一、MSCK刷分区
我们平时通常是通过alter table add partition方式增加Hive的分区的,但有时候会通过HDFS put/cp命令或flink、flum程序往表目录下拷贝分区目录,如果目录多,需要执行多条alter语句,非常麻烦。Hive提供了一个"Recover Partition"的功能。
MSCK(全称metastore consistency check,Hive表分区连贯性检查),运行MASK REPAIR TABLE 后,Hive会去检测这个表在HDFS上的文件,把没有写入metastore的分区信息写入到metastore。
具体语法如下:
sql
MSCK REPAIR TABLE table_name;执行示例:
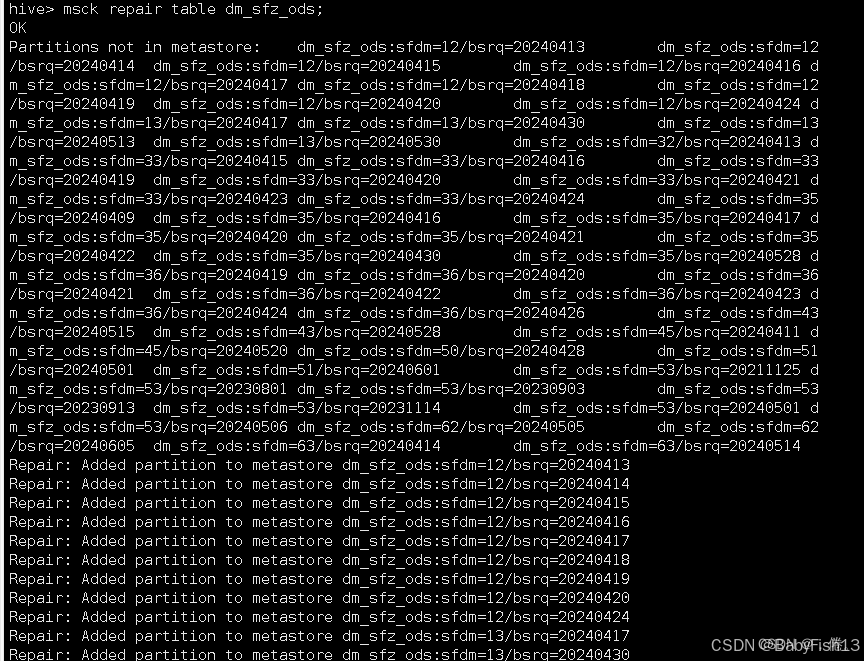
**应当注意的是,**如果元数据中存在,但实际数据路径不存在,hive会删除元数据中的消息,而不是去新增底层数据路径。反之如果元数据中不存在,单实际路径中存在,hive会新增元数据信息。
在命令运行的时候,常见一个报错为Caused by: MetaException (message:java. lang. Nul PointerException)或者return code 1 from org.apache.hadoop.hive.ql.exec这个报错是指,实际路径中存在过不去hive校验的数据,通常是路径有特殊字符、数据文件格式不对等,此时如果你已经确定数据没有问题,但就是过不去校验,可以使用下面的配置:
sql
set hive.msck.path.validation=ignore; #忽略校验错误
或者
set hive.msck.path.validation=skip; #跳过校验但是修改这个参数有个风险,就是你在未来操作这些问题分区的数据文件时,由于你当时没有排查并解决这些问题,可能导致操作报错,博主有过因为跳过验证后期在删除历史无用的分区时报空指针的问题。
原理相当简单,执行后,Hive会检测如果HDFS目录下存在但表的metastore中不存在的partition元信息,更新到metastore中。
二、一般情况下的【alter table add partition】
此外如果你只是新增一个已知的分区,你可以直接add它。
sql
ALTER TABLE table_name ADD PARTITION (partition_column='value') LOCATION 'hdfs://path/to/partition';location可以不带,默认改路径在表数据路径下,但是注意ADD PARTITION不会去直接操作对应的数据路径,和msck的时候一样,对于需要追加的新分区只操作元数据的新增。
如,使用ALTER TABLE命令指定要添加的分区:
sql
ALTER TABLE table_name ADD PARTITION (partition_column = 'partition_value');这个命令用于直接添加一个新的分区。如果需要刷新所有分区,可以先删除所有分区,然后重新加载数据:
sql
ALTER TABLE table_name DELETE PARTITION (partition_column = 'partition_value');
LOAD DATA INPATH 'path_to_data' INTO TABLE table_name PARTITION (partition_column = 'partition_value');这个流程首先删除指定分区,然后重新加载数据到该分区。
**注意:**在实际操作中,需要根据具体的Hive版本和集群配置来选择正确的方法,并确保有足够的权限执行这些操作。