大家好,我是码哥,《Redis 高手心法》畅销书作者。
在 Java 的世界里,垃圾回收(Garbage Collection,GC)就像一位默默奉献的清洁工,负责清理那些不再被需要的对象。
没有 GC,我们的程序内存迟早会被耗尽。但 GC 的运作并非无代价,不合适的垃圾回收策略可能导致高延迟甚至性能瓶颈。
本章将带你深入理解 JVM 的垃圾回收机制,从垃圾回收算法到收集器设计,再到 GC 日志分析与调优实践。
通过对这些内容的掌握,您将能在高并发场景下为 JVM 选择最佳的垃圾回收管理方案。
进入正文前,介绍下我的《Java 面试高手心法 58 讲》专栏内容涵盖 Java 基础、Java 高级进阶、Redis、MySQL、消息中间件、微服务架构设计等面试必考点、面试高频点。

丢掉你收藏的那些所谓的「面试宝典」,因为它们大多数深度不够,甚至内容还有错误,这也是为何每次面试你都回答不好的原因,你只会看完就忘,还浪费时间。

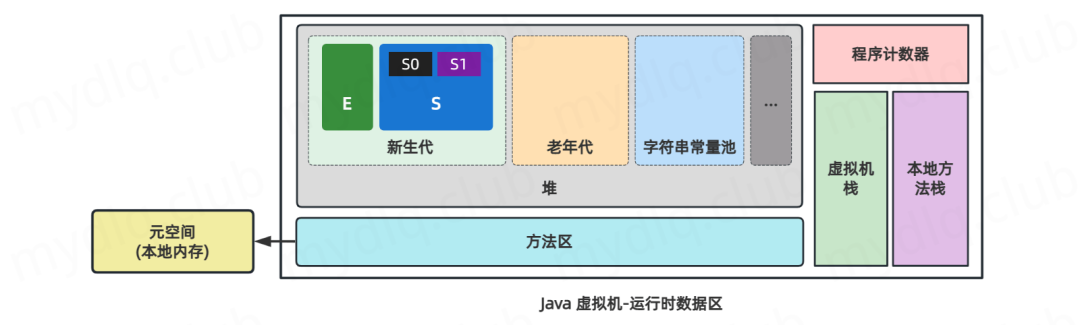
垃圾回收重点关注的区域
在 Java 虚拟机中,垃圾回收机制主要关注于运行时数据区的 "堆空间" 中的数据,其次关注的是 "方法区" 中的数据。
从垃圾回收频率上讲,新生代、老年代、字符串常量池 和 元空间 都是垃圾回收的重点关注区域。
 小豆丁技术栈
小豆丁技术栈
垃圾回收算法
垃圾回收算法是垃圾收集器的基础。JVM 中经典的算法包括标记-清除、复制和标记-整理,它们共同构成了分代垃圾回收策略的理论基础。
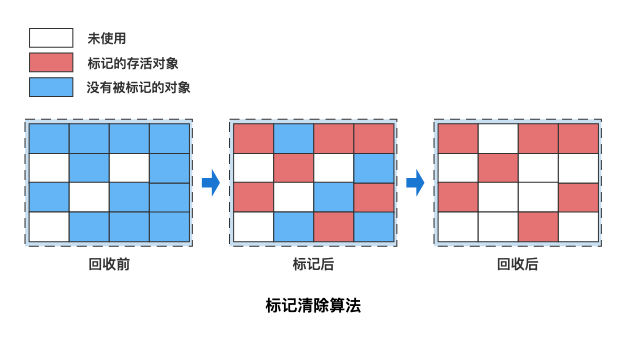
标记-清除算法(Mark-Sweep)
算法原理
标记-清除是最早的垃圾回收算法之一,主要分为两个阶段:
-
标记阶段:从 GC Roots 出发,遍历所有可达对象并将其标记为存活对象。
-
清除阶段:回收未被标记的对象,释放其占用的内存。
 小豆丁技术栈
小豆丁技术栈
优点:实现简单,适合存活对象少的场景。
缺点 :内存碎片化 :未被回收的对象分布不连续,可能导致大对象无法分配;性能低下,需要完整遍历堆,耗时较长。
标记-清除算法通常用于老年代的垃圾回收,适合生命周期较长、存活率高的对象。
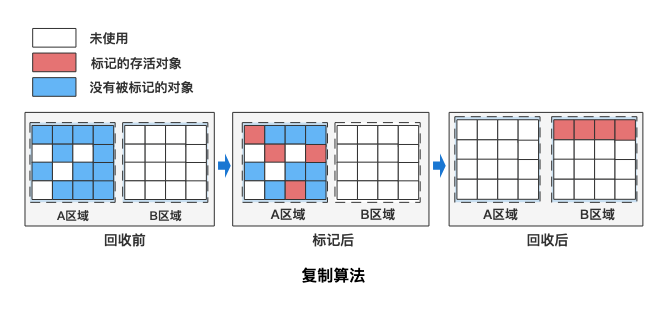
复制算法(Copying)
复制算法将堆分为两块相等的内存区域(From 和 To)。每次 GC 时,只扫描 From 区,将存活对象复制到 To 区,最后清空 From 区。
 小豆丁技术栈
小豆丁技术栈
优点:没有碎片化问题,内存分配效率高。
缺点:浪费内存:需要额外空间保存对象;不适合老年代,存活对象多时复制成本高。
复制算法通常用于新生代回收,新生代对象存活率低,复制成本较低。
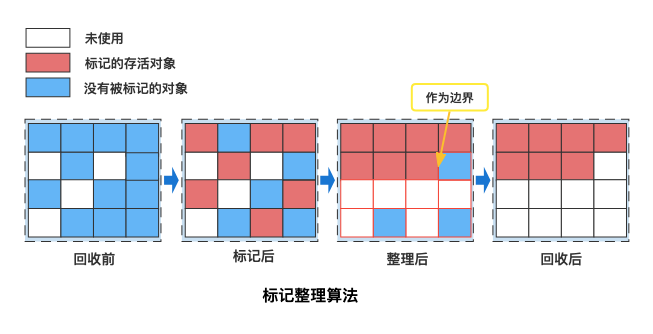
标记-整理算法(Mark-Compact)
标记-整理(Mark-Compact)是标记-清除的改进版,标记阶段相同,但清除阶段会将存活对象移动到内存的一端,然后清理剩余空间。
 小豆丁技术栈
小豆丁技术栈
优点:消除了内存碎片。不需要额外空间。
缺点:对象移动成本较高。
标记-整理算法通常用于老年代回收,解决老年代内存碎片问题。
分代收集算法
上面所介绍的 标记清除算法、复制算法 和 标记整理算法,它们各自都具有自己独特的优势和特点,每种算法都有各自相适应的场景,没有一种算法可以完全替代另一种算法。
在这样的背景下 分代收集算法 孕育而生,由于每个对象的生命周期各不相同,有的对象可以长期存活,有的对象朝生夕灭。
因此,针对不同生命周期的对象,可以采取不同的回收方式来提高回收效率。
在一般情况下,市面上大多数 Java 虚拟机中的 GC 都采用分代收集,即将 堆空间 划分为 新生代 和 老年代,不同生命周期的对象放到不同的区域中进行存储,并且针对不同的区域采用不同的回收策略,这就是我们常说的 分代收集 (Generational Collection)。
垃圾收集器深入解析
JVM 中的垃圾收集器基于上述算法设计,针对不同场景优化性能。接下来,我们深入剖析常见收集器的实现原理和应用场景。
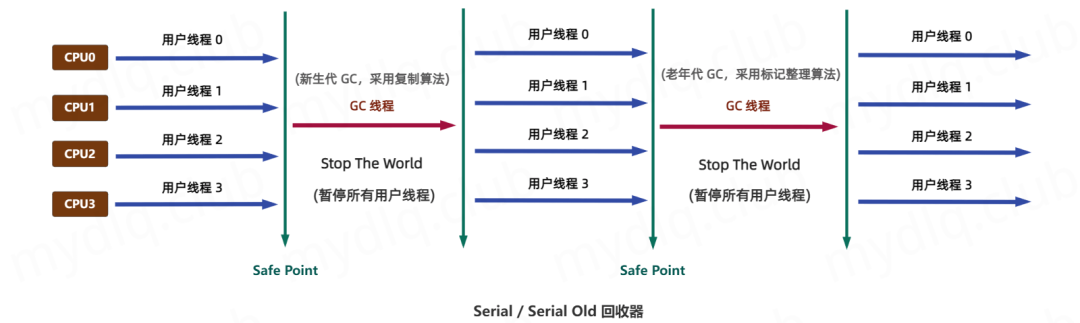
Serial 收集器
Serial 收集器是单线程收集器,采用复制算法回收新生代,标记-整理算法回收老年代。GC 时会 Stop-The-World(STW),暂停所有应用线程。
 小豆丁技术栈
小豆丁技术栈
特点
-
实现简单,单线程操作效率高。。
-
使用 复制算法 回收新生代,标记-整理算法 回收老年代。
-
没有线程切换的开销。
-
GC 时应用完全暂停,延迟较高。
适用于单线程应用或内存占用较小的场景,如嵌入式设备和简单的命令行工具。
-XX:+UseSerialGC: 启用 Serial 新生代和 Serial Old 老年代回收器。
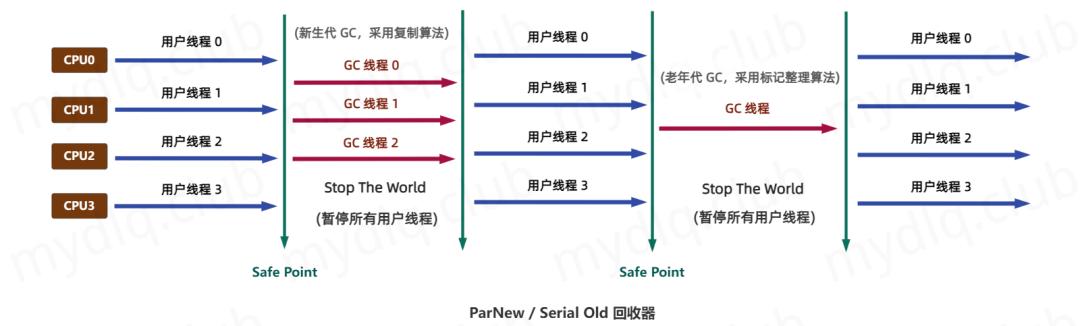
ParNew 回收器
arNew GC 是一款并行回收器,除了在进行垃圾回收时使用多线程并发执行外,其它方面几乎和 Serial GC 一致,包括 回收算法、Stop The World、对象分配规则 和 回收策略 等,因此常称 ParNew GC 为 Serial GC 的多线程版本。
不过 ParNew GC 属于新生代回收器,只能对新生代中的对象进行回收。
 小豆丁技术栈
小豆丁技术栈
◆ 优点:
-
① 支持并行回收: ParNew GC 支持多线程并行进行回收,可以利用多核 CPU 的优势,提高垃圾回收的效率;
-
② 回收效率高且停顿时间短: ParNew GC 是一个专门用于回收年轻代的垃圾垃圾回收器,使用的是复制算法,并且回收的空间比价小,所以回收效率高且停顿时间短;
◆ 缺点:
-
① 浪费部分内存空间: ParNew GC 使用的是复制算法,需要将内存空间拆成两份,每次只使用其中一份内存空间存储对象,所以比较浪费内存空间;
-
② 老年代垃圾回收效率低: 由于 ParNew GC 只用于年轻代垃圾回收,而不处理老年代垃圾回收,因此老年代的垃圾回收效率低下,容易导致 Full GC;
ParNew 回收器常配置参数。
-
-XX:+UseParNewGC: 启用新生代回收器 ParNew。
-
-XX:ParallelGCThreads: 配置 GC 的线程数量,通常推荐该值和 CPU 核心数量保持一致。
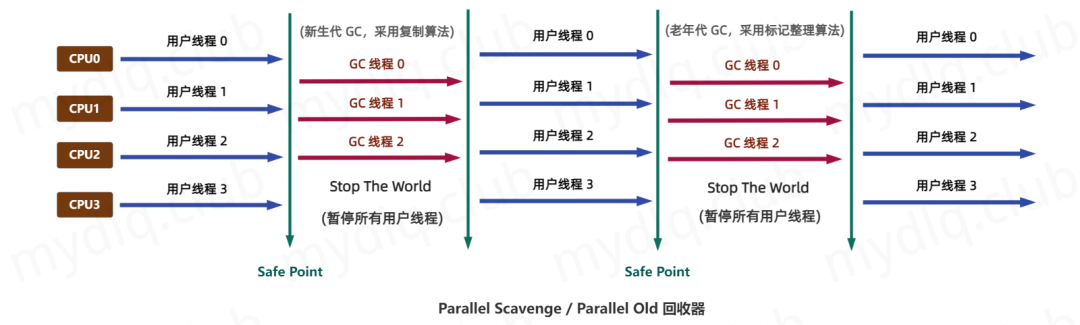
Parallel 收集器
Parallel 收集器使用多线程并行回收新生代(复制算法)和老年代(标记-整理算法),以提高吞吐量。
 小豆丁技术栈
小豆丁技术栈
特点
-
多线程并行回收,适合多核 CPU。
-
优化吞吐量,回收时应用暂停时间较长。
-
STW 时间较长,对低延迟场景不友好。
适用于吞吐量优先的后台任务,如大数据处理和批量计算。
Parallel 回收器常配置参数
-
-XX:+UseParallelGC: 启用新生代回收器 Parallel Scavenge。
-
-XX:+UseParallelOldGC: 启用老年代回收器 Parallel Old。
-
-XX:ParallelGCThreads: 配置 GC 的线程数量,通常推荐该值和 CPU 核心数量保持一致。
-
-XX:MaxGCPauseMillis: 配置 GC 回收最大停顿时间,即 Stop The World 时间。
-
-XX:GCTimeRatio:配置 GC 回收时间占总时间的比例,用于衡量吞吐量的大小,取值范围为 0-100,默认值为 99,也就表示垃圾回收时间不超过 1%。
- 该参数与 -XX:MaxGCPauseMillis 参数有一定矛盾性,因为设置较短的停顿时间可能会导致更多的 GC 次数,从而增加总的 GC 时间,使得 GCTimeRatio 容易超过设定的比例。
-
-XX:+UseAdaptiveSizePolicy:
配置 Parallel Scavenge 回收器具有自适应调节策略。
-
在这种模式下,新生代 Eden 和 Survivor 的比例、晋升老年代的对象年龄等参数会被自动调整,期望在堆大小、吞吐量和停顿时间之间达到最佳平衡。
-
在手动调优比较困难的场合,可以直接使用这种自适应的方式,仅指定虚拟机的最大堆、目标的吞吐量 (GCTimeRatio) 和停顿时间 (MaxGCPauseMillis),让虚拟机自己完成调优工作。
-
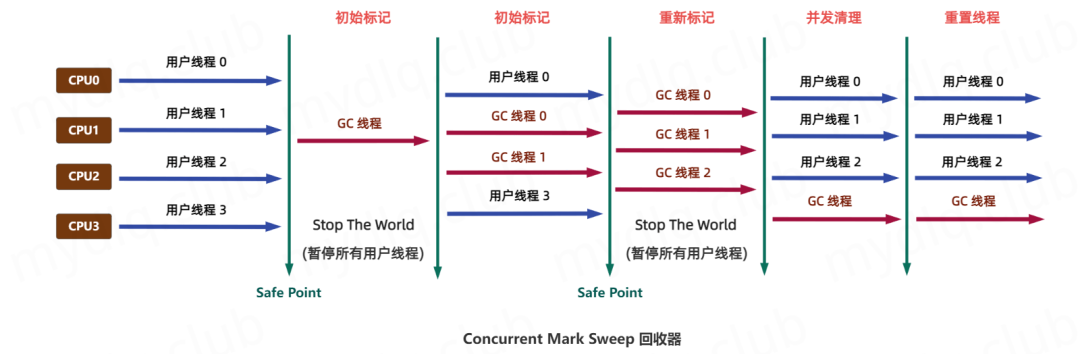
CMS 收集器
CMS 收集器使用并发回收方式,降低 STW 时间,这款回收器是 HotSpot 虚拟机中第一款真正意义上的并发回收器,它第一次实现了让垃圾收集线程与用户线程同时工作。
CMS GC 是一款老年代回收器,其主要回收目标就是老年代中的对象,使用的是标记清除算法。
老年代回收分为四个阶段:
-
初始标记:标记 GC Roots 可达的对象(STW)。
-
并发标记:并发扫描对象引用关系(无 STW)。
-
重新标记:处理并发期间新增的对象(STW)。
-
并发清除:清理无效对象(无 STW)。
 小豆丁技术栈
小豆丁技术栈
特点
-
并发回收,减少暂停时间。
-
存在内存碎片化问题。
-
并发时可能影响应用性能。
适用于响应时间敏感的场景,如 Web 应用和在线交易系统。
CMS 回收器可配置参数:
-
-XX:+UseConMarkSweepGC: 启用 CMS 老年代回收器。
-
-XX:ParallelcMSThreads: 设置 CMS GC 执行时的线程数量。
-
-XX:CMSInitiatingOccupanyFraction: 设置堆内存使用率的阈值,一旦达到该阈值,便开始进行回收。
-
-XX:+UseCMSCompactAtFullCollection: 设置是否在执行完 Full GC 前对内存空间进行压缩整理,以此避免内存碎片的产生。
-
-XX:CMSFullGCsBeforeCompaction: 设置在执行多少次 Full GC 后对内存空间进行压缩整理。
4.2.4 G1 收集器
G1 将堆划分为多个固定大小的 Region,每个 Region 都是连续的一段内存区域,大小在 1MB ~ 32MB 之间,且为 2 的 N 次幂,具体大小根据堆的实际大小而定。
并且每个 Region 扮演着不同的角色,比如可以是 Eden 区、Survivor 区、Old 区或 Humongous 区等,通过全局标记统计每个 Region 的垃圾量,优先回收垃圾最多的 Region,降低停顿时间。
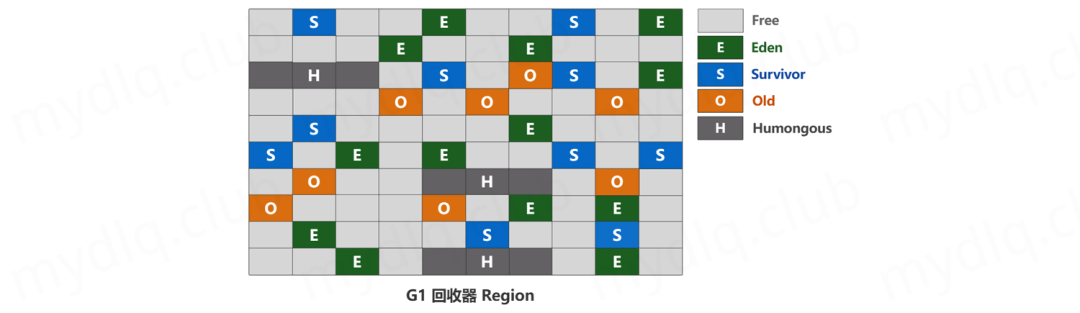 小豆丁技术栈
小豆丁技术栈
G1 回收器整体使用的是 标记-整理算法,局部使用的是 复制算法。
在 G1 中支持三种回收模式,分别为 Young GC、Mixed GC 和 Full GC:
-
Young GC: 对新生代中的 Region 进行回收。当新生代的空间不足时会触发 Young GC,回收新生代中的垃圾对象。
-
Mixed GC: 这是一种混合回收模式,不仅回收新生代中的 Region,还会回收部分老年代中的 Region。这种模式旨在减少 Full GC 的频率,通过定期回收部分老年代 Region 来降低整个堆的垃圾积累。
-
Full GC: 对整个堆空间的所有 Region 进行回收,包括新生代和老年代。Full GC 通常在 G1 无法通过 Mixed GC 清理足够的空间时触发,或者在某些特殊情况下触发 (如系调用 system.gc() 方法触发)。
G1 回收器优缺点
◆ 优点:
-
可预测的停顿时间: G1 GC 将堆空间分成多个大小相等的 Region (区域),这些 Region 可以作为 Eden 区、Survivor 区或 Old 区等。通过在多个 Region 中执行并发垃圾收集,G1 能够实现可预测的停顿时间,这意味着垃圾收集的停顿时间可以预测和控制;
-
高效的内存回收: G1 GC 使用增量式的垃圾收集算法,不仅在特定区域中进行垃圾回收,还在整个堆中进行。这种全局性的垃圾回收方式使得 G1 能够高效地回收内存,并减少垃圾收集的停顿时间;
-
优化的内存分配: G1 GC 使用了一种名为 Remembered Set 的数据结构,可以追踪对象之间的引用,从而在内存分配时避免扫描整个堆。这一特性可以显著减少内存分配的时间;
-
空间整理: G1 GC 通过对未使用的 Region 进行空间整理,将零散的空闲空间合并成更大的连续空间块,从而优化内存使用,提高堆的利用率;
◆ 缺点:
-
对硬件资源要求较高: G1 GC 需要在多核 CPU 和大内存环境下运行才能充分发挥其优势。如果在较小的硬件资源上运行,可能会导致运行缓慢或 OutOfMemoryError 等问题;
-
初始标记和最终标记的时间较长: G1 GC 的初始标记和最终标记阶段需要单线程执行,并且会暂停应用程序。在处理大型内存空间时,这两个阶段可能会导致较长的停顿时间;
-
混合收集过程可能会影响吞吐量: G1 GC 的混合收集过程涉及多次暂停应用程序,这可能会对应用程序的吞吐量产生一定的影响;
总结
最后,也向大家介绍下我的新书《Redis 高手心法》。本书基于 Redis 7.0 版本,拟人故事化方式和诙谐幽默的言语与各路"神仙"对话。



通过本章的学习,我们讲解了垃圾回收算法、收集器实现及调优技巧。
不同场景下选择合适的 GC 策略和参数,是优化高并发应用性能的关键。
你们在面试中是否遇到过 GC 性能调优问题?欢迎在评论区分享你的经验和问题。
往期推荐
<>
什么是 JVM?JVM 为什么是开发者必须了解的核心技术?
<>
<>
Redis 7.0 深度探秘:List 数据结构原理与实战指南
<>
<>
面试官拷打:Redis 高可用篇章中面试最常见的 6 个问题!
<>
<>
重生之MySQL SQL 执行的 7 大关键步骤,解锁新技能
<>
<>
参考资料