前言
随着自然语言处理(NLP)技术的快速发展,越来越多的企业和个人开发者寻求在本地环境中运行大型语言模型(LLM),以确保数据隐私和提高响应速度。Ollama 作为一个强大的本地运行框架,支持多种先进的 LLM,并提供了易于使用的API接口。本文将详细介绍如何通过 Ollama 构建一个高效、安全的本地AI对话系统,包括Ollama的安装与配置、使用 Go 语言操作大模型以及与 LobeChat 的结合实现可视化管理。
一、Ollama 简介与优势
Ollama 是一款专注于本地部署的大型语言模型框架,旨在为用户提供一种无需依赖云端服务即可享受先进 AI 能力的方式。它具备以下特点:
- 隐私保护:所有处理都在用户的本地设备上完成,确保敏感信息不离开用户环境。
- 多模型支持:支持多个版本的 Llama 以及其他流行的 LLM,如 Phi 4, Gemma 2 等。
- 易用性:提供简单直观的命令行工具和 RESTful API,方便开发者快速上手。
- 性能优化:针对不同硬件配置进行了优化,能够充分利用现有资源提供最佳性能。
- 社区支持:活跃的开源社区提供了丰富的文档和支持,帮助开发者解决问题并分享经验。
二、安装与配置 Ollama
1.环境准备
在开始安装之前,请确认您的开发环境满足以下要求:
- 操作系统兼容性:支持的操作系统包括 Windows、macOS 和 Linux。请根据实际情况选择合适的安装方式。
- 硬件资源要求:根据所选模型大小,建议至少具备 8GB RAM 用于7B模型,16GB RAM用于13B模型,32GB RAM 用于 33B 模型。对于 GPU 加速,推荐使用 NVIDIA CUDA 兼容的显卡。
- 依赖库安装:确保已安装 Docker,以便能够轻松部署 LobeChat 服务。如果需要从源码编译 Ollama,则还需安装 GCC、CMake 等构建工具链。
- 网络连接:初次安装时需保证有稳定的互联网连接,以便下载必要的依赖项和更新。
2.安装步骤
根据不同的操作系统,安装步骤有所不同:
- macOS:
下载 Ollama for macOS 并解压、安装。
- Windows:
下载 Ollama for Windows 并安装。
- Linux:
可以通过官方脚本或手动安装:
curl -fsSL https://ollama.com/install.sh | sh3.配置 Ollama 允许跨域访问
为了让其他服务正确连接到 Ollama,设置几个关键的环境变量:
- macOS:
由于 Ollama 的默认参数配置,启动时设置了仅本地访问,所以跨域访问以及端口监听需要进行额外的环境变量设置 OLLAMA_ORIGINS。使用 launchctl 设置环境变量:
launchctl setenv OLLAMA_ORIGINS "*"完成设置后,需要重启 Ollama 应用程序。
- Windows:
由于 Ollama 的默认参数配置,启动时设置了仅本地访问,所以跨域访问以及端口监听需要进行额外的环境变量设置 OLLAMA_ORIGINS。
在 Windows 上,Ollama 继承了您的用户和系统环境变量。
- 首先通过 Windows 任务栏点击 Ollama 退出程序。
- 从控制面板编辑系统环境变量。
- 为您的用户账户编辑或新建 Ollama 的环境变量 OLLAMA_ORIGINS,值设为 * 。
- 点击OK/应用保存后重启系统。
- 重新运行Ollama。
- Linux:
由于 Ollama 的默认参数配置,启动时设置了仅本地访问,所以跨域访问以及端口监听需要进行额外的环境变量设置 OLLAMA_ORIGINS。如果 Ollama 作为 systemd 服务运行,应该使用systemctl设置环境变量:
-
通过调用sudo systemctl edit ollama.service编辑 systemd 服务。
Gosudo systemctl edit ollama.service -
对于每个环境变量,在 Service 部分下添加 Environment:
[Service] Environment="OLLAMA_HOST=0.0.0.0" Environment="OLLAMA_ORIGINS=*" -
保存并退出。
-
重载 systemd 并重启 Ollama:
sudo systemctl daemon-reload sudo systemctl restart ollama
4. 模型选择与下载
根据具体的业务需求选择合适的预训练模型。Ollama 支持多个版本的 Llama 以及其他流行的 LLM,如下表所示:
| 模型名称 | 参数量 | 大小 (GB) | 下载命令 |
|---|---|---|---|
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Solar | 10.7B | 6.1GB | ollama run solar |
选择好模型后,可以通过下命令下载并加载到本地环境中。请注意,较大的模型可能需要更多的时间和存储空间来完成下载及初始化过程。
5. Ollama 命令使用
提供了丰富的命令行工具,用于管理和操作模型。以下是常用的命令及其功能,以表格形式展示:
|---------------------------------------------------|------------------|
| 命令 | 描述 |
| ollama --help | 查看帮助信息 |
| ollama list | 列出所有可用模型 |
| ollama pull <model> | 下载或更新指定模型 |
| ollama start | 启动Ollama服务 |
| ollama stop | 停止Ollama服务 |
| ollama restart | 重启Ollama服务 |
| ollama status | 检查服务状态 |
| ollama delete <model> | 删除不再使用的模型 |
| ollama generate --model <model> --prompt "提示文本" | 生成文本,基于指定模型和提示文本 |
这些命令可以帮助您更高效地管理Ollama环境,确保模型的正确下载、加载和服务的稳定运行。
我们使用 llama3.2作为后面示例的大模型语言,执行命令:"ollama pull llama3.2",下载该模型语言。

三、使用 Go 语言操作大模型
1. Go 语言客户端示例
下面是一个简单的 Go 语言客户端示例,演示如何与 Ollama REST API 交互,发送文本请求并接收响应。请注意,某些API调用可能需要 API 密钥进行身份验证,具体取决于 Ollama 的服务配置。
Go
package main
import (
"bufio"
"bytes"
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"os"
"strings"
"time"
)
// ChatRequest 是发送到 API 的请求体结构
type ChatRequest struct {
Model string `json:"model"` // 模型的名称或标识符
Messages []ChatMessage `json:"messages"` // 消息内容,包含具体的文本信息
Stream bool `json:"stream"` // 是否以流的方式返回结果
}
// ChatMessage 是请求和响应中消息的结构
type ChatMessage struct {
Role string `json:"role"` // 角色,可以是"user"或"assistant"
Content string `json:"content"` // 消息内容
}
// ChatResponse 是从 API 接收到的响应体结构
type ChatResponse struct {
Model string `json:"model"` // 模型的名称或标识符
CreatedAt time.Time `json:"created_at"` // 响应创建的时间戳
Message ChatMessage `json:"message"` // 生成的消息内容
DoneReason string `json:"done_reason"` // 完成生成的原因
Done bool `json:"done"` // 表示生成是否完成
TotalDuration int64 `json:"total_duration"` // 总生成持续时间(毫秒)
LoadDuration int `json:"load_duration"` // 模型加载持续时间(毫秒)
PromptEvalCount int `json:"prompt_eval_count"` // 提示评估的次数
PromptEvalDuration int `json:"prompt_eval_duration"` // 提示评估的持续时间(毫秒)
EvalCount int `json:"eval_count"` // 评估的总次数
EvalDuration int `json:"eval_duration"` // 评估的总持续时间(毫秒)
}
func main() {
// 读取器用于从标准输入读取用户输入
reader := bufio.NewReader(os.Stdin)
// 打印欢迎信息
fmt.Println("欢迎使用AI!输入 'exit' 退出对话。")
for {
fmt.Print("我: ")
userInput, err := reader.ReadString('\n')
if err != nil {
log.Fatalf("Error reading input: %v", err)
}
userInput = strings.TrimSpace(userInput)
if userInput == "exit" {
fmt.Println("Goodbye!")
break
}
// 创建请求体
requestBody := ChatRequest{
Model: "llama3.2:latest",
Messages: []ChatMessage{
{
Role: "user",
Content: userInput,
},
},
Stream: false, // 根据需要设置为 true 或 false
}
// 将请求体序列化为JSON
jsonData, err := json.Marshal(requestBody)
if err != nil {
log.Fatalf("Error marshaling request body: %v", err)
}
// 创建HTTP请求
apiURL := "http://localhost:11434/api/chat"
req, err := http.NewRequest("POST", apiURL, bytes.NewBuffer(jsonData))
if err != nil {
log.Fatalf("Error creating request: %v", err)
}
// 设置请求头,包括Content-Type和API密钥(如果API需要)
apiKey := "your_api_key_here" // 替换为实际的API密钥
req.Header.Set("Authorization", fmt.Sprintf("Bearer %s", apiKey))
req.Header.Set("Content-Type", "application/json")
// 发送HTTP请求并获取响应
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
log.Fatalf("Error making request: %v", err)
}
defer resp.Body.Close()
// 读取响应体
body, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatalf("Error reading response body: %v", err)
}
// 解析响应体
var response ChatResponse
err = json.Unmarshal(body, &response)
if err != nil {
log.Fatalf("Error unmarshaling response body: %v", err)
}
// 打印生成的文本,添加标记
fmt.Printf("%s\n", response.Message.Content)
}
}这段代码展示了如何通过 HTTP POST 请求调用 Ollama 的服务端点 /api/chat,发送一段文本聊天内容,并接收由选定模型生成的回复。如果 Ollama 服务需要 API 密钥认证,确保在请求头中包含正确的 Authorization 字段。

2.API 密钥认证
在使用 Go 语言或其他编程语言与 Ollama 服务进行交互时,务必确认是否需要 API 密钥进行认证。如果需要,应按照 Ollama 提供的指南设置正确的认证信息,以确保 API 调用的安全性和合法性。对于生产环境,强烈建议使用安全的方式管理和传输 API 密钥,以防止泄露和滥用。
四、配置可视化 LobeChat
1. 安装 LobeChat
使用 Docker 容器化技术可以简化 LobeChat 的部署过程。通过添加环境变量 OLLAMA_PROXY_URL 来指定 Ollama 的服务地址,使得 LobeChat 可以通过这个代理与 Ollama 交互。完整的 Docker 命令如下所示:
Go
docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://host.docker.internal:11434 lobehub/lobe-chat这条命令会在本地机器的 3210 端口启动 LobeChat 服务,并将其与 Ollama 服务相连。
2.配置 LobeChat 模型
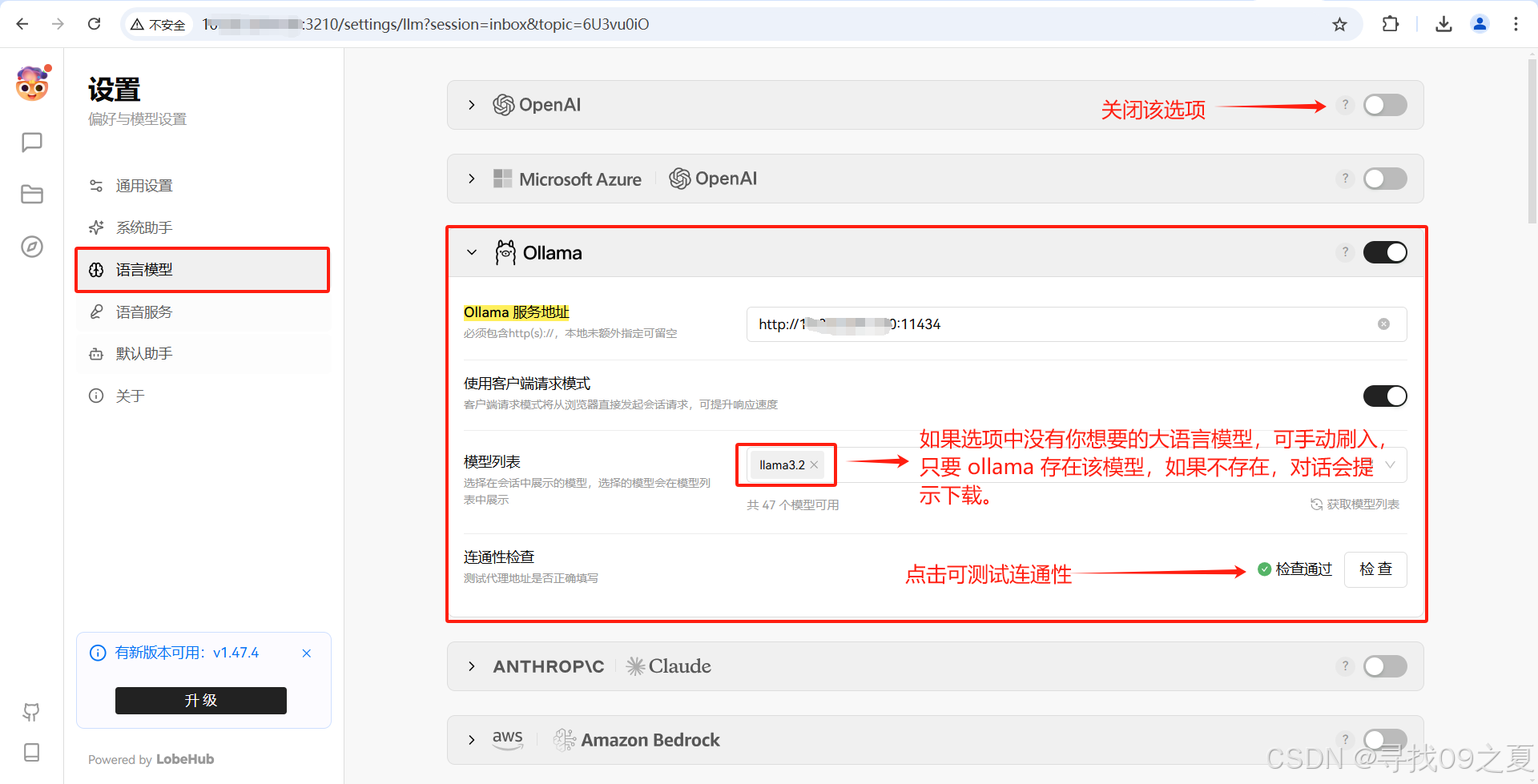
点击"会话设置",选择"语言模型",设置之前自己下载的语言模型;选择"默认助手",模型选择"llama:3.2"。

3.测试与优化
完成上述步骤后,接下来就是对集成后的系统进行全面的功能测试。这包括但不限于单元测试、集成测试以及用户体验测试。根据测试结果进行必要的调整和优化,确保系统的稳定性和性能。特别是要注意以下几点:
- 对话质量:检查对话是否流畅,回复是否准确。
- 响应时间:测量从用户提问到机器人回应的时间间隔。
- 资源使用情况:监控CPU、内存等资源消耗,确保不会因频繁调用导致系统负载过高。
4. 用户界面定制
LobeChat 提供了灵活的前端定制选项,可以根据实际需求修改用户界面的设计和功能。例如,可以添加自定义样式、图标和按钮,增强用户体验;也可以集成第三方插件和服务,扩展平台的功能范围。此外,还可以根据用户反馈不断迭代改进 UI/UX 设计,使产品更加符合目标受众的需求。
五、应用场景与案例研究
企业级客服机器人
借助 LobeChat 与 Ollama 的集成,企业可以构建一个高度智能化且安全可靠的客服平台。所有对话都发生在本地环境中,既保护了客户隐私,又提高了沟通效率。例如,一家银行可以利用这一平台为客户提供全天候的金融服务咨询,确保信息安全的同时提升服务质量。
教育辅助工具
对于在线教育平台而言,这种集成可以帮助创建更加个性化的学习体验。例如,根据学生的答题情况实时提供反馈和建议,促进知识的有效传递。此外,还可以开发针对特定学科的智能辅导系统,帮助学生更好地掌握知识点。
智能家居控制
通过语音助手等形式,用户可以用自然语言指令控制家中的智能设备,享受便捷舒适的家居生活。例如,说出"打开客厅灯",系统就能立即执行相应操作,极大地方便了日常生活。
医疗健康助手
在医疗领域,集成后的系统可以作为医生的助手,帮助分析病历、提供诊断建议或解释复杂的医学术语。它还可以用于患者的日常健康管理,提醒用药时间和预约日期,提高医疗服务的质量和效率。
总结
本文详细介绍了如何通过 Ollama 构建一个高效、安全的本地 AI 对话系统,涵盖了从安装配置到使用 Go 语言操作大模型,再到配置可视化 LobeChat 的全过程。通过这种集成,不仅提升了对话的质量和效率,还为客户提供了前所未有的个性化体验。希望这篇文章能帮助你深入了解Ollama及其应用潜力,如果你有任何问题或想要了解更多相关信息,请随时留言交流!
参考资料