文章目录
- [1、Algorithm concept](#1、Algorithm concept)
- [2、Algorithm principle](#2、Algorithm principle)
-
- [(1)The Construction of Trees](#(1)The Construction of Trees)
- [(2)Division selection](#(2)Division selection)
-
- [1、Information gain](#1、Information gain)
- [2、gini index](#2、gini index)
- [3、chi-square test](#3、chi-square test)
- [(3)Stopping criteria](#(3)Stopping criteria)
- [(4)Pruning treatment](#(4)Pruning treatment)
- [3、Advantages and disadvantages of decision trees](#3、Advantages and disadvantages of decision trees)
- 4、决策树分类任务实现对比
-
- [(1)Data Load](#(1)Data Load)
- [(2)Sample partitioning](#(2)Sample partitioning)
- [(3)model training](#(3)model training)
- (4)Evaluation
- [(5)Model visualization](#(5)Model visualization)
- [5、Comparison of Decision Tree Regression Task Implementation](#5、Comparison of Decision Tree Regression Task Implementation)
-
- [(1)Data loading and sample partitioning](#(1)Data loading and sample partitioning)
- [(2)model training](#(2)model training)
- (3)Evaluation
- [(4)Model visualization](#(4)Model visualization)
- 6、summarize
1、Algorithm concept
Firstly, we need to understand what a decision tree is?
Developing a simple algorithm to sort the three elements A, B, and C requires breaking down the problem into smaller sub problems. Firstly, consider whether A is smaller than B. Next, if B is less than C, then things will become interesting: if A<B and B<C, then obviously A<B<C. But if B is not less than C, the third question becomes crucial: Is A less than C? Perhaps it would be better to solve this problem in a graphical way
So, we can draw a node for each question and an edge for each answer, with all leaf nodes representing a possible correct sorting. The following figure shows the decision tree diagram we have drawn:

This is the first decision tree we have created. To make the right decision, two to three if statements are required, therefore, the algorithm flow is as follows:

Sorting code:
python
def sort2(A, B, C):
if (A < B) and (B < C) : return [A, B, C]
if (A < B) and not (B < C) and (A < C): return [A, C, B]
if (A < B) and not (B < C) and not (A < C): return [C, A, B]
if not (A < B) and (B < C) and (A < C): return [B, A, C]
if not (A < B) and (B < C) and not (A < C): return [B, C, A]
if not (A < B) and not (B < C) : return [C, B, A]As expected, the sorting problem provided us with 6 rules corresponding to 6 different permutation combinations, and the final result was consistent with the decision tree algorithm. This simple example demonstrates four important characteristics of decision trees:
1. Very suitable for classification and data mining.
2. Intuitive and easy to understand.
3. It is relatively easy to implement.
4. Suitable for different populations.
This further demonstrates the efficiency and usability of decision trees in handling simple sorting or classification problems.
A tree is a directed connected graph with a root node. Each other node has a predecessor node (parent node) and no or multiple successor nodes (child nodes). A node without successors is called a leaf. All nodes are connected by edges. The depth of a node is the number of edges on the path to the root. The height of the entire tree is the number of edges along the longest path from the root to any leaf.
A decision tree is a tree like structure, with the corresponding relationships between its elements as follows:
| tree structure | Corresponding elements in the decision tree |
|---|---|
| Root node | Initial decision node |
| node | Internal decision nodes used for testing attributes |
| side | Rules to be followed |
| Leaf node | Terminal nodes representing result classification |
The input of a machine learning algorithm consists of a set of instances (such as rows, examples, or observations). Each instance is described by a fixed number of attributes (i.e. columns) and a label called a class (in the case of classification tasks), which are assumed to be nominal or numerical. The collection of all instances is called a dataset.
According to this definition, we obtain a table containing the dataset: each decision becomes an attribute (all binary relationships), all leaves are classes, and each row represents an instance of the dataset. As shown in the following figure:

Data is collected in tabular form (such as a database) and decision trees must be generated. The reason why there are now eight classes instead of six is simple: for instances 1, 2 and 7, 8, it doesn't matter whether A<B or not, the result is the same. The effect of removing unrelated branches from a tree is called pruning.
2、Algorithm principle
(1)The Construction of Trees
The core idea of tree based classification methods originates from a concept learning system. The series of algorithms that will be introduced next are all based on a simple but very powerful algorithm called TDIDT, which stands for "top-down inductive decision tree". The framework of this algorithm includes two main methods: decision tree growth and pruning. These two methods will be demonstrated in detail in the following two pseudocodes, following the divide and conquer principle.
By recursively splitting the feature space, a complex decision tree is created to achieve a high degree of fit on the training data. Its purpose is to maximize the accuracy on the training data. The construction process of decision tree:

By removing unnecessary nodes to simplify the tree structure and prevent overfitting, the goal is to improve the model's generalization ability to new data. The construction process of decision tree:
(2)Division selection
In the process of building a decision tree, partition selection (also known as split selection) is a key step in determining how to partition nodes based on the characteristics of the data. This process involves selecting a feature and corresponding segmentation threshold or category, so that the dataset is segmented into as pure a subset as possible at that node. Different partitioning selection methods use different criteria to measure the quality of data segmentation. Let N training samples be:

1、Information gain
The idea of entropy and information gain is based on Claude Elwood Shannon's information theory proposed in 1948. Information gain is based on the concept of entropy. Entropy is a measure of uncertainty or chaos in a dataset. The goal of information gain is to reduce this uncertainty by partitioning the data.
The definition of entropy is as follows:

Information gain is the decrease in entropy before and after partitioning:

Among them, the first term is entropy, and the second term is the weighted entropy of child nodes. Therefore, this difference reflects a decrease in entropy or information obtained from the use of attributes.
2、gini index
The Gini index measures the difference between the probability distributions of target attribute values, defined as follows:

The goal is to find the purest node, which is an instance with a single class. Similar to the reduction of entropy and gain information used in information gain based standards, the selected attribute is the one with the most impurity reduction.
3、chi-square test
The chi square statistic (χ 2) standard is based on comparing the frequency values of a category obtained due to splitting with the prior frequency of that category. The formula for calculating the value of x2 is:

Among them,
It is the prior frequency of sample N in k. The larger the chi square value, the more uniform the segmentation, indicating a higher frequency of instances from a certain class. Select attributes based on the maximum value of x2.
The quality of partition selection directly affects the performance of decision trees. Choosing appropriate partitioning criteria can help generate better decision trees, improve model prediction accuracy, and reduce the risk of overfitting. In practical applications, information gain and Gini index are the most common choices, and the specific method used often depends on the type of task (classification or regression) and the nature of the data.
(3)Stopping criteria
In the process of building a decision tree, the stopping criteria determine when to stop splitting nodes. Reasonable stopping criteria can prevent decision trees from overfitting data, generating overly complex tree structures, and also help improve the model's generalization ability. The following are several commonly used stopping criteria for decision trees:
- All instances in the training set belong to a single y-value.
-The maximum tree depth has been reached.
-The number of cases in the terminal node is less than the minimum number of cases in the parent node.
-If a node is split, the number of instances in one or more child nodes will be less than the minimum number of instances in the child nodes.
-The optimal segmentation criterion is not greater than a certain threshold。
(4)Pruning treatment
Using strict stopping criteria often creates small and inappropriate decision trees. On the other hand, using loose stopping criteria often generates large decision trees that overfit the training set. To avoid these two extremes, people have proposed the idea of pruning: using loose stopping criteria, after the growth stage, by removing sub branches that do not contribute to generalization accuracy, overfitting trees are pruned back to smaller trees.
1、pre-pruning
Pre pruning is the process of stopping the splitting of nodes in advance during the construction of a decision tree. When certain stopping conditions are met, no further node splitting occurs, which prevents the tree from overgrowth. Common pre pruning strategies include:
- Maximum depth limit: Presets the maximum depth of the tree, and once the tree reaches this depth, it stops splitting further.
- Minimum sample size limit: The minimum number of samples that must be included in each leaf node, and splitting stops when the number of samples in the node is below this threshold.
- Minimum information gain or Gini gain limit: If the information gain or Gini gain caused by splitting is below a certain threshold, the splitting will be stopped.
- Purity threshold of leaf nodes: If the proportion of a certain category in a node exceeds a preset threshold, the splitting will be stopped and the node will be treated as a leaf node.
The advantages of pre pruning:
High computational efficiency: As pruning is performed during the decision tree generation process, unnecessary splitting can be reduced, thereby accelerating model training.
Reduce overfitting: Pre pruning can effectively prevent decision trees from overfitting training data by stopping splitting in advance.
Disadvantages of pre pruning:
Risk of underfitting: Pre pruning may prematurely stop splitting, causing the decision tree to not fully learn the patterns in the data, resulting in underfitting problems.
2、post-pruning
Post pruning refers to building a complete decision tree first, and then simplifying the tree. The process of post pruning starts from the lowest leaf node and evaluates layer by layer whether certain subtrees or branches can be deleted and replaced with leaf nodes. Common post pruning methods include:
- Subtree Replacement: When a branch of a subtree is found to have little contribution to the model's prediction, the subtree is replaced with a leaf node, which directly uses the majority of classes in the subtree as the classification result.
- Subtree Raising: Simplify the tree structure by raising a portion of the subtree to its parent node. Specifically, if the child node of a node in the subtree can replace its parent node, it will be promoted.
- Cost Complexity Pruning: This method balances the complexity of the tree and the prediction error of the model by adding a regularization parameter. In practical operation, cross validation will be performed on the pruned decision tree to select the subtree that minimizes the prediction error.
The advantages of post pruning:
More effective generalization ability: Through post pruning, overfitting can be significantly reduced, making the model more predictive on new data.
Retain more information: Since post pruning is performed after generating the complete decision tree, it ensures that the model utilizes the information in the data as much as possible, reducing the risk of premature termination of splitting.
Disadvantages of post pruning:
High computational cost: Post pruning usually requires generating a fully grown decision tree, which increases computational costs, especially when the dataset is large.
Higher complexity: The pruning strategy and evaluation criteria for post pruning are usually more complex than pre pruning, and may require more tuning and calculations.
Specific algorithm for pruning
- Greedy pruning: Determine whether to prune based on the prediction error of the subtree, compare the performance before and after pruning, and preserve a better structure.
- CART pruning algorithm: a pruning algorithm based on cost complexity, combined with tree complexity and error performance. Find the optimal pruning depth through cross validation.
- Reduced Error Pruning: Starting from a fully grown tree, test the pruning effect of each node. If pruning does not increase the error rate, retain the pruned structure.
3、Advantages and disadvantages of decision trees
dvantages :
- It is intuitive and easy to understand, and can be converted into a set of rules for quick explanation, comprehension, and implementation: the path from the root node to the leaf node is the explanation of the classification, and the leaf node represents the final classification result.
- Able to handle nominal (categorical) and numerical input data.
- Can handle datasets with missing values.
- As a non parametric method, it does not rely on spatial distribution of data or structural assumptions of classifiers.
disadvantages :
- Decision trees are overly sensitive to noise and irrelevant attributes in the training set.
- Require the target attribute to consist of discrete values.
When attributes are highly correlated, decision trees usually perform well because they adopt a divide and conquer approach; But when there are many complex interactions, the performance of decision trees is not as ideal as expected.
4、决策树分类任务实现对比
Mainly based on the process of model construction, compare the differences between traditional code methods and using Sentosa_SSML Community Edition to complete machine learning algorithms.
(1)Data Load
Drag and drop the data reading operator, select the data file path, choose the reading format, etc., and click apply to read the data.

(2)Sample partitioning
Connect types and sample partitioning operators to partition training and testing data sets.
Firstly, the sample partitioning operator can choose the ratio of partitioning the training and testing sets of the data.

Right click preview to see the data partitioning results.

Secondly, the connection type operator sets the model type of the Specifications column to the Label column.

(3)model training
After the sample partitioning is completed, connect the decision tree classification operator and double-click on the right side to configure the model properties.

Right click to execute, and after training is completed, the decision tree classification model is obtained.

(4)Evaluation
Evaluate the model using evaluation operators

Evaluate the model using evaluation operators

Test set evaluation results
Evaluate the model using confusion matrix evaluation operator

Training set evaluation results:

Test set evaluation results:

Evaluate the model using the ROC-AUC operator

ROC-AUC operator evaluation result:






(5)Model visualization
Right click on the decision tree classification model to view model information. The importance of model features, confusion matrix, and decision tree visualization are shown in the following figure:



5、Comparison of Decision Tree Regression Task Implementation
(1)Data loading and sample partitioning
Data loading and sample partitioning are the same as above
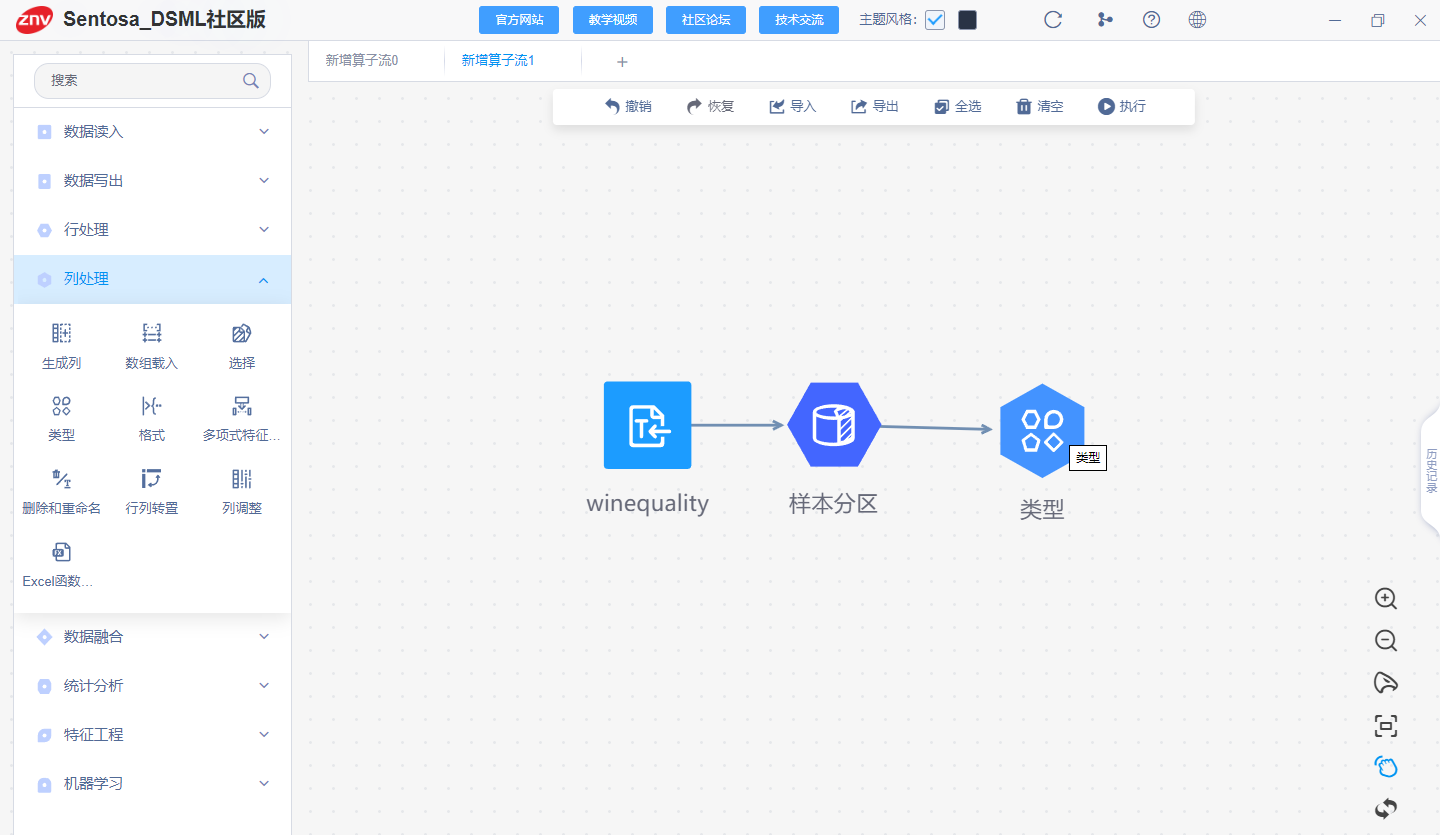
(2)model training
After the sample partitioning is completed, connect the decision tree regression operator, configure the model attributes, and execute to obtain the decision tree regression model.
(3)Evaluation
Evaluate the model using evaluation operators

Training set evaluation results

Test set evaluation results

(4)Model visualization
Right click on the decision tree regression model to view model information:


6、summarize
& emsp; Compared to traditional coding methods, using Sentosa_DSML Community Edition to complete the process of machine learning algorithms is more efficient and automated. Traditional methods require manually writing a large amount of code to handle data cleaning, feature engineering, model training, and evaluation. In Sentosa_DSML Community Edition, these steps can be simplified through visual interfaces, pre built modules, and automated processes, effectively reducing technical barriers. Non professional developers can also develop applications through drag and drop and configuration, reducing dependence on professional developers.
& emsp; Sentosa_DSML Community Edition provides an easy to configure operator flow, reducing the time spent writing and debugging code, and improving the efficiency of model development and deployment. Due to the clearer structure of the application, maintenance and updates become easier, and the platform typically provides version control and update features, making continuous improvement of the application more convenient.
Sentosa Data Science and Machine Learning Platform (Sentosa_DSML) is a one-stop AI development, deployment, and application platform with full intellectual property rights owned by Liwei Intelligent Connectivity. It supports both no-code "drag-and-drop" and notebook interactive development, aiming to assist customers in developing, evaluating, and deploying AI algorithm models through low-code methods. Combined with a comprehensive data asset management model and ready-to-use deployment support, it empowers enterprises, cities, universities, research institutes, and other client groups to achieve AI inclusivity and simplify complexity.
The Sentosa_DSML product consists of one main platform and three functional platforms: the Data Cube Platform (Sentosa_DC) as the main management platform, and the three functional platforms including the Machine Learning Platform (Sentosa_ML), Deep Learning Platform (Sentosa_DL), and Knowledge Graph Platform (Sentosa_KG). With this product, Liwei Intelligent Connectivity has been selected as one of the "First Batch of National 5A-Grade Artificial Intelligence Enterprises" and has led important topics in the Ministry of Science and Technology's 2030 AI Project, while serving multiple "Double First-Class" universities and research institutes in China.
To give back to society and promote the realization of AI inclusivity for all, we are committed to lowering the barriers to AI practice and making the benefits of AI accessible to everyone to create a smarter future together. To provide learning, exchange, and practical application opportunities in machine learning technology for teachers, students, scholars, researchers, and developers, we have launched a lightweight and completely free Sentosa_DSML Community Edition software. This software includes most of the functions of the Machine Learning Platform (Sentosa_ML) within the Sentosa Data Science and Machine Learning Platform (Sentosa_DSML). It features one-click lightweight installation, permanent free use, video tutorial services, and community forum exchanges. It also supports "drag-and-drop" development, aiming to help customers solve practical pain points in learning, production, and life through a no-code approach.
This software is an AI-based data analysis tool that possesses capabilities such as mathematical statistics and analysis, data processing and cleaning, machine learning modeling and prediction, as well as visual chart drawing. It empowers various industries in their digital transformation and boasts a wide range of applications, with examples including the following fields:
1.Finance: It facilitates credit scoring, fraud detection, risk assessment, and market trend prediction, enabling financial institutions to make more informed decisions and enhance their risk management capabilities.
2.Healthcare: In the medical field, it aids in disease diagnosis, patient prognosis, and personalized treatment recommendations by analyzing patient data.
3.Retail: By analyzing consumer behavior and purchase history, the tool helps retailers understand customer preferences, optimize inventory management, and personalize marketing strategies.
4.Manufacturing: It enhances production efficiency and quality control by predicting maintenance needs, optimizing production processes, and detecting potential faults in real-time.
5.Transportation: The tool can optimize traffic flow, predict traffic congestion, and improve transportation safety by analyzing transportation data.
6.Telecommunications: In the telecommunications industry, it aids in network optimization, customer behavior analysis, and fraud detection to enhance service quality and user experience.
7.Energy: By analyzing energy consumption patterns, the software helps utilities optimize energy distribution, reduce waste, and improve sustainability.
8.Education: It supports personalized learning by analyzing student performance data, identifying learning gaps, and recommending tailored learning resources.
9.Agriculture: The tool can monitor crop growth, predict harvest yields, and detect pests and diseases, enabling farmers to make more informed decisions and improve crop productivity.
10.Government and Public Services: It aids in policy formulation, resource allocation, and crisis management by analyzing public data and predicting social trends.
Welcome to the official website of the Sentosa_DSML Community Edition at https://sentosa.znv.com/. Download and experience it for free. Additionally, we have technical discussion blogs and application case shares on platforms such as Bilibili, CSDN, Zhihu, and cnBlog. Data analysis enthusiasts are welcome to join us for discussions and exchanges.
Sentosa_DSML Community Edition: Reinventing the New Era of Data Analysis. Unlock the deep value of data with a simple touch through visual drag-and-drop features. Elevate data mining and analysis to the realm of art, unleash your thinking potential, and focus on insights for the future.
Official Download Site: https://sentosa.znv.com/
Official Community Forum: http://sentosaml.znv.com/
GitHub:https://github.com/Kennethyen/Sentosa_DSML
Bilibili: https://space.bilibili.com/3546633820179281
CSDN: https://blog.csdn.net/qq_45586013?spm=1000.2115.3001.5343