1.安装transformers
一定要按照下面的方法安装(或者从源码安装),否则会报错,试了其他几种方法都不行
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .安装完有下面提示即可:
Successfully installed transformers-4.50.0.dev0
2.下载权重
地址:
https://huggingface.co/google/siglip2-base-patch16-224/tree/main
3.推理代码
方法1:
python
from transformers import pipeline
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
dtype = torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "google/siglip2-base-patch16-224"
# load pipeline
image_classifier = pipeline(task="zero-shot-image-classification",model="google/siglip2-base-patch16-224",)
path ="000000039769.jpg"
image = Image.open(path)
candidate_labels = ["2 cats", "a plane", "a remote"]
outputs = image_classifier(image, candidate_labels=candidate_labels)
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
print(outputs)推理结果:

方法2:
python
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip2-base-patch16-224")
processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-224")
#url = "http://images.cocodataset.org/val2017/000000039769.jpg"
#image = Image.open(requests.get(url, stream=True).raw)
path ="000000039769.jpg"
image = Image.open(path)
candidate_labels = ["2 cats", "2 dogs"]
# follows the pipeline prompt template to get same results
texts = [f"This is a photo of {label}." for label in candidate_labels]
# IMPORTANT: we pass `padding=max_length` and `max_length=64` since the model was trained with this
inputs = processor(text=texts, images=image, padding="max_length", max_length=64, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image) # these are the probabilities
print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")推理结果:
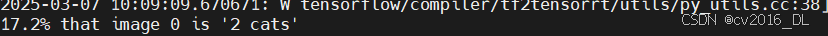
4.动态分辨率测试代码
注意下面的代码中# fixres的 processo需要自己再定义下:
python
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
# first, create an image with a circle and define labels
def create_image(width, height):
image = Image.new("RGB", (width, height), color="red")
draw = ImageDraw.Draw(image)
center_x = image.width // 2
center_y = image.height // 2
radius = min(center_x, center_y) // 8 * 7
draw.ellipse(
(center_x - radius, center_y - radius, center_x + radius, center_y + radius),
fill="blue",
outline="green",
width=image.width // 20,
)
return image
labels = [
"a circle",
"an ellipse",
"a square",
"a rectangle",
"a triangle",
]
text = [f"A photo of {label}." for label in labels]
print(text)
image_with_circle = create_image(512, 256)
# loading NaFlex model and processor
naflex_checkpoint = "google/siglip2-base-patch16-naflex"
naflex_model = AutoModel.from_pretrained(naflex_checkpoint, torch_dtype=dtype, device_map=device)
naflex_processor = AutoProcessor.from_pretrained(naflex_checkpoint)
# naflex inference
inputs = naflex_processor(text=text, images=image_with_circle, padding="max_length", max_length=64, return_tensors="pt")
inputs = inputs.to(device)
with torch.inference_mode():
naflex_outputs = naflex_model(**inputs)
# fixres inference
inputs = processor(text=text, images=image_with_circle, padding="max_length", max_length=64, return_tensors="pt")
inputs = inputs.to(device)
with torch.inference_mode():
outputs = model(**inputs)
#visualize results
logits_per_text = torch.cat([naflex_outputs.logits_per_text, outputs.logits_per_text], dim=1)
probs = (logits_per_text.float().sigmoid().detach().cpu().numpy() * 100)
pd.DataFrame(probs, index=labels, columns=["naflex", "fixres"]).style.format('{:.1f}%').background_gradient('Greens', vmin=0, vmax=100)