前言:
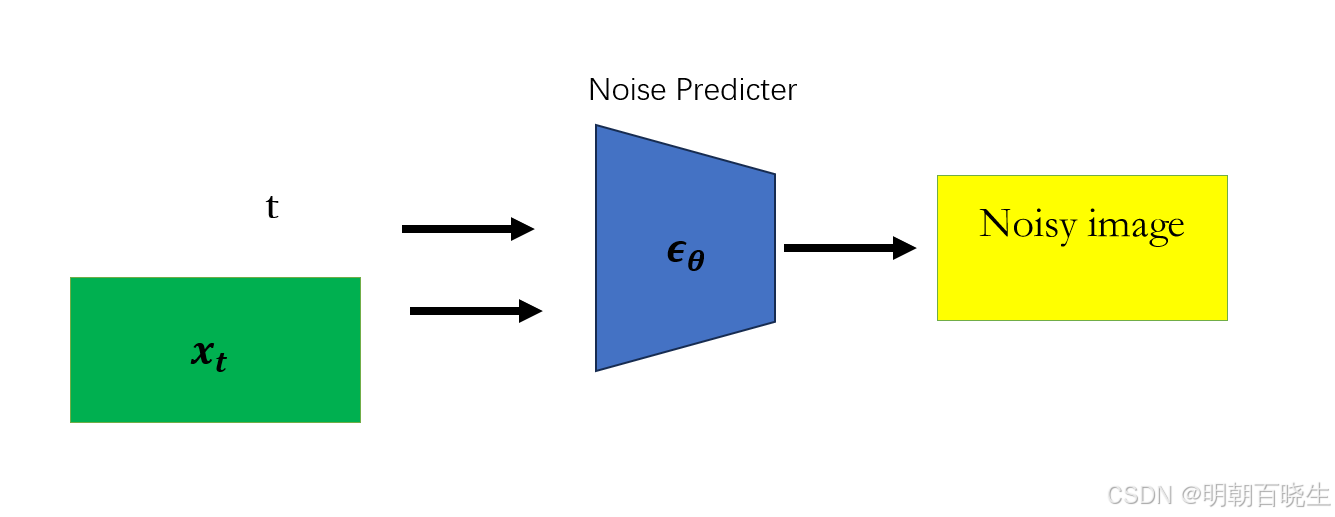
本篇主要简单介绍一下State Diffusion. State Diffuison 里面Noise Predictor 模型
主要应用了Unet 架构,提供了对应的PyTorch 代码。
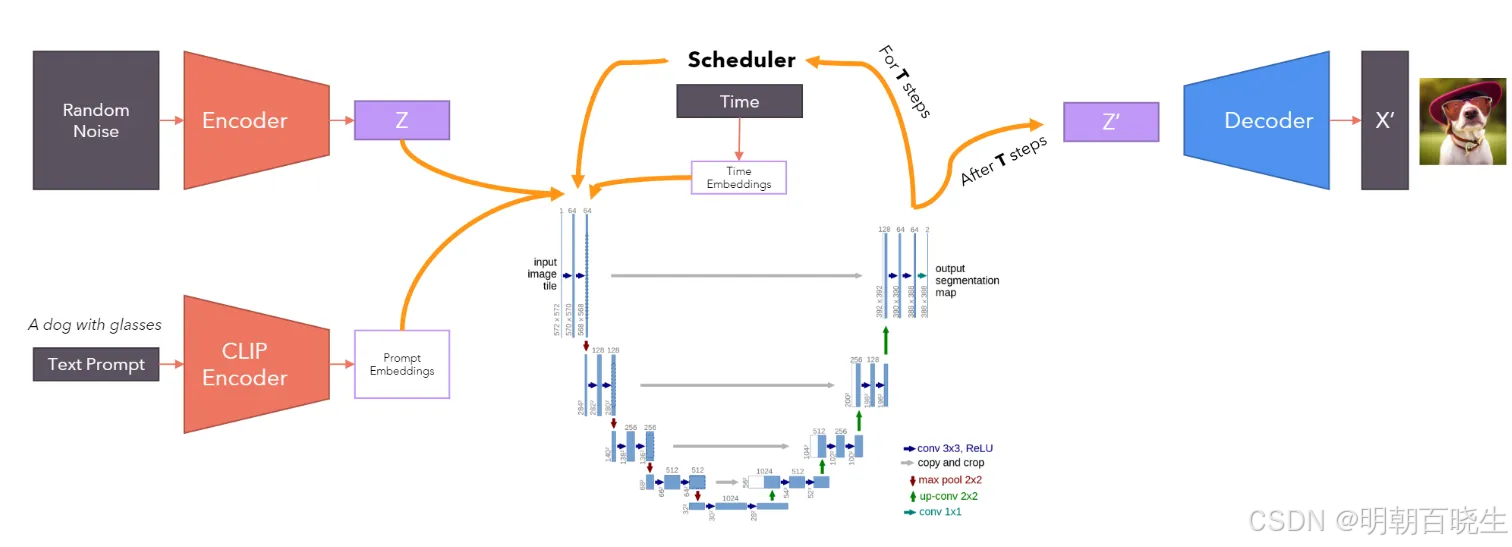
目录:
- 训练过程
- 采样过程
- U-Net
- 参考
一 训练过程(Forward Process)
1.1 论文
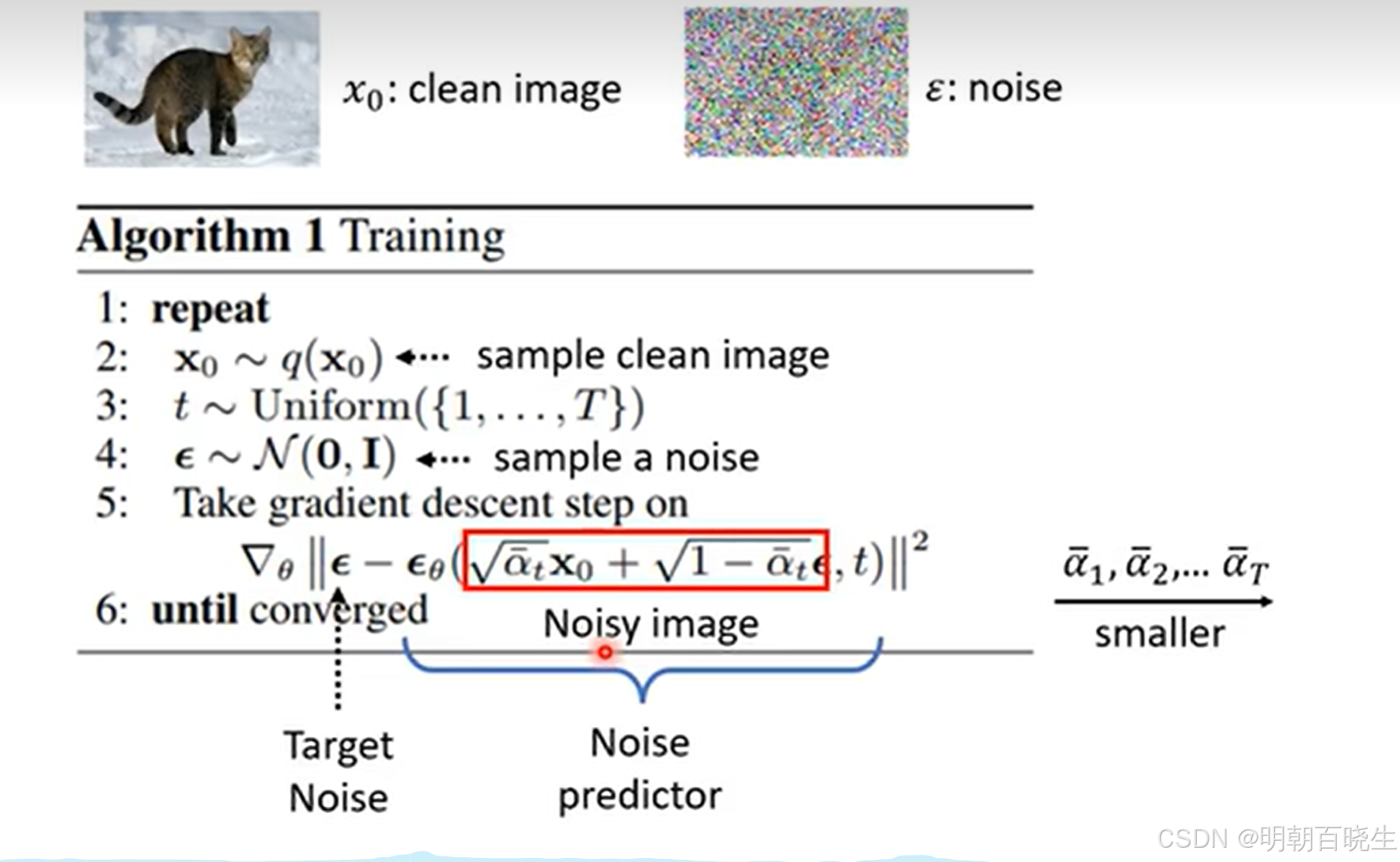
1.2 算法和训练目标
- 从我们的训练数据集中随机抽取一个图片
- 在我们的噪声(方差)计划上选择一个随机时间步长T
- 将该时间步的噪声添加到我们的数据中,通过"扩散核"模拟前向扩散过程
- 将消散后的图像传入模型,以预测我们添加的噪声
- 计算预测噪声和实际噪声之间的均方误差,并通过该目标函数优化模型的参数
- 然后重复!

最后得到Noise Predictor
1.3 超参数如何计算
可以通过下面图表示, 是一个逐渐递减的超参数,噪声比率越来越大
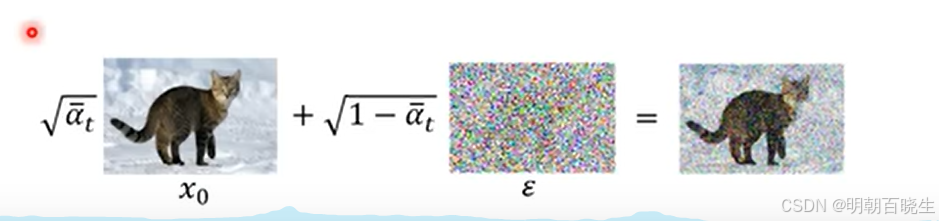
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 10 17:03:16 2024
@author: chengxf2
"""
import torch.nn as nn
import torch
class DDPM_Scheduler(nn.Module):
def __init__(self, num_time_steps: int=1000):
super().__init__()
self.beta = torch.linspace(1e-4, 0.02, num_time_steps, requires_grad=False)
alpha = 1 - self.beta
self.alpha = torch.cumprod(alpha, dim=0).requires_grad_(False)
net = DDPM_Scheduler(20)
print(net.alpha)
二 采样算法(Reverse Process)
2.1 论文

2.2 采样算法总结如下:
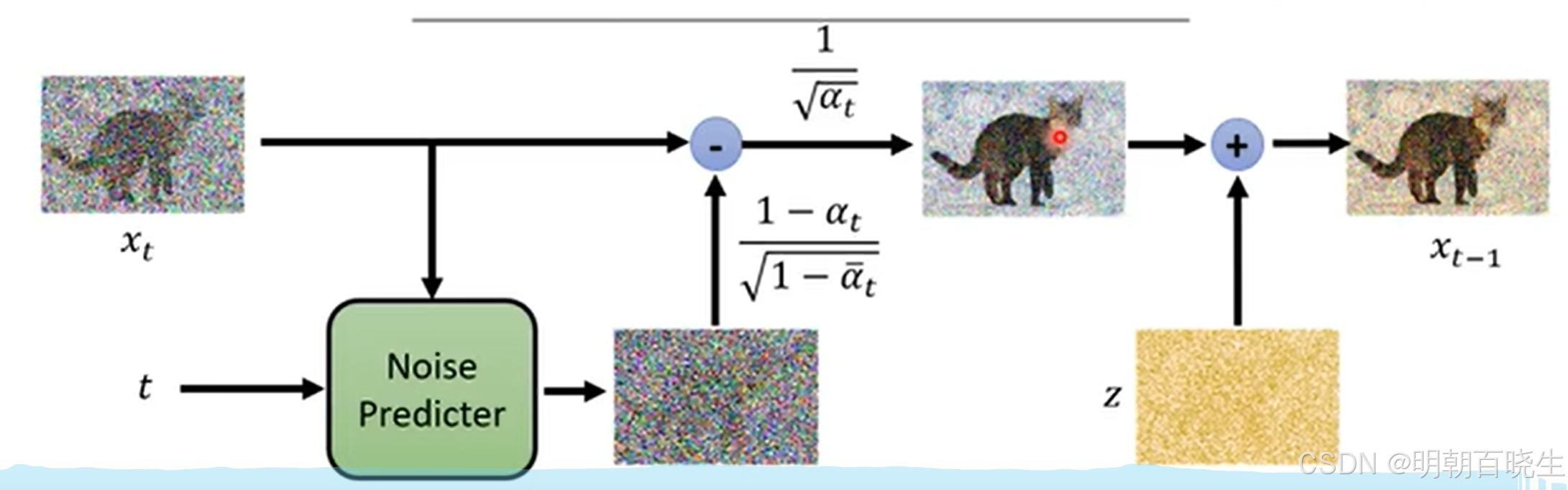
- 从标准正态分布中生成随机噪声
for t = T,...1
通过估计逆过程分布来更新 Z(图片+噪声),其中均值由上一步的 Z 参数化,方差由我 们的模型在该时间步估计的噪声参数化
添加少量噪音以增加稳定性(解释如下)
重复此操作,直到到达时间步骤 0,即恢复的图像!
2.3 添加少量噪音以增加稳定性
但直观上可以归结为一个迭代过程,我们从纯噪声开始,估计在时间步骤 t 理论上添加的噪声,然后减去它。我们这样做直到我们得到生成的样本 。我们应该注意的唯一小细节是,在我们减去估计的噪声后,我们会加回一小部分以保持过程稳定。例如,在迭代过程开始时一次性估计和减去总噪声量会导致非常不连贯的样本,因此在实践中,经验表明,在每个时间步骤中加回一点噪声并进行迭代可以生成更好的样本。
三 U-Net
参考: 一文搞定UNet------图像分割(语义分割) - 简书
DDPM 论文的作者使用了最初为医学图像分割设计的 UNET 架构来构建模型,以预测扩散逆向过程的噪声。这里面简单的介绍一下UNet 架构
UNet是一种专门用于图像分割任务的卷积神经网络(CNN)架构,最早由Olaf Ronneberger等人在2015年提出。以下是对UNet的详细介绍:
3.1 模型
灰色箭头:
复制和裁剪,最上层的箭头:一张568∗568的图片经过操作后生成一张392∗392的图片,然后和经过收缩路径后的UNet图片合起来(原图为64通道,经过收缩路径的图片为64通道,合起来为128通道)
红色箭头:为2∗2最大池化层,经过最大池化层后图片的尺寸要除以2。
绿色箭头:为上采样操作,一般使用转置卷积(注:转置卷积只是将矩阵形状进行了还原,输出的矩阵数值和原来的不一样。)
蓝绿色箭头:为一个1∗1的卷积核,输入通道数为64,输出通道数为2。可得Padding为0,Stride为
卷积计算公式:


采用的也是编码器解码器结构
左边为编码器,右边为解码器
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 2 10:10:16 2025
@author: chengxf2
"""
import copy
import os
import random
import shutil
import zipfile
from math import atan2, cos, sin, sqrt, pi, log
import cv2
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from PIL import Image
from numpy import linalg as LA
from torch import optim, nn
from torch.utils.data import DataLoader, random_split
from torch.utils.data.dataset import Dataset
from torchvision import transforms
from tqdm import tqdm
class CarvanaDataset(Dataset):
def __init__(self, root_path, limit=None):
self.root_path = root_path
self.limit = limit
self.images = sorted([root_path + "/train/" + i for i in os.listdir(root_path + "/train/")])[:self.limit]
self.masks = sorted([root_path + "/train_masks/" + i for i in os.listdir(root_path + "/train_masks/")])[:self.limit]
self.transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor()])
if self.limit is None:
self.limit = len(self.images)
def __getitem__(self, index):
img = Image.open(self.images[index]).convert("RGB")
mask = Image.open(self.masks[index]).convert("L")
return self.transform(img), self.transform(mask)
def __len__(self):
return min(len(self.images), self.limit)
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
'''
如图所示:
每一步中重复进行的双重卷积(蓝色箭头)。
它包括两个3x3的卷积,之后是ReLU激活函数:
'''
super().__init__()
self.conv_op = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
output = self.conv_op(x)
return output
class DownSample(nn.Module):
'''
下采样:
这对应于图中左侧的部分(编码路径)
在那里我们执行双重卷积和最大池化(红色箭头)。
'''
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = DoubleConv(in_channels, out_channels)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
down = self.conv(x)
p = self.pool(down)
return down, p
class UpSample(nn.Module):
'''
上采样:
这对应于图中右侧的部分(解码路径)。
这是通过反卷积(绿色箭头)后接一个双重卷积来完成的。
我们可以看到,在每次最大池化(MaxPooling)之前,都有一次复制和裁剪(灰色箭头),总共四次。
'''
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, inputs, x2):
x1 = self.up(inputs)
x = torch.cat([x1, x2], 1)
return self.conv(x)
class UNet(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.down_convolution_1 = DownSample(in_channels, out_channels=64)
self.down_convolution_2 = DownSample(in_channels=64, out_channels=128)
self.down_convolution_3 = DownSample(in_channels=128, out_channels=256)
self.down_convolution_4 = DownSample(in_channels=256, out_channels=512)
self.bottle_neck = DoubleConv(512, 1024)
self.up_convolution_1 = UpSample(1024, 512)
self.up_convolution_2 = UpSample(512, 256)
self.up_convolution_3 = UpSample(256, 128)
self.up_convolution_4 = UpSample(128, 64)
self.out = nn.Conv2d(64, out_channels=num_classes, kernel_size=1)
def forward(self, x):
down_1,p1 = self.down_convolution_1(x)
down_2, p2 = self.down_convolution_2(p1)
down_3, p3 = self.down_convolution_3(p2)
down_4, p4 = self.down_convolution_4(p3)
bott = self.bottle_neck(p4)
up_1 = self.up_convolution_1(bott, down_4)
up_2 = self.up_convolution_2(up_1, down_3)
up_3 = self.up_convolution_3(up_2, down_2)
up_4 = self.up_convolution_4(up_3, down_1)
out = self.out(up_4)
return out
def dice_coefficient(prediction, target, epsilon=1e-07):
prediction_copy = prediction.clone()
prediction_copy[prediction_copy < 0] = 0
prediction_copy[prediction_copy > 0] = 1
intersection = abs(torch.sum(prediction_copy * target))
union = abs(torch.sum(prediction_copy) + torch.sum(target))
dice = (2. * intersection + epsilon) / (union + epsilon)
return dice
def drawloss():
epochs_list = list(range(1, EPOCHS + 1))
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(epochs_list, train_losses, label='Training Loss')
plt.plot(epochs_list, val_losses, label='Validation Loss')
plt.xticks(ticks=list(range(1, EPOCHS + 1, 1)))
plt.title('Loss over epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.grid()
plt.tight_layout()
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs_list, train_dcs, label='Training DICE')
plt.plot(epochs_list, val_dcs, label='Validation DICE')
plt.xticks(ticks=list(range(1, EPOCHS + 1, 1)))
plt.title('DICE Coefficient over epochs')
plt.xlabel('Epochs')
plt.ylabel('DICE')
plt.grid()
plt.legend()
plt.tight_layout()
plt.show()
epochs_list = list(range(1, EPOCHS + 1))
plt.figure(figsize=(12, 5))
plt.plot(epochs_list, train_losses, label='Training Loss')
plt.plot(epochs_list, val_losses, label='Validation Loss')
plt.xticks(ticks=list(range(1, EPOCHS + 1, 1)))
plt.ylim(0, 0.05)
plt.title('Loss over epochs (zoomed)')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.grid()
plt.tight_layout()
plt.legend()
plt.show()
def random_images_inference(image_tensors, mask_tensors, image_paths, model_pth, device):
model = UNet(in_channels=3, num_classes=1).to(device)
model.load_state_dict(torch.load(model_pth, map_location=torch.device(device)))
transform = transforms.Compose([
transforms.Resize((512, 512))
])
# Iterate for the images, masks and paths
for image_pth, mask_pth, image_paths in zip(image_tensors, mask_tensors, image_paths):
# Load the image
img = transform(image_pth)
# Predict the imagen with the model
pred_mask = model(img.unsqueeze(0))
pred_mask = pred_mask.squeeze(0).permute(1,2,0)
# Load the mask to compare
mask = transform(mask_pth).permute(1, 2, 0).to(device)
print(f"Image: {os.path.basename(image_paths)}, DICE coefficient: {round(float(dice_coefficient(pred_mask, mask)),5)}")
# Show the images
img = img.cpu().detach().permute(1, 2, 0)
pred_mask = pred_mask.cpu().detach()
pred_mask[pred_mask < 0] = 0
pred_mask[pred_mask > 0] = 1
plt.figure(figsize=(15, 16))
plt.subplot(131), plt.imshow(img), plt.title("original")
plt.subplot(132), plt.imshow(pred_mask, cmap="gray"), plt.title("predicted")
plt.subplot(133), plt.imshow(mask, cmap="gray"), plt.title("mask")
plt.show()
def test(trained_model):
test_running_loss = 0
test_running_dc = 0
with torch.no_grad():
for idx, img_mask in enumerate(tqdm(test_dataloader, position=0, leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = trained_model(img)
loss = criterion(y_pred, mask)
dc = dice_coefficient(y_pred, mask)
test_running_loss += loss.item()
test_running_dc += dc.item()
test_loss = test_running_loss / (idx + 1)
test_dc = test_running_dc / (idx + 1)
if __name__ == "__main__":
print(os.listdir("../input/carvana-image-masking-challenge/"))
DATASET_DIR = '../input/carvana-image-masking-challenge/'
WORKING_DIR = '/kaggle/working/'
if len(os.listdir(WORKING_DIR)) <= 1:
with zipfile.ZipFile(DATASET_DIR + 'train.zip', 'r') as zip_file:
zip_file.extractall(WORKING_DIR)
with zipfile.ZipFile(DATASET_DIR + 'train_masks.zip', 'r') as zip_file:
zip_file.extractall(WORKING_DIR)
print(
len(os.listdir(WORKING_DIR + 'train')),
len(os.listdir(WORKING_DIR + 'train_masks'))
)
train_dataset = CarvanaDataset(WORKING_DIR)
generator = torch.Generator().manual_seed(25)
train_dataset, test_dataset = random_split(train_dataset, [0.8, 0.2], generator=generator)
test_dataset, val_dataset = random_split(test_dataset, [0.5, 0.5], generator=generator)
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cuda":
num_workers = torch.cuda.device_count() * 4
LEARNING_RATE = 3e-4
BATCH_SIZE = 8
POCHS = 10
train_losses = []
train_dcs = []
val_losses = []
val_dcs = []
LEARNING_RATE = 3e-4
BATCH_SIZE = 8
train_dataloader = DataLoader(dataset=train_dataset,
num_workers=num_workers, pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
val_dataloader = DataLoader(dataset=val_dataset,
num_workers=num_workers, pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
test_dataloader = DataLoader(dataset=test_dataset,
num_workers=num_workers, pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
model = UNet(in_channels=3, num_classes=1).to(device)
optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE)
criterion = nn.BCEWithLogitsLoss()
for epoch in tqdm(range(EPOCHS)):
model.train()
train_running_loss = 0
train_running_dc = 0
for idx, img_mask in enumerate(tqdm(train_dataloader, position=0, leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
optimizer.zero_grad()
dc = dice_coefficient(y_pred, mask)
loss = criterion(y_pred, mask)
train_running_loss += loss.item()
train_running_dc += dc.item()
loss.backward()
optimizer.step()
train_loss = train_running_loss / (idx + 1)
train_dc = train_running_dc / (idx + 1)
train_losses.append(train_loss)
train_dcs.append(train_dc)
model.eval()
val_running_loss = 0
val_running_dc = 0
with torch.no_grad():
for idx, img_mask in enumerate(tqdm(val_dataloader, position=0, leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
loss = criterion(y_pred, mask)
dc = dice_coefficient(y_pred, mask)
val_running_loss += loss.item()
val_running_dc += dc.item()
val_loss = val_running_loss / (idx + 1)
val_dc = val_running_dc / (idx + 1)
val_losses.append(val_loss)
val_dcs.append(val_dc)
print("-" * 30)
print(f"Training Loss EPOCH {epoch + 1}: {train_loss:.4f}")
print(f"Training DICE EPOCH {epoch + 1}: {train_dc:.4f}")
print("\n")
print(f"Validation Loss EPOCH {epoch + 1}: {val_loss:.4f}")
print(f"Validation DICE EPOCH {epoch + 1}: {val_dc:.4f}")
print("-" * 30)
# Saving the model
torch.save(model.state_dict(), 'my_checkpoint.pth')
n = 10
image_tensors = []
mask_tensors = []
image_paths = []
for _ in range(n):
random_index = random.randint(0, len(test_dataloader.dataset) - 1)
random_sample = test_dataloader.dataset[random_index]
image_tensors.append(random_sample[0])
mask_tensors.append(random_sample[1])
image_paths.append(random_sample[2])
model_path = '/kaggle/working/my_checkpoint.pth'
random_images_inference(image_tensors, mask_tensors, image_paths, model_path, device="cpu")四 参考:
3.【生成式AI】Diffusion Model 原理剖析 (1_4)_哔哩哔哩_bilibili
https://towardsdatascience.com/diffusion-model-from-scratch-in-pytorch-ddpm-9d9760528946