卷积神经04-TensorFlow环境安装
文章目录
- 卷积神经04-TensorFlow环境安装
-
- 0-核心知识脉络
- 1-参考网址
- 2-手动安装Tensorflow-GPU
- 3-Tensorflow环境-探索过程
- 4-如何使用toml进行版本管理
-
- [1. 定义依赖项的版本](#1. 定义依赖项的版本)
-
- [示例:Rust 项目中的 `Cargo.toml`](#示例:Rust 项目中的
Cargo.toml) - [示例:Python 项目中的 `pyproject.toml`](#示例:Python 项目中的
pyproject.toml)
- [示例:Rust 项目中的 `Cargo.toml`](#示例:Rust 项目中的
- [2. 使用版本范围](#2. 使用版本范围)
- [3. 使用版本锁定(锁定文件)](#3. 使用版本锁定(锁定文件))
-
- [示例:Rust 的 `Cargo.lock`](#示例:Rust 的
Cargo.lock) - [示例:Python 的 `poetry.lock`](#示例:Python 的
poetry.lock)
- [示例:Rust 的 `Cargo.lock`](#示例:Rust 的
- [4. 使用动态版本](#4. 使用动态版本)
-
- [示例:Python 中的 `*` 表示最新版本](#示例:Python 中的
*表示最新版本)
- [示例:Python 中的 `*` 表示最新版本](#示例:Python 中的
- [5. 使用环境变量或占位符](#5. 使用环境变量或占位符)
- 总结
- 5-过程问题解决
-
- 1-Pycharm直接点击python文件提示安装的包在什么位置
- [2-AttributeError: module 'numpy.typing' has no attribute 'ArrayLike'](#2-AttributeError: module 'numpy.typing' has no attribute 'ArrayLike')
-
- [1. 检查 NumPy 版本](#1. 检查 NumPy 版本)
- [2. 升级 NumPy](#2. 升级 NumPy)
- [3. 检查 TensorFlow 和 NumPy 的兼容性](#3. 检查 TensorFlow 和 NumPy 的兼容性)
- [4. 重新安装 TensorFlow 和 NumPy](#4. 重新安装 TensorFlow 和 NumPy)
- [5. 检查 Python 环境](#5. 检查 Python 环境)
- [6. 检查是否有多个 NumPy 安装](#6. 检查是否有多个 NumPy 安装)
- [7. 验证问题是否解决](#7. 验证问题是否解决)
- [8. **如果问题仍然存在**](#8. 如果问题仍然存在)
- 9-总结
- [2-ImportError: cannot import name 'Self' from 'typing_extensions'](#2-ImportError: cannot import name 'Self' from 'typing_extensions')
- [3-ValueError: numpy.dtype size changed, may indicate binary incompatibility](#3-ValueError: numpy.dtype size changed, may indicate binary incompatibility)
- 4-python验证tensorflow是否支持GPU
-
- [1. 检查 TensorFlow 版本](#1. 检查 TensorFlow 版本)
- [2. 检查 GPU 是否可用](#2. 检查 GPU 是否可用)
- [3. 检查 TensorFlow 是否在 GPU 上运行](#3. 检查 TensorFlow 是否在 GPU 上运行)
- [4. 检查 TensorFlow 是否使用了 GPU](#4. 检查 TensorFlow 是否使用了 GPU)
- [5. 检查 TensorFlow 是否正确配置了 CUDA 和 cuDNN](#5. 检查 TensorFlow 是否正确配置了 CUDA 和 cuDNN)
- 6.总结
0-核心知识脉络
- 1)根据自己电脑的CUDA版本安装对应版本的Tensorflow,充分的使用GPU性能
- 2)安装Tensorflow之前,电脑要先安装【CUDA ToolKit】+【cuDNN】GPU依赖(本地已经安装)
- 3)但是Tensorflow-GPU不能直接安装(不再支持直接安装),所以要先安装对应的【tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl】依赖
- 4)因为是在Anaconda环境中,要先安装对应的cudatoolkit依赖
- 5)过程不要使用pycharm对应的依赖仓库管理依赖
- 6)python项目可以使用toml进行依赖管理

1-参考网址
- TensorFlow 保姆级教程:https://blog.csdn.net/mng123/article/details/144842102
2-手动安装Tensorflow-GPU
1-关于Tensorflow的官网介绍
下面的这段话是句【屁话】,让我多花了两个小时!
-
CUDA是NVIDIA推出的一种并行计算平台和编程模型,用于在GPU上进行通用计算。需要根据TensorFlow版本来安装对应的CUDA版本。例如,TensorFlow 2.x通常支持CUDA 11.x。你可以从NVIDIA官方网站下载CUDA Toolkit进行安装。
-
cuDNN(CUDA Deep Neural Network library)是NVIDIA专门为深度学习框架优化的库。在安装完CUDA后,需要注册NVIDIA开发者账号并下载与CUDA版本对应的cuDNN库。下载完成后,按照NVIDIA提供的安装说明将cuDNN解压并复制到CUDA的相应目录下。
安装GPU版本的TensorFlow:在命令行中输入
pip install tensorflow-gpu
2-安装Tensorflow-GPU版本
因为我电脑的环境版本是【Python3.9】+【cuda=11.8】,因为已经安装过了【CUDA ToolKit11.8】+【cuDNN】,所以可以直接安装【GPU版本Tensorflow】
1-安装Tensorflow-GPU版本脉络
- 1)Anacanda配置【Python指定版本】-当前Python3.9
- 2)下载Python3.9对应的Tensorflow-GPU的依赖文件:tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl
- 3)pip安装对应的Tensorflow-GPU的依赖文件:tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl
- 4)pip安装Tensorflow-GPU
- 5)解决protobuf版本问题
- 6)Tensorflow-GPU是否可用验证
2-安装Tensorflow-GPU版本细节
1-Anacanda配置【Python指定版本】-当前Python3.9
# 创建虚拟环境
conda create -n TF3.9 python=3.9
# 启用虚拟环境
conda activate TF3.92-下载Python3.9对应的Tensorflow-GPU的依赖文件:tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl
Tensorflow-GPU的安装地址::https://www.tensorflow.org/install/pip?hl=zh-cn#system-install

3-pip安装对应的Tensorflow-GPU的依赖文件:tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl
pip install D:\TT_RUNTIME+\Anaconda3\Scripts\tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl4-pip安装Tensorflow-GPU
pip install tensorflow-gpu5-解决protobuf版本问题
pip install protobuf==3.20.36-Tensorflow-GPU是否可用验证
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
# 检查是否有可用的 GPU
gpus = tf.config.list_physical_devices('GPU')
if gpus:
print("GPU is available")
# 打印 GPU 设备信息
for gpu in gpus:
print("Name:", gpu.name, "Type:", gpu.device_type)
else:
print("GPU is NOT available")
'''
# 1-安装tensorflow显示GPU不可用
- TensorFlow version: 2.18.0
- GPU is NOT available
# 2-安装tensorflow成功后显示
- TensorFlow version: 2.6.0
- GPU is available
'''8)安装cuda对应的cudatoolkit
conda install cudatoolkit=11.8 -c pytorch9)然后再安装对应的tensorflow-gpu
pip install tensorflow-gpu3-Tensorflow环境-探索过程
我想使用【Python3.9】这样就可以和【Pytorch当时实践的python环境保持一致】
1-访问tensorflow官网
tensorflow官网支持文档:https://www.tensorflow.org/install/pip?hl=zh-cn#system-install
- tensorflow版本安装-页面1
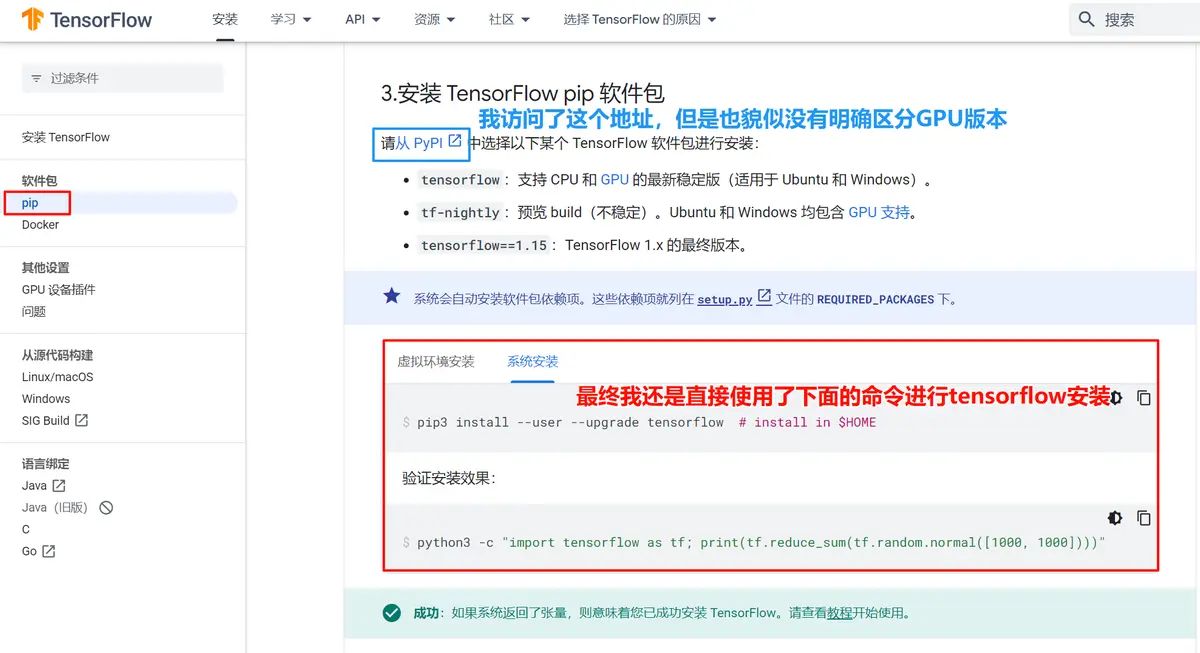
- tensorflow版本安装-页面2
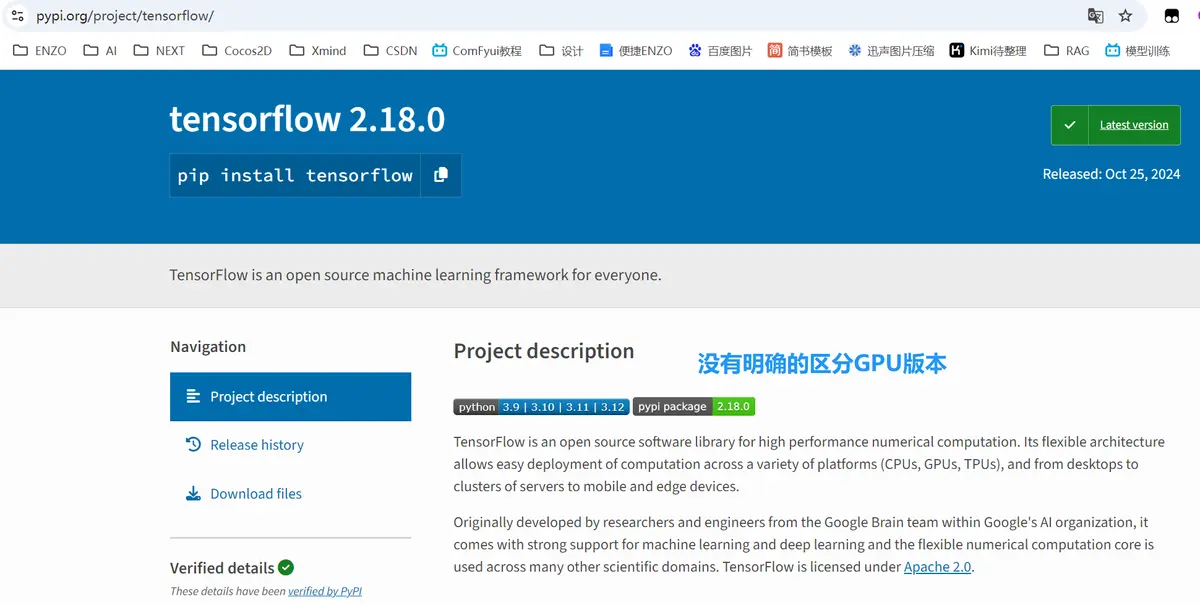
- tensorflow版本安装-页面3
访问tensorflow-gpu地址:https://pypi.org/project/tensorflow-gpu/
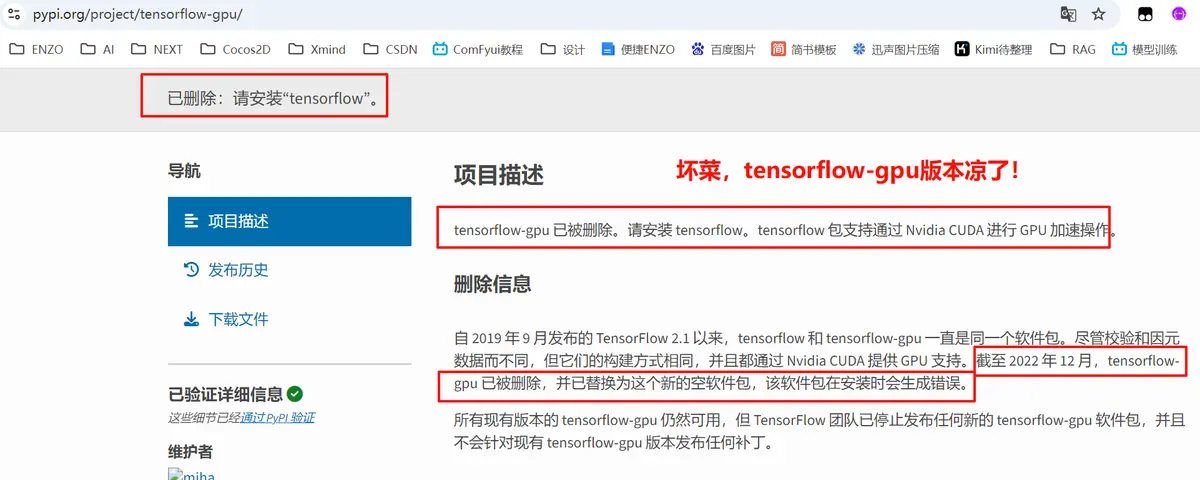
2-安装Tensorflow-GPU
安装过程还是出现了很多弯路,在此仅记录成功过程,有助理解Tensorflow-GPU安装过程的思路
1)安装Tensorflow之前,电脑要先安装【CUDA ToolKit】+【cuDNN】GPU依赖(本地已经安装)
具体可以参考【卷积神经02-CUDA环境安装】:https://blog.csdn.net/2301_77717148/article/details/145083431
2)但是Tensorflow-GPU不能直接安装(不再支持直接安装),所以要先安装对应的【tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl】依赖
pip install D:\TT_RUNTIME+\Anaconda3\Scripts\tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl3)因为是在Anaconda环境中,要先安装对应的cudatoolkit依赖
conda install cudatoolkit=11.8 -c pytorch4)验证是否支持GPU
注意:TensorFlow的版本应该就是【tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl】中【gpu-2.6.0】对应的GPU版本;其中【cp39】代表【Python对应版本】
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
# 检查是否有可用的 GPU
gpus = tf.config.list_physical_devices('GPU')
if gpus:
print("GPU is available")
# 打印 GPU 设备信息
for gpu in gpus:
print("Name:", gpu.name, "Type:", gpu.device_type)
else:
print("GPU is NOT available")
'''
# 1-安装tensorflow显示GPU不可用
- TensorFlow version: 2.18.0
- GPU is NOT available
# 2-安装tensorflow成功后显示
- TensorFlow version: 2.6.0
- GPU is available
'''5)安装Tensorflow-GPU安装失败
- 【怀疑】可能还是GPU版本没有成功安装
再次查看tensorflow官网支持文档:https://www.tensorflow.org/install/pip?hl=zh-cn#system-install
- 发现了GPU的安装说明,这时才发现这个就是传说中的【单独支持】;下载对应的软件后,手动安装
6)对应配置的含义

7)手动安装GPU版本软件
需要将安装好的文件【tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl】放置到【Anacanda】的Scripts目录中,我的安装路径为:D:\TT_RUNTIME+\Anaconda3\Scripts
- 然后执行具体文件安装
注意:执行的是一个具体文件
pip install D:\TT_RUNTIME+\Anaconda3\Scripts\tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl8)安装cuda对应的cudatoolkit
conda install cudatoolkit=11.8 -c pytorch9)然后再安装对应的tensorflow-gpu
pip install tensorflow-gpu4-如何使用toml进行版本管理
使用 TOML(Tom's Obvious, Minimal Language)进行版本管理通常涉及到在配置文件中定义或引用软件包或依赖项的版本号。TOML 本身是一种轻量级配置文件格式,常用于项目的配置文件中,例如 Cargo.toml(Rust 语言的包管理器)或 pyproject.toml(Python 项目)。
以下是使用 TOML 进行版本管理的一些常见场景和方法:
1. 定义依赖项的版本
在 Cargo.toml(Rust 项目的配置文件)或 pyproject.toml(Python 项目)中,你可以定义依赖项的版本号。
示例:Rust 项目中的 Cargo.toml
toml
[package]
name = "my_project"
version = "0.1.0"
edition = "2021"
[dependencies]
rand = "0.8.5" # 指定版本为 0.8.5
serde = { version = "1.0", features = ["derive"] } # 指定版本为 1.0,并启用某些特性
[dev-dependencies]
criterion = "0.3.5" # 开发依赖项示例:Python 项目中的 pyproject.toml
toml
[project]
name = "my_python_project"
version = "1.0.0"
dependencies = [
"requests>=2.25.1", # 指定版本 >= 2.25.1
"numpy==1.21.0" # 指定确切版本
]2. 使用版本范围
你可以使用版本范围来指定依赖项的版本,常见的符号包括:
^:表示兼容版本,例如^1.2.3表示>=1.2.3且<2.0.0。~:表示次要版本更新,例如~1.2.3表示>=1.2.3且<1.3.0。>=:表示大于或等于某个版本的版本。<=:表示小于或等于某个版本的版本。
示例:
toml
[dependencies]
rand = "^0.8.5" # 表示 0.8.5 及以上,但低于 0.9.0
serde = "~1.0" # 表示 1.0.x 版本,但不包括 1.1.0
numpy = ">=1.18.0, <1.22.0" # 表示版本范围在 1.18.0 到 1.22.0 之间3. 使用版本锁定(锁定文件)
在某些情况下,你可能希望锁定依赖项的版本,以确保项目在不同环境中的一致性。例如,Rust 使用 Cargo.lock 文件来锁定依赖项的版本,而 Python 使用 Pipfile.lock 或 poetry.lock。
示例:Rust 的 Cargo.lock
Cargo.lock 文件会自动生成,并包含所有依赖项的确切版本。
toml
# This file is automatically @generated by Cargo.
# It is not intended for manual editing.
[[package]]
name = "rand"
version = "0.8.5"示例:Python 的 poetry.lock
poetry.lock 文件会自动生成,并包含所有依赖项的确切版本。
toml
[[package]]
name = "requests"
version = "2.25.1"4. 使用动态版本
在一些包管理器中,你可以使用动态版本号来表示最新的版本或特定的版本范围。
示例:Python 中的 * 表示最新版本
toml
[project]
dependencies = [
"requests==2.25.*", # 表示 2.25.x 的最新版本
"numpy==1.*" # 表示 1.x 的最新版本
]5. 使用环境变量或占位符
在一些情况下,你可以使用环境变量或占位符来动态指定版本号。
示例:
toml
[dependencies]
my_library = { version = "${MY_LIBRARY_VERSION}" } # 使用环境变量总结
使用 TOML 进行版本管理的关键在于:
- 在配置文件中明确指定依赖项的版本号。
- 使用版本范围符号(如
^,~,>=,<=)来灵活管理版本。 - 使用锁定文件(如
Cargo.lock,poetry.lock)来确保版本一致性。 - 在需要时使用环境变量或占位符动态指定版本。
通过这些方法,你可以有效地管理项目中的依赖项版本,确保项目的稳定性和可维护性。
5-过程问题解决
1-Pycharm直接点击python文件提示安装的包在什么位置
- 1)Pycharm提示时点击安装的包,不在本机的默认python依赖仓库中,也不再Anacanda依赖仓库中
- 2)而是在【Pycharm】对应的依赖仓库中,最好是不要使用【Pycharm】对应的依赖,这个不容易进行版本管理
- 3)我本地对应的【Pycharm】依赖仓库地址:D:\TT_INSTALL+\Pycharm2024Pro\PyCharm2024.1.4\plugins\python\helpers\typeshed\stubs
2-AttributeError: module 'numpy.typing' has no attribute 'ArrayLike'
从错误信息来看,问题出在 numpy.typing 模块中缺少 ArrayLike 属性。这通常是由于 NumPy 版本不兼容或安装不完整导致的。以下是解决此问题的步骤:
1. 检查 NumPy 版本
ArrayLike 是 NumPy 1.20.0 及以上版本引入的特性。如果您的 NumPy 版本过低,可能会导致此问题。
运行以下代码检查 NumPy 版本:
python
import numpy as np
print(np.__version__)如果版本低于 1.20.0,请升级 NumPy。
2. 升级 NumPy
使用以下命令升级 NumPy 到最新版本:
bash
pip install --upgrade numpy如果使用的是 Anaconda 环境,可以使用以下命令:
bash
conda update numpy3. 检查 TensorFlow 和 NumPy 的兼容性
TensorFlow 和 NumPy 的版本需要兼容。如果升级 NumPy 后问题仍然存在,可能是 TensorFlow 版本与 NumPy 版本不匹配。
您可以参考 TensorFlow 官方文档中的 兼容性指南 来确认 TensorFlow 和 NumPy 的兼容版本。
4. 重新安装 TensorFlow 和 NumPy
如果问题仍未解决,可以尝试重新安装 TensorFlow 和 NumPy:
bash
pip uninstall tensorflow numpy
pip install tensorflow numpy5. 检查 Python 环境
确保您使用的是正确的 Python 环境。如果您在虚拟环境中工作,请激活虚拟环境后再运行代码:
bash
# 激活虚拟环境
source venv/bin/activate # Linux/macOS
venv\Scripts\activate # Windows6. 检查是否有多个 NumPy 安装
有时,系统中可能存在多个 NumPy 安装,导致冲突。您可以通过以下命令检查 NumPy 的安装路径:
python
import numpy as np
print(np.__file__)如果发现多个 NumPy 安装路径,请卸载多余的版本:
bash
pip uninstall numpy7. 验证问题是否解决
完成上述步骤后,重新运行您的代码,检查问题是否解决。
8. 如果问题仍然存在
如果问题仍未解决,可能是 TensorFlow 或 NumPy 的安装文件损坏。您可以尝试以下操作:
-
删除 TensorFlow 和 NumPy 的缓存文件:
bashpip cache purge -
重新安装 TensorFlow 和 NumPy。
9-总结
此问题通常是由于 NumPy 版本过低或 TensorFlow 与 NumPy 版本不兼容导致的。通过升级 NumPy、重新安装 TensorFlow 和 NumPy,以及检查 Python 环境,应该可以解决此问题。
2-ImportError: cannot import name 'Self' from 'typing_extensions'
看起来你在导入 TensorFlow 时遇到了一个 ImportError,错误提示是无法从 typing_extensions 模块中导入名为 'Self' 的名称。这个问题可能是由于 typing_extensions 模块的版本不兼容引起的。
以下是一些可能的解决方案:
-
更新
typing_extensions模块 :确保你使用的
typing_extensions模块是最新版本。你可以通过以下命令来更新它:bashpip install --upgrade typing_extensions -
检查 Python 版本 :
确保你使用的 Python 版本与 TensorFlow 兼容。TensorFlow 通常要求 Python 3.7 或更高版本。你可以检查你的 Python 版本:
bashpython --version -
检查 TensorFlow 安装 :
确保 TensorFlow 正确安装。你可以尝试卸载并重新安装 TensorFlow:
bashpip uninstall tensorflow pip install tensorflow -
虚拟环境 :
如果你在使用虚拟环境,确保你激活了正确的环境,并且所有依赖项都已正确安装。
-
检查路径冲突 :
从错误信息来看,你有两个不同的 Python 环境:
C:\Users\popyu\AppData\Roaming\Python\Python39\site-packagesD:\TT_RUNTIME+\Anaconda3\envs\CNNPY3.9\lib\site-packages
这可能意味着你的系统中存在多个 Python 环境,导致模块冲突。确保你只使用一个环境,并且所有包都安装在这个环境中。
-
手动安装
typing_extensions:如果更新不解决问题,可以尝试手动安装特定版本的
typing_extensions,例如:bashpip install typing_extensions==4.2.0 -
检查代码中是否有冲突的导入 :
确保你的代码中没有重复或冲突的导入语句。
如果以上方法都不能解决问题,请提供更多的环境信息,比如操作系统的版本、Python 的版本、TensorFlow 的版本等,这样可以帮助更准确地诊断问题。
3-ValueError: numpy.dtype size changed, may indicate binary incompatibility
看起来你在使用 TensorFlow 时遇到了一个与 NumPy 和 h5py 库相关的二进制不兼容性问题。具体错误是 numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject*。这通常是由于不同版本的库之间存在不兼容性导致的。
以下是一些可能的解决方案:
- 确保所有库版本兼容:
- 确保你使用的 TensorFlow、NumPy 和 h5py 版本是兼容的。你可以参考 TensorFlow 的官方文档,查看推荐的版本组合。
-
升级或降级 NumPy:
-
有时,升级或降级 NumPy 到特定版本可以解决兼容性问题。例如,尝试安装 NumPy 1.19.5:
bashpip install numpy==1.19.5
-
-
升级 h5py:
-
有时,重新安装 h5py 可以解决二进制不兼容性问题:
bashpip install --upgrade h5py
-
-
重新安装 h5py:
-
有时,重新安装 h5py 可以解决二进制不兼容性问题:
bashpip uninstall h5py pip install h5py
-
-
检查环境变量和路径:
- 确保你的 Python 环境变量和路径没有冲突,特别是如果你有多个 Python 版本或虚拟环境。
-
使用 conda 管理环境:
-
如果你使用 Anaconda,尝试创建一个新的环境,并安装推荐的库版本:
bashconda create -n tensorflow_env python=3.9 conda activate tensorflow_env pip install tensorflow
-
-
检查 C 头文件和库:
- 确保你的系统上安装了正确的 C 头文件和库,特别是 HDF5 库,因为 h5py 依赖于它。
-
查看相关问题和解决方案:
- 搜索类似的问题,看看其他人是如何解决这个问题的。例如,在 Stack Overflow 或 GitHub Issues 上寻找相关的讨论。
以下是一个示例命令,用于创建一个新的虚拟环境并安装 TensorFlow 及其依赖项:
bash
python -m venv tf_env
source tf_env/bin/activate # 在 Windows 上使用 `tf_env\Scripts\activate`
pip install tensorflow希望这些建议能帮助你解决问题。如果问题仍然存在,请提供更多的环境信息和错误日志,以便进一步诊断。
4-python验证tensorflow是否支持GPU
要验证 TensorFlow 是否支持 GPU,您可以按照以下步骤进行操作。假设您已经安装了 TensorFlow 和相关的 GPU 驱动程序(如 NVIDIA 驱动程序、CUDA 和 cuDNN)。
1. 检查 TensorFlow 版本
首先,确保您使用的是支持 GPU 的 TensorFlow 版本。通常,TensorFlow 2.x 版本都支持 GPU。
python
import tensorflow as tf
print("TensorFlow version:", tf.__version__)2. 检查 GPU 是否可用
TensorFlow 提供了一个函数 tf.config.list_physical_devices,可以用来检查系统中是否有可用的 GPU。
python
# 检查是否有可用的 GPU
gpus = tf.config.list_physical_devices('GPU')
if gpus:
print("GPU is available")
# 打印 GPU 设备信息
for gpu in gpus:
print("Name:", gpu.name, "Type:", gpu.device_type)
else:
print("GPU is NOT available")3. 检查 TensorFlow 是否在 GPU 上运行
即使有可用的 GPU,TensorFlow 也需要正确配置才能使用它。您可以通过运行一个小型的计算任务来验证 TensorFlow 是否在 GPU 上执行。
python
import time
# 创建一个简单的张量
a = tf.constant([1.0, 2.0, 3.0, 4.0], shape=[2, 2], name='a')
b = tf.constant([4.0, 3.0, 2.0, 1.0], shape=[2, 2], name='b')
# 在 GPU 上执行矩阵乘法
start_time = time.time()
c = tf.matmul(a, b)
end_time = time.time()
print("Matrix multiplication result:", c)
print("Time taken:", end_time - start_time, "seconds")4. 检查 TensorFlow 是否使用了 GPU
您可以通过 nvidia-smi 命令来查看 GPU 的使用情况。打开终端并运行以下命令:
bash
nvidia-smi如果有 TensorFlow 进程在 GPU 上运行,您应该能够看到相关的 GPU 使用信息。
5. 检查 TensorFlow 是否正确配置了 CUDA 和 cuDNN
如果您已经安装了 CUDA 和 cuDNN,但仍然无法使用 GPU,可能是由于版本不匹配或路径配置问题。您可以通过以下代码检查 TensorFlow 是否正确配置了 CUDA 和 cuDNN:
python
from tensorflow.python.client import device_lib
# 打印所有设备信息
print(device_lib.list_local_devices())在输出的设备列表中,您应该能够看到 GPU 设备的详细信息,包括设备名称和类型。
6.总结
通过上述步骤,您可以验证 TensorFlow 是否支持 GPU,并且确认 TensorFlow 是否正确配置并使用了 GPU。如果一切正常,您应该能够看到 TensorFlow 在 GPU 上执行计算,并且 nvidia-smi 显示 GPU 的使用情况。