utils.py:
python
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
def rag_tool(api_key,memory,uploaded_file,question):
# 将文件内容写入到本地,才能有文件路径(用户上传的文件直接储存在内存里,无路径)
file_content = uploaded_file.read() #返回文件的二进制数据
temp_file_path = "temp.pdf"
with open(temp_file_path,"wb") as fwb: #以二进制写入方式打开文件,并创建文件对象(与文件进行交互的接口)
fwb.write(file_content) #写入上面读取到的文件内容
# 加载
loader = PyPDFLoader(temp_file_path)
docs = loader.load()
# 分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=50,
separators=["\n\n","\n","。","!","?",",","","、"," ",""]
)
texts = text_splitter.split_documents(docs)
# 嵌入模型
embeddings_model = OpenAIEmbeddings(api_key=api_key,
base_url="https://api.gptsapi.net/v1")
# 嵌入并储存
db = FAISS.from_documents(texts,embeddings_model)
# 检索
retriever = db.as_retriever()
# 模型
model = ChatOpenAI(model="gpt-3.5-turbo",
api_key=api_key,
base_url="https://api.gptsapi.net/v1")
# 记忆
# 创建带记忆的检索增强对话链(有了检索器、模型、记忆)
chain = ConversationalRetrievalChain.from_llm(
llm = model,
retriever = retriever,
memory = memory,
return_source_documents=True
)
result = chain.invoke(
{
"chat_history":memory,
"question":question
}
)
return resultmain.py:
python
import streamlit as st
from utils import rag_tool
from langchain.memory import ConversationBufferMemory
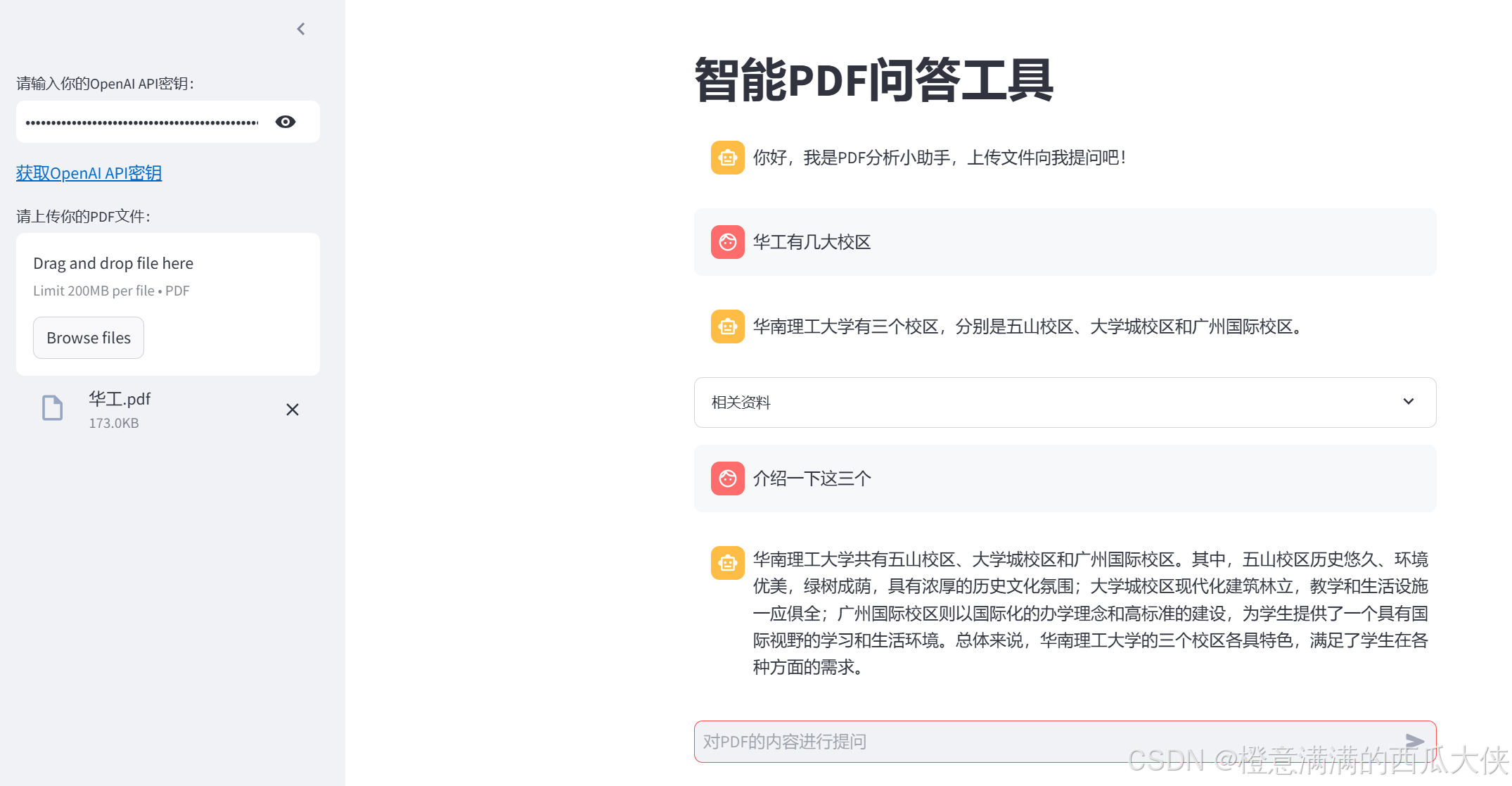
st.title("智能PDF问答工具")
with st.sidebar:
api_key = st.text_input("请输入你的OpenAI API密钥:",type="password")
st.markdown("[获取OpenAI API密钥](https://2233.ai/api)")
# 上传文件
uploaded_file = st.file_uploader("请上传你的PDF文件:",type="pdf")
# 初始化会话状态
if "memory" not in st.session_state:
st.session_state.memory = ConversationBufferMemory(
return_messages=True,
memory_key="chat_history",
output_key="answer"
)
st.session_state.messages = [
{
"role":"ai","content":"你好,我是PDF分析小助手,上传文件向我提问吧!"
}
]
st.session_state.documents = []
# 显示历史对话消息(初始显示)和历史资料
num = 0
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])
if message["role"]=="ai":
if message["content"]!="你好,我是PDF分析小助手,上传文件向我提问吧!": #注意超范围问题,第一句ai消息没有相应的相关资料
with st.expander("相关资料"):
st.write(st.session_state.documents[num][0].page_content)
num += 1
# 获取用户输入
question = st.chat_input("对PDF的内容进行提问")
if question:
if not api_key:
st.info("请输入你的OpenAI API密钥")
st.stop()
if not uploaded_file:
st.info("请先上传文件!")
st.stop()
# 合法后就显示
st.session_state.messages.append(
{"role":"human","content":question}
)
st.chat_message("human").write(question)
# 获取AI的回复
with st.spinner("AI正在思考中,请稍等···"):
result = rag_tool(api_key=api_key,memory=st.session_state.memory,uploaded_file=uploaded_file,question=question)
answer = result["answer"]
st.session_state.messages.append(
{"role":"ai","content":answer}
)
st.chat_message("ai").write(answer)
relavant_docs = result["source_documents"]
st.session_state.documents.append(relavant_docs)
with st.expander("相关资料"):
st.write(relavant_docs[0].page_content) #Document(id='1abe1f48-fd94-445f-b3ff-02b1b5f12f29', metadata={'source': './京剧介绍.txt'},page_content='***') 这种里面的元素是对象的属性,不是键值