大数据行业应用持续升温,特别是企业级大数据市场正在进入快速发展时期。越来越多的企业期望实现数据孤岛的打通,整合海量的数据资源,挖掘并沉淀有价值的数据,进而驱动更智能的商业。随着公司数据爆发式增长,原有的数据库无法承担海量数据的处理,那么就开始考虑大数据平台了。大数据平台应该支持大数据常用的Hadoop 组件,如HBase、Hive、Flume、Spark,也可以接Greenplum,而Greenplum 正好有它的外部表(也就是Greenplum 创建一张表,表的特性叫作外部表,读取的内容是Hadoop 的Hive 中的),这可以和Hadoop 融合(当然也可以不用外部表)。通过搭建企业级的大数据平台,打通各系统之间的数据,通过多源异构接入多个业务系统的数据,完成对海量数据的整合。大数据采集平台应支持多样数据源,接口丰富,支持文件和关系型数据库等,支持直接跨库跨源的混合计算。
大数据平台实现数据的分层与水平解耦,沉淀公共的数据能力。这可分为三层:数据模型、数据服务与数据开发,通过数据建模实现跨域数据的整合和知识沉淀,通过数据服务实现对于数据的封装和开放,快速、灵活地满足上层应用的要求,通过数据开发工具满足个性化数据和应用的需要。某运营商的数据平台:
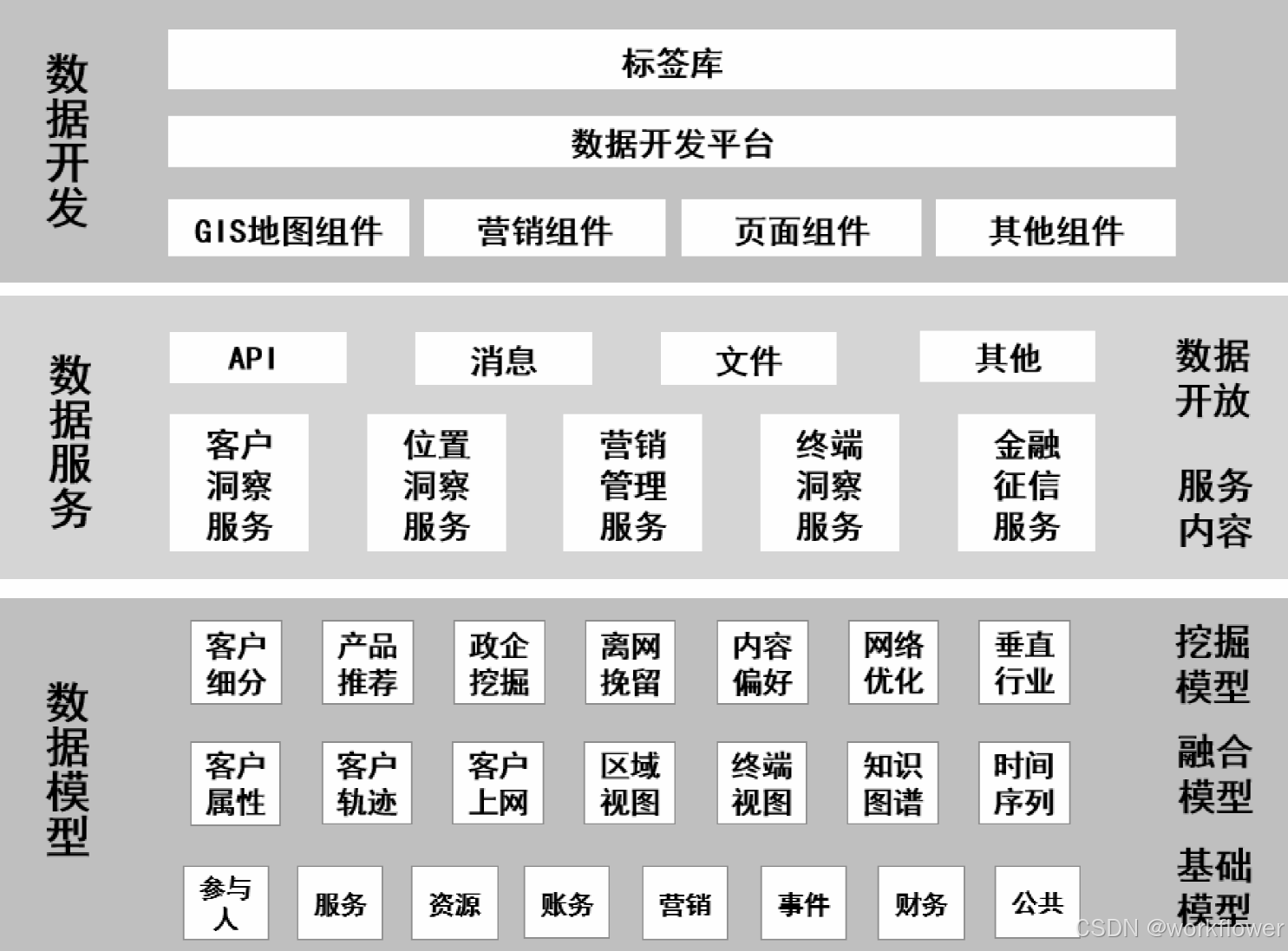
数据平台还涉及三方面内容。第一是数据技术。大家都有自己的数据中心、机房、小数据库。但当数据积累到一定体量后,这方面的成本会非常高,而且数据之间的质量和标准不一样,会导致效率不高等问题。因此,我们需要通过数据技术对海量数据进行采集、计算、存储、加工,同时统一标准和口径。第二是数据资产。把数据统一之后,会形成标准数据,再进行存储,形成大数据资产层,进而保证为各业务提供高效服务。第三是数据服务,包括指数,就是数据平台面向上端提供的数据服务。
数据平台应确保大家在使用数据的过程中,口径、标准、时效性、效率都有保障,能有更高的可靠性和稳定性。