前置:Linux基础及命令复习
目录
- shell概述
-
- [Shell脚本入门案例 sh bash ./ . source](#Shell脚本入门案例 sh bash ./ . source)
- 变量
-
- [系统预定义变量 HOME PWD SHELL等](#系统预定义变量 HOME PWD SHELL等)
- [自定义变量 unset readonly](#自定义变量 unset readonly)
-
- [补充:开启子Shell进程的常见方法 (...) (...) \`...\` \<(...) \>(...)](#补充:开启子Shell进程的常见方法 (...) (...)
...<(...) >(...))
- [补充:开启子Shell进程的常见方法 (...) (...) \`...\` \<(...) \>(...)](#补充:开启子Shell进程的常见方法 (...) (...)
- [特殊变量 n # \* @ ?](# * @ ?)
- [运算符 ((表达式)) 表达式](#运算符 ((表达式)) [表达式])
- [条件判断 test condition 或 condition ](#条件判断 test condition 或 [ condition ])
- ★流程控制
- read读取控制台输入
- 函数
-
- [系统函数 basename dirname](#系统函数 basename dirname)
- 自定义函数
- ★Shell工具
- 正则表达式入门
shell概述
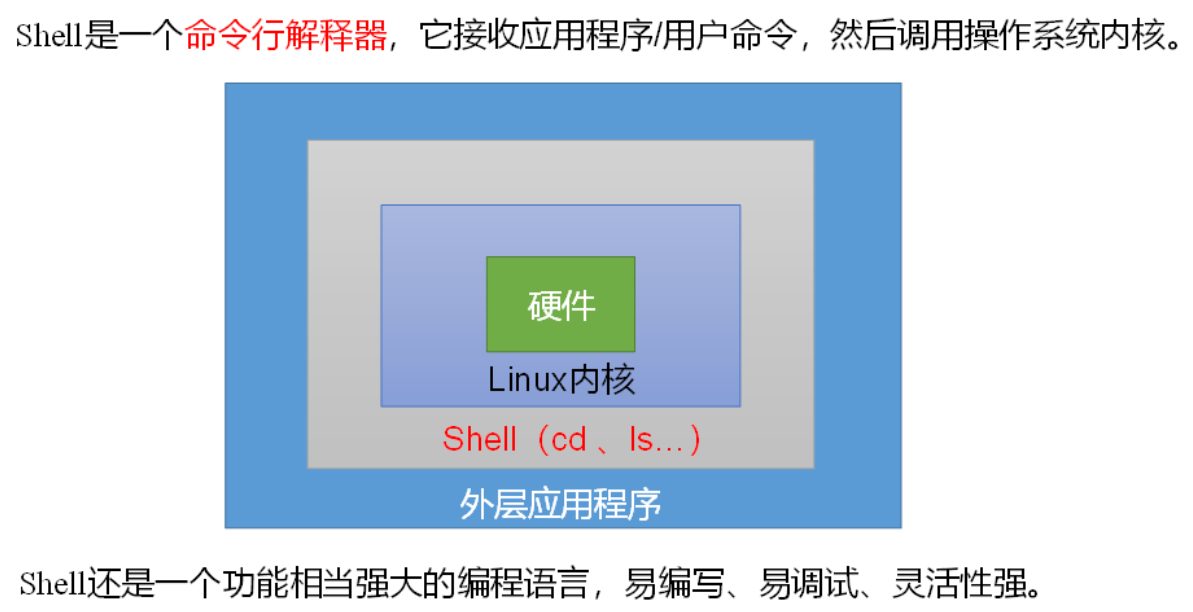
什么是 Shell?
Shell 是一种命令行解释器,是用户与操作系统之间交互的桥梁。它接收用户输入的命令,解释并将其传递给操作系统内核执行,然后将执行结果返回给用户。
简单来说,Shell 是一个解释器,可以理解用户的命令,也可以运行脚本实现自动化任务。
Shell 是 Linux 的核心工具之一,它不仅是一个命令行界面,还提供强大的脚本编程能力。通过学习 Shell 编程,你可以自动化许多重复的任务,提高工作效率。在大数据开发中,Shell 常被用来管理集群、自动化运行任务、处理数据等。
Shell 的主要功能
命令解释:接收并执行用户输入的命令。
脚本运行:通过编写脚本(多个命令的集合)实现自动化操作。
编程能力:支持变量、条件判断、循环、函数等编程语法。
任务调度:可以通过 cron 等工具定时运行脚本。
Linux 提供的 Shell 解析器
Bash (Bourne Again Shell):是 Linux 默认的 Shell,大多数 Linux 发行版默认安装。扩展了传统 Bourne Shell 的功能,支持命令补全、历史记录等。
Sh (Bourne Shell):一个简单而经典的 Shell,是早期 Unix 系统的默认 Shell。
功能较少,主要用于兼容性和轻量化任务。
Zsh (Z Shell):功能强大且易于定制,特别受开发者和高级用户欢迎。提供更灵活的命令补全、高亮显示和自动化功能。
Ksh (Korn Shell):综合了 C Shell 和 Bourne Shell 的优点,功能丰富。
Csh (C Shell) 和 Tcsh:类似 C 语言的语法,适合习惯 C 语言的用户。
Dash:轻量级的 Shell,适合系统脚本执行,速度快,占用资源少。
我们最常用的就是sh和bash了
bash
[root@localhost root01]# cat /etc/shells
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
/bin/tcsh
/bin/cshbash和sh的关系
Sh 是一种经典的 Shell,它是传统 Unix 系统的标准 Shell。
Bash 是 GNU 开发的增强版 Shell,兼容 Sh 的功能,并扩展了许多强大的特性,比如:命令历史记录 (history)。Tab 自动补全。算术运算支持 ($((expression)))。更丰富的脚本功能和控制结构。
兼容性:绝大部分情况下,Bash 可以运行 Sh 脚本,但反之不一定成立。
在centos7下观察发现,sh其实就是bash的软链接:
bash
[root@localhost bin]# ll | grep bash
-rwxr-xr-x. 1 root root 964536 4月 1 2020 bash
lrwxrwxrwx. 1 root root 10 3月 1 2024 bashbug -> bashbug-64
-rwxr-xr-x. 1 root root 6964 4月 1 2020 bashbug-64
lrwxrwxrwx. 1 root root 4 3月 1 2024 sh -> bash
# Centos默认的解析器是bash
[root@localhost bin]# echo $SHELL
/bin/bashShell脚本入门案例 sh bash ./ . source
需求 : 创建一个Shell脚本,输出helloworld
bash
[root01@localhost test]$ touch helloworld.sh
[root01@localhost test]$ vim helloworld.sh
在helloworld.sh中输入如下内容
#!/bin/bash
echo "helloworld"#!/bin/bash 这一行被称为 shebang(也叫做 hashbang)。它的作用是指定脚本文件应当使用的解释器。
脚本的常用执行方式
第一种 :采用bash或sh+ 脚本的相对路径或绝对路径(不用赋予脚本+x权限)
sh+脚本的相对路径/绝对路径
bash
[root01@localhost test]$ sh helloworld.sh
helloworld
[root01@localhost test]$ sh /home/root01/test/helloworld.sh
helloworld bash+脚本的相对路径/绝对路径
bash
[root01@localhost test]$ bash helloworld.sh
helloworld
[root01@localhost test]$ /home/root01/test/helloworld.sh
helloworld第二种:采用输入脚本的绝对路径或相对路径执行脚本(必须具有可执行权限+x)
上面的第一种执行方法,本质是bash解析器帮你执行脚本,所以脚本本身不需要执行权限。第二种执行方法,本质是脚本需要自己执行,所以需要执行权限。
bash
[root01@localhost test]$ ./helloworld.sh
bash: ./helloworld.sh: 权限不够
# 赋予helloworld.sh 脚本的+x权限
[root01@localhost test]$ chmod +x helloworld.sh
# 相对路径
[root01@localhost test]$ ./helloworld.sh
helloworld
# 绝对路径
[root01@localhost test]$ /home/root01/test/helloworld.sh
helloworld 第三种 :在脚本的路径前加上"."或者 source
假如有以下脚本
bash
[root01@localhost test]$ cat test.sh
#!/bin/bash
A=5
echo $A分别使用sh,bash,./ 和 . 的方式来执行,结果如下:
bash
[root01@localhost test]$ bash test.sh
5
[root01@localhost test]$ echo $A
[root01@localhost test]$ sh test.sh
5
[root01@localhost test]$ echo $A
[root01@localhost test]$ chmod +x test.sh
[root01@localhost test]$ ./test.sh
5
[root01@localhost test]$ echo $A
[root01@localhost test]$ . test.sh
5
[root01@localhost test]$ echo $A
5
[root01@localhost test]$ source test.sh
5
[root01@localhost test]$ echo $A
5
[root01@localhost test]$ 为什么
sh,bash,./的方式,echo $A输出没反应呢?
前三种 方式都是在当前shell中打开一个子shell来执行脚本内容,当脚本内容结束,则子shell关闭,回到父shell中。这意味着:1.脚本中的变量和环境修改:仅在子 shell 中有效,不会影响当前的父 shell。
2.执行结束后:子 shell 关闭,所有在脚本中设置的变量在父 shell 中不可见。
第四种 ,也就是使用在脚本路径前加"."或者 source的方式,可以使脚本内容在当前shell里执行,而无需打开子shell!这意味着:1.变量和环境修改:直接作用于当前 shell,脚本中设置的变量在执行后依然存在。
2.无需启动子 shell:所有命令在当前环境中执行,修改当前环境的变量和设置。
这也是为什么我们每次要修改完/etc/profile文件以后,需要source一下的原因。
开子shell与不开子shell的区别就在于,环境变量的继承关系,如在子shell中设置的当前变量,父shell是不可见的。
什么是 source 命令?
source 是一个 shell 内建命令,用于在当前 shell 环境中读取和执行指定的脚本文件。它通常用于加载配置文件或在当前环境中运行脚本以便修改环境变量。
source 常用来做什么?
1.加载配置文件:当你修改了像 ~/.bashrc、~/.bash_profile 或 /etc/profile 这样的配置文件后,需要重新加载它们以使修改生效,而无需重新启动终端。可以使用 source 或 . 命令来实现。
2.执行需要修改当前 shell 环境的脚本:如果脚本中包含环境变量的设置、别名的定义或其他需要在当前 shell 中生效的操作,应使用 source 执行。
为什么修改 /etc/profile这样的系统级的配置文件后需要 source?
/etc/profile 是一个系统级的配置文件,当用户登录时,系统会自动读取并执行该文件中的内容,以设置环境变量、别名等。然而,修改 /etc/profile 后,这些修改只会在新的 shell 会话中生效。如果你希望在当前会话中立即应用这些更改,而不必重新登录或启动一个新的终端,可以使用 source 命令来重新加载配置文件。
变量
系统预定义变量 HOME PWD $SHELL等
以下是一些常用的系统变量及其作用说明:
$HOME:当前用户的主目录。例如,/home/username。
$PWD:当前工作目录的完整路径。
$SHELL:用户当前使用的默认Shell类型及其路径。例如,/bin/bash。
$USER:当前登录的用户名。
$HOSTNAME:当前主机名。
$PATH:可执行文件的搜索路径,多个路径之间用冒号分隔。
$UID:当前用户的用户ID。
$EUID:当前用户的有效用户ID(尤其在切换用户权限时有区别)。
$?:上一条命令的退出状态码,0表示成功,非0表示失败。
$$:当前Shell脚本的进程ID。
系统变量的调用不区分大小写,但按照习惯,系统变量通常使用大写字母
案例实操
bash
# 使用 echo 命令可以直接查看某个系统变量的值。例如,查看当前用户的主目录:
[root@localhost root01]# echo $HOME
/root
# 例如当前工作目录:
[root@localhost root01]# echo $PWD
/home/root01
# 使用 set 命令可以查看当前Shell中所有的变量
# 包括系统预定义变量和用户自定义变量。
# 执行命令后,会输出大量信息
[root@localhost root01]# set
BASH=/bin/bash
BASH_ALIASES=()
BASH_ARGC=()
BASH_ARGV=()
...
# 通过查看 $SHELL 变量,可以知道当前使用的默认Shell类型
[root@localhost root01]# echo $SHELL
/bin/bash
# 如果你想确认当前Shell是否与默认Shell一致,可以查看 $0 变量,它表示当前运行的Shell或脚本名称:
[root@localhost root01]# echo $0
bash
# 通过 $? 可以获取上一条命令的退出状态码。
[root@localhost root01]# ls /nonexistentpath
ls: 无法访问/nonexistentpath: 没有那个文件或目录
[root@localhost root01]# echo $?
2 # 返回的状态码 2 表示命令执行失败
# 使用 $$ 可以获取当前脚本的进程ID,这在调试或日志记录中非常有用
[root@localhost root01]# echo $$
105311
# 如果要查看变量的完整清单,除了 set 命令外
# 还可以使用 env 命令(仅显示环境变量)
[root@localhost root01]# env
XDG_VTNR=1
XDG_SESSION_ID=2
...
# 使用 export 命令可以将用户自定义变量转为环境变量,供子进程使用
[root@localhost root01]# MY_VAR="hello"
[root@localhost root01]# export MY_VAR
[root@localhost root01]# env | grep MY_VAR
MY_VAR=hello自定义变量 unset readonly
1.基本语法
定义变量:变量名=变量值,注意=号前后不能有空格
Shell 的赋值语法是 VAR=value,而 value 必须是一个静态字符串或通过命令替换捕获(后面会介绍)的结果,不能直接是直接调用命令本身。
撤销变量:unset 变量名
声明静态变量:readonly变量,注意:不能unset。在当前Shell进程中会一直存在,除非当前Shell会话结束
2.变量定义规则
变量名规则:变量名称只能包含字母、数字和下划线,不能以数字开头。按约定俗成,环境变量名一般使用大写,普通变量名使用小写。
语法规则:等号=两侧不能有空格,否则会导致语法错误。如果变量值包含空格或特殊字符,必须使用引号(单引号或双引号)括起来。
默认类型:在bash中,所有变量的默认类型为字符串类型,无法直接进行数值运算。
作用域:普通变量的作用域仅限于当前Shell进程。通过 export 命令可以将变量提升为全局环境变量,供子Shell进程使用。
3.案例实操
bash
# (1)定义变量A并查看其值
[root01@localhost test]$ A=5
[root01@localhost test]$ echo $A
5
# (2)给变量A重新赋值
[root01@localhost test]$ A=8
[root01@localhost test]$ echo $A
8
# (3)撤销变量A
[root01@localhost test]$ unset A
[root01@localhost test]$ echo $A # 执行 unset 后,变量A被撤销,再次输出时为空。
# (4)声明静态变量B
[root01@localhost test]$ readonly B=2
[root01@localhost test]$ echo $B
2
[root01@localhost test]$ B=9
bash: B: 只读变量 # 尝试修改静态变量时,系统会报错提示其为只读变量。
# (5)默认字符串类型的数值运算
[root01@localhost test]$ C=1+2
[root01@localhost test]$ echo $C
1+2 # 在Shell中,变量值为字符串,不能直接进行算术运算
# 如果需要运算,可使用 expr 或 $(( ))。
[root01@localhost test]$ C=$((1+2))
[root01@localhost test]$ echo $C
3
# 或者 C=$(expr 1 + 2)
# expr 对空格敏感,运算符和操作数之间必须有空格,否则会报错
# 注意:在 expr 中,乘法符号 * 必须用反斜杠 \ 转义,否则会被Shell解释为通配符。
# $(( )) 对空格不敏感,可以省略空格。$(( )) 更简洁,更适合现代Shell脚本的书写
# (6)处理带空格的变量值
[root01@localhost test]$ D=I love banzhang
bash: love: 未找到命令... # 未使用引号时,变量赋值会因空格导致语法错误
# 正确写法是使用双引号或单引号
[root01@localhost test]$ D="I love banzhang"
[root01@localhost test]$ echo $D
I love banzhang
# (7)将变量提升为全局环境变量
# 通过 export 命令,可以将变量变为全局环境变量,供子Shell进程访问
# 创建脚本 helloworld.sh 并添加如下内容:
#!/bin/bash
echo "helloworld"
echo $B
# 执行脚本前未导出变量B时,脚本无法访问变量B的值
[root01@localhost test]$ ./helloworld.sh
helloworld
# 导出变量后,再次执行脚本
[root01@localhost test]$ export B
[root01@localhost test]$ ./helloworld.sh
helloworld
2补充:开启子Shell进程的常见方法 (...) $(...) `...` <(...) >(...)
上面说到:普通变量的作用域仅限于当前Shell进程。通过 export 命令可以将变量提升为全局环境变量,供子Shell进程使用。
那么什么是子Shell进程; 一般开启子Shell进程的方法有哪些?
子Shell进程简介
子Shell进程是从当前Shell进程派生出的一个新的Shell实例。子Shell是当前Shell的子进程,它可以继承当前Shell的环境变量,但不会影响当前Shell的变量。当子Shell进程终止时,其对环境变量的修改不会反作用于父Shell进程。
在Linux系统中,每一个进程都有一个父进程,Shell本身也是一个进程(例如,bash Shell是由系统启动的)。当Shell启动一个新的子进程时,这个新进程称为子Shell。
另外,下文章节会介绍函数,在 Shell 脚本中,不能直接将函数调用赋值给变量。为了捕获函数的输出,必须使用命令替换 $(...) 或反引号 `...`。
这部分可以等看完函数这一章节再看
开启子Shell进程的常见方法
1.运行脚本
当我们运行一个Shell脚本时,会自动启动一个子Shell来执行脚本中的命令。
bash
# 创建一个脚本 test.sh
#!/bin/bash
echo "This is a child shell"
echo "Current PID: $$"
# 运行脚本:
bash test.sh
# 输出:
# This is a child shell
# Current PID: 12345 # 子Shell的进程ID$$ 是Shell的特殊变量,用于显示当前Shell进程的ID,前面系统变量时有提到。
2.使用子Shell语法 ()
在一对小括号 () 中运行的命令会启动一个子Shell。
作用:隔离作用域,子Shell的变量、环境和操作不会影响父Shell。
是否可用于获取函数结果:不能直接将函数结果赋值给变量。
bash
echo "Parent Shell PID: $$"
(
echo "This is a child shell"
echo "Child Shell PID: $$"
)
# 输出:
# Parent Shell PID: 6789
# This is a child shell
# Child Shell PID: 12345
# 脚本里也是一样。内容(假设文件名为 test.sh):
#!/bin/bash
echo "Parent Shell PID: $$"
(
echo "This is a child shell"
echo "Child Shell PID: $$"
)
# 运行脚本:
bash test.sh
Parent Shell PID: 12345
This is a child shell
Child Shell PID: 67890子Shell的PID与父Shell的PID不同。
3.通过管道 |
使用管道操作符时,每一端的命令通常会在子Shell中运行。
bash
echo "hello world" | grep "hello"在这个例子中,echo 和 grep 会分别运行在不同的子Shell中。
4.在命令替换中启动子Shell
当使用命令替换$(...) 或反引号`...`时,也会启动子Shell。
含义:执行括号内的命令(或函数)并捕获其标准输出,将结果作为值返回。
作用:常用于将函数或命令的输出赋值给变量。
是否可用于获取函数结果:可以,这是获取函数输出的推荐方法。
注意:$(...) 是现代的命令替换语法,推荐使用它而不是反引号(因为它在嵌套时需要转义,容易引起混淆)
bash
result=$(echo "This is a child shell")
echo $result
# 命令 echo "This is a child shell" 是在子Shell中执行的
result=`echo "This is a child shell"`
echo $result
# 反引号 `...` 是另一种实现命令替换的方式,与 $(...) 功能相同
# 都会启动一个子Shell来执行命令,并将其输出返回到父Shell。
# 虽然反引号和 $() 都可以实现命令替换,但 $() 是更现代和推荐的写法,原因如下:
# 1.$() 可以更清晰地嵌套命令,而反引号嵌套时需要转义,很容易出错
# 2.$() 更直观,特别是对于复杂的命令链,易于阅读和维护。反引号在代码中容易与其他字符混淆,特别是在某些字体中。5.通过子Shell启动新的Shell会话
可以手动启动一个子Shell(例如执行 bash 或 sh):
bash
[root01@localhost test]$ echo $$
65202
[root01@localhost test]$ bash # 进入子Shell
[root01@localhost test]$ echo $$ # 查看子Shell的PID
65248
[root01@localhost test]$ exit # 退出子Shell,回到父Shell
exit
[root01@localhost test]$ echo $$
652026.使用重定向符号 <() 或 >()
Process Substitution 是一种特殊的情况,它允许在子Shell中运行命令,然后将其输出作为文件进行处理。
bash
cat <(echo "This is a child shell")
# 在这个例子中,echo "This is a child shell" 是在子Shell中执行的。<(...)
含义:将命令的输出作为一个临时文件的路径(FIFO或临时文件),供其他命令读取。
作用:通常用于需要将命令输出作为文件输入的场景。
是否可用于获取函数结果:间接可以,但更适合传递文件形式的输出,不推荐直接用于变量赋值。
>(...)
含义:将命令的输出写入临时文件路径供其他命令使用。
作用:通常用于需要将命令的输出重定向到文件的场景。
是否可用于获取函数结果:不能直接用于变量赋值。
特殊变量 n # \* @ $?
在Shell脚本中,有许多特殊变量可以用来获取脚本信息、参数信息以及命令执行的状态。熟练掌握这些变量有助于编写更灵活和高效的脚本。
总结:
$n 用于获取具体位置的参数。
$# 获取参数总数。
$* 和 $@ 用于获取所有参数,区别在于处理方式。
$? 用于检查命令或脚本执行的状态。
下面分别介绍
1 $n
$n是位置参数变量:
$0 表示当前脚本的名称。
$1 至 $9 表示传递给脚本的第1到第9个参数。
超过9个参数时,需要使用大括号,如 ${10}。
案例实操。创建脚本 parameter.sh:
bash
#!/bin/bash
echo '========== $n =========='
echo $0 # 输出脚本名
echo $1 # 输出第一个参数
echo $2 # 输出第二个参数执行脚本:
bash
[root01@localhost test]$ chmod 777 parameter.sh
[root01@localhost test]$ ./parameter.sh ab cd ef
========== $n ==========
./parameter.sh
ab
cd2 $#
$# 表示传递给脚本的参数总数,常用于循环或参数验证。
案例实操。扩展 parameter.sh:
bash
#!/bin/bash
echo '========== $n =========='
echo $0 # 脚本名
echo $1 # 第一个参数
echo $2 # 第二个参数
echo '========== $# =========='
echo $# # 参数总数执行脚本:
bash
[root01@localhost test]$ ./parameter.sh tx nb hah
========== $n ==========
./parameter.sh
tx
nb
========== $# ==========
33 \* 和 @
$* 将所有的参数视为一个整体,参数间用空格隔开。
$@ 将每个参数独立处理,参数间仍用空格隔开。
案例实操。更新 parameter.sh:
bash
#!/bin/bash
echo '========== $n =========='
echo $0 # 脚本名
echo $1 # 第一个参数
echo $2 # 第二个参数
echo '========== $# =========='
echo $# # 参数总数
echo '========== $* =========='
echo $* # 所有参数作为一个整体
echo '========== $@ =========='
echo $@ # 每个参数独立输出执行脚本:
bash
[root01@localhost test]$ ./parameter.sh tx nb hah 1 2 3 4
========== $n ==========
./parameter.sh
tx
nb
========== $# ==========
7
========== $* ==========
tx nb hah 1 2 3 4
========== $@ ==========
tx nb hah 1 2 3 4
[root01@localhost test]$ 区别补充:在大多数情况下,$* 和 $@ 表现一致。
在双引号中使用时,行为不同:$* 将所有参数作为单个字符串(参数用空格隔开)。$@将每个参数保留为独立的字符串。示例:
bash
#!/bin/bash
echo "Using \"\$*\":"
for arg in "$*"; do
echo $arg
done
echo "Using \"\$@\":"
for arg in "$@"; do
echo $arg
done执行结果:
bash
[root01@localhost test]$ ./parameter.sh a b c
Using "$*":
a b c
Using "$@":
a
b
c4 $?
$? 表示最后一次执行命令的返回状态:返回 0 表示成功。
返回非 0 表示失败(错误码由命令本身决定)。
案例实操。验证脚本执行是否成功:
bash
[root01@localhost test]$ ./helloworld.sh
hello world
[root01@localhost test]$ echo $?
0验证错误命令:
bash
[root01@localhost test]$ invalid_command
-bash: invalid_command: command not found
[root01@localhost test]$ echo $?
127扩展:使用 $? 检查执行结果并给出提示
bash
#!/bin/bash
./helloworld.sh
if [ $? -eq 0 ]; then
echo "Script executed successfully!"
else
echo "Script execution failed!"
fi运算符 ((表达式)) 表达式
在 Shell 脚本中,可以使用以下两种方式进行数学运算:
$((表达式)):推荐的写法,支持更多功能,易读性更高。
$[表达式]:较旧的写法,功能较为简单,但在现代 Shell 中仍可使用。
bash
[root01@localhost test]$ S=$[(2+3)*4]
[root01@localhost test]$ echo $S
20
bash
[root01@localhost test]$ S=$(( (2+3)*4 ))
[root01@localhost test]$ echo $S
20更多运算符支持
Shell 中支持以下运算符,适用于 $(( )) 和 $[ ]:
算术运算符 :+,-,*,/,%(取余)。
关系运算符 :<,>,<=,>=,==,!=(返回布尔值)。
逻辑运算符 :&&,||。
例如:
bash
[root01@localhost test]$ X=$((5 > 3 && 2 < 4))
[root01@localhost test]$ echo $X
1 # 1表示条件成立 跟执行命令的返回状态不同(0代表执行成功)注意事项
整数运算:Shell 原生支持的运算仅限于整数。如果需要处理小数,可借助 bc 工具。例如:
bash
[root01@localhost test]$ echo "scale=2; 10/3" | bc
3.33空格敏感性:运算式中的空格可能会导致错误。例如:
bash
[root01@localhost test]$ S=$[ (2 + 3) * 4 ] # 正确
[root01@localhost test]$ S=$[ (2+3)*4 ] # 正确
[root01@localhost test]$ S=$[ ( 2+3 )*4 ] # 错误兼容性问题:某些较旧的 Shell 可能对 $(( )) 的支持不完善,需确认 Shell 版本。
条件判断 test condition 或 condition
1) 基本语法
条件判断在 Shell 脚本中非常重要,用于根据条件执行不同的逻辑操作。主要有以下两种形式:
test condition
[ condition ] (注意 condition 前后需要有空格)
注意 : 条件"非空即为 true"。例如:
hello 返回 true。
返回 false。
2) 常用判断条件
(1) 整数之间的比较
-eq : 等于(equal)
-ne : 不等于(not equal)
-lt : 小于(less than)
-le : 小于等于(less equal)
-gt : 大于(greater than)
-ge : 大于等于(greater equal)
(2)按照文件权限进行判断
-r:文件是否有读权限(read)
-w:文件是否有写权限(write)
-x:文件是否有执行权限(execute)
(3)按照文件类型进行判断
-e:文件是否存在(existence)
-f:文件是否存在且是一个常规文件(file)
-d:文件是否存在且是一个目录(directory)
(4)复杂条件判断
-a:表示逻辑与(and)。
-o:表示逻辑或(or)。
在 condition 或 test 中可用,但在复杂条件中建议使用 && 和 || 代替
比如: if condition1 -a condition2 换成 if condition1 && condition2
3) 案例实操
(1)判断 23 是否大于等于 22
bash
[root01@localhost test]$ [ 23 -ge 22 ]
[root01@localhost test]$ echo $?
0 # 条件 [ 23 -ge 22 ] 为真,返回值 0 表示判断成功。(2)判断 helloworld.sh 是否具有写权限
bash
[root01@localhost test]$ [ -w helloworld.sh ]
[root01@localhost test]$ echo $?
0 # 如果文件 helloworld.sh 存在并具有写权限,返回值为 0 表示判断成功。(3)判断 /home/test/cls.txt 文件是否存在
bash
[root01@localhost test]$ [ -e /home/test/cls.txt ]
[root01@localhost test]$ echo $?
1 # 条件 [ -e /home/test/cls.txt ] 为假,返回值 非0 表示判断失败(4)多条件判断
使用 &&:前一个命令执行成功时,才会执行后一个命令。
使用 ||:前一个命令执行失败时,才会执行后一个命令。
bash
# 案例 1:判断非空字符串
[root01@localhost test]$ [ haha ] && echo OK || echo notOK
OK # [ atguigu ] 条件为真,执行 echo OK
# 案例 2:判断空字符串
[root01@localhost test]$ [ ] && echo OK || echo notOK
notOK # [ ] 条件为假,执行 echo notOK(5)if 语句配合条件判断(下节重点介绍)
条件判断通常与 if 语句结合使用,以下是基本格式:
bash
if [ condition ]; then
# 条件为真时执行的语句
else
# 条件为假时执行的语句
fi比如:
bash
[root01@localhost test]$ if [ -e helloworld.sh ]; then
> echo "File exists"
> else
> echo "File does not exist"
> fi★流程控制
if判断
基本语法
单分支:
bash
if [ 条件判断式 ]; then
# 程序
fi
# 或者
if [ 条件判断式 ]
then
# 程序
fi多分支:
bash
if [ 条件判断式 ]; then
# 程序
elif [ 条件判断式 ]; then
# 程序
else
# 程序
fi注意:
1.
[ condition ]还可以换成test condition,具体见上一节的条件判断介绍2.
[ 条件判断式 ]中,必须确保中括号和条件判断式之间有空格。if 关键字后面也要有空格。
案例实操:输入一个数字,如果是1,则输出 banzhang zhen shuai;如果是2,则输出 cls zhen mei;其他情况下,不输出任何内容。
编写脚本 if.sh:
bash
#!/bin/bash
if [ $1 -eq 1 ]; then
echo "banzhang zhen shuai"
elif [ $1 -eq 2 ]; then
echo "cls zhen mei"
fi运行脚本:
bash
chmod 777 if.sh
./if.sh 1
# 输出banzhang zhen shuaicase语句
基本语法
bash
case $变量名 in
"值1")
# 如果变量的值等于值1,则执行程序1
;;
"值2")
# 如果变量的值等于值2,则执行程序2
;;
*)
# 如果变量的值不匹配上述任何一个值,则执行此程序
;;
esac注意事项:
case 行尾必须是关键字 in。
每个模式匹配后需要以右括号 ) 结束。
双分号 ;; 表示命令序列结束,相当于 Java 的 break。
最后的 *) 是默认匹配模式,相当于 Java 的 default。
案例实操 :输入一个数字,如果是1,则输出 banzhang;如果是2,则输出 cls;否则,输出 renyao。
编写脚本 case.sh:
bash
#!/bin/bash
case $1 in
"1")
echo "banzhang"
;;
"2")
echo "cls"
;;
*)
echo "renyao"
;;
esac运行脚本:
bash
chmod 777 case.sh
./case.sh 1
# banzhangfor循环
基本语法
bash
# 基本语法 1
for (( 初始值; 循环条件; 变量变化 ))
do
# 程序
done
# 基本语法 2
for 变量 in 值1 值2 值3 ...
do
# 程序
done案例实操1 : 计算从1加到100的和。
编写脚本 for1.sh:
bash
#!/bin/bash
sum=0
for ((i=1; i<=100; i++)); do
sum=$((sum + i))
done
echo $sum运行脚本:
bash
chmod 777 for1.sh
./for1.sh
# 5050案例实操2: 打印所有输入参数
编写脚本 for2.sh:
bash
#!/bin/bash
# 检查是否有输入参数
if [ $# -eq 0 ]; then
echo "No parameters were provided."
exit 1
fi
# 打印总参数数量
echo "Total number of parameters: $#"
# 按序号逐个打印参数
echo "Parameters:"
i=1
for param in "$@"; do
echo "Parameter $i: $param"
i=$((i + 1))
done
# 打印所有参数的拼接形式
echo "All parameters as a single string (\$*): $*"
echo "All parameters individually quoted (\$@): $@"
# 处理双引号包含的 $* 和 $@
echo "All parameters as a single string in quotes (\"\$*\"): \"$*\""
echo "All parameters individually quoted (\"\$@\" with quotes):"
for param in "$@"; do
echo "\"$param\""
done运行脚本:
bash
chmod 777 print_params.sh
./print_params.sh cls mly wls
#输出:
Total number of parameters: 3
Parameters:
Parameter 1: cls
Parameter 2: mly
Parameter 3: wls
All parameters as a single string ($*): cls mly wls
All parameters individually quoted ($@): cls mly wls
All parameters as a single string in quotes ("$*"): "cls mly wls"
All parameters individually quoted ("$@" with quotes):
"cls"
"mly"
"wls"
$*和$@的行为在被双引号包含时有所不同。具体见特殊变量部分介绍。
while循环
基本语法
bash
while [ 条件判断式 ]
do
# 程序
done案例实操:计算从1加到100的和
编写脚本 while.sh:
bash
#!/bin/bash
sum=0
i=1
while [ $i -le 100 ]; do
sum=$((sum + i))
i=$((i + 1))
done
echo $sum运行脚本:
bash
chmod 777 while.sh
./while.sh
# 输出:5050read读取控制台输入
基本语法
bash
read (选项) (参数)常用选项:
-p:指定提示符,提示用户输入内容;
-t:指定读取输入的等待时间(单位:秒)。若超时未输入,命令将返回一个空值。
-s:隐藏用户输入内容,适用于输入密码等场景
参数:指定接收用户输入的变量名。
实用案例: 提示用户在 7 秒内输入姓名
bash
#!/bin/bash
# 提示用户在7秒内输入姓名
read -t 7 -p "Enter your name in 7 seconds: " NAME
# 输出用户输入的姓名
echo "Your name is: $NAME"执行脚本
bash
[root01@localhost test]$ ./read.sh
Enter your name in 7 seconds: hah
Your name is: hah
# 如果用户未在 7 秒内输入任何内容,$NAME 变量将为空
Your name is: 扩展知识
1.read 命令可以一次读取多个值,并将它们按顺序存储到指定的变量中:
bash
#!/bin/bash
# 提示用户输入多个值
read -p "Enter your first name and last name: " FIRSTNAME LASTNAME
# 输出结果
echo "First Name: $FIRSTNAME"
echo "Last Name: $LASTNAME"
bash
Enter your first name and last name: John Doe
First Name: John
Last Name: Doe2.读取多行:read 默认读取一行内容,如果需要多行输入,可结合 while 循环使用:
bash
#!/bin/bash
echo "Enter multiple lines (Ctrl+D to finish):"
# 使用 while 循环读取多行
while read LINE; do
echo "You entered: $LINE"
done3.结合条件语句,可以为未输入值的变量提供默认值:
bash
#!/bin/bash
# 提示用户输入
read -t 5 -p "Enter your favorite color: " COLOR
# 如果用户未输入,赋予默认值
COLOR=${COLOR:-"Blue"}
echo "Your favorite color is: $COLOR"
bash
# 超时或直接按下回车:
Enter your favorite color:
Your favorite color is: Blue4.变量作用域:使用 read 读取的变量默认是全局变量,若在函数中使用,需配合 local 关键字限制其作用域
Shell 脚本中定义的变量默认是全局变量,无论是在函数内部还是外部定义。
如果在函数中声明变量时使用了
local关键字,则该变量的作用域仅限于函数内部。函数外无法访问该变量:local 变量名=值
函数
系统函数 basename dirname
dirname 和 basename 是一对常用的命令,分别负责提取路径的目录部分和文件名部分。结合 dirname 和 basename,可以方便地拆分路径为目录和文件名。
一、basename
basename命令用于从路径中提取文件名。它会移除所有路径前缀(包括最后一个 '/'),并返回文件名部分。如果指定了后缀 suffix,则从文件名中去除指定的后缀。
基本语法 basename [string / pathname] [suffix]
选项说明:
string / pathname:输入的字符串或路径。
suffix(可选):指定后缀,若匹配则会从文件名中去除。
案例实操:
bash
# 截取路径中的文件名称
[root01@localhost test]$ basename /home/test/banzhang.txt
banzhang.txt
# 截取路径中的文件名称,并去除后缀
[root01@localhost test]$ basename /home/test/banzhang.txt .txt
banzhang二、dirname
dirname命令用于提取文件路径中的目录部分。它会移除路径中非目录的部分(文件名),返回剩余的路径部分。
案例实操:
bash
# 获取文件的路径部分
[root01@localhost test]$ dirname /home/test/banzhang.txt
/home/test常用的其他系统函数:
以下是一些类似于 dirname 和 basename 的常用工具命令:
realpath:解析路径,返回绝对路径
readlink:获取符号链接的目标路径
find:在目录中查找文件或目录
cut:按字段或字符分割字符串
awk 和 sed:强大的文本处理工具,后面单独介绍
自定义函数
在 Shell 脚本中可以定义自定义函数,封装一段可以复用的脚本逻辑。函数必须先声明后调用。
基本语法
bash
[ function ] funname[()] {
# 1. 函数体,执行操作
Action;
# 2. 返回值
[return int;] # 只返回整数作为状态码
# 或
echo "string_result" # 返回字符串结果
}各部分含义:
[ function ]:可选的关键字 function 用于声明函数。在 POSIX 标准下,函数的声明可以不需要 function 关键字,直接写 funname() 即可。如:
bash
function myfunc() { echo "Hello"; }
# 或直接
myfunc() { echo "Hello"; }funname[()]:funname 是函数名,自定义。括号 () 是函数调用的标志,在 Shell 中通常可以省略内部参数定义(不像其他编程语言需要明确参数)。
在 Shell 中,确实可以认为 函数是没有显式形参的。这与Shell的设计初衷:简单和轻量级、灵活性有关。函数通过1、2...等隐式参数机制实现了参数的传递和处理。
注意 :1.函数内的 1、2 等是基于函数调用时传递的参数,而不是脚本启动时的参数。参数数量不固定,$#表示参数个数,$*或$@表示所有参数。2.默认情况下,函数中的变量是全局的。可以使用
local关键字声明局部变量,避免与全局变量冲突。
Action:函数体,包含执行的操作内容。可以是任意 Shell 命令或逻辑
[return int;] :可选部分,用于指定返回值。Shell 中 return 只能返回 整数值(0-255)。其实返回值不是严格的"类型",而是进程退出码,通常用来指示函数运行的状态。0:表示成功。非零:表示错误状态或特定的返回码。
经验技巧
1.函数声明顺序:必须在调用函数之前声明函数,因为 Shell 脚本是逐行解释执行,而不是像其他语言一样先编译后执行。
2.函数返回值:函数的返回值通过 $? 系统变量获取。
可以显式使用 return n(返回值范围为 0-255)。如果未显式指定返回值,Shell 会将函数中最后一条命令的运行结果作为返回值。return仅用于返回整数,表示函数执行状态。echo可以返回字符串或复杂结果,用于调用者进一步处理:
bash
# 函数返回整数
function check_number() {
if [ $1 -gt 0 ]; then
return 0 # 正数
else
return 1 # 非正数
fi
}
check_number -5
echo $? # 输出 1
# 函数返回字符串:
function get_filename() {
echo "$(basename $1)"
}
result=$(get_filename "/home/user/file.txt")
echo $result # 输出 file.txt倒数第二行使用了
$(...)在 Shell 脚本中,不能直接将函数调用赋值给变量,原因是 函数的输出是通过标准输出 (stdout) 提供的,而不是直接作为返回值赋值。为了捕获函数的输出,必须使用命令替换 $(...) 或反引号 `...`。
案例实操 : 计算两个输入参数的和
创建脚本文件 fun.sh:
bash
#!/bin/bash
function sum() {
s=0
s=$[$1 + $2] # 使用[]进行简单数学运算
echo "$s" # 输出结果
}
# 提示用户输入两个数字
read -p "Please input the number1: " n1
read -p "Please input the number2: " n2
# 调用函数计算并显示结果
# 如果未显式指定返回值,Shell 会将函数中最后一条命令的运行结果作为返回值
sum $n1 $n2优化建议:在函数中定义局部变量,避免意外覆盖全局变量。例如:
bash
function sum() {
local s=0 # 声明局部变量
s=$[$1 + $2]
echo "$s"
}运行:
bash
[root01@localhost test]$ chmod 777 fun.sh
[root01@localhost test]$ ./fun.sh
Please input the number1: 2
Please input the number2: 5
7★Shell工具
cut
cut 的主要功能是用于"剪切"数据,从文件的每一行中提取字节、字符或字段并输出,适合处理结构化文本。默认以制表符作为分隔符。
基本用法
bash
cut [选项参数] filename常用选项:
| 选项参数 | 功能 | 案例 |
|---|---|---|
-f |
指定列号,提取指定列 | cut -f 1 cut.txt 提取文件 cut.txt 的第 1 列内容 |
-d |
指定字段分隔符,默认是制表符 \t |
cut -d ":" -f 2 /etc/passwd 使用 : 分隔符,提取第 2 列 |
-c |
提取指定的字符 | cut -c 1-3 cut.txt 提取每行前 3 个字符 |
--complement |
提取除指定列或字符外的其他内容 | cut -d ":" --complement -f 1 /etc/passwd 排除第 1 列内容 |
--output-delimiter |
自定义输出分隔符 | cut -d ":" -f 1,3 --output-delimiter="-" /etc/passwd 输出使用 - 分隔 |
案例实操
bash
# 数据准备
[root01@localhost test]$ touch cut.txt
[root01@localhost test]$ vim cut.txt
dong shen
guan zhen
wo wo
lai lai
le le
bash
# 提取第一列内容(以空格为分隔符)
[root01@localhost test]$ cut -d " " -f 1 cut.txt
dong
guan
wo
lai
le
# 提取第二列和第三列(以空格为分隔符)
[root01@localhost test]$ cut -d " " -f 2,3 cut.txt
shen
zhen
wo
lai
le
# 提取每行前 3 个字符
[root01@localhost test]$ cut -c 1-3 cut.txt
don
gua
wo
lai
le
# 提取 PATH 变量的,以":"为分隔符的,第3个及后续路径
[root01@localhost test]$ echo $PATH
/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/bin:/sbin:/root/bin
[root01@localhost test]$ echo $PATH | cut -d ":" -f 3-
/usr/bin:/usr/sbin:/bin:/sbin:/root/bin
# 自定义输出分隔符("->"),提取/etc/passwd文件的第一和第三列(以":"为分隔符)
[root01@localhost test]$ cut -d ":" -f 1,3 --output-delimiter="->" /etc/passwd
root->0
daemon->1
...awk
awk 是一款功能强大的文本处理工具,能够以逐行的方式处理文件内容,通过匹配模式和自定义操作实现灵活的文本处理。
基本用法
bash
awk [选项参数] '/pattern1/{action1} /pattern2/{action2}... ' filenamepattern:表示awk在数据中查找的内容,即匹配模式(可以是正则表达式)。
action:在找到匹配内容时,执行的一系列命令(可以是打印、计算等操作)。默认情况下,如果没有指定action,则打印匹配行。
常用选项:
| 选项参数 | 功能 | 案例 |
|---|---|---|
-F |
指定输入文件的字段分隔符 | 将/etc/passwd文件按冒号分隔并打印第一列和第七列:awk -F ':' '{print $1, $7}' /etc/passwd |
-v |
给awk脚本赋值一个外部变量 | 定义变量var并将其与第一列一起打印 : awk -v var=5 '{print $1, var}' file |
-f |
从文件中加载awk脚本 | 在文件script.awk中定义awk脚本并应用于文件:awk -f script.awk file |
-- |
结束选项参数,表明后续参数将不再被视为选项,而是输入文件名或脚本内容 | awk -- '{print $1}' --help 如果没有 --,--help 会被解析为选项,显示帮助信息 |
案例实操
bash
# 数据准备
[root01@localhost test]$ sudo cp /etc/passwd ./
# 搜索passwd文件中以root开头的所有行,并输出该行的第7列
# 这里使用了-F ':'指定了字段分隔符为冒号(:),并通过正则表达式/^root/匹配以root开头的行
[root01@localhost test]$ awk -F ':' '/^root/{print $7}' passwd
/bin/bash
/bin/bash
# 搜索passwd文件中以root开头的所有行,并输出该行的第1列和第7列,列之间用逗号分隔
[root01@localhost test]$ awk -F ':' '/^root/{print $1","$7}' passwd
root,/bin/bash
root01,/bin/bash
# 显示passwd的第一列和第七列(不指定pattern),以逗号分隔
# 且在所有行前面添加列名"user,shell",在最后一行添加dahaige,/bin/zuishuai
[root01@localhost test]$ awk -F ':' 'BEGIN{print "user,shell"} {print $1","$7} END{print "dahaige,/bin/zuishuai"}' passwd
user,shell
root,/bin/bash
bin,/sbin/nologin
...
dahaige,/bin/zuishuai
# 将passwd文件中的用户ID(第三列)增加1并输出
[root01@localhost test]$ awk -v i=1 -F ':' '{print $3+i}' passwd
1
2
3
4
...
BEGIN块在开始处理文件之前执行,通常用于初始化输出或打印列名。
END块在所有行处理完成后执行,通常用于打印总结或添加额外的输出。
awk的内置变量
awk有多个内置变量,帮助我们在处理文本时更加灵活和高效。以下是常用的几个内置变量:
| 变量名 | 说明 | 示例 |
|---|---|---|
FILENAME |
当前处理的文件名 | 每行打印当前文件名和第一列的内容:awk '{print FILENAME, $1}' file.txt |
NR |
已读记录的行号(即当前处理到的行数) | 每行打印行号和整行 内容 : awk '{print NR, $0}' file |
NF |
当前记录(行)的字段数(即列数) | 按冒号分割每行,打印行号、列数和整行内容:awk -F ':' '{print NR, NF, $0}' /etc/passwd |
FS |
输入字段分隔符(默认是空格或制表符) | 将输入字段分隔符设置为冒号后,打印第一列和第三列内容:awk 'BEGIN {FS=":"} {print $1, $3}' /etc/passwd |
RS |
输入记录分隔符(默认是换行符) | 将记录分隔符设置为双换行,打印记录号和每条记录内容:awk 'BEGIN {RS="\n\n"} {print NR, $0}' file |
示例详解
bash
# FILENAME 示例 打印当前文件名和每行的第一列内容
[root01@localhost test]$ awk '{print FILENAME, $1}' passwd
passwd root:x:0:0:root:/root:/bin/bash
passwd bin:x:1:1:bin:/bin:/sbin/nologin
...
# NR 示例 每行打印行号和整行内容。NR 表示当前行号,$0 表示整行内容
[root01@localhost test]$ awk '{print NR, $0}' /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
...
# NF 示例 按冒号分割每行,打印行号、列数和整行内容
# NF 表示当前行的字段(列)数量,NR 表示行号
[root01@localhost test]$ awk -F ':' '{print NR, NF, $0}' /etc/passwd
1 7 root:x:0:0:root:/root:/bin/bash
2 7 bin:x:1:1:bin:/bin:/sbin/nologin
...
# FS 示例 FS 指定分隔符为冒号,打印第一列(用户名)和第七列(默认登录 Shell)
[root01@localhost test]$ awk 'BEGIN {FS=":"} {print $1, $7}' /etc/passwd
root /bin/bash
bin /sbin/nologin
...
# RS 示例 RS设置输入记录分隔符为单个换行(默认值),每行被视为一条记录
# FS设置字段分隔符为冒号(:),用于分隔每行中的字段
[root01@localhost test]$ awk 'BEGIN {RS="\n"; FS=":"} {print NR, $1, $7}' /etc/passwd
1 root /bin/bash
2 bin /sbin/nologin
...
# 如果将 RS 设置为双换行符,则可以将连续的空行作为记录分隔符。例如:
awk 'BEGIN {RS="\n\n"; FS=":"} {print NR, $1, $7}' /etc/passwd
# 假设/etc/passwd 文件有多余空行,比如:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
# 执行结果:
1 root /bin/bash
2 bin /sbin/nologin
3 daemon /sbin/nologin其他常用用法
bash
# 条件语句:awk支持类似于编程语言的条件判断,如if、else等
awk '{if ($3 > 5000) print $1, $3}' passwd
# 算术运算:awk可以进行基本的算术运算
awk '{print $1, $3*2}' passwd
# 字符串操作:awk可以操作字符串,如连接、长度等
awk '{print $1, length($1)}' passwdawk是一个功能非常强大的文本处理工具,适用于从文本文件中提取、处理和分析数据,还有很多用法不赘述了。
sort
sort 命令在 Linux 中非常有用,用于对文本文件中的行进行排序,并将结果输出到标准输出或文件。sort 支持多种排序方式和功能,是日常文本处理和脚本编写的利器。
基本语法
bash
sort [选项] [文件...]常用选项:
| 选项 | 说明 |
|---|---|
-n |
按数值大小排序(数字比较) |
-r |
按降序(逆序)排序 |
-t |
设置排序时使用的分隔符 |
-k |
指定排序的键列(从 1 开始计数) |
-u |
去重(删除重复的行) |
-o |
指定输出结果的文件(原地排序) |
-c |
检查文件是否已经排序,若未排序则报错 |
-f |
忽略大小写进行排序 |
-b |
忽略每行前面的空格进行排序 |
--version-sort |
按版本号排序(适用于软件版本号等排序) |
案例实操
bash
# 数据准备
[root01@localhost test]$ touch sort.txt
[root01@localhost test]$ vim sort.txt
# 文件内容为:
bb:40:5.4
bd:20:4.2
xz:50:2.3
cls:10:3.5
ss:30:1.6
# 按照":`分隔符,第 3 列倒序排序。-t : 指定使用冒号 : 作为分隔符;-k 3 表示按第 3 列排序;-n 表示按数值大小排序;-r 表示按降序排序
[root01@localhost test]$ sort -t : -nrk 3 sort.txt
bb:40:5.4
bd:20:4.2
cls:10:3.5
xz:50:2.3
ss:30:1.6
# 去除重复行并按字母顺序排序。假设文件内容为:
apple
orange
banana
apple
grape
[root01@localhost test]$ sort -u sort.txt
apple
banana
grape
orange
# -u 选项会删除重复行。默认按字母顺序排序。
# 忽略大小写排序。假设文件内容为:
apple
Orange
Banana
APPLE
[root01@localhost test]$ sort -f sort.txt
APPLE
apple
Banana
Orange
# 按版本号排序。假设文件内容为:
file-1.2.1
file-1.2.10
file-1.10.5
file-1.3.3
[root01@localhost test]$ sort --version-sort sort.txt
file-1.2.1
file-1.2.10
file-1.3.3
file-1.10.5
# --version-sort 按版本号(逻辑顺序)排序,而不是按字典顺序。
# 检查文件是否已排序。假设文件内容为:
apple
banana
orange
grape
[root01@localhost test]$ sort -c sort.txt
sort:sort.txt:4:无序: grape
# 如果文件已排序,则无输出;如果未排序,则报错。
# 按多个字段排序。假设文件内容为:
Tom,20,85
Jerry,19,90
Spike,21,85
Tyke,20,95
# 先按分数(第 3 列)降序排序,如果分数相同,再按年龄(第 2 列)升序排序:
[root01@localhost test]$ sort -t , -k3,3nr -k2,2n sort.txt
Tyke,20,95
Jerry,19,90
Tom,20,85
Spike,21,85
# 命令解析:-t ,:指定 , 作为分隔符;-k3,3nr:-k3,3 表示只排序第 3 列,n 表示按数值排序,r 表示降序;-k2,2n:当第 3 列相同时,按第 2 列升序排序sed
sed(Stream Editor)是 Linux 中一个强大的文本处理工具,用于对文本流进行处理和转换。它能够执行查找、替换、插入、删除等操作,广泛应用于批量文本编辑、日志处理和自动化脚本中。
基本语法
bash
sed [选项] '命令' 文件...常用选项:
| 选项 | 说明 |
|---|---|
-e |
指定要执行的编辑命令(可以多次使用) |
-i |
直接修改文件(原地编辑),无需输出到新文件 |
-n |
禁止自动输出,配合 p 命令显示指定行 |
-f |
从文件中读取命令(脚本文件) |
-r |
使用扩展正则表达式(ERE) |
-s |
合并连续的空白字符(用于空白处理) |
--version |
显示 sed 版本信息 |
常用命令和案例
bash
1. 替换(s 命令).最常用的 sed 功能是替换字符串。其基本语法为:
sed 's/原字符串/新字符串/[替换选项]' 文件
默认只替换行中的第一个匹配项.全局替换:使用 g 选项替换每行的所有匹配项.忽略大小写:使用 I 选项忽略大小写
# 示例:替换第一个出现的字符串.将文件中的 "apple" 替换为 "orange"
sed 's/apple/orange/' file.txt
# 示例:全局替换所有 "apple" 为 "orange"
sed 's/apple/orange/g' file.txt
# 示例:替换并忽略大小写.将文件中的 "apple" 和 "APPLE" 替换为 "orange"
sed 's/apple/orange/I' file.txt
2. 删除行(d 命令).sed 可以用来删除文件中的某些行。常见的删除方式有删除指定行和删除匹配某模式的行
# 示例:删除第 2 行
sed '2d' file.txt
# 示例:删除所有包含 "apple" 的行
sed '/apple/d' file.txt
3. 插入和追加(i 和 a 命令).可以使用 i 命令在指定行之前插入内容,使用 a 命令在指定行之后追加内容。
# 示例:在第 2 行之前插入文本。在第 2 行之前插入 "Hello"
sed '2i Hello' file.txt
4. 替换行(c 命令).使用 c 命令可以完全替换指定行的内容。
# 示例:替换第 2 行内容.替换第 2 行的内容为 "This is a new line"
sed '2c This is a new line' file.txt
5. 显示行(p 命令).使用 p 命令配合 -n 选项,可以仅输出匹配的行,避免默认输出所有行。
# 示例:显示匹配 "apple" 的行.仅显示包含 "apple" 的行
sed -n '/apple/p' file.txt
6. 替换并修改文件(-i 选项).使用 -i 选项可以让 sed 直接修改文件,而不需要通过重定向输出到新文件。
# 示例:直接在文件中替换内容.将文件中的所有 "apple" 替换为 "orange"(原地修改)
sed -i 's/apple/orange/g' file.txt
7. 正则表达式支持.sed 支持基本正则表达式(BRE),也可以通过 -r 选项启用扩展正则表达式(ERE),使得正则表达式功能更加丰富。
# 示例:使用扩展正则表达式进行替换.使用扩展正则表达式(-r),将所有以字母开头的单词替换为 "REPLACED"
sed -r 's/\b[a-zA-Z]+\b/REPLACED/g' file.txt
8. 批量替换多个文件.通过使用通配符,sed 可以对多个文件执行相同的替换操作。
# 示例:批量替换多个文件中的 "apple" 为 "orange"
sed -i 's/apple/orange/g' *.txt
9. 显示指定行范围(n 命令).使用 n 命令,可以显示指定行范围的内容。
# 示例:显示第 2 到第 4 行
sed -n '2,4p' file.txt
10. 使用 -f 选项读取脚本.sed 允许将多个编辑命令保存在脚本文件中,然后通过 -f 选项调用该脚本执行。
# 示例:从脚本文件读取命令.从脚本文件 "script.sed" 中读取命令
sed -f script.sed file.txt
# script.sed 内容可能是这样的:
s/apple/orange/g
2d
11. 批量删除空行
sed '/^$/d' file.txtwc
wc(word count)命令用于统计文件中的信息,包括行数、单词数、字符数以及字节数等,是一个非常实用的文本分析工具。
基本语法
bash
wc [选项参数] 文件名常用选项参数说明
| 选项参数 | 功能说明 | 示例 |
|---|---|---|
-l |
统计文件行数 | wc -l filename 输出文件的总行数 |
-w |
统计文件的单词数 | wc -w filename 输出文件的单词总数 |
-m |
统计文件的字符数 | wc -m filename 输出文件的字符总数 |
-c |
统计文件的字节数 | wc -c filename 输出文件的字节总数 |
案例实操
bash
# 统计文件行数
[root01@localhost test]$ wc -l /etc/profile
78 /etc/profile # 结果表示 /etc/profile 文件有 20 行
# 统计文件的单词数
[root01@localhost test]$ wc -w /etc/profile
255 /etc/profile
# 组合选项,统计多个信息 可以组合多个选项一次性查看文件的行数、单词数和字节数:
[root01@localhost test]$ wc -lwmc /etc/profile
78 255 1855 1855 /etc/profile
# wc 命令还可以同时统计多个文件的信息。例如:
[root01@localhost test]$ wc -lwmc file1.txt file2.txt
10 50 300 300 file1.txt
15 80 500 500 file2.txt
25 130 800 800 total
# wc 经常与其他命令组合使用,比如统计当前目录下文件的总行数
[root01@localhost test]$ ls | wc -l # 输出结果表示当前目录下的文件数量
# 或者统计日志文件中包含特定关键字的行数
grep "error" logfile | wc -l正则表达式入门
正则表达式是一种强大的文本模式匹配工具,用于描述、查找符合某个模式的字符串。在Linux系统中,诸如grep、sed、awk等命令都支持正则表达式功能。正则表达式广泛用于日志分析、文本处理、数据验证等场景。
正则表达式的基本形式是通过匹配一个或多个字符来找出符合条件的字符串。简单的字符串匹配就可以使用常规表达式,不包含特殊字符时,它就匹配其自身。例如:
bash
cat /etc/passwd | grep hah # 这条命令会匹配所有包含 atguigu 的行常用特殊字符
1.特殊字符:^(匹配行首)。^ 表示匹配行的开头。例如:
bash
cat /etc/passwd | grep ^a # 这条命令会匹配所有以字母 a 开头的行。补充思考:^ 在正则表达式中是一个定位符,用于限定匹配的位置
2.特殊字符:$(匹配行尾).$ 表示匹配行的结尾。例如:
bash
cat /etc/passwd | grep t$ # 这条命令会匹配所有以字母 t 结尾的行。补充思考:^$ 匹配的是什么?^$ 会匹配空行,也就是说,匹配那些没有任何内容的行。
3.特殊字符:.(匹配任意单个字符). 匹配除换行符外的任何单个字符。例如:
bash
cat /etc/passwd | grep r..t # 这条命令会匹配包含 r 和 t 之间有两个字符的行,如 rabt、root、r1xt 等。补充:如果你需要匹配换行符,可以使用 -P(Perl兼容模式)或其他特定的工具,因为正则表达式通常不匹配换行符。
4.特殊字符:*(匹配前一个字符零次或多次)。* 与前一个字符(或表达式)一起使用,表示匹配该字符零次或多次。例如:
bash
cat /etc/passwd | grep ro*t
# 这条命令会匹配所有以 r 开头、以 t 结尾,并且 o 可以出现零次或多次的行,如 rt、rot、root、rooot 等。补充思考:.* 匹配什么?.* 匹配任意字符(除了换行符)出现零次或多次。通常用于匹配任何内容
bash
cat /etc/passwd | grep ^.*root.*$ # 这条命令会匹配所有包含 root 的行,不论 root 前后有什么字符5.特殊字符:[](字符集匹配).[] 用于匹配括号中的任意一个字符。例如:
bash
cat /etc/passwd | grep r[a,b,c]*t
# 这条命令会匹配包含字母 r 后跟 a、b 或 c 之一,并且之后跟随 t 的所有行,例如 rt、rat、rbt、rabt 等。常见的字符集包括:
[0-9]:匹配一个数字字符。
[a-z]:匹配一个小写字母。
[A-Z]:匹配一个大写字母。
[a-zA-Z]:匹配一个字母。
[0-9a-fA-F]:匹配一个十六进制字符。
补充思考:cat /etc/passwd | grep r[a-c, e-f]*t 匹配什么?
这条命令匹配包含 r 后跟 a、b、c 或 e、f 字符之一,后面跟着零个或多个字符,然后以 t 结尾的所有行
6.特殊字符:\(转义字符)。\用于转义特殊字符,使它们失去特殊含义,变成字面字符。例如,若我们想匹配包含字符 $ 的行,可以使用反斜杠来转义 $:
bash
cat /etc/passwd | grep a\$b
# 这条命令会匹配所有包含 a$b 的行。补充思考:在正则表达式中,\ 是一个非常重要的字符。许多特殊字符(如 (、)、*、+、?、{}、[、]、|等)都需要使用反斜杠来进行转义