自然语言处理
第一章 自言语言处理基础
第二章 自然语言处理实践
文章目录
- 自然语言处理
- 前言
- 一、自然语言主要处理技术
-
- [1. 分词(segment)](#1. 分词(segment))
- [2. 词性标注(part-of-speech tagging)](#2. 词性标注(part-of-speech tagging))
- [3. 命名实体识别(NER,Named Entity Recognition)](#3. 命名实体识别(NER,Named Entity Recognition))
- [4. 句法分析(syntax parsing)](#4. 句法分析(syntax parsing))
- [5. 指代消解(anaphora resolution)](#5. 指代消解(anaphora resolution))
- [6. 情感识别(emotion recognition)](#6. 情感识别(emotion recognition))
- [7. 纠错(correction)](#7. 纠错(correction))
- [8. 问答系统(QA system)](#8. 问答系统(QA system))
- 二、中文分词的概念与分类
-
- [1. 概念](#1. 概念)
- [2. 正向最大匹配法](#2. 正向最大匹配法)
- [3. 逆向最大匹配法](#3. 逆向最大匹配法)
- [4. 双向最大匹配法](#4. 双向最大匹配法)
- 三、jieba分词
-
- [1. 介绍](#1. 介绍)
- [2. 特点](#2. 特点)
- [3. 分词模式](#3. 分词模式)
-
- [1. 精确模式(Full Mode)](#1. 精确模式(Full Mode))
- [2. 全模式(Full Mode)](#2. 全模式(Full Mode))
- [3. 搜索引擎模式(Search Mode)](#3. 搜索引擎模式(Search Mode))
- 4、Jieba分词的使用方
- [四. NLTK](#四. NLTK)
-
- [1. 分词与词性标注](#1. 分词与词性标注)
- [2. 情感分析](#2. 情感分析)
- [3. 句法分析](#3. 句法分析)
- [五. 总结](#五. 总结)
前言
自然语言处理(Natural Language Processing,NLP)
关注的是自然语言与计算机之间的交互。它是人工智能(Artificial Intelligence,AI)和计算语言学的主要分支之一。
它提供了计算机和人类之间的无缝交互并使得计算机能够在机器学习的帮助下理解人类语言。
一、自然语言主要处理技术
1. 分词(segment)
分词常用的手段是基于字典的最长串匹配,据说可以解决85%的问题,但是歧义分词很难。举个例子,"美国会通过对台售武法案",我们既可以切分为"美国/会/通过对台售武法案",又可以切分成"美/国会/通过对台售武法案"。
2. 词性标注(part-of-speech tagging)
词性一般是指动词、名词、形容词等。例如:我/r爱/v北京/ns天安门/ns。其中,ns代表名词v代表动词,ns、v都是标注,以此类推。
3. 命名实体识别(NER,Named Entity Recognition)
命名实体是指从文本中识别具有特定类别的实体(通常是名词),例如人名、地名、机构名专有名词等。
4. 句法分析(syntax parsing)
"小李是小杨的班长"和"小杨是小李的班长",这两句话句法分析可以分析出其中的主从关系,哪 你的AI入门首选课更专业的满足你定制化A1需求真正理清句子的关系。
5. 指代消解(anaphora resolution)
中文中代词出现的频率很高,它的作用的是用来表征前文出现过的人名、地名等。例如,清华大学坐落于北京,这家大学是目前中国最好的大学之一。在这句话中,其实"清华大学"这个词出现了两次,"这家大学"指代的就是清华大学。但是出于中文的习惯,我们不会把"清华大学"再重复一遍。
6. 情感识别(emotion recognition)
所谓情感识别,本质上是分类问题,经常被应用在舆情分析等领域。情感一般可以分为正面、负面,中性三类别。在电商企业,情感识别可以分析商品评价的好坏,以此作为下一个环节的评判依据。
7. 纠错(correction)
自动纠错在搜索技术以及输入法中利用得很多。由于用户的输入出错的可能性比较大,出错的场景也比较多。所以,我们需要一个纠错系统。
8. 问答系统(QA system)
比较著名的有:苹果Siri、IBM Watson、微软小冰等。问答系统往往需要语音识别、合成,自然语言理解、知识图谱等多项技术的配合才会实现得比较好。

二、中文分词的概念与分类
1. 概念
中文分词(Chinese Word Segmentation)是将连续的中文文本序列切分成一个个独立、有意义的词汇的过程。与英文等西方语言不同,中文文本中没有明显的单词边界,词语之间紧密相连,因此需要通过分词来明确词语的界限。例如,句子"我爱自然语言处理"如果不进行分词,计算机无法准确理解其含义,而经过分词后,可以切分为"我/爱/自然语言处理",这样每个词汇的意义就变得清晰明了,为后续的文本分析、语义理解等任务奠定了基础。
基于规则的分词是一种机械分词方法,主要是通过维护词典,在切分语句时,将语句的每个字符串与词表中的词进行逐一匹配,找到则切分,否则不予切分。按照匹配切分的方式,主要有正向最大匹配法、逆向最大匹配法以及双向最大匹配法三种方法。
2. 正向最大匹配法
比如我们现在有个词典,最长词的长度为5,词典中存在"南京市长"和"长江大桥"两个词。现采用正向最大匹配对句子"南京市长江大桥"进行分词,那么首先从句子中取出前五个字"南京市长江",发现词典中没有该词,于是缩小长度,取前4个字"南京市长",词典中存在该词,于是该词被确认切分。再将剩下的"江大桥"按照同样方式切分,得到"江""大桥",最终分为"南京市长""江""大桥"3个词。显然,这种结果还不是我们想要的。
3. 逆向最大匹配法
逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(i为词典中最长词数)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。比如之前的"南京市长江大桥",按照逆向最大匹配,最终得到"南京市""长江大桥"。当然,如此切分并不代表完全正确,可能有个叫"江大桥"的"南京市长"也说不定。
4. 双向最大匹配法
双向最大匹配法(Bi-directction Matching method)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。"南京市长江大桥"采用该方法,中间产生"南京市/长江/大桥"和"南京市/长江大桥"两种结果,最终选取词数较少的"南京市/长江大桥"这一结果。
三、jieba分词
1. 介绍
Jieba分词:高效、灵活的中文分词工具在自然语言处理领域,中文分词是处理中文文本的基础任务之一。Jieba分词是目前最流行、使用最广泛的中文分词库之一,它以其高效、灵活和易于使用的特点,广泛应用于各种自然语言处理任务中。
2. 特点
Jieba分词的主要特点如下:
高效性:Jieba分词的分词速度非常快,单核分词速度可达100万字/秒,在处理大规模文本数据时表现出色。
准确性:它结合了多种分词算法,包括基于前缀词典实现高效的词图扫描、动态规划查找最大概率路径进行快速分词,以及基于隐马尔可夫模型(HMM)的词性标注,能够有效处理歧义和未登录词。
灵活性:Jieba分词支持多种分词模式,用户可以根据具体需求选择不同的分词策略。此外,它还允许用户自定义词典,动态调整分词结果。
开源性:Jieba分词是开源项目,代码托管在GitHub上,社区活跃,开发者可以方便地获取源码、进行二次开发或扩展功能。
3. 分词模式
Jieba分词提供了三种主要的分词模式,以满足不同场景下的需求:
1. 精确模式(Full Mode)
精确模式是Jieba分词的默认模式,它试图将句子最精确地切开,适合文本分析等场景。这种模式会尽可能地匹配最长的词语,减少歧义,但可能会导致分词结果较为保守。例如,对于句子"我爱自然语言处理",精确模式会将其切分为"我/爱/自然语言处理"。
2. 全模式(Full Mode)
全模式会把句子中所有可能的词语都扫描出来,速度非常快,但不能解决歧义。这种模式适合快速提取文本中的关键词或进行初步的分词测试。例如,对于句子"我爱自然语言处理",全模式会将其切分为"我/爱/自然/自然语言/自然语言处理/语言/语言处理/处理"。
3. 搜索引擎模式(Search Mode)
搜索引擎模式是基于精确模式的改进,它在精确模式的基础上,对长词再次切分,提高召回率,特别适合用于搜索引擎构建倒排索引的分词,粒度比较细。例如,对于句子"我爱自然语言处理",搜索引擎模式会将其切分为"我/爱/自然/自然语言/自然语言处理/语言/语言处理/处理"。
4、Jieba分词的使用方
python
pip install jieba
import jieba
# 默认精确模式
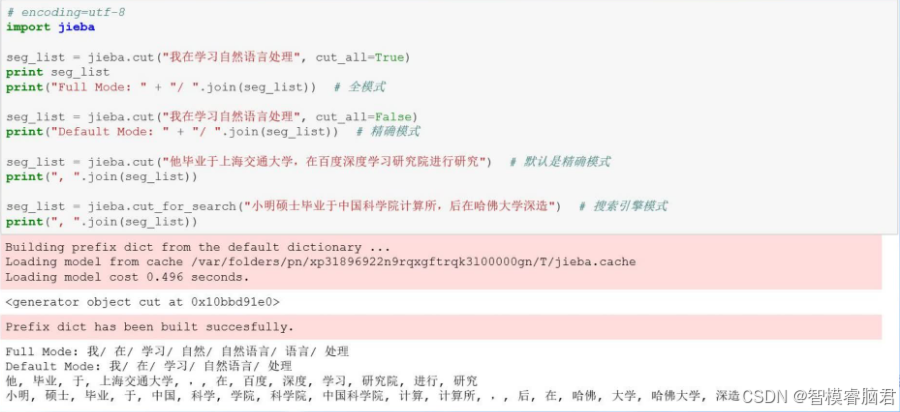
seg_list = jieba.cut("我爱自然语言处理", cut_all=False)
print("精确模式: " + "/ ".join(seg_list))
# 全模式
seg_list = jieba.cut("我爱自然语言处理", cut_all=True)
print("全模式: " + "/ ".join(seg_list))
seg_list = jieba.cut_for_search("我爱自然语言处理")
print("搜索引擎模式: " + "/ ".join(seg_list))
词性标注
python
import jieba.posseg as pseg
words = pseg.cut("我爱自然语言处理")
for word, flag in words:
print(f"{word} {flag}")输出结果如下:
我 r
爱 v
自然语言处理 n

四. NLTK
NLTK提供了从基础到高级的自然语言处理功能,涵盖了文本预处理、分词、词性标注、句法分析、语义分析等多个方面。它还支持情感分析、命名实体识别(NER)、机器翻译等复杂任务,几乎涵盖了自然语言处理的各个领域。
1. 分词与词性标注
NLTK支持多种分词算法,包括基于正则表达式的分词器和基于预训练模型的分词器。此外,NLTK还提供了词性标注工具,可以为文本中的每个单词标注其词性(名词、动词、形容词等)。
python
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag
text = "NLTK is a powerful tool for natural language processing."
tokens = word_tokenize(text) # 分词
tags = pos_tag(tokens) # 词性标注
print(tags)2. 情感分析
python
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
analyzer = SentimentIntensityAnalyzer()
text = "I love this movie! It is amazing."
scores = analyzer.polarity_scores(text)
print(scores)3. 句法分析
python
import nltk
from nltk import CFG, RecursiveDescentParser
grammar = CFG.fromstring("""
S -> NP VP
NP -> 'the' N
VP -> V NP
N -> 'cat' | 'dog'
V -> 'chased'
""")
parser = RecursiveDescentParser(grammar)
sentence = "the cat chased the dog".split()
for tree in parser.parse(sentence):
print(tree)五. 总结
Jieba分词是一款高效、灵活且易于使用的中文分词工具,它在自然语言处理领域得到了广泛应用。通过多种分词模式和自定义功能,Jieba能够满足不同场景下的需求。尽管存在一些局限性,但通过不断更新和优化,Jieba分词仍然是中文分词领域的重要工具之一。对于需要进行中文文本处理的开发者和研究人员来说,Jieba分词是一个不可多得的利器。
NLTK是一个功能强大、易于上手的自然语言处理工具包,它为开发者提供了丰富的功能和资源,适用于教学、研究和开发等多种场景。尽管存在一些局限性,但NLTK仍然是自然语言处理领域中最受欢迎的工具之一。对于初学者来说,NLTK是学习自然语言处理的绝佳起点;对于经验丰富的开发者,NLTK也可以作为快速原型开发和实验的工具。