基于机器学习鉴别中药材的方法
摘要
由于不同红外光照射药材时会呈现不同的光谱特征,所以本文基于中药材的这一特点来判断其产地和种类。
针对问题一:要对附件一中所给数据对所给中药材进行分类,并就其特征和差异性进行研究。首先,我们读取原始数据,利用python绘图后发现,出现三个异常值,利用3sigma原则清洗数据后,再利用k-means迭代求解的聚类分析算法计算出k值为3最合适,则应将这些中药材分为三类;在此基础之上,我们将之前清洗的3个异常数据归为一类,最终将中药材分为四类。
针对问题二:主要分析同一种药材在不同产地的特征以及差异性,并对药材的种类进行鉴别。首先,我们对附件二中的数据进行读取,利用python绘制光谱图并对数据进行预处理。由于数据量过大,药材产地鉴别困难,我们通过一阶差分、二阶差分以及多元散射校正(MSC)进行数据预处理,对预测准确值进行评估后,发现二阶差分效果最好。其次,使用sklearn、gbm、RF、SVM监督学习算法再次对模型进行评价,结果表明:RF的准确率最高,达到了0.98,表示该模型具有准确性和实用性。我们利用该模型对表中给出编号药材的产地进行鉴别,得出最终结果:
|----|---|----|----|----|----|----|----|----|----|-----|-----|-----|-----|-----|-----|
| No | 3 | 14 | 38 | 48 | 58 | 71 | 79 | 86 | 89 | 110 | 134 | 152 | 227 | 331 | 618 |
| OP | 6 | 1 | 4 | 7 | 10 | 6 | 9 | 11 | 3 | 4 | 9 | 2 | 5 | 8 | 3 |
针对问题三:需要根据该种药材的近红外光谱数据、中红外光谱数据,鉴别该药材的产地,并完成表格。我们分别对该药材近、中红外数据进行读取并绘图,确定近红外区和中红外区各个产地药材的数量。接着分别利用一阶差分和二阶差分对数据进行预处理,划分训练集数据,使用训练集数据进行训练,利用机器学习中的RF、SVM、lgb建立模型。由于近红外区准确率较低,近红外加中红外的数据量过大,所以我们最终选择基于中红外数据,利用准确率最高的RF建立模型,最终得到表格结果:
|----|----|----|----|----|----|----|----|-----|-----|-----|
| No | 4 | 15 | 22 | 30 | 34 | 45 | 74 | 114 | 170 | 209 |
| OP | 17 | 11 | 1 | 2 | 16 | 3 | 4 | 10 | 9 | 14 |
针对问题四:要求对所给药材的类别和产地进行鉴别,并完成表格。首先,读取附件四中的数据.使用Python绘制光谱图.并对附件四进行数据预处理,对于问题四数据使用一阶差分、二阶差分、随机森林(RF)和向量机模型算法(SVM)。对于处理后的数据进行模型训练,通过对比得到在模型中使用二阶差分效果最好。最终得到结果:
|-------|----|-----|-----|-----|-----|-----|-----|
| No | 94 | 109 | 140 | 278 | 308 | 330 | 347 |
| Class | 1 | 1 | 1 | 3 | 3 | 3 | 3 |
| OP | 5 | 3 | 1 | 1 | 3 | 4 | 11 |
关键字:中药材鉴别 红外光谱 一阶差分 二阶差分 机器学习
一、问题重述
1.1 问题背景
不同种类的中药材在同一波段内的光谱特征差异明显,成为判断药材种类的重要依据。即便对于同一类型的中药材,不同产地的药材在同一波段下的光谱特征也会有所差异,这些差异源于药材中的无机元素和有机物质的不同含量。产地是中药材道地性的重要指标,但对于药材品质的鉴别,相较于种类而言,产地对光谱特征的影响较小。有些药材在近红外区的光谱区别更为明显,而有些药材则在中红外区有更明显的区别。因此,在实际应用中,我们常常需要综合利用近红外和中红外的光谱数据来进行综合鉴别,以提高对中药材产地鉴别的准确性。
1.2 问题提出
附件1至附件4是一些中药材的近红外或中红外光谱数据,其中No列为药材的编号,Class列为中药材的类别,OP列为该种药材的产地,其余各列第一行的数据为光谱的波数,第二行以后的数据表示该行编号的药材在对应波段光谱照射下的吸光度。
- 分析处理附件一中的中红外光谱数据,研究其中不同种类药材的特征和差异性,并且对药材的种类进行鉴别。
- 对附件二中给出的中红外光谱数据进行分析,分析不同产地药材的特征和差异性,并鉴别药材产地,给出表格中各编号药材的产地。
- 分析附件三中的近红外和中红外数据,鉴别药材的产地,并通过计算得出表格中不同种类药材的产地。
- 附件四给出了几种药材的近红外光谱数据,对其产地和种类进行鉴别,并完成相关表格。
二、问题分析
本文主要通过对不同中药材在近红外中红外光照下的不同光谱特征,对不同种类中药材的特征和差异性进行分析,并对中药材的产地和种类作出鉴别。
2.1 问题一的分析
问题一要求我们根据附件1中的几种药材的中红外和近红外光谱数据,分析不同种类的药材的特征和差异,并对药材的种类进行分析。首先读取数据,利用Python绘图,对附件1进行数据预处理,判断有无异常数据,由若有异常数据,则需进行数据清洗。其次,根据所给数据建立聚类模型,对中红外光谱数据进行筛选和分类,确定药材种类。最后,对不同种类的中药材数据进行特征提取和差异性分析。
2.2 问题二的分析
问题二中给出了某一种药材的红外光谱数据,我们首先读取这些数据,利用Python画图,对数据进行预处理,为了减小数据量,我们利用一阶差分、二阶差分等方法对数据进行处理,并对模型准确度进行评估,选择准确率最高的模型。在前一个模型建立的基础之上,二次建立模型,对模型准确率进行评估,选择最合适的模型,利用该模型对题中药材的产地进行鉴别,从而分析其特征和差异性。
2.3 问题三的分析
问题三同时给出了某种药材的近红外和中红外光谱数据,首先,我们分别读取该种药材近红外和中红外的数据,分别绘制其近红外光谱图和中红外光谱图。可利用一阶差分和二阶差分建立模型,而后对模型准确性进行评估。同时,考虑到有些药材在近红外区的区别比较明显,有些药材在中红外区的区别比较明显,我们将中红外区和近红外区的数据放在一起,扩充样本数量,此做法一般可以提高模型的准确度。其次,将分别读取数据和综合读取数据的两种模型的准确度进行对比,我们可以确定合适的数据选取方式。最后,利用相关数据和模型对表中药材产地进行鉴别。
2.4 问题四的分析
问题四给出了几种药材的近红外光谱数据.据题目要求,需鉴别药材的不同类别和产地,并以此分类并给绘图。读取数据并将其绘图,对于数据进行预处理。分别用一阶差分,二阶差为,随机森林(RF)、向量机(SVM),并且将多种模型的结果比较,从而选择预测率最高的模型,并将不同近红外光谱数据分组比较。
三、模型假设
- 假设题中所给数据准确无误,能够真实反映不同产地、不同种类中药材的光谱特征。
- 假设中药材的产地和种类不受其它外界因素的影响。
四、符号说明及名词定义
|-----------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 符号 | 说明 |
| Sl  | 第l
| 第l  个类簇的中心 |
个类簇的中心 |
| xi  | 第i
| 第i 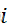 个类簇中第l
个类簇中第l  个对象 |
个对象 |
| Dat ai  | 理想光谱样本数据值 |
| 理想光谱样本数据值 |
| ( x i , y i)  | 训练数据 |
| 训练数据 |
五、模型建立、求解与分析
5.1 问题一的模型建立与分析
5.1.1数据清洗预处理
数据清洗是指重新检查和验证数据的过程,旨在删除重复信息,纠正现有错误并提供数据一致性。通过数据清洗能够提高数据的可用性以及分析结果的准确性。
在读取附件一的数据后,我们利用Python绘制所给药材的光谱图,会发现有三种药材的光谱曲线与其它药材之间有明显区别,我们判定其为异常样本,利用3sigma原则对数据进行清洗,以提高其准确性。


(a)原始光谱图 (b)数据清洗后光谱图
图1 光谱对比
5.1.2肘方法确定K-means聚类中簇的最佳数量
根据肘部方法的基本原理,由图 我们可以得出,在k=3时,畸变程度得到很大改善,此时误差平方和最小,所以选取k=3为最优k值,进行聚类分析。

图2 聚类中簇数量
5.1.3 k-means聚类分析
K-均值(k-means)聚类分析法原理:K-均值算法是一种迭代型聚类算法,在给定k  值和k
值和k 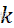 个初始类簇中心点的情况下,把每个点(即数据记录)分到离其最近的类簇中心点所代表的类簇中,所有点分配完毕之后,根据一个类簇内的所有点重新计算该类簇的中心点(取平均值),然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数。
个初始类簇中心点的情况下,把每个点(即数据记录)分到离其最近的类簇中心点所代表的类簇中,所有点分配完毕之后,根据一个类簇内的所有点重新计算该类簇的中心点(取平均值),然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数。
其基本原理是:假定给定数据样本x  ,包含了n个对象
,包含了n个对象
X={ X 1 , X 2 ,⋯, X n} 
其中每个对象都具有个维度的属性。K-means算法的目标是将m  个对象依据对象间的相似性聚集到指定的k
个对象依据对象间的相似性聚集到指定的k  个类簇中,每个对象属于且仅属于一个其到类簇中心距离最小的类簇中。算法步骤如下:
个类簇中,每个对象属于且仅属于一个其到类簇中心距离最小的类簇中。算法步骤如下:
(1)初始化k  个聚类中心:C 1 , C 2 ,⋯, C k },1<k≤ n0
个聚类中心:C 1 , C 2 ,⋯, C k },1<k≤ n0 
(2)计算每一个对象到每一个聚类中心的欧式距离d i s ( X i , C j)  ,即
,即
d isX i ,C = t=1 m ( X it - C ji )2 
式中:xi  为第i
为第i  个对象,1<i≤n; Cj
个对象,1<i≤n; Cj  为第n个聚类中心,1<j≤k; Xii
为第n个聚类中心,1<j≤k; Xii  为第i
为第i  个对象的第t
个对象的第t  个属性,1≤t≤m; Cjt
个属性,1≤t≤m; Cjt  为第j
为第j  个聚类中心的第t
个聚类中心的第t  个属性。
个属性。
(3)依次比较每一个对象到每一个聚类中心的距离,将对象分配到距离最近的聚类中心的 类簇中,得到k  个类簇*{* S 1 , S 2 ,⋯, S k}
个类簇*{* S 1 , S 2 ,⋯, S k} 
4)K-均值算法用中心定义了类簇的原型,类簇中心就是类簇内所有对象在各个维度的均值,其计算公式为
C t = l=1 k x i ∈ s l x i sl 
式中:Sl  为第l
为第l  个类簇的中心,1≤l≤k;| S l|
个类簇的中心,1≤l≤k;| S l|  为第l
为第l  个类簇中对象的个数;xi
个类簇中对象的个数;xi  为第i
为第i  个类簇中第l
个类簇中第l  个对象,1≤i≤| S l|
个对象,1≤i≤| S l| 
在我们确定k值为3后,就可利用k-means方法,对数据进行聚类,结果如下图所示,数据归为3类,原始数据中的三个异常数据比较接近,我们将其单独划分为一类,最终我们将药材分为四类。

图3 k-means分类1

图4 k-means分类2
5.2 问题二的模型建立与分析
5.2.1数据预处理
我们在读取附件2中该药材的中共外光谱数据后,利用python绘制光谱图,为了使得数据格式标准化,提高数据挖掘模式的质量,则需要对这些数据进行预处理,以下是处理方法。
- 一阶拆分
一阶差分,即离散函数中连续相邻两项之差。当自变量从x变到x+1时,函数y=y(x)的改变量称为函数 y(x)在点x的一阶差分,记为:
∆yx=yx+1-yx,(x=0,1,2,......)。
设函数y=f(x),式中y只对x在非负整数值上有定义,在自变量x依次取遍非负整数,即x=0,1,2...... 时,相应的函数值为f 0 ,f 1 ,f 2 ,f 3....  ,简记为:y 0 , y 1, y 2 , y3
,简记为:y 0 , y 1, y 2 , y3 
一阶差分的结果如图5;
- 二阶拆分
当自变量从x变到x+1时,函数y=y(x)一阶差分的差分Δ(Δy(x))=Δ(y(x+1) - y(x))=Δy(x+1) - Δy(x)=(y(x+2) - y(x+1)) - (y(x+1) - y(x))=y(x+2) - 2y(x+1) + y(x)称为二阶差分。
二阶拆分的结果如图6;
- 多元散射矫正(MSC)
多元散射校正(MSC),高光谱数据预处理常用的算法之一,它可以有效的消除由于散射水平不同带来的光谱差异,从而增强光谱与数据之间的相关性。该方法通过理想光谱修正光谱数据的基线平移和偏移现象,而实际中,我们无法获取真正的理想光谱数据,因此我们常常假设所有光谱数据的平均值作为"理想光谱"。实现多元散射矫正的具体实现方法如下:
①求得所有光谱数据的平均值作为"理想光谱":
Data = i=1 n D ataij n
②将每个样本的光谱与平均光谱进行一元线性回归,求解最小二乘问题得到每个样本的基线平移量和偏移量:
Dat a i = k i t a i = k i + b i
③对每个样本的光谱进行校正:减去求得的基线平移量后除以偏移量,得到校正后的光谱:
Dat a i (MSC)= (Dat a i - b i ) k i
我们分别使用一阶拆分、二阶拆分、多元散射矫正对原始数据进行预处理,可得到以下图像,对预测准确值进行评估,相比之后我们发现二阶差分的效果最好。接下来我们对训练数据集进行划分,分成训练集和验证集,进行相应操作。
5.2.2机器学习
- Sklearn
Sklearn,即scikit-learn,是一个开源的基于python语言的机器学习工具包。它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
Sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
- gbm(决策树)
GBM全称gradient boosting machine,一般叫做梯度提升树算法,是一类很常用的集成学习算法,其计算步骤如下:
1.输入训练数据*(* x i , y i ) 
2.构建提升树模型f M (x)
3.初始化f 0 (x)= a r g m i n i=1 N L( y i θ)
Form=1toM
- 对于第m个基学习器,首先计算梯度
g m ( x i )=* *∂L(* *y* *i* *,f(* *x* *i* *))* *∂f(* *x* *i* *)* * f(x)= f m - 1(x)
- 根据梯度学习第m个学习器
θ m ' = a r g m b,β N * *-* *g* *m* *(* *x* *i* *)* *-* *β* *m* *θ(* *x* *i* *)* * 2
- 通过line search求取最佳步长
β m = a r g m β N β L\|* *y* *i* *,* *f* *m* *-* *1* *(* *x* *i* *)+* *β* *m* *θ* *m* *(* *x* *i* *)
- 令 f m = β m θ m ' 更新,模型
f( x i )= f m - 1 + f m
- RF(随机森林算法)
随机森林算法,即通过对数据集的采样生成多个不同的数据集,并在每一个数据集上训练出一颗分类树,最终结合每一颗分类树的预测结果作为随机森林的预测结果。顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。随机森林的构造过程如下:
-
假如有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
-
当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
-
决策树形成过程中每个节点都要按照步骤2来分裂,一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
-
按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
-
SVM
SVM全称Support Vector Machine,即支持向量机,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。SVM要解决的问题可以用一个经典的二分类问题加以描述。
一个最优化问题通常有两个最基本的因素:1)目标函数,也就是你希望什么东西的什么指标达到最好;2)优化对象,你期望通过改变哪些因素来使你的目标函数达到最优。在线性SVM算法中,目标函数显然就是那个"分类间隔",而优化对象则是决策面。所以要对SVM问题进行数学建模,首先要对上述两个对象("分类间隔"和"决策面")进行数学描述。
通过LGB、RF、SVM对模型进行训练和评估,我们可以分别得出三种算法的平均分类准确率,如下表所示,其中,利用随机森林算法的平均分类准确率最高。此时,我们可对问题2中的产地预测进行回答,表格结果如下:
表1
|---------|-------|-----------|-------|
| | LGB | RF | SVM |
| 平均分类准确率 | 98.9% | 98.9% | 94.9% |
表2
|----|---|----|----|----|----|----|----|----|----|-----|-----|-----|-----|-----|-----|
| No | 3 | 14 | 38 | 48 | 58 | 71 | 79 | 86 | 89 | 110 | 134 | 152 | 227 | 331 | 618 |
| OP | 6 | 1 | 4 | 7 | 10 | 6 | 9 | 11 | 3 | 4 | 9 | 2 | 5 | 8 | 3 |
5.3 问题三的模型建立与分析
5.3.1数据预处理
问题三模型的建立与问题二类似,首先从附件3分别读取该药材的近红外和中红外的原始数据,绘制图像。
其次,我们可以得到该种药材的产地及其对应的药材数量,如下表:
表3 药材近红外产地与数量对照表
|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|
| OP | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| No | 14 | 14 | 14 | 14 | 15 | 15 | 15 | 15 | 14 | 14 | 14 | 15 | 15 | 14 | 15 | 14 | 14 |
表4 药材中红外产地与数量对照表
|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|
| OP | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| No | 14 | 14 | 14 | 14 | 15 | 15 | 15 | 15 | 14 | 14 | 14 | 15 | 15 | 15 | 14 | 14 | 14 |
由于问题二中采用多元散射校正的效果不会,接下来我们采用一阶差分和二阶差分别对近红外和中红外的光谱数据进行预处理,利用python绘图,结果如下图:
据图可知,二阶差分的效果优于一阶差分,所以我们采用二阶差分进行预处理。
5.3.2机器学习
对训练数据集进行划分,分成训练集和验证集,分别利用LightGBM(LGB)、随机森林算法(RF)、向量机模型算法(SVM)对近红外、中红外以及近中红外的数据的进行处理,得到的准确率结果如下表所示:
表5 近中红外不同机器学习算法的平均分类准确率
|-----|-------|-----------|-------|
| | LGB | RF | SVM |
| 近红外 | 0.810 | 0.838 | 0.459 |
| 中红外 | 0.919 | 0.973 | 0.541 |
近红外数据与中红外数据综合后,数据量过大,难以进行处理,直接对近红外、中红外不同模型的平均分类准确率进行对比,由结果可知,中红外随机森林算法(RF)的准确率最高。此时,我们可对问题3中药材的产地进行预测,得到下表:
表6 药材产地鉴别结果
|----|----|----|----|----|----|----|----|-----|-----|-----|
| No | 4 | 15 | 22 | 30 | 34 | 45 | 74 | 114 | 170 | 209 |
| OP | 17 | 11 | 1 | 2 | 16 | 3 | 4 | 10 | 9 | 14 |
5.4 问题四的模型建立与分析
5.4.1数据预处理
首先,读取附件4中药材的近红外光谱的原始数据,利用python画出下图:
Data = i=1 n D ataij n
②将每个样本的光谱与平均光谱进行一元线性回归,求解最小二乘问题得到每个样本的基线平移量和偏移量:
Dat a i = k i t a i = k i + b i
③对每个样本的光谱进行校正:减去求得的基线平移量后除以偏移量,得到校正后的光谱:
Dat a i (MSC)= (Dat a i - b i ) k i
我们分别使用一阶拆分、二阶拆分、多元散射矫正对原始数据进行预处理,可得到以下图像,对预测准确值进行评估,相比之后我们发现二阶差分的效果最好。接下来我们对训练数据集进行划分,分成训练集和验证集,进行相应操作。
5.2.2机器学习
- Sklearn
Sklearn,即scikit-learn,是一个开源的基于python语言的机器学习工具包。它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
Sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
- gbm(决策树)
GBM全称gradient boosting machine,一般叫做梯度提升树算法,是一类很常用的集成学习算法,其计算步骤如下:
1.输入训练数据*(* x i , y i )
2.构建提升树模型f M (x)
3.初始化f 0 (x)= a r g m i n i=1 N L( y i θ)
Form=1toM
- 对于第m个基学习器,首先计算梯度
g m ( x i )=* *∂L(* *y* *i* *,f(* *x* *i* *))* *∂f(* *x* *i* *)* * f(x)= f m - 1(x)
- 根据梯度学习第m个学习器
θ m ' = a r g m b,β N * *-* *g* *m* *(* *x* *i* *)* *-* *β* *m* *θ(* *x* *i* *)* * 2
- 通过line search求取最佳步长
β m = a r g m β N β L\|* *y* *i* *,* *f* *m* *-* *1* *(* *x* *i* *)+* *β* *m* *θ* *m* *(* *x* *i* *)
- 令 f m = β m θ m *'*更新,模型
f( x i )= f m - 1 + f m
- RF(随机森林算法)
随机森林算法,即通过对数据集的采样生成多个不同的数据集,并在每一个数据集上训练出一颗分类树,最终结合每一颗分类树的预测结果作为随机森林的预测结果。顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。随机森林的构造过程如下:
-
假如有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
-
当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
-
决策树形成过程中每个节点都要按照步骤2来分裂,一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
-
按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
-
SVM
SVM全称Support Vector Machine,即支持向量机,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。SVM要解决的问题可以用一个经典的二分类问题加以描述。
一个最优化问题通常有两个最基本的因素:1)目标函数,也就是你希望什么东西的什么指标达到最好;2)优化对象,你期望通过改变哪些因素来使你的目标函数达到最优。在线性SVM算法中,目标函数显然就是那个"分类间隔",而优化对象则是决策面。所以要对SVM问题进行数学建模,首先要对上述两个对象("分类间隔"和"决策面")进行数学描述。
通过LGB、RF、SVM对模型进行训练和评估,我们可以分别得出三种算法的平均分类准确率,如下表所示,其中,利用随机森林算法的平均分类准确率最高。此时,我们可对问题2中的产地预测进行回答,表格结果如下:
表1
|---------|-------|-----------|-------|
| | LGB | RF | SVM |
| 平均分类准确率 | 98.9% | 98.9% | 94.9% |
表2
|----|---|----|----|----|----|----|----|----|----|-----|-----|-----|-----|-----|-----|
| No | 3 | 14 | 38 | 48 | 58 | 71 | 79 | 86 | 89 | 110 | 134 | 152 | 227 | 331 | 618 |
| OP | 6 | 1 | 4 | 7 | 10 | 6 | 9 | 11 | 3 | 4 | 9 | 2 | 5 | 8 | 3 |
5.3 问题三的模型建立与分析
5.3.1数据预处理
问题三模型的建立与问题二类似,首先从附件3分别读取该药材的近红外和中红外的原始数据,绘制图像。
其次,我们可以得到该种药材的产地及其对应的药材数量,如下表:
表3 药材近红外产地与数量对照表
|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|
| OP | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| No | 14 | 14 | 14 | 14 | 15 | 15 | 15 | 15 | 14 | 14 | 14 | 15 | 15 | 14 | 15 | 14 | 14 |
表4 药材中红外产地与数量对照表
|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|----|
| OP | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| No | 14 | 14 | 14 | 14 | 15 | 15 | 15 | 15 | 14 | 14 | 14 | 15 | 15 | 15 | 14 | 14 | 14 |
由于问题二中采用多元散射校正的效果不会,接下来我们采用一阶差分和二阶差分别对近红外和中红外的光谱数据进行预处理,利用python绘图,结果如下图:
Data = i=1 n D ataijn