可以分为先操作缓存和先操作数据库两种方式,更新缓存中的数据都是采用删除的方式,等到下一次查询时从更新之后的数据库中再写入缓存。
如果说先删除缓存,那么会出现下面这种情况,当线程 1 删除缓存之后,由于网络延迟,线程 2 先执行查询操作,没有查询到目标数据之后,就会从数据库中把旧的数据写入缓存中,然后线程 1 再更新数据库,此时虽然数据库中是更新之后的数据,但是之后再进行查询的时候,由于缓存中已经又重新被写入了旧数据,此时就会出现数据不一致的问题
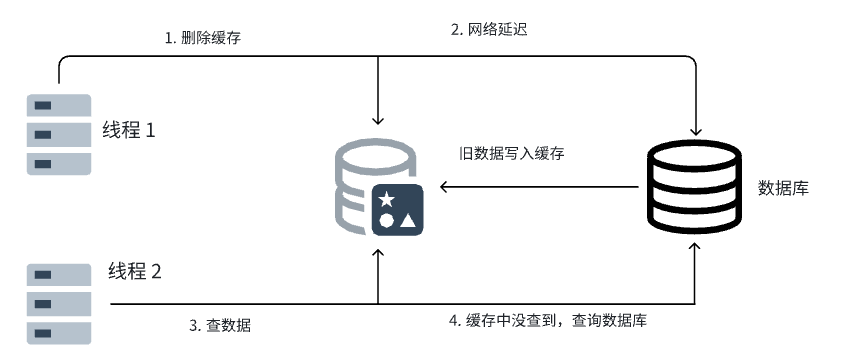
解决方案是通过延迟双删的方式,第一次线程 1 删除缓存,等到数据库中的数据更新之后,延迟一段时间再进行删除缓存,通过两次删除,就能保证之后再获取缓存中的数据时不会获取到脏数据,而延迟一段时间再删除是为了确保线程 2 把旧数据写入缓存之后再进行删除,不然即使执行双删操作,旧数据也会重新被写入缓存,双删了个寂寞。
再来看先操作数据库的方案:
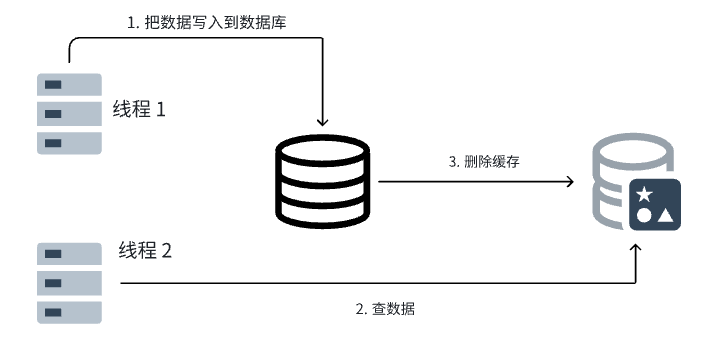
先把数据写入到数据库,然后再删除缓存,这种方式其实还是存在问题,如果删除缓存时删除失败了,那么之后查询到的还是旧数据,还是存在数据不一致问题。
针对缓存删除失败的情况,可以采用删除重试的方式,重试的操作可以添加到 MQ 中,通过异步的方式来处理,这样的话代码的耦合度也会上来,如果要实现解耦,可以采用读取 binlog 来进行异步删除。
最终的方案就是:先修改数据库,然后通过 Canal 监听数据库的 binlog 日志,记录数据库的修改信息,然后通过消息队列异步修改缓存的数据,需要注意保证缓存中数据按顺序更新,然后加上重试机制,避免由于网络问题导致更新失败