1. 作者介绍
郭建东,男,西安工程大学电子信息学院,2024级研究生
研究方向:机器视觉与人工智能
电子邮件:1229963266@qq.com
高金年,男,西安工程大学电子信息学院,2024级研究生,张宏伟人工智能课题组
研究方向:机器人与智能装备控制技术
电子邮件:2432529790@qq.com
2. 调用通义千问实现语音合成并将合成的音频通过扬声器播放
2.1.通义千问语音合成简介
通义千问是阿里云推出的一个大型语言模型,基于先进的深度学习技术打造,能够理解和生成自然语言,在多轮对话、知识问答等多种应用场景中发挥重要作用。
优点:它具有高度准确的语言理解能力,能精准把握用户问题和意图;支持多种语言输入输出,如中文、英文等;还具备出色的多轮对话支持能力,可依据上下文进行交互,提供自然流畅的对话体验。
2.2语音合成
语音合成,又称文本转语音(Text-to-Speech,TTS),是将文本转换为自然语音的技术。该技术基于机器学习算法,通过学习大量语音样本,掌握语言的韵律、语调和发音规则,从而在接收到文本输入时生成真人般自然的语音内容。
作用:在通义千问的应用生态中,语音合成技术至关重要。它将模型生成的文本转化为语音,实现了人机交互的语音化,让用户能通过语音接收信息,极大地提升了交互的便捷性和自然度。
例如在智能客服场景中,用户提问后,通义千问给出的回答可通过语音合成直接播报,无需用户阅读文字,尤其适用于不方便看屏幕的场景,提高了服务效率和用户体验。
2.3.通义千问语音合成算法
- CosyVoice 模型介绍:
CosyVoice是通义实验室依托大规模预训练语言模型,深度融合文本理解和语音生成的新一代生成式语音合成大模型,在自然语音生成方面表现卓越。支持多语言生成,涵盖中文、英文、日文、粤语和韩语五种语言,满足不同地区用户的需求;具备强大的音色和情感控制能力,仅需3 - 10秒的原始音频,就能生成模拟音色,包含韵律和情感等细节,还能通过富文本或自然语言形式对生成语音的情感和韵律进行细粒度控制,使生成的语音更加生动自然。 - 语音合成算法原理
(1) 文本分析:对输入的文本进行深入分析,包括词汇、语法、语义理解,识别文本中的关键词、短语结构以及语义关系,为后续的语音参数生成提供基础。例如分析句子"今天天气真好",确定"今天"是时间词,"天气真好"表达积极的天气状况描述。
(2) 声学模型:根据文本分析结果,结合声学知识,预测生成语音所需的声学参数,如基频、共振峰、时长等,这些参数决定了语音的音高、音色和语速等特征。
(3) 波形生成:利用预测得到的声学参数,通过特定的算法生成语音波形,最终转化为可播放的音频信号。
3. 代码实现
3.1开通服务并获取 API - KEY
(1) 百度搜索阿里云
(2) 注册账号

3)击右侧控制台
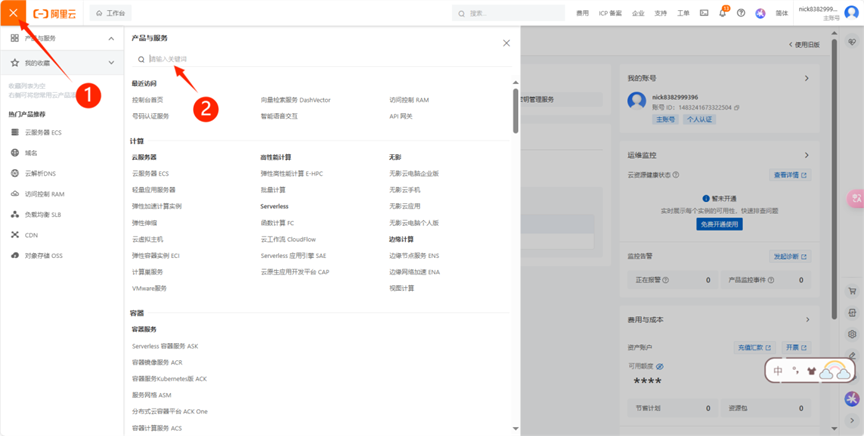
(4) 点击左边导航搜索向量检索服务DashVector
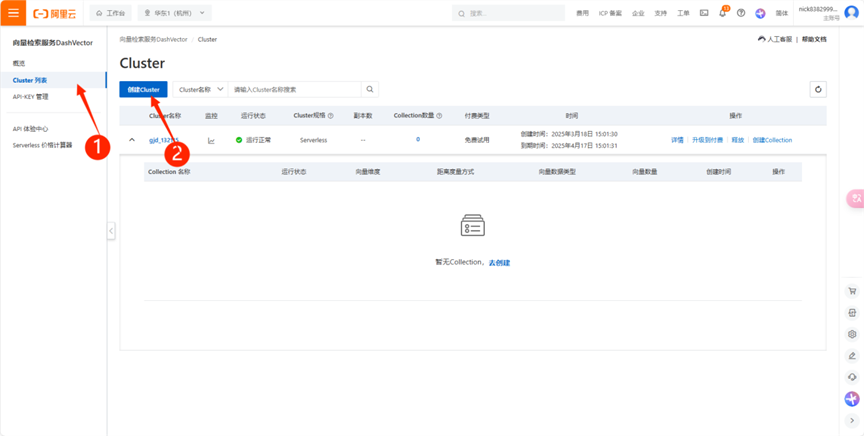
(5) 在Cluster列表中,点击创建Cluster
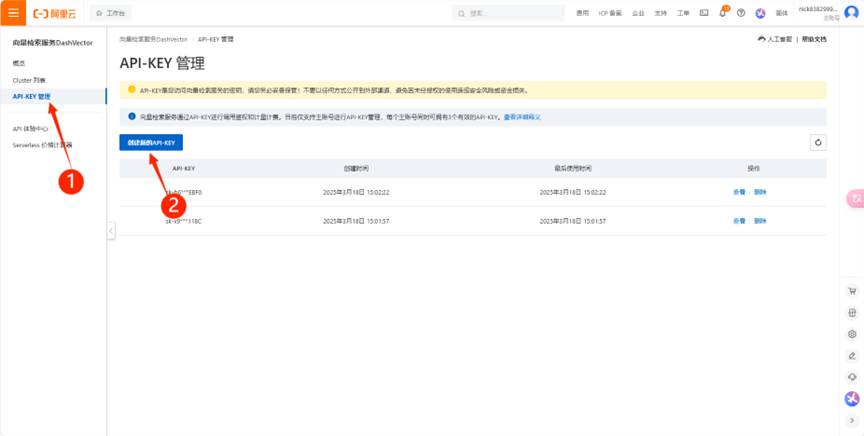
(6) 在API-KEY管理中,创建自己的API-KEY密钥
3.2将获取的 API - KEY配置到环境变量
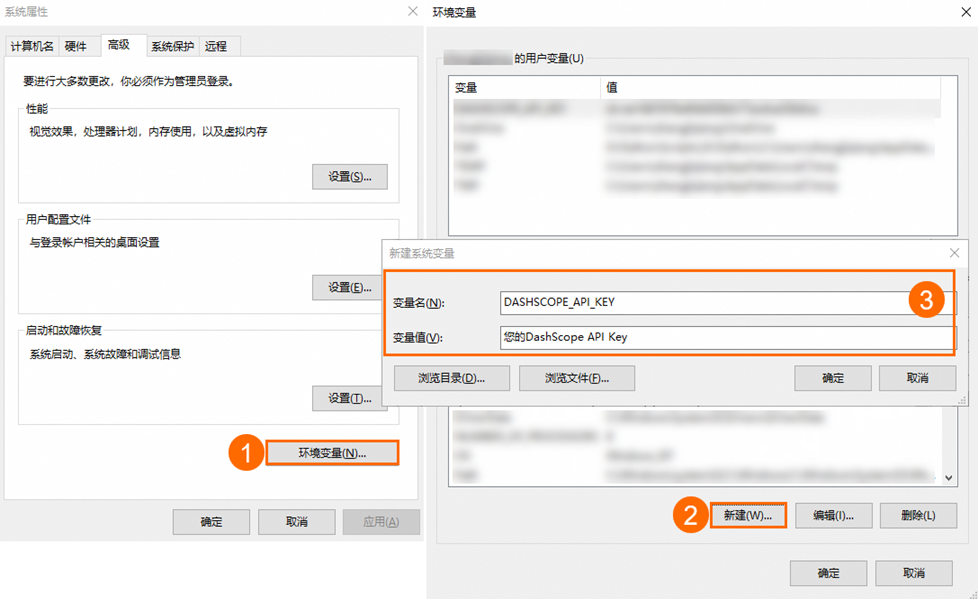
(1) 在Windows系统桌面中按Win+Q键,在搜索框中搜索编辑系统环境变量,单击打开系统属性界面。
(2) 在系统属性窗口,单击环境变量,然后在系统变量区域下单击新建,变量名填DASHSCOPE_API_KEY,变量值填入您的DashScope API Key。
(3) 依次单击三个窗口的确定,关闭系统属性配置页面,完成环境变量配置。
(4) 打开CMD(命令提示符)窗口或Windows PowerShell窗口,执行如下命令检查环境变量是否生效。
CMD查询命令:echo %DASHSCOPE_API_KEY%

3.3 安装最新版 SDK
通过运行以下命令安装DashScope Python SDK:pip install -U dashscope
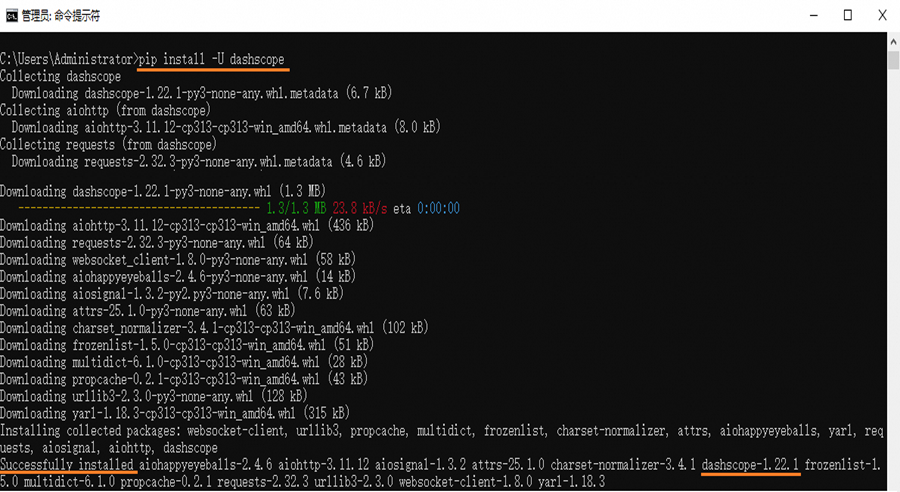
当终端出现Successfully installed ... dashscope-x.x.x的提示后,表示您已经成功安装DashScope Python SDK。
3.4 安装需要的库
(1) 首先需要创建虚拟环境
(2) 在搜索栏中输入Windows PowerShell,以 管理员身份 运行(避免权限问题)。
(3) 创建一个新虚拟环境,名字为py39_env(可以自己改)。

(4) 激活环境。

(5) 安装需要的库

3.5运行代码
若没有将API Key配置到环境变量中,需将下面这行代码注释放开,并将apiKey替换为自己的API Key------# dashscope.api_key = "apiKey"
python
import pyaudio
import dashscope
from dashscope.audio.tts_v2 import *
from http import HTTPStatus
from dashscope import Generation
# 若没有将API Key配置到环境变量中,需将下面这行代码注释放开,并将apiKey替换为自己的API Key
# dashscope.api_key = "apiKey"
model = "cosyvoice-v1"
voice = "longxiaochun"
class Callback(ResultCallback):
_player = None
_stream = None
def on_open(self):
print("websocket is open.")
self._player = pyaudio.PyAudio()
self._stream = self._player.open(
format=pyaudio.paInt16, channels=1, rate=22050, output=True
)
def on_complete(self):
print("speech synthesis task complete successfully.")
def on_error(self, message: str):
print(f"speech synthesis task failed, {message}")
def on_close(self):
print("websocket is closed.")
# stop player
self._stream.stop_stream()
self._stream.close()
self._player.terminate()
def on_event(self, message):
print(f"recv speech synthsis message {message}")
def on_data(self, data: bytes) -> None:
print("audio result length:", len(data))
self._stream.write(data)
def synthesizer_with_llm():
callback = Callback()
synthesizer = SpeechSynthesizer(
model=model,
voice=voice,
format=AudioFormat.PCM_22050HZ_MONO_16BIT,
callback=callback,
)
messages = [{"role": "user", "content": "请介绍一下你自己"}]
responses = Generation.call(
model="qwen-turbo",
messages=messages,
result_format="message", # set result format as 'message'
stream=True, # enable stream output
incremental_output=True, # enable incremental output
)
for response in responses:
if response.status_code == HTTPStatus.OK:
print(response.output.choices[0]["message"]["content"], end="")
synthesizer.streaming_call(response.output.choices[0]["message"]["content"])
else:
print(
"Request id: %s, Status code: %s, error code: %s, error message: %s"
% (
response.request_id,
response.status_code,
response.code,
response.message,
)
)
synthesizer.streaming_complete()
print('requestId: ', synthesizer.get_last_request_id())
if __name__ == "__main__":
synthesizer_with_llm()4.参考链接
(点击CosyVoice的将LLM生成的文本实时转成语音并通过扬声器播放模块,点击Python运行的代码进行复制。)