https://github.com/stanford-cs149/asst1
bash
sudo apt-get autoremove open-vm-tools
sudo apt-get install open-vm-tools-desktop
wget https://github.com/ispc/ispc/releases/download/v1.24.0/ispc-v1.24.0-linux.tar.gz
sudo apt-get install git
sudo apt-get install ispc
export PATH=$PATH:${HOME}/(自己路径)/ispc-v1.24.0-linux/bin
gcc编译出错:fatal error: sys/cdefs.h: No such file or directory
sudo apt install gcc-multilib # 一般安装这个就可以了,不行再安装下面的
sudo apt install g++-multilib
sudo apt install libc6-dev libc6-dev-i386任务1

线程数 耗时(单位:ms)
1 333
2 169
3 209
4 138
5 135
6 108
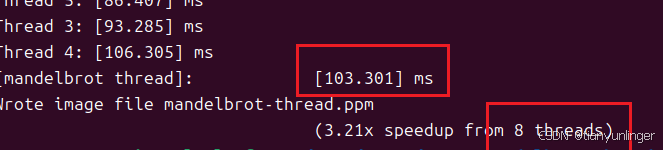
7 103
8 100
利用率不足的原因是不同线程负责的图像区域迭代的计算量不同,导致计算时间不同,出现了短板效应。3 线程中中间部分的计算时间明细大于上下两边,导致时间增加。
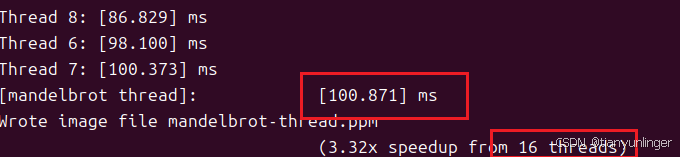
使用 16 线程时,性能提升通常不会显著高于 8 线程。
任务2
bash
void _cs149_vload_float(__cs149_vec_float &dest, float* src, __cs149_mask &mask) { _cs149_vload<float>(dest, src, mask); }
void _cs149_vload_int(__cs149_vec_int &dest, int* src, __cs149_mask &mask) { _cs149_vload<int>(dest, src, mask); }dest: 目标向量寄存器,存储从数组中加载的值。
src: 源数组,从中加载值。
mask: 掩码,控制哪些元素被加载。掩码中为1的位置表示对应的元素将被加载,为0的位置表示对应的元素保持原值
传统的标量操作是指每次处理一个数据点。例如,对于一个简单的数组加法操作:
cpp
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}在这个循环中,每次迭代只处理一个元素,总共需要N次迭代来完成整个数组的加法。
向量化操作
向量化操作通过使用SIMD指令,可以在一个时钟周期内同时处理多个数据点。例如,使用向量化指令可以将上述数组加法操作优化为:
cpp
for (int i = 0; i < N; i += VECTOR_WIDTH) {
__cs149_vec_float a, b, c;
_cs149_vload_float(a, A + i, mask);
_cs149_vload_float(b, B + i, mask);
_cs149_vadd_float(c, a, b, mask);
_cs149_vstore_float(C + i, c, mask);
}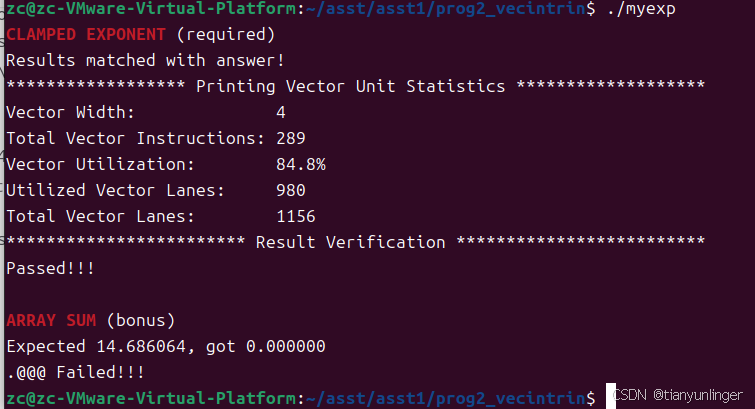
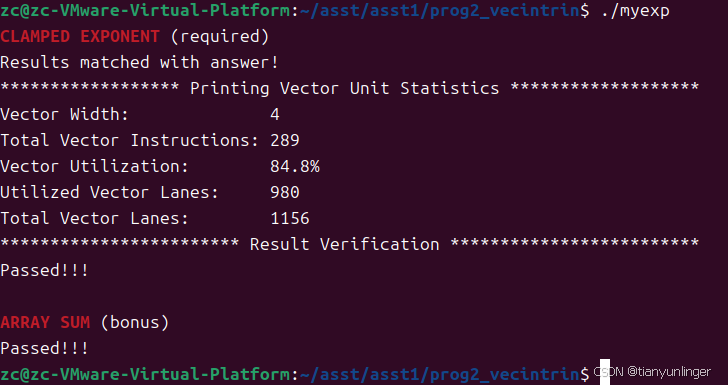
任务3
在 ISPC(Intel® Implicit SPMD Program Compiler)的上下文中,task(任务) 是一个用于实现并行计算的高级抽象概念。它允许程序员将程序分解为多个独立的计算单元,这些计算单元可以并行执行,从而充分利用多核 CPU 的计算能力
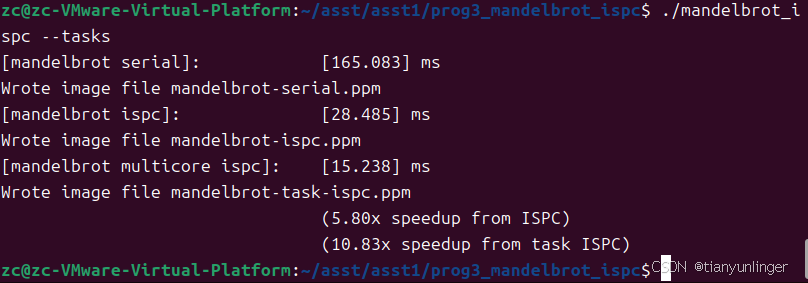
线程抽象和 ISPC 任务抽象主要有以下区别:线程是重量级的,每个线程都有独立的栈和上下文,适合复杂的、需要独立执行流的任务;而 ISPC 任务是轻量级的,由运行时系统管理,适合数据并行和计算密集型任务。如果你启动 10,000 个 ISPC 任务,运行时系统会高效地管理这些任务,将它们分配到可用的 CPU 核心上,即使任务数量远超核心数量,系统也能保持较高的效率。相反,如果启动 10,000 个线程,操作系统的线程调度和资源分配会变得非常低效,可能导致系统性能严重下降,甚至出现资源耗尽的情况。
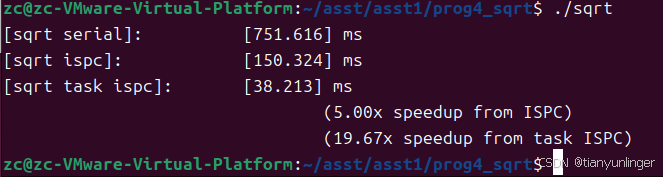
任务4
牛顿迭代法
牛顿迭代法是一种用于寻找实值函数零点的数值方法。假设我们有一个函数 f ( x ) f(x) f(x),我们想要找到它的根,即 f ( x ) = 0 f(x) = 0 f(x)=0 的解。牛顿迭代法通过以下步骤来逼近这个根:
- 初始猜测 :选择一个初始猜测值 x 0 x_0 x0。
- 迭代公式 :使用以下公式进行迭代:
x n + 1 = x n − f ( x n ) f ′ ( x n ) x_{n+1} = x_n - \frac{f(x_n)}{f'(x_n)} xn+1=xn−f′(xn)f(xn)
其中, f ′ ( x n ) f'(x_n) f′(xn) 是函数 f f f 在点 x n x_n xn 处的导数。 - 收敛条件 :当 ∣ x n + 1 − x n ∣ |x_{n+1} - x_n| ∣xn+1−xn∣ 小于某个设定的容忍度(如 1 0 − 6 10^{-6} 10−6)时,认为迭代收敛,停止迭代。
更改main函数中的values值
cpp
values[i] = .5f + 2.0f * static_cast<float>(rand()) / RAND_MAX; 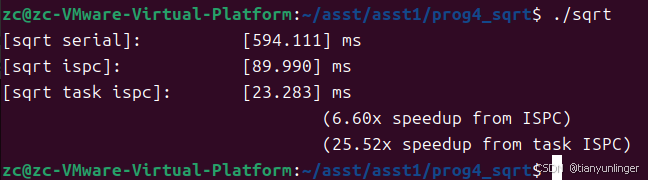
cpp
values[i] = (i % 8 == 0) ? 2 : 1;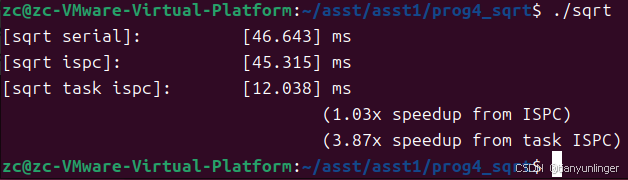
c
values[i] = (i % 8 == 0) ? 0.0f : 0.0001f;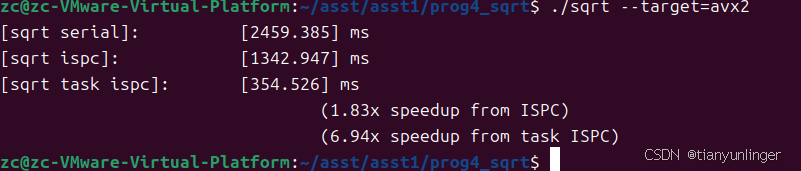
任务五
SAXPY 是一个常见的线性代数操作,其名称来源于 S ingle A precision X plus Y,即"单精度浮点数的 X 加上 Y"。它是 BLAS(Basic Linear Algebra Subprograms,基础线性代数子程序) 库中的一个标准函数,用于执行向量操作。

乘数 4 可以理解为:
从 X 加载一个缓存行。
从 Y 加载一个缓存行。
将结果写回到 Y(可能触发缓存写回)。
额外的缓存行加载和写回操作。
saxpy.ispc文件
优化后的代码通过动态计算任务数量和跨度,更好地利用了多核和 SIMD 的并行能力。
c
export void saxpy_ispc_withtasks(uniform int N,
uniform float scale,
uniform float X[],
uniform float Y[],
uniform float result[])
{
// Calculate the number of tasks based on the number of available cores
// and the SIMD width (e.g., 8 for AVX2).
uniform int numCores = 8; // Adjust based on your system
uniform int simdWidth = 8; // AVX2: 8-wide SIMD
uniform int numTasks = numCores * simdWidth;
// Calculate the span for each task
uniform int span = (N + numTasks - 1) / numTasks; // Ceiling division
// Launch tasks
launch[numTasks] saxpy_ispc_task(N, span, scale, X, Y, result);
}
任务六
error: externally-managed-environment
× This environment is externally managed
╰─> To install Python packages system-wide, try apt install
python3-xyz, where xyz is the package you are trying to
install.
bash
sudo mv /usr/lib/python3.x/EXTERNALLY-MANAGED /usr/lib/python3.x/EXTERNALLY-MANAGED.bk
bash
ln -s /afs/ir.stanford.edu/class/cs149/data/data.dat ./data.dat外部服务器无法访问数据
参考网站: