《Attention is All You Need》是一篇极其重要的论文,它提出的 Transformer 模型和自注意力机制不仅推动了 NLP 领域的发展,还对整个深度学习领域产生了深远影响。这篇论文的重要性体现在其开创性、技术突破和广泛应用上,是每一位深度学习研究者和从业者必读的经典之作
1. 论文背景与动机
研究背景
• 在 2017 年之前,序列建模任务(如机器翻译)主要依赖于递归神经网络(RNN)和卷积神经网络(CNN)。
• RNN 和 CNN 存在一些问题:
• RNN 难以并行化,训练速度慢。
• CNN 难以捕捉长距离依赖关系。
研究动机
• 提出一种完全基于注意力机制(Attention Mechanism)的模型,摒弃递归和卷积结构,解决上述问题。
• 目标是通过并行化和长距离依赖捕捉,提高模型效率和性能。
2. 核心贡献
论文的主要贡献包括:
- 提出 Transformer 模型:完全基于自注意力机制(Self-Attention)的架构。
- 引入多头注意力机制(Multi-Head Attention):通过多个注意力头捕捉不同的特征表示。
- 位置编码(Positional Encoding):通过添加位置信息,弥补自注意力机制无法感知序列顺序的缺陷。
- 在机器翻译任务上取得显著性能提升:在 WMT 2014 英德和英法翻译数据集上取得了当时的最优结果。

3. 模型架构
Transformer 模型由编码器(Encoder)和解码器(Decoder)组成,每个部分由多个相同的层堆叠而成。
编码器(Encoder)
• 每层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention):捕捉输入序列中元素之间的关系。
- 前馈神经网络(Feed-Forward Network) :对每个位置的表示进行非线性变换。
• 每个子层后使用残差连接(Residual Connection)和层归一化(Layer Normalization)。
解码器(Decoder)
• 每层包含三个子层:
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention):防止解码器关注未来信息。
- 多头注意力机制(Multi-Head Attention):关注编码器的输出。
- 前馈神经网络(Feed-Forward Network) 。
• 同样使用残差连接和层归一化。
位置编码(Positional Encoding)
• 由于 Transformer 没有递归或卷积结构,它需要额外的位置信息来感知序列顺序。
• 使用正弦和余弦函数生成位置编码,并将其添加到输入嵌入中。
4. 关键技术
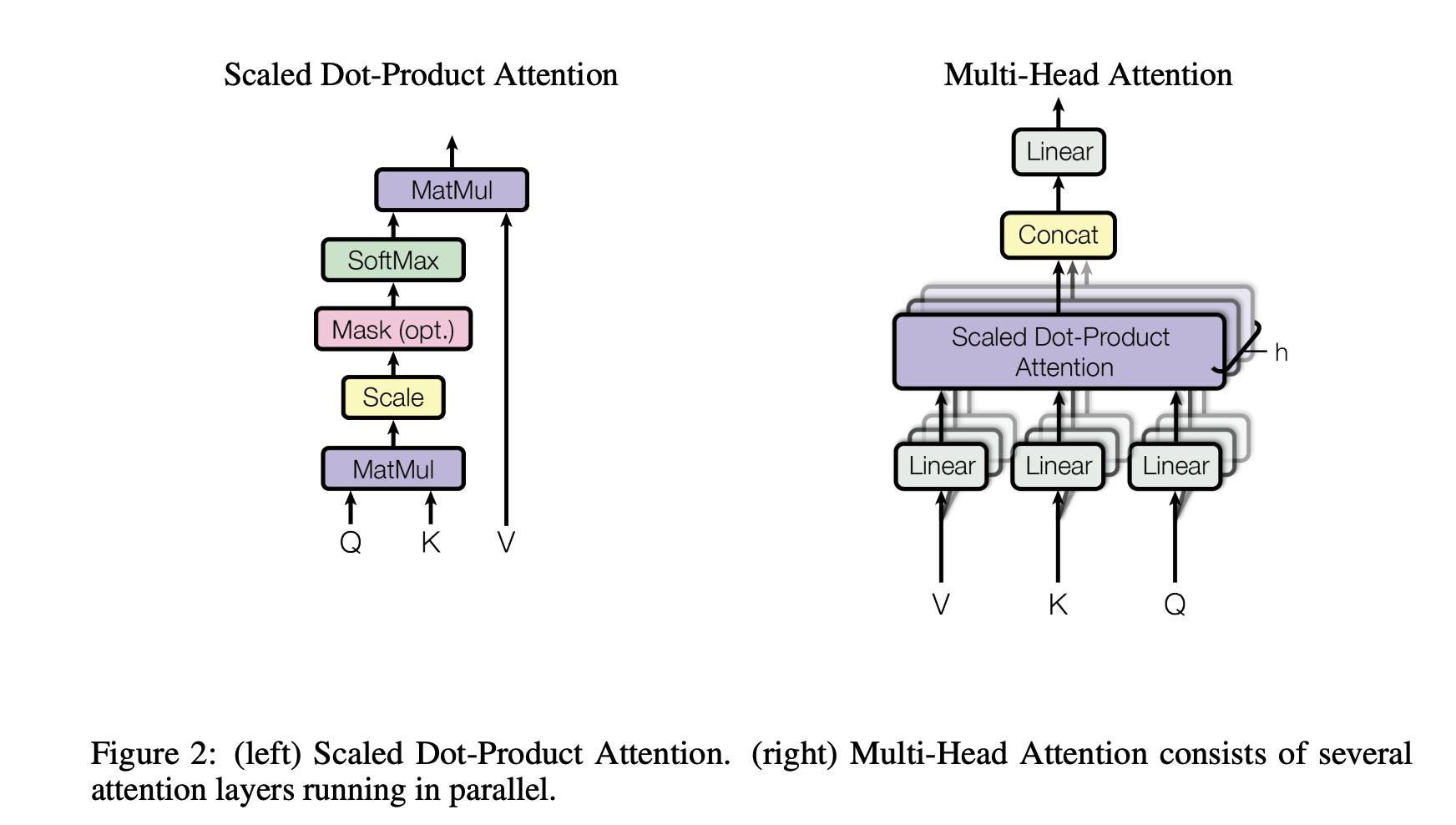
自注意力机制(Self-Attention)
• 通过 Query、Key、Value 计算输入序列中元素之间的关联性。
• 公式:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dk QKT)V
其中 d k d_k dk 是 Key 的维度。
多头注意力机制(Multi-Head Attention)
• 使用多个注意力头捕捉不同的特征表示。
• 公式:
MultiHead ( Q , K , V ) = Concat ( head 1 , ... , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中每个头独立计算注意力。
训练与优化
• 使用 Adam 优化器,动态调整学习率。
• 使用标签平滑(Label Smoothing)防止过拟合。
5. 实验与结果
数据集
• WMT 2014 英德和英法翻译数据集。
性能
• 在英德翻译任务上,BLEU 得分为 28.4,比当时的最优模型提高了 2 BLEU。
• 在英法翻译任务上,BLEU 得分为 41.8,训练成本仅为其他模型的 1/4。
消融实验
• 验证了多头注意力机制、位置编码和模型深度对性能的影响。
6. 讨论与未来工作
• Transformer 模型的并行化能力使其在大规模数据集上表现优异。
• 自注意力机制的计算复杂度随序列长度平方增长,限制了其在长序列任务中的应用。
• 未来可以探索更高效的自注意力机制和更大规模的预训练模型。
7. 总结
"Attention is All You Need" 提出了 Transformer 模型,彻底改变了序列建模领域。其核心创新------自注意力机制和多头注意力机制------为后续研究(如 BERT、GPT 等)奠定了基础。这篇论文不仅在理论上具有重要价值,还在实际应用中取得了显著成果,成为现代深度学习的里程碑之一。