前面的都是使用了mediapipe框架。后面的这两节采用了opencv\dlib的框架。
一 脸部检测
核心:opencv
detectMultiScale函数
detectMultiScale(image, scaleFactor, minNeighbors, flags, minSize, maxSize)image--待检测图片,一般为灰度图像加快检测速度;
scaleFactor参数控制每个图像序列的缩放比例。该参数决定了在每个图像序列中检测窗口的大小。默认值为1.1,表示每次图像被缩小10%。较小的值可以捕捉更多的细节,但也会增加计算量。较大的值可以加快检测速度,但可能会错过一些目标。
minNeighbors参数定义了每个目标至少应该有多少个邻居,才能被认为是一个目标。该参数用于过滤检测到的目标。
flags参数用于定义检测模式。它可以是以下几个值的组合:
- CASCADE_SCALE_IMAGE:使用缩放图像进行检测(默认值)。
- CASCADE_FIND_BIGGEST_OBJECT:只检测最大的目标。
- CASCADE_DO_ROUGH_SEARCH:快速搜索模式。
minSize、maxSize参数用于指定检测目标的最小、最大尺寸。
src/yahboom_esp32_mediapipe/yahboom_esp32_mediapipe/目录下新建05_FaceEyeDetection.py,代码如下:
python
#!/usr/bin/env python2
# encoding: utf-8
#import ros lib
import rclpy
from rclpy.node import Node
from geometry_msgs.msg import Point
import mediapipe as mp
from cv_bridge import CvBridge
from sensor_msgs.msg import CompressedImage,Image
#import define msg
from yahboomcar_msgs.msg import PointArray
#import commom lib
import cv2 as cv
import numpy as np
import time
from cv_bridge import CvBridge
from sensor_msgs.msg import Image, CompressedImage
from rclpy.time import Time
import datetime
print("import done")
class FaceEyeDetection(Node):
def __init__(self,name):
super().__init__(name)
self.bridge = CvBridge()
#加载分类器
self.eyeDetect = cv.CascadeClassifier( "/home/bohu/yahboomcar/yahboomcar_ws/src/yahboom_esp32_mediapipe/resource/haarcascade_eye.xml")
self.faceDetect = cv.CascadeClassifier("/home/bohu/yahboomcar/yahboomcar_ws/src/yahboom_esp32_mediapipe/resource/haarcascade_frontalface_default.xml")
self.pub_rgb = self.create_publisher(Image,"/FaceEyeDetection/image", 500)
def cancel(self):
self.pub_rgb.unregister()
def face(self, frame):
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)#灰度
faces = self.faceDetect.detectMultiScale(gray, 1.3)#检测
for face in faces: frame = self.faceDraw(frame, face)
return frame
def eye(self, frame):
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)#灰度
eyes = self.eyeDetect.detectMultiScale(gray, 1.3)#检测
for eye in eyes:
cv.circle(frame, (int(eye[0] + eye[2] / 2), int(eye[1] + eye[3] / 2)), (int(eye[3] / 2)), (0, 0, 255), 2)
return frame
#画框显示
def faceDraw(self, frame, bbox, l=30, t=10):
x, y, w, h = bbox
x1, y1 = x + w, y + h
cv.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 255), 2)
# Top left x,y
cv.line(frame, (x, y), (x + l, y), (255, 0, 255), t)
cv.line(frame, (x, y), (x, y + l), (255, 0, 255), t)
# Top right x1,y
cv.line(frame, (x1, y), (x1 - l, y), (255, 0, 255), t)
cv.line(frame, (x1, y), (x1, y + l), (255, 0, 255), t)
# Bottom left x1,y1
cv.line(frame, (x, y1), (x + l, y1), (255, 0, 255), t)
cv.line(frame, (x, y1), (x, y1 - l), (255, 0, 255), t)
# Bottom right x1,y1
cv.line(frame, (x1, y1), (x1 - l, y1), (255, 0, 255), t)
cv.line(frame, (x1, y1), (x1, y1 - l), (255, 0, 255), t)
return frame
def pub_img(self, frame):
self.pub_rgb.publish(self.bridge.cv2_to_imgmsg(frame, "bgr8"))
class MY_Picture(Node):
def __init__(self, name):
super().__init__(name)
self.bridge = CvBridge()
self.sub_img = self.create_subscription(
CompressedImage, '/espRos/esp32camera', self.handleTopic, 1) #获取esp32传来的图像
self.last_stamp = None
self.new_seconds = 0
self.fps_seconds = 1
self.face_eye_detection = FaceEyeDetection('face_eye_detection')
self.content = ["face", "eye", "face_eye"]
self.content_index = 0
#回调函数
def handleTopic(self, msg):
self.last_stamp = msg.header.stamp
if self.last_stamp:
total_secs = Time(nanoseconds=self.last_stamp.nanosec, seconds=self.last_stamp.sec).nanoseconds
delta = datetime.timedelta(seconds=total_secs * 1e-9)
seconds = delta.total_seconds()*100
if self.new_seconds != 0:
self.fps_seconds = seconds - self.new_seconds
self.new_seconds = seconds#保留这次的值
start = time.time()
frame = self.bridge.compressed_imgmsg_to_cv2(msg)
frame = cv.resize(frame, (640, 480))
cv.waitKey(10)
action = cv.waitKey(1) & 0xFF
if action == ord("f") or action == ord("F"):
self.content_index += 1
if self.content_index >= len(self.content): self.content_index = 0
if self.content[self.content_index] == "face": frame = self.face_eye_detection.face(frame)
elif self.content[self.content_index] == "eye": frame = self.face_eye_detection.eye(frame)
else: frame = self.face_eye_detection.eye(self.face_eye_detection.face(frame))
end = time.time()
fps = 1 / ((end - start)+self.fps_seconds)
text = "FPS : " + str(int(fps))
cv.putText(frame, text, (20, 30), cv.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 1)
cv.imshow('frame', frame)
self.face_eye_detection.pub_img(frame)
# print(frame)
cv.waitKey(10)
def main():
print("start it")
rclpy.init()
esp_img = MY_Picture("My_Picture")
try:
rclpy.spin(esp_img)
except KeyboardInterrupt:
pass
finally:
esp_img.destroy_node()
rclpy.shutdown()主要流程跟之前类似,这个不如mediapipe框架好,尤其是画框比较麻烦。
这个识别效果对比之前的face_recognition,我觉得不如那个好,参见:
ros2-4.2 用python实现人脸识别_ros2使用人脸检测-CSDN博客
构建后运行:
ros2 run yahboom_esp32_mediapipe FaceEyeDetection
效果如下

二 人脸特效
人脸检测
使用了dlib库
.get_frontal_face_detector()
功能:人脸检测画框
参数:无
返回值:默认的人脸检测器
shape_predictor()
功能:标记人脸关键点
参数:shape_predictor_68_face_landmarks.dat:68个关键点模型地址
返回值:人脸关键点预测器
python
import cv2
import mediapipe as mp
import dlib
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("/home/bohu/yahboomcar/yahboomcar_ws/src/yahboom_esp32_mediapipe/resource/shape_predictor_68_face_landmarks.dat")
cap = cv2.VideoCapture(0)#打开默认摄像头
while True:
ret,frame = cap.read()#读取一帧图像
#图像格式转换
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 因为摄像头是镜像的,所以将摄像头水平翻转
# 不是镜像的可以不翻转
frame= cv2.flip(frame,1)
#输出结果
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = detector(gray)
print(f'faces:{len(faces)}')
for face in faces:
# 利用预测器预测
shape = predictor(gray, face)
# print(shape)
# 标出68个点的位置
for i in range(68):
cv2.circle(frame, (shape.part(i).x, shape.part(i).y), 2, (0, 255, 0), -1, 1)
cv2.putText(frame, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
cv2.imshow('opencv detectMultiScale', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()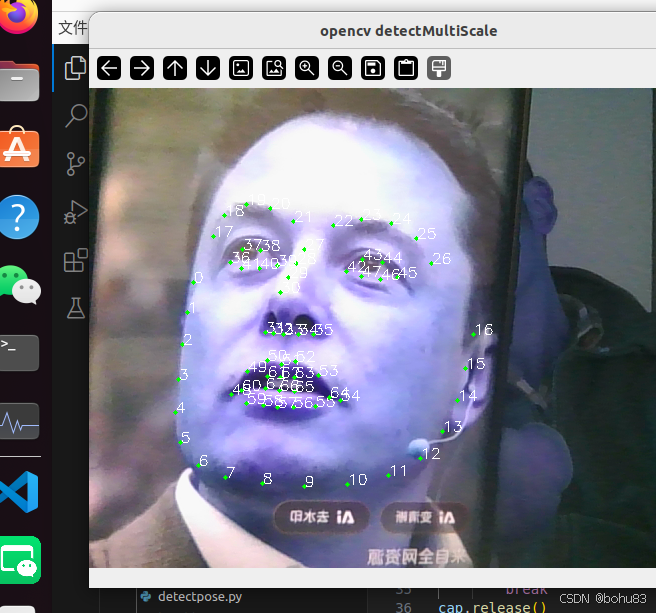
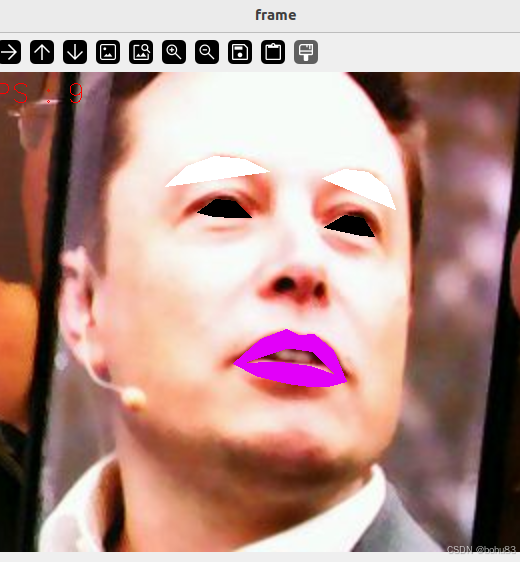
人脸特效
基本思路就是在dlib人脸检测点上,在额外使用opencv画线\和fillConvexPoly填充多边形函数。
这种就是比较麻烦,没有官方的函数之间调用好。
src/yahboom_esp32_mediapipe/yahboom_esp32_mediapipe/目录下新建文件06_FaceLandmarks.py,代码如下:
python
#!/usr/bin/env python3
# encoding: utf-8
import rclpy
from rclpy.node import Node
import time
import dlib
import cv2 as cv
import numpy as np
from cv_bridge import CvBridge
from sensor_msgs.msg import Image, CompressedImage
from rclpy.time import Time
import datetime
class FaceLandmarks:
def __init__(self, dat_file):
self.hog_face_detector = dlib.get_frontal_face_detector()
self.dlib_facelandmark = dlib.shape_predictor(dat_file)
def get_face(self, frame, draw=True):
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
self.faces = self.hog_face_detector(gray)
for face in self.faces:
self.face_landmarks = self.dlib_facelandmark(gray, face)
if draw:
for n in range(68):
x = self.face_landmarks.part(n).x
y = self.face_landmarks.part(n).y
cv.circle(frame, (x, y), 2, (0, 255, 255), 2)
cv.putText(frame, str(n), (x, y), cv.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 255), 2)
return frame
def get_lmList(self, frame, p1, p2, draw=True):
lmList = []
if len(self.faces) != 0:
for n in range(p1, p2):
x = self.face_landmarks.part(n).x
y = self.face_landmarks.part(n).y
lmList.append([x, y])
if draw:
next_point = n + 1
if n == p2 - 1: next_point = p1
x2 = self.face_landmarks.part(next_point).x
y2 = self.face_landmarks.part(next_point).y
cv.line(frame, (x, y), (x2, y2), (0, 255, 0), 1)
return lmList
def get_lipList(self, frame, lipIndexlist, draw=True):
lmList = []
if len(self.faces) != 0:
for n in range(len(lipIndexlist)):
x = self.face_landmarks.part(lipIndexlist[n]).x
y = self.face_landmarks.part(lipIndexlist[n]).y
lmList.append([x, y])
if draw:
next_point = n + 1
if n == len(lipIndexlist) - 1: next_point = 0
x2 = self.face_landmarks.part(lipIndexlist[next_point]).x
y2 = self.face_landmarks.part(lipIndexlist[next_point]).y
cv.line(frame, (x, y), (x2, y2), (0, 255, 0), 1)
return lmList
def prettify_face(self, frame, eye=True, lips=True, eyebrow=True, draw=True):
if eye:
leftEye = landmarks.get_lmList(frame, 36, 42)
rightEye = landmarks.get_lmList(frame, 42, 48)
if draw:
if len(leftEye) != 0: frame = cv.fillConvexPoly(frame, np.mat(leftEye), (0, 0, 0))
if len(rightEye) != 0: frame = cv.fillConvexPoly(frame, np.mat(rightEye), (0, 0, 0))
if lips:
lipIndexlistA = [51, 52, 53, 54, 64, 63, 62]
lipIndexlistB = [48, 49, 50, 51, 62, 61, 60]
lipsUpA = landmarks.get_lipList(frame, lipIndexlistA, draw=True)
lipsUpB = landmarks.get_lipList(frame, lipIndexlistB, draw=True)
lipIndexlistA = [57, 58, 59, 48, 67, 66]
lipIndexlistB = [54, 55, 56, 57, 66, 65, 64]
lipsDownA = landmarks.get_lipList(frame, lipIndexlistA, draw=True)
lipsDownB = landmarks.get_lipList(frame, lipIndexlistB, draw=True)
if draw:
if len(lipsUpA) != 0: frame = cv.fillConvexPoly(frame, np.mat(lipsUpA), (249, 0, 226))
if len(lipsUpB) != 0: frame = cv.fillConvexPoly(frame, np.mat(lipsUpB), (249, 0, 226))
if len(lipsDownA) != 0: frame = cv.fillConvexPoly(frame, np.mat(lipsDownA), (249, 0, 226))
if len(lipsDownB) != 0: frame = cv.fillConvexPoly(frame, np.mat(lipsDownB), (249, 0, 226))
if eyebrow:
lefteyebrow = landmarks.get_lmList(frame, 17, 22)
righteyebrow = landmarks.get_lmList(frame, 22, 27)
if draw:
if len(lefteyebrow) != 0: frame = cv.fillConvexPoly(frame, np.mat(lefteyebrow), (255, 255, 255))
if len(righteyebrow) != 0: frame = cv.fillConvexPoly(frame, np.mat(righteyebrow), (255, 255, 255))
return frame
class MY_Picture(Node):
def __init__(self, name,landmarkss):
super().__init__(name)
self.bridge = CvBridge()
self.sub_img = self.create_subscription(
CompressedImage, '/espRos/esp32camera', self.handleTopic, 1) #获取esp32传来的图像
self.landmarksros = landmarkss
self.last_stamp = None
self.new_seconds = 0
self.fps_seconds = 1
def handleTopic(self, msg):
self.last_stamp = msg.header.stamp
if self.last_stamp:
total_secs = Time(nanoseconds=self.last_stamp.nanosec, seconds=self.last_stamp.sec).nanoseconds
delta = datetime.timedelta(seconds=total_secs * 1e-9)
seconds = delta.total_seconds()*100
if self.new_seconds != 0:
self.fps_seconds = seconds - self.new_seconds
self.new_seconds = seconds#保留这次的值
start = time.time()
frame = self.bridge.compressed_imgmsg_to_cv2(msg)
frame = cv.resize(frame, (640, 480))
cv.waitKey(10)
frame = self.landmarksros.get_face(frame, draw=False)
frame = self.landmarksros.prettify_face(frame, eye=True, lips=True, eyebrow=True, draw=True)
end = time.time()
fps = 1 / ((end - start)+self.fps_seconds)
text = "FPS : " + str(int(fps))
cv.putText(frame, text, (20, 30), cv.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 1)
cv.imshow('frame', frame)
landmarks = None
def main():
global landmarks
print("start it")
#使用官方训练好的dlib 68点模型
dat_file = "/home/bohu/yahboomcar/yahboomcar_ws/src/yahboom_esp32_mediapipe/resource/shape_predictor_68_face_landmarks.dat"
landmarks = FaceLandmarks(dat_file)
rclpy.init()
esp_img = MY_Picture("My_Picture",landmarks)
try:
rclpy.spin(esp_img)
except KeyboardInterrupt:
pass
finally:
esp_img.destroy_node()
rclpy.shutdown()构建后运行:
ros2 run yahboom_esp32_mediapipe FaceLandmarks
效果如下: