本篇博客由作者女朋友亲情赞助,本人所撰写内容见资源文件。
1. 虚拟机集群的安装与配置
1.1 创建并配置两个虚拟机
配置网络,让主机和所有部署的虚拟机处于同一个网段下,主机可以去连虚拟机,虚拟机可以去连主机,虚拟机之间也可以相互连接。
(1)寻找空闲的IP地址
(2)进入cd /etc/sysconfig/network-scripts
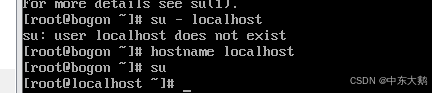
将bogon切换到localhost:
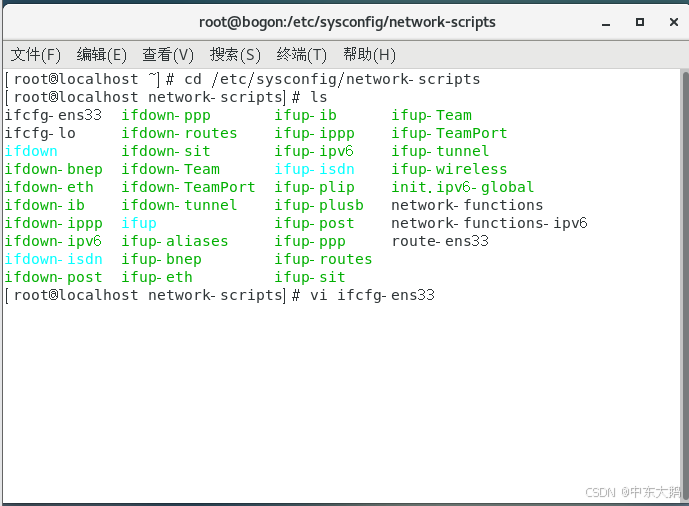
(3)vi编辑文件ifcfg-ens33


(4)service network restart进行重启


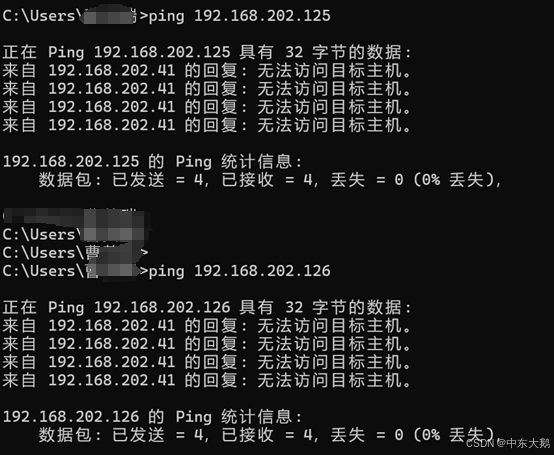
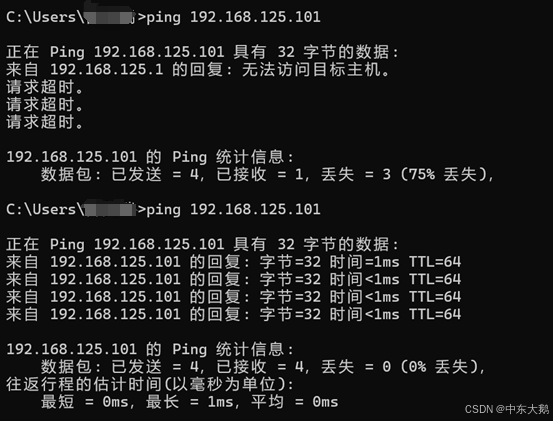
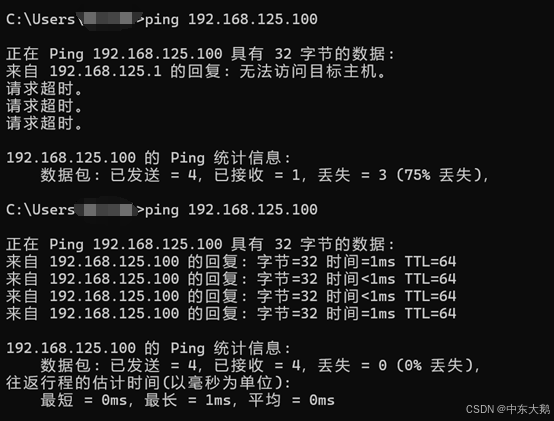
(5)再次通过ping发现主机可以访问到虚拟机,基本配置完成。
3、使用xshell创建namenode和datanode,分别对应两个虚拟机的地址。


输入用户密码进行连接:


4、实现相互免密登录(namenode和datanode都做)
(1)修改主机名,ping的时候可以直接使用对方的主机名。





(2)生成公钥实现免密登录




配置java的jdk
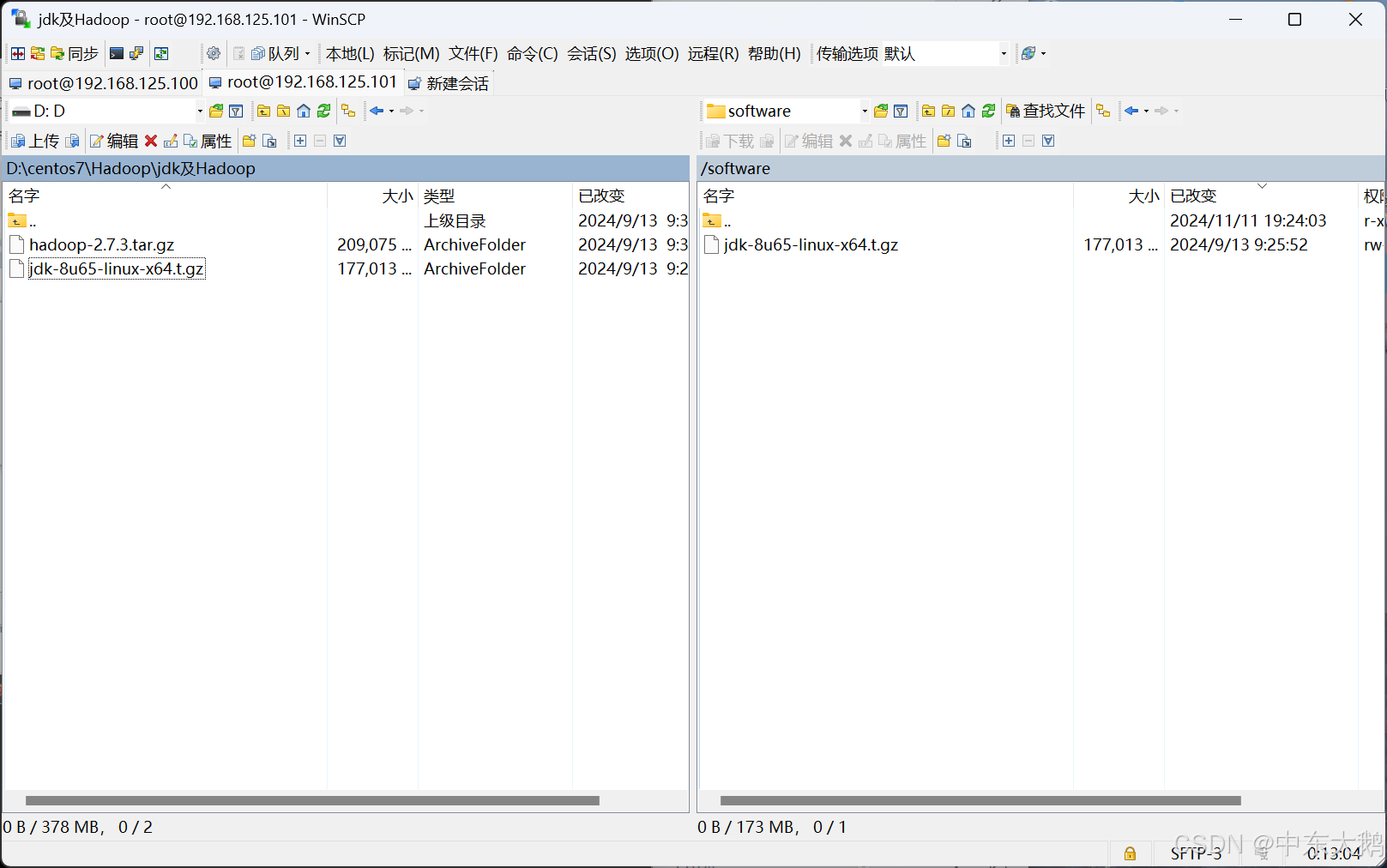
(1)使用winSCP远程传输工具



(2)将java的jdk文件拖入software文件夹中
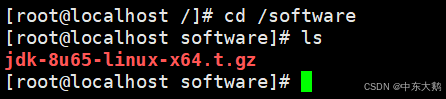
(3)使用ls看到目录下有了java解压包
(4)解压文件 tar -xzvf jdk-8u65-linux-x64.t.gz

进入配置文件 vi /etc/profile,添加以下配置内容
export JAVA_HOME=/software/jdk/
export PATH=.:$PATH:$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/software/hadoop
export PATH=.:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH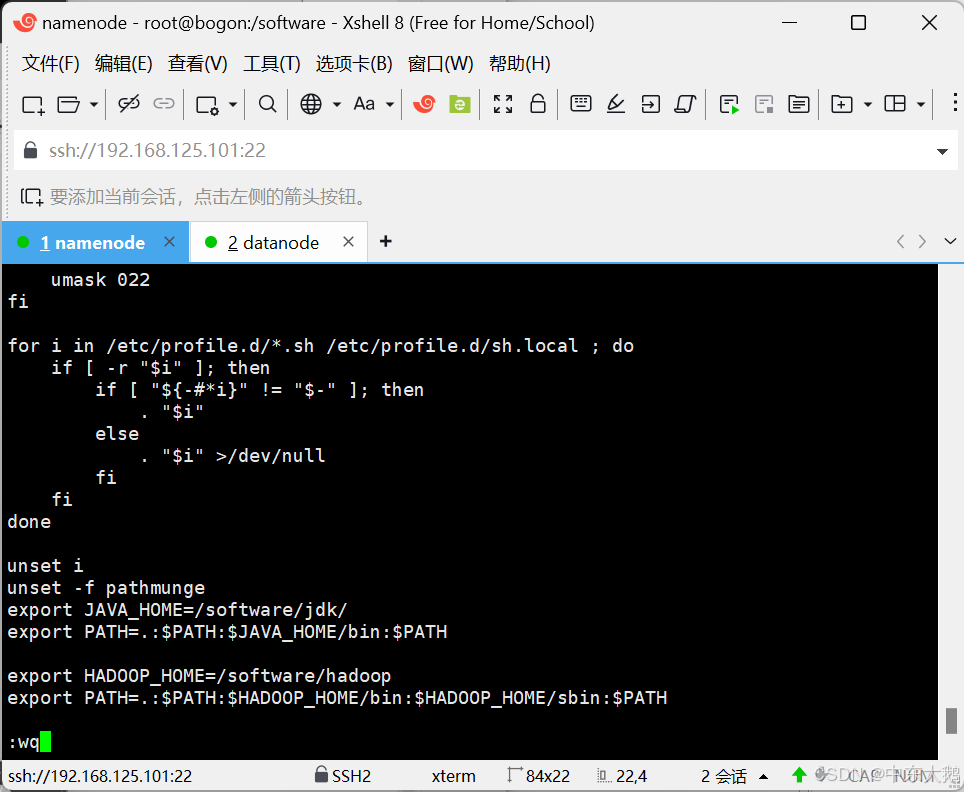
(6)让配置文件生效

主节点namenode配置Hadoop
(1)使用winSCP将hadoop压缩文件上传到software目录
(2)解压压缩文件

(3)修改对应的名字
修改Hadoop的配置文件:
core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml、slaves、yarn-site.xml
(5)打包Hadoop分发至datanode
进入到software目录后,对hadoop进行打包:
cd /software
tar -czvf hadoop.tar.gz hadoop将其分发:
scp hadoop.tar.gz datanode:/software在分节点进行解压完成配置:
cd /software
tar -zxvf hadoop.tar.gz hadoop7、启动集群(namenode完成)
(1)格式化集群
hdfs namenode -format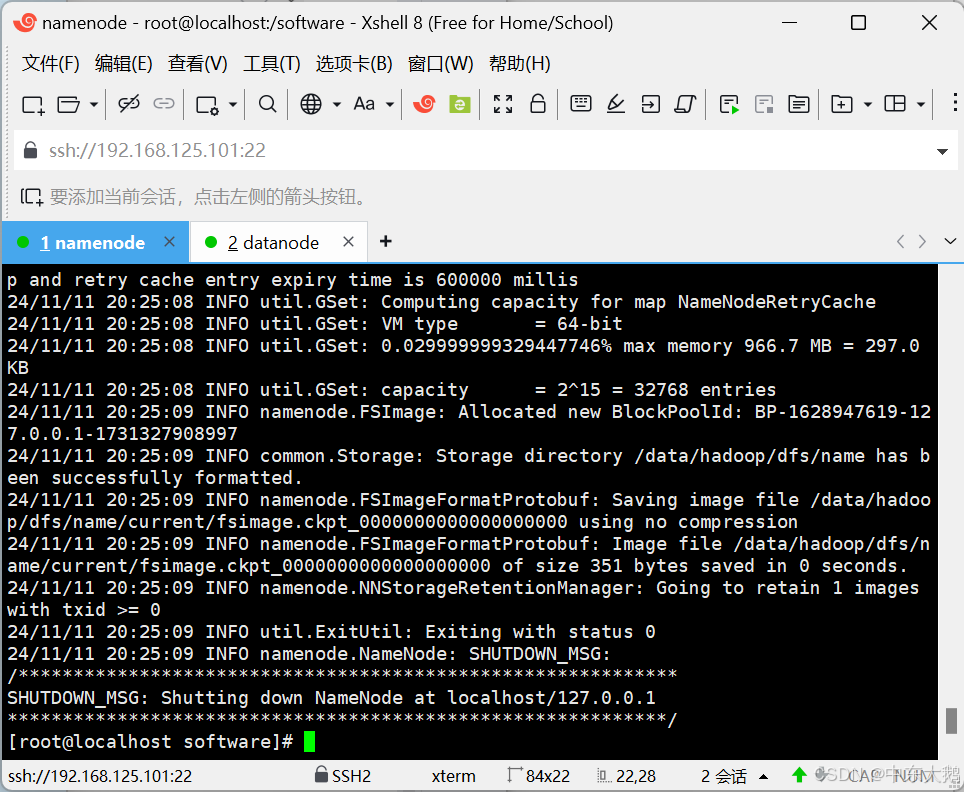
(2)启动集群
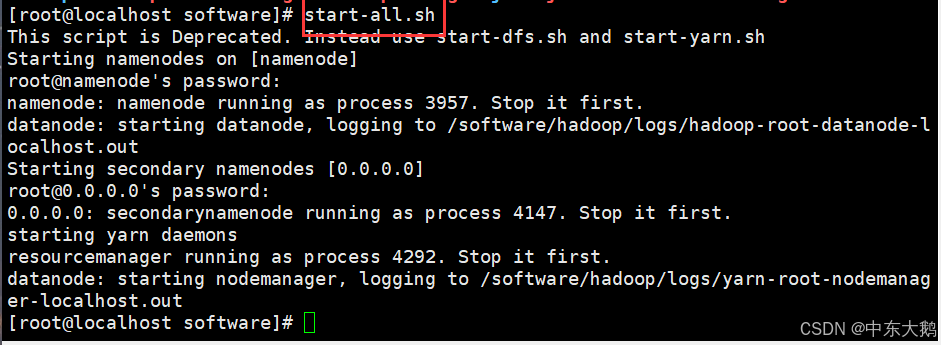
(3)jps查看状态
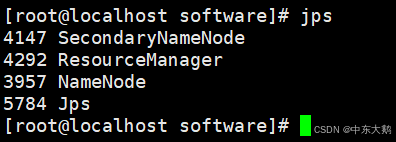
(4)查看集群报告
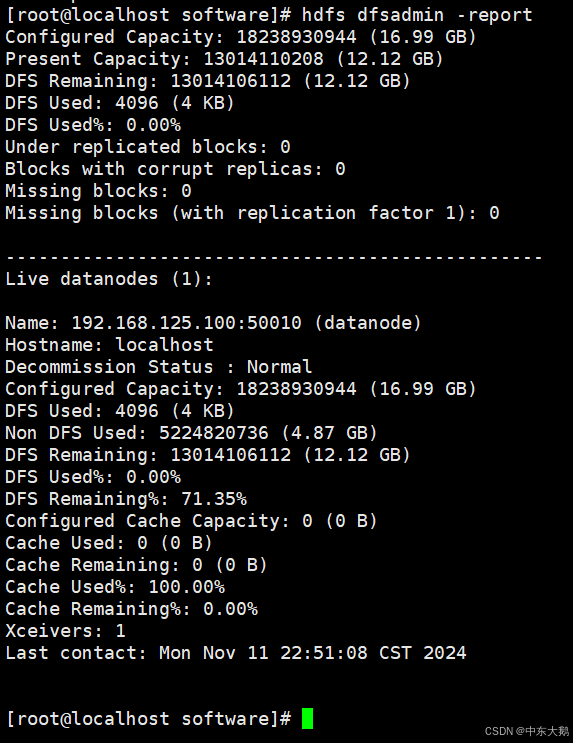
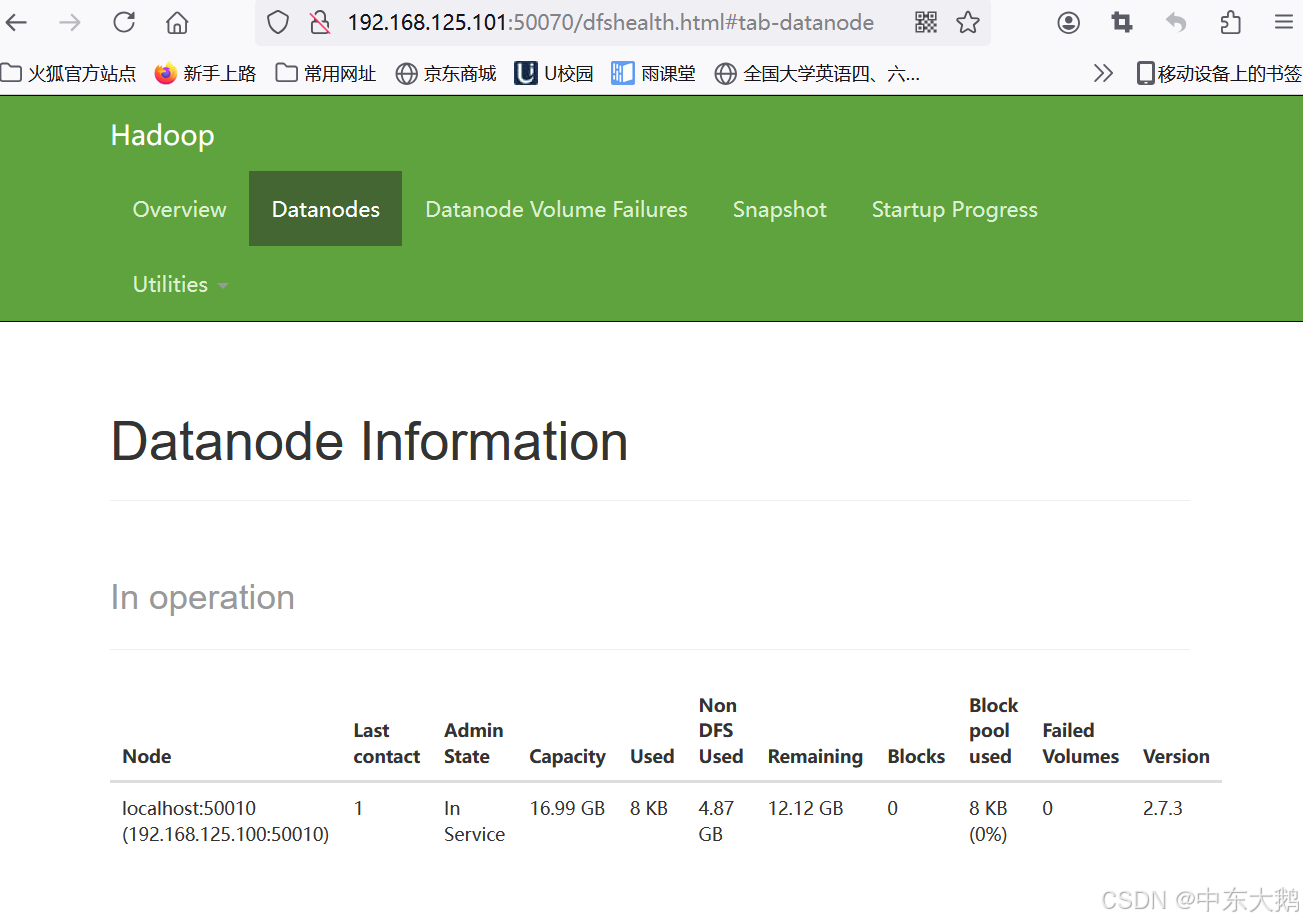
2. 启动Hadoop HDFS
1、进入hadoop的目录

2、启动HDFS:start-dfs.sh
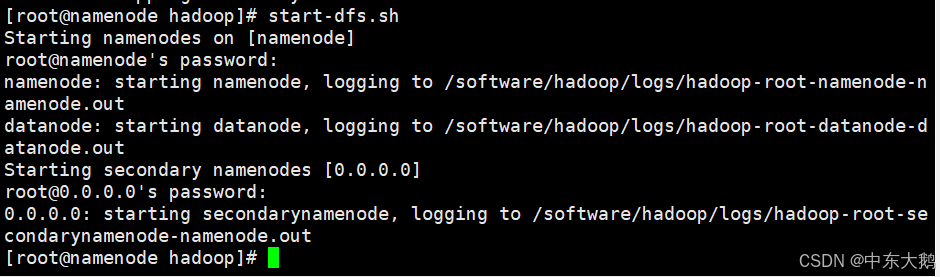
3、使用jps命令查看Java进程,确认NameNode和DataNode等进程正在运行。


3. HDFS基本操作实践
1、使用hdfs dfs -mkdir命令创建新的目录。
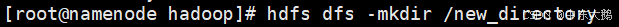
2、使用hdfs dfs -put命令上传本地文件到HDFS。
遇到问题:There are 0 datanode(s) running and no node(s) are excluded in this operation.

hdfs dfsadmin -report全为0:

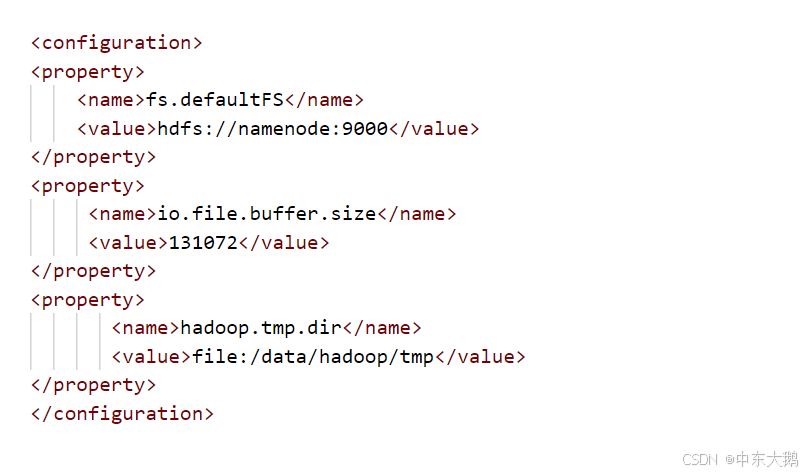
解决方案:①格式化多次,在core-site.xml中把file:/data/hadoop/tmp目录全部删除
②datanode: nodemanager running as process 6332. Stop it first.
这个错误提示表明NodeManager(YARN的组件)在使用DataNode所需的端口或资源,所以DataNode无法启动。可以通过以下步骤解决此问题:
因为NodeManager和DataNode使用的资源冲突,首先需要停止NodeManager进程,然后再启动DataNode。
执行以下命令停止NodeManager:
$HADOOP_HOME/sbin/yarn-daemon.sh stop nodemanager
确保NodeManager已成功停止。
③使用以下命令检查 DataNode 是否在所有相关节点上运行:
$HADOOP_HOME/sbin/hadoop-daemon.sh status datanode
如果 DataNode 未启动,可以尝试在各节点上启动它:
$HADOOP_HOME/sbin/hadoop-daemon.sh start datanode

之后,再次运行 hdfs dfsadmin -report 检查容量状态。
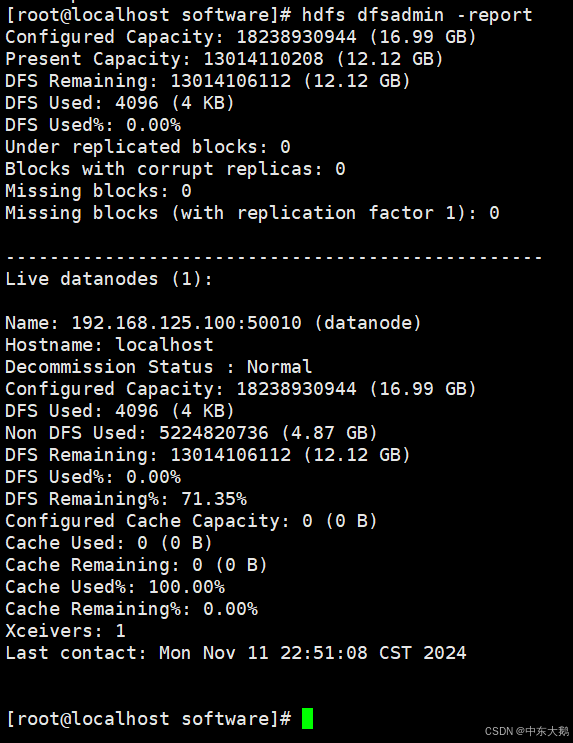
可以看到集群中有1个正常运行的DataNode,问题成功得到了解决。
使用hdfs dfs -get命令下载HDFS上的文件到本地。

4、使用hdfs dfs -cat命令查看HDFS上的文件内容。

5、使用hdfs dfs -rm命令删除HDFS上的文件。
