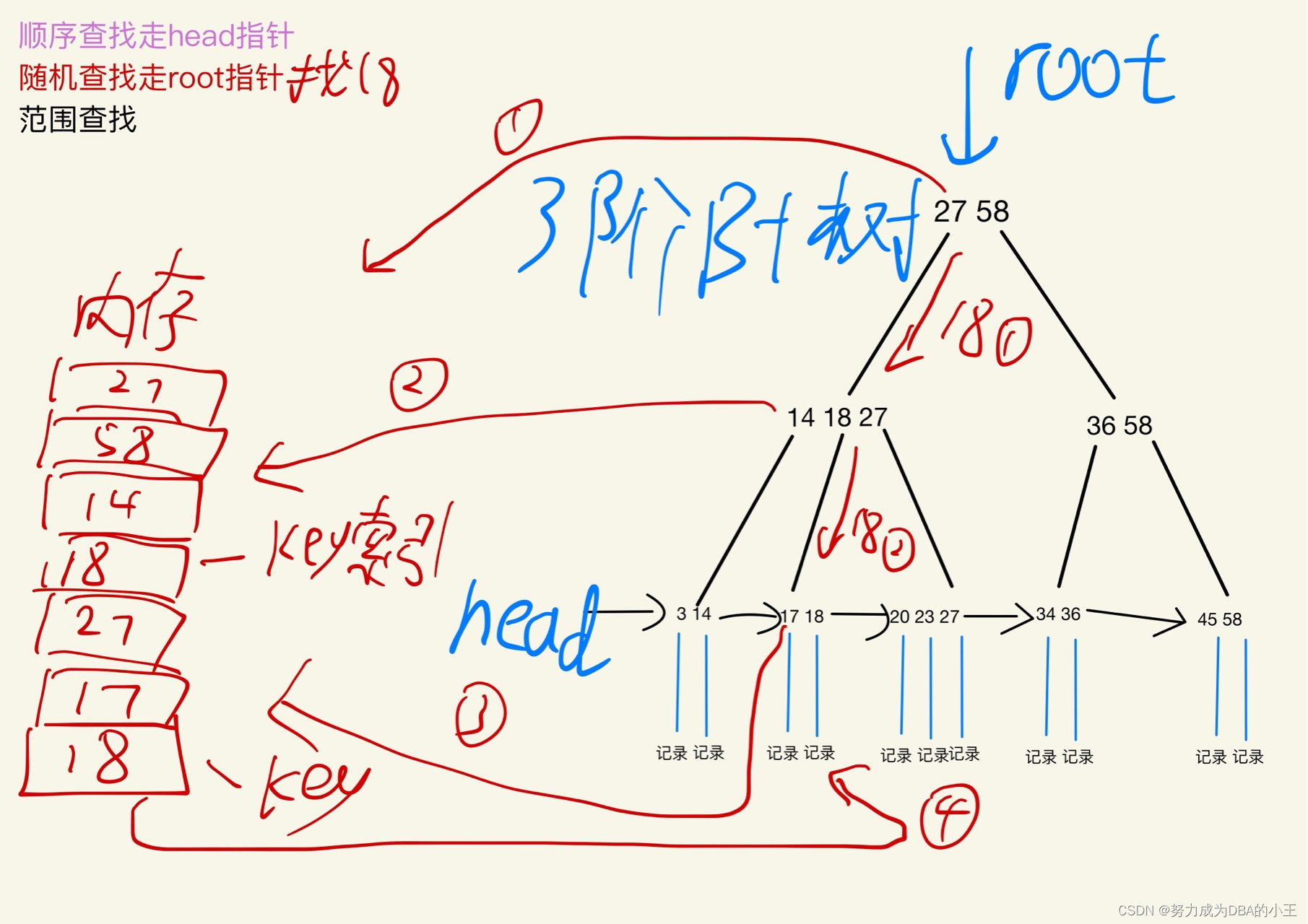
范围查找B+树
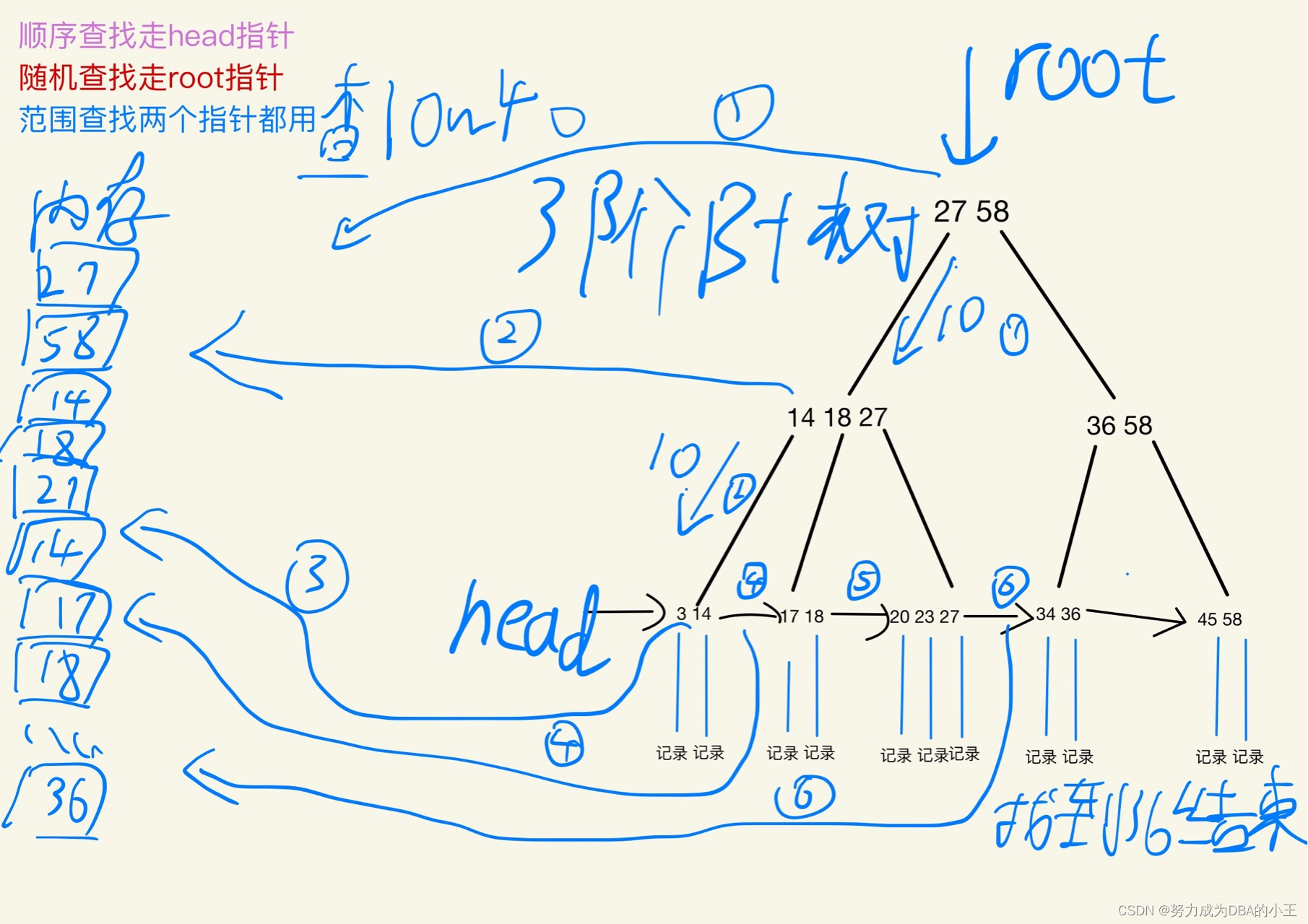
结合mysql数据库理解
操作系统连续读和缓存数据的原理,当一个数据被用到的时候它附近的数据也会被用到。磁盘每一次发生读操作的时候,在找到目标数据之后都会连续读取4 KB的数据。文件系统把一个块的大小定义成了4KB,每次IO操作加载8个扇区的数据到内存中。而MySQL认为4KB太小了,Mysql中最小存储单元是页(16KB),每次IO操作都可以缓存16KB的数据,会把16KB数据放到Buffer Pool中没有ByteBuffer的大小恰好是16KB。

即使32行数据不创建索引 ,在查找数据未必感觉会慢,这个就是顺序读和BufferPool带来的便利,数据太大的时候几百万的时候就不得不创建索引了,在mysql中所有数据都是存储在page里面的。
mysql中统计数据的占用空间用page计算
一个Page(16KB)/一条记录(512B) = 32条记录
SSD一次IO读4KB块读取32条记录需要读4次
假如将ID这列创建索引,索引也要占空间。
假设指令为6B key就是ID
一个Page(16KB)/(key(8B)+指针(6B) = 1170 条索引

1170 * 32 = 37,440条数据

1170 * 1170 * 32 = 43,804,800 条数据
以空间换时间
B+树到底可以存储多少数据呢
在Innodb存储引擎里面,最小存储单元是页,而一个页的大小默认是16KB。

也即代表B+树的每个节点可以存16KB数据,这里我们假设我们的一行数据大小是1KB,那么我们一个节点就可以存16行数据。

非叶子节点存放的是主键值与指针,所以这里假设主键类型为bigint,占用8Byte,指针可以设置为占用6Byte ,总共就为14Byte,这样就可以算出一个节点大概可以存放多少个指针了(指针指向下一层节点),大概为16KB/14Byte=1170个。 这里之前算过了
由此,可以推算出,2层B+树的话,可以存放1170*16=18720行数据。3层B+树的话,可以存放1170*1170*16=21902400行数据 ,也就差不多2000w条数据了。4层B+树的话1170*1170*1170*16,5层B+树 1170 * 1170 * 1170 * 1170 * 16
总结
遍历时候,顺序扫描叶子结点比中序遍历整棵树要快。
B+树的作用是一次IO可以检索更多的数据。 因为树节点中不必存储自己的数据,数据全部存储在叶子节点。树节点的存储数据更小,磁盘一次io能将更多的树节点中的数据读入到内存中,加快检索的效率。
B+树与B树的设计主要用于提高IO速度,也就是读取磁盘的速度。无论是记录查询还是索引查询主要受限于硬盘的I/O速度,查询I/O次数越少,速度越快,所以就产生了B树。B树中每个节点都可以存放表的行记录数据,每个节点的读取可以视为一次I/O读取,树的高度表示最多的I/O次数,在相同数量的总记录个数下,每个节点的记录个数越多,高度越低,查询所需的I/O次数越少.
为了进一步提高磁盘的访问效率,就产生了B+树,B+树与B树最大的不同是内部结点不保存记录数据,只保存关键字,用于查找,所有记录数据都保存在叶子结点中。由于每个非叶子节点只存放关键字,这样节点中能存放的关键字数量就更多,每个节点的扇出数就越大,树的结构就更加矮小,访问磁盘的次数就更少。
基本上是个人理解加参考其他大佬的肯定有很多问题欢迎指正,我会及时修改。
参考文献
1. mysql面试题-深入理解B+树原理_哔哩哔哩_bilibili
B树(B-树) - 来由, 定义, 插入, 构建_哔哩哔哩_bilibili
头条面试:请描述MySQL的B+树索引原理,B+树索引有哪些好处_哔哩哔哩_bilibili
彻底理解B树和B+树!为何它们常用在数据库中?_哔哩哔哩_bilibili
面试官问我为啥B+树一般都不超过3层?3层B+树能存多少数据?redo log与binlog的两阶段提交?_b+树为什么三层-CSDN博客