文章目录
- [GPT Action](#GPT Action)
- [从零开始使用 GPT Actions](#从零开始使用 GPT Actions)
-
- [Weather.gov 示例](#Weather.gov 示例)
- [步骤 1:编写和测试 Open API 架构(使用 Actions GPT)](#步骤 1:编写和测试 Open API 架构(使用 Actions GPT))
- [步骤 2: 确定认证需求](#步骤 2: 确定认证需求)
- [步骤 3:创建 GPT Action 并进行测试](#步骤 3:创建 GPT Action 并进行测试)
-
- 深入探讨:编写说明的指导
- [测试 GPT 操作](#测试 GPT 操作)
- [步骤 4:在第三方应用中设置回调 URL](#步骤 4:在第三方应用中设置回调 URL)
- 第5步:评估自定义GPT
- 常见调试步骤
- [GPT Actions 库](#GPT Actions 库)
- [GPT Action 认证](#GPT Action 认证)
- [GPT Actions 生产笔记](#GPT Actions 生产笔记)
- [使用 GPT Actions 进行数据检索](#使用 GPT Actions 进行数据检索)
- [使用 GPT Actions 发送和返回文件](#使用 GPT Actions 发送和返回文件)
GPT Action
通过 GPT Action 和 API 集成自定义 ChatGPT。
https://platform.openai.com/docs/actions
GPT Action 存储在 自定义 GPT 中,这使得用户可以通过提供指令、附加文档作为知识库以及连接到第三方服务来自定义 ChatGPT 以满足特定用例。
GPT Action 使 ChatGPT 用户能够通过使用自然语言与 ChatGPT 之外的外部应用程序通过 RESTful API 调用来交互。它们将自然语言文本转换为 API 调用所需的 json 架构。GPT Action 通常用于在 ChatGPT 中进行 数据检索(例如查询数据仓库)或在另一个应用程序中执行操作(例如提交 JIRA 工作项)。
GPT Action 如何工作
在核心上,GPT Action 利用 函数调用 来执行 API 调用。
类似于 ChatGPT 的数据分析能力(它会生成 Python 代码然后执行),它们利用函数调用来实现以下功能:(1) 决定哪个 API 调用与用户的提问相关,(2) 生成 API 调用所需的 json 输入。然后,GPT Action 使用该 json 输入执行 API 调用。
开发者甚至可以指定动作的认证机制,并且自定义 GPT 将使用第三方应用的认证来执行 API 调用。GPT Action 将 API 调用的复杂性对最终用户进行隐藏:他们只需用自然语言提出问题,ChatGPT 就会以自然语言提供输出。
GPT Actions 的力量
API 允许 互操作性,使您的组织能够访问其他应用程序。然而,让用户从第三方 API 中获取正确信息可能需要开发人员承担重大开销。
GPT Actions 提供了一种可行的替代方案:开发人员现在可以简单地描述 API 调用的模式,配置身份验证,并将一些指令添加到 GPT 中,然后 ChatGPT 提供了用户自然语言问题和 API 层之间的桥梁。
简化示例
入门指南 通过使用来自 weather.gov 的两个 API 调用来演示一个示例,生成预报:
/points/{latitude},{longitude}输入经纬度坐标,输出预报办公室 (wfo) 和 x-y 坐标/gridpoints/{office}/{gridX},{gridY}/forecast输入 wfo,x,y 坐标,输出预报
一旦开发者将填充这两个 API 调用的 JSON 架构编码到 GPT Action 中,用户就可以简单地询问"这个周末去华盛顿 DC 我应该带些什么?"然后 GPT Action 将确定该位置的经纬度,按顺序执行这两个 API 调用,并根据收到的周末预报响应提供打包清单。
在这个示例中,GPT Actions 将向 api.weather.gov 提供两个 API 输入:
/points API 调用:
json
{
"latitude": 38.9072,
"longitude": -77.0369,
}/forecast API 调用:
json
{
"wfo": "LWX",
"x": 97,
"y": 71,
}开始构建
查看入门指南深入了解此天气示例,以及我们的动作库以获取预构建的常见第三方应用GPT动作示例。
更多信息
- Familiarize yourself with our GPT policies(https://openai.com/policies/usage-policies#:\~:text=or educational purposes.-,Building with ChatGPT,-Shared GPTs allow)
- Explore the differences between GPTs and Assistants
- Check out the GPT data privacy FAQ's
- Find answers to common GPT questions
从零开始使用 GPT Actions
从头开始设置和测试 GPT Actions。
https://platform.openai.com/docs/actions/getting-started
Weather.gov 示例
NSW(国家气象服务)维护了一个 公共API,用户可以通过查询该API来获取任何经纬度点的天气预报。要获取预报,有2个步骤:
- 用户向api.weather.gov/points API提供经纬度,并接收回WFO(天气预报办公室)、grid-X和grid-Y坐标
- 这3个元素输入到api.weather.gov/forecast API中,以获取该坐标的预报
为了进行这项练习,让我们构建一个自定义GPT,其中用户输入一个城市、地标或经纬度坐标,自定义GPT回答关于该地点天气预报的问题。
步骤 1:编写和测试 Open API 架构(使用 Actions GPT)
一个 GPT Action 需要一个 Open API 架构 来描述 API 调用的参数,这是一个描述 API 的标准。
OpenAI 发布了一个公共 Actions GPT 来帮助开发者编写这个架构。例如,前往 Actions GPT 并询问:
"前往 https://www.weather.gov/documentation/services-web-api 并阅读该页面的文档。为 /points/{latitude},{longitude} 和 /gridpoints/{office}/{gridX},{gridY}/forecast API 调用构建一个 Open API 架构"
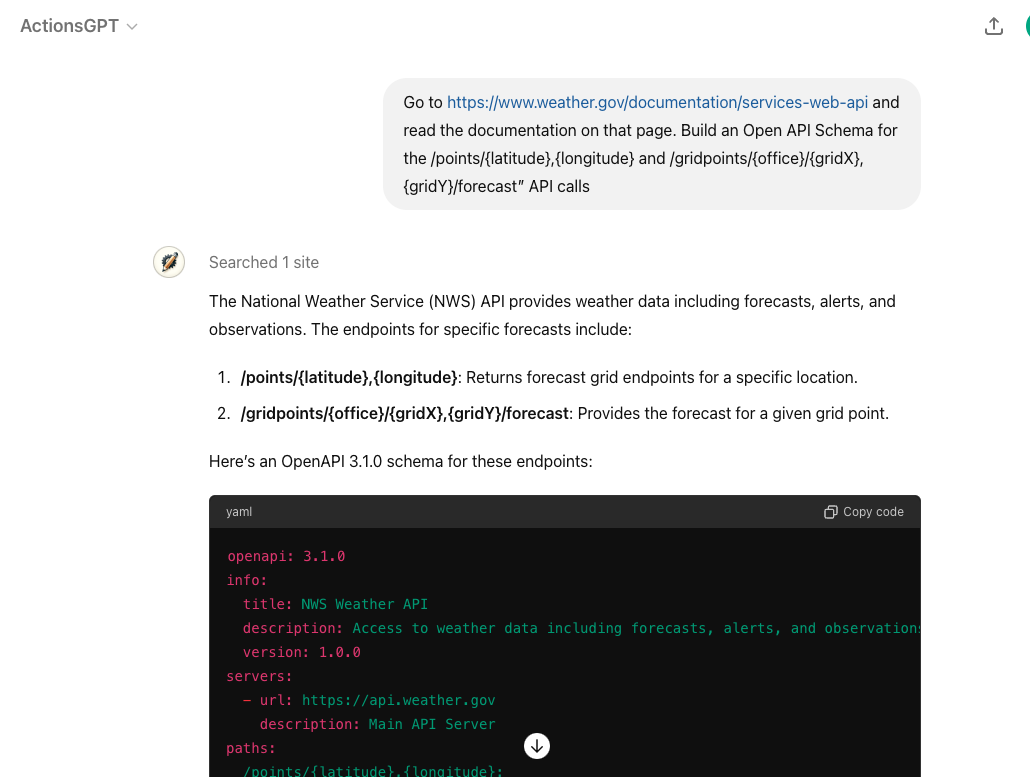
深度挖掘:查看完整的开放API模式
ChatGPT 使用顶部 info(特别是描述)来决定此操作是否与用户查询相关。
yaml
info:
title: NWS Weather API
description: Access to weather data including forecasts, alerts, and observations.
version: 1.0.0然后下面的 参数 进一步定义了架构的各个部分。例如,我们正在通知 ChatGPT,office 参数指的是天气预报办公室(WFO)。
yaml
/gridpoints/{office}/{gridX},{gridY}/forecast:
get:
operationId: getGridpointForecast
summary: Get forecast for a given grid point
parameters:
- name: office
in: path
required: true
schema:
type: string
description: Weather Forecast Office ID关键字: 在此 Open API 架构中,请特别注意您使用的 模式名称 和 描述。ChatGPT 使用这些名称和描述来理解 (a) 应该调用哪个 API 动作以及 (b) 应该使用哪个参数。如果某个字段仅限于特定的值,您还可以提供一个带有描述性类别名称的 "枚举"。
虽然您可以直接在 GPT Action 中尝试 Open API 架构,但在 ChatGPT 中直接调试可能是一个挑战。我们建议使用第三方服务,如 Postman,来测试您的 API 调用是否正常工作。Postman 注册免费,错误处理详细,认证选项全面。它甚至提供了直接导入 Open API 架构的选项(见下文)。

步骤 2: 确定认证需求
此 Weather 第三方服务不需要认证,因此您可以为这个自定义 GPT 跳过此步骤。对于需要认证的其他 GPT 操作,有 2 个选项:API 密钥或 OAuth。
询问 ChatGPT 可以帮助您开始大多数常见应用。例如,如果我需要使用 OAuth 来认证 Google Cloud,我可以提供一张截图并询问详细信息:"我正在通过 OAuth 建立与 Google Cloud 的连接。请提供如何填写这些方框的说明。"
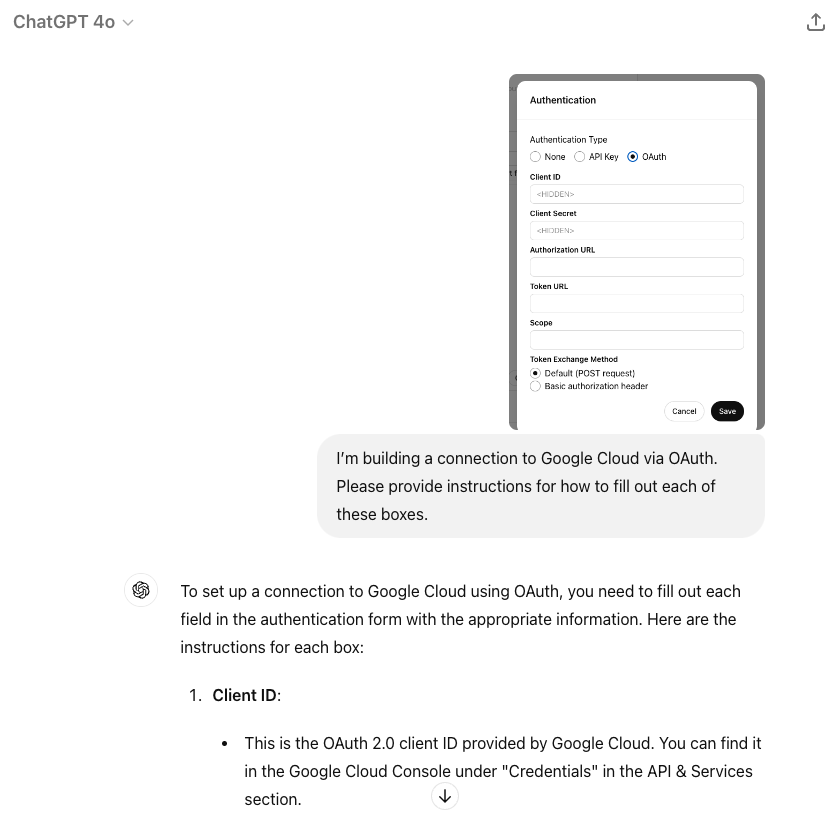
通常,ChatGPT会为所有5个元素提供正确的方向。一旦你准备好了这些基础知识,尝试在Postman或类似的服务中测试和调试认证。如果你遇到错误,向ChatGPT提供错误信息,它通常可以帮助你从这里进行调试。
步骤 3:创建 GPT Action 并进行测试
现在是创建您自定义 GPT 的时候了。如果您以前从未创建过自定义 GPT,请从我们的 创建 GPT 指南 开始。
- 提供一个名称、描述和图像来描述您的自定义 GPT
- 前往动作部分,粘贴您的 Open API 架构。在编写说明时,注意动作名称和 json 参数。
- 添加您的身份验证设置
- 返回主页并添加说明
深入探讨:编写说明的指导
编写成功指令的方法有很多种:最重要的是指令能够让模型反映用户的偏好。
通常有三个部分:
- Context,向模型解释 GPT 操作正在做什么
- Instructions,说明步骤顺序 - 您可以在此处引用操作名称以及 API 调用需要注意的任何参数
- Additional Notes,如果有任何需要注意的地方
以下是 Weather GPT 指令的示例。请注意指令如何引用 Open API 架构中的 API 操作名称和 json 参数。
text
**Context**: A user needs information related to a weather forecast of a specific location.
**Instructions**:
1. The user will provide a lat-long point or a general location or landmark (e.g. New York City, the White House). If the user does not provide one, ask for the relevant location
2. If the user provides a general location or landmark, convert that into a lat-long coordinate. If required, browse the web to look up the lat-long point.
3. Run the "getPointData" API action and retrieve back the gridId, gridX, and gridY parameters.
4. Apply those variables as the office, gridX, and gridY variables in the "getGridpointForecast" API action to retrieve back a forecast
5. Use that forecast to answer the user's question
**Additional Notes**:
- Assume the user uses US weather units (e.g. Fahrenheit) unless otherwise specified
- If the user says "Let's get started" or "What do I do?", explain the purpose of this Custom GPT测试 GPT 操作
每个操作旁边都会看到一个 测试 按钮。点击每个操作对应的按钮。在测试中,您可以查看每个 API 调用的详细输入和输出。
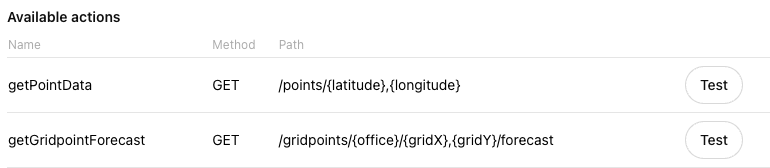
如果您的 API 调用在 Postman 等第三方工具中工作,但在 ChatGPT 中不工作,可能有几个可能的原因:
- ChatGPT 中的参数错误或缺失
- ChatGPT 中的身份验证问题
- 您的指示不完整或不清晰
- Open API 架构中的描述不清晰
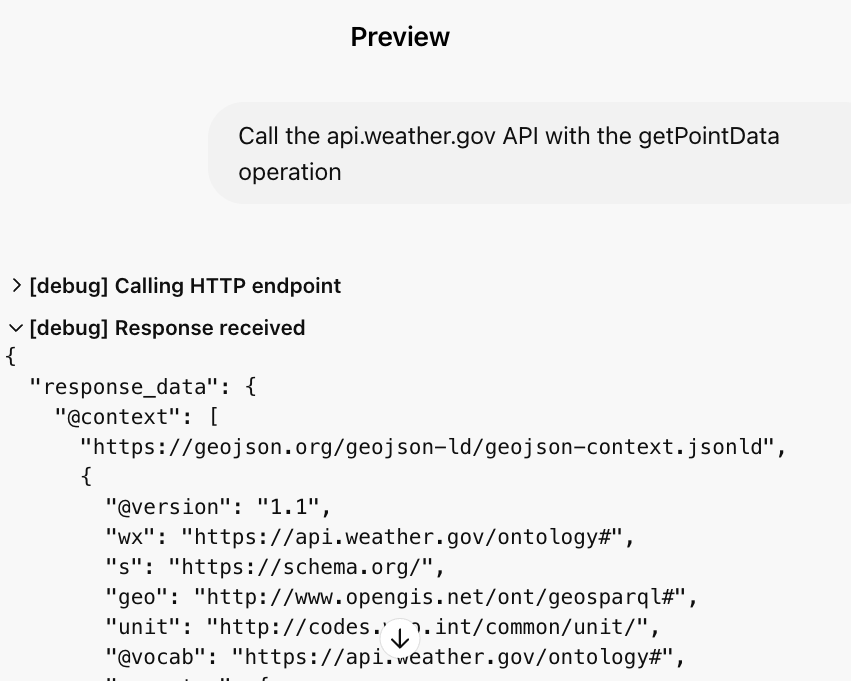
步骤 4:在第三方应用中设置回调 URL
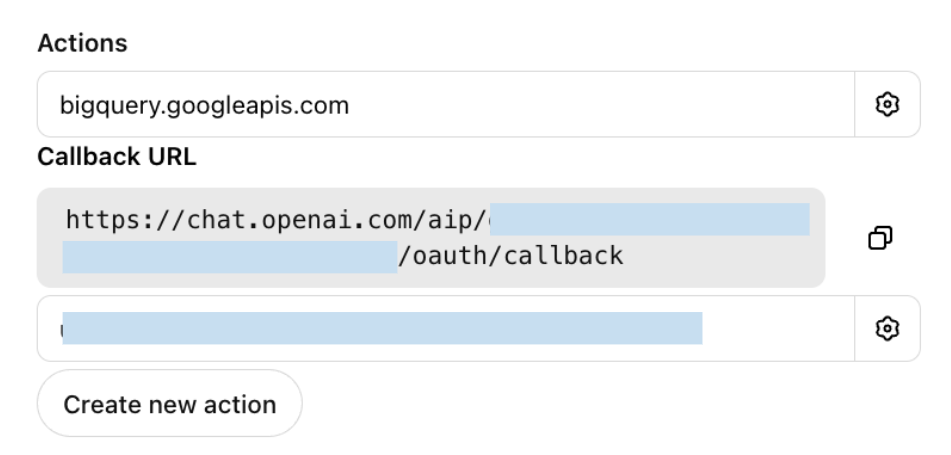
如果你的 GPT Action 使用 OAuth 验证,你需要在你的第三方应用程序中设置回调 URL。一旦你使用 OAuth 设置了 GPT Action ,ChatGPT 会为你提供一个回调 URL(每次你更新 OAuth 参数之一时,它都会更新)。复制该回调 URL 并将其添加到你的应用程序的相应位置。
第5步:评估自定义GPT
尽管你在上面的步骤中测试了GPT操作,但你仍然需要评估指令和GPT操作是否以用户期望的方式运行。尽量想出至少5-10个代表性的问题(越多越好),作为要询问你的自定义GPT的**"评估集"**问题。
关键点: 测试自定义GPT是否按照你的期望处理每个问题。
一个示例问题:"这个周末去白宫旅行我应该带些什么?"测试自定义GPT的能力: (1) 将地标转换为经纬度,(2) 运行两个GPT操作,以及 (3) 回答用户的问题。


常见调试步骤
挑战: GPT 操作调用了错误的 API 调用(或根本没有调用)
解决方案: 确保操作的描述清晰 - 并参考自定义 GPT 说明中的操作名称
挑战: GPT 操作调用了正确的 API 调用,但未正确使用参数
解决方案: 添加或修改 GPT 操作中参数的描述
挑战: 自定义 GPT 不起作用,但我没有收到明确的错误
解决方案: 确保测试操作 - 测试窗口中有更强大的日志。如果仍然不清楚,请使用 Postman 或其他第三方服务进行更好的诊断。
挑战: 自定义 GPT 给出身份验证错误
解决方案: 确保您的回调 URL 设置正确。尝试在 Postman 或其他第三方服务中测试完全相同的身份验证设置
挑战: 自定义 GPT 无法处理更困难/模糊的问题
解决方案: 尝试在自定义 GPT 中快速设计您的指令。请参阅我们的 快速工程指南 中的示例
这是构建自定义 GPT 的指南。如果您有其他问题,祝您构建和利用 OpenAI 开发者论坛 顺利。
GPT Actions 库
构建和集成 GPT Actions 以适用于常见应用。
https://platform.openai.com/docs/actions/actions-library
目的
虽然与从头开始使用这些API构建整个应用程序相比,GPT动作对API开发人员来说应该要简单得多,但仍然需要一些设置才能使GPT动作启动运行。GPT动作库旨在为构建常见应用程序上的GPT动作提供指导。
入门指南
如果您以前从未构建过动作,请首先阅读入门指南,以更好地了解动作的工作原理。
通常,本指南面向熟悉并舒适调用API调用的人。对于调试帮助,尝试向ChatGPT解释您的问题,并包括截图。
如何访问
The OpenAI Cookbook 拥有一个 目录 ,包含第三方应用程序和中间件应用程序。
第三方动作菜谱
GPT Action 可以直接与 HTTP 服务集成。利用 SaaS API 的 GPT Action 将直接进行身份验证并直接从 SaaS 提供商请求资源,例如 Google Drive 或 Snowflake。
中间件操作食谱
GPT 操作可以从拥有中间件中受益。它允许预处理、数据格式化、数据过滤,甚至连接到未通过 HTTP 暴露的端点(例如:数据库)。有多个中间件食谱可用,描述了示例实现路径,例如 Azure,GCP 和 AWS。
给我们反馈
您希望我们优先考虑哪些集成?我们的集成中存在错误吗?在cookbook页面的github上提交一个PR或issue,我们会查看的。
为我们的库贡献力量
如果您有兴趣为我们的库贡献力量,请遵循以下指南,然后提交一个 GitHub 上的 PR 以供我们审查。一般来说,遵循类似 这个示例 GPT Action 的模板。
指南 - 包含以下部分:
- 应用信息 - 描述第三方应用,并包含应用网站和 API 文档的链接
- 自定义 GPT 指令 - 包含要包含在自定义 GPT 中的确切指令
- OpenAPI 模式 - 包含要包含在 GPT Action 中的确切 OpenAPI 模式
- 身份验证指令 - 对于 OAuth,包含确切的一组项目(授权 URL、token URL、作用域等);还包括如何在应用程序中编写回调 URL 的说明(以及任何其他步骤)
- 常见问题解答和故障排除 - 用户可能会遇到哪些常见问题?在这里写下它们,并给出解决方案
免责声明
此操作库旨在作为与 OpenAI 无法控制的第三方进行交互的指南。这些第三方可能会更改其 API 设置或配置,并且 OpenAI 无法保证这些操作将永久有效。请将它们视为起点。
本指南适用于开发人员和熟悉编写 API 调用的人员。非技术用户可能会发现这些步骤具有挑战性。
GPT Action 认证
了解 GPT Actions 的认证选项。
https://platform.openai.com/docs/actions/authentication
动作提供了不同的认证模式以适应各种用例。要指定动作的认证模式,请使用 GPT 编辑器并选择 "无"、"API 密钥" 或 "OAuth"。
默认情况下,所有操作的认证方法设置为 "None",但您可以更改此设置,允许不同的操作有不同的认证方法。
无认证
我们支持无需认证的流程,适用于用户可以直接向您的API发送请求,而无需API密钥或使用OAuth进行登录的应用程序。
考虑使用无认证来处理初始用户交互,因为如果用户被迫登录应用程序,您可能会遇到用户流失。您可以通过启用一个单独的操作来创建一个"未登录"的体验,然后将用户引导到"已登录"的体验。
API密钥认证
就像用户可能已经在使用您的API一样,我们允许通过GPT编辑器UI进行API密钥认证。我们将密钥加密后存储在我们的数据库中,以保护您的API密钥安全。
如果您有一个执行比无认证流程稍微重要一些的操作的API,但又不需要单个用户登录,这种做法很有用。添加API密钥认证可以保护您的API,并为您提供更精细的访问控制,以及了解请求来源的可见性。
OAuth
操作允许每个用户进行 OAuth 登录。这是提供个性化体验并向用户提供最强大操作的最佳方式。带有操作的 OAuth 流程的简单示例如下所示:
- 首先,在 GPT 编辑器 UI 中选择"身份验证",然后选择"OAuth"。
- 系统将提示您输入 OAuth 客户端 ID、客户端密钥、授权 URL、令牌 URL 和范围。
- 客户端 ID 和密钥可以是简单的文本字符串,但应遵循 OAuth 最佳实践。
- 我们存储客户端密钥的加密版本,而客户端 ID 可供最终用户使用。
- OAuth 请求将包含以下信息:
python
request={
'grant_type': 'authorization_code',
'client_id': 'YOUR_CLIENT_ID',
'client_secret': 'YOUR_CLIENT_SECRET',
'code': 'abc123',
'redirect_uri': 'https://chat.openai.com/aip/g-some_gpt_id/oauth/callback'
}注意:https://chatgpt.com/aip/g-some_gpt_id/oauth/callback 也有效。`
- 为了让某人使用带有 OAuth 的操作,他们需要发送一条调用该操作的消息,然后用户将在 ChatGPT UI 中看到一个
登录 [域]按钮。 authorization_url端点应返回如下所示的响应:{ "access_token": "example_token", "token_type": "bearer", "refresh_token": "example_token", "expires_in": 59 }- 在用户登录过程中,ChatGPT 使用指定的
authorization_content_type向您的authorization_url发出请求,我们期望返回一个访问令牌和一个可选的 刷新令牌,我们使用它定期获取新的访问令牌。 - 每次用户向操作发出请求时,用户的令牌都将在授权标头中传递:(
"Authorization": "[Bearer/Basic] [用户令牌]")。 - 出于安全原因,我们要求 OAuth 应用程序使用 state 参数。
自定义 GPT(重定向 URL)上登录失败问题?
- 确保在您的 OAuth 应用程序中启用此重定向 URL:
- #1 重定向 URL:
https://chat.openai.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback(某些客户端可能使用不同的域) - #2 重定向 URL:
https://chatgpt.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback(保存后,在 ChatGPT UI 的 URL 栏中获取您的 GPT ID)如果您有多个 GPT,则需要为每个 GPT 启用一个或一个通配符,具体取决于风险承受能力。 - 调试说明:您的 Auth 提供程序通常会记录失败(例如"redirect_uri 未为客户端注册"),这也有助于调试登录问题。
GPT Actions 生产笔记
在生产环境中部署 GPT Actions 的最佳实践。
https://platform.openai.com/docs/actions/production
速率限制
考虑在您公开的API端点上实施速率限制。ChatGPT会尊重429响应代码,并在收到一定数量的429或500响应代码后,在短时间内动态减少向您的操作发送请求。
超时
在执行体验中的API调用时,如果超过以下阈值,则会发生超时:
- API调用往返时间为45秒
使用 TLS 和 HTTPS
所有访问您的操作的流量都必须在端口 443 上使用 TLS 1.2 或更高版本,并带有有效的公共证书。
IP 输出范围
ChatGPT 将从 CIDR 块列表中的一个 IP 地址调用您的操作,该列表位于 ChatGPT-actions.json 中。
您可能希望明确允许这些 IP 地址。此列表会定期自动更新。
多种身份验证方案
当定义一个操作时,您可以混合使用单一的身份验证类型(OAuth 或 API 密钥)以及不需要身份验证的端点。
您可以在我们的 操作身份验证页面 上了解更多有关操作身份验证的信息。
开放 API 规范限制
在您的 OpenAPI 规范中请注意以下限制,这些限制可能会发生变化:
- 每个 API 端点描述/摘要字段的最大字符数为 300
- 每个 API 参数描述字段的最大字符数为 700
其他限制
在构建时需要注意以下一些限制:
- 不支持自定义头部
- 除了谷歌、微软和 Adobe OAuth 域名之外,所有在 OAuth 流中使用的域名必须与用于主端点的域名相同
- 请求和响应的有效载荷必须少于 100,000 个字符
- 请求在 45 秒后超时
- 请求和响应只能包含文本(不支持图片或视频)
后果性标志
在 OpenAPI 规范中,您现在可以将某些端点设置为 "后果性",如下所示:
yaml
paths:
/todo:
get:
operationId: getTODOs
description: Fetches items in a TODO list from the API.
security: []
post:
operationId: updateTODOs
description: Mutates the TODO list.
x-openai-isConsequential: true一个后果行为的良好例子是为用户预订酒店房间并代表其支付费用。
- 如果
x-openai-isConsequential字段为true,ChatGPT 将操作视为"必须始终在运行前提示用户确认",并且不显示"始终允许"按钮(这两个都是 GPTs 设计的旨在给构建者和用户更多控制动作的功能)。 - 如果
x-openai-isConsequential字段为false,ChatGPT 显示"始终允许"按钮。 - 如果该字段不存在,ChatGPT 默认将所有 GET 操作设置为
false,将所有其他操作设置为true
最佳实践:提供示例
以下是编写您的 GPT 指令和描述时以及在设计 API 响应时需要遵循的一些最佳实践:
1、您的描述不应该鼓励 GPT 在用户没有请求您的动作特定服务类别时使用该动作。
坏例子:
每当用户提到任何类型的任务时,询问他们是否想使用 TODO 动作将某事添加到他们的待办事项列表中。
好例子:
TODO 列表可以添加、删除和查看用户的 TODO。
2、您的描述不应该指定 GPT 使用动作的具体触发条件。ChatGPT 被设计成在适当的时候自动使用您的动作。
坏例子:
当用户提到一项任务时,回复:"你想让我把这项任务添加到你的 TODO 列表中吗?说 'yes' 继续。"
好例子:
无需提供指令
3、来自 API 的动作响应应返回原始数据而不是自然语言响应,除非这是必要的。GPT 将使用返回的数据提供自己的自然语言响应。
坏例子:
我找到了你的待办事项列表!你有 2 个待办事项:买杂货和遛狗。如果你想,我可以添加更多待办事项!
好例子:
{ "todos": "get groceries", "walk the dog" }
GPT Action 数据的使用方式
GPT Actions 将 ChatGPT 连接到外部应用。如果用户与 GPT 的自定义操作进行交互,ChatGPT 可能会将其对话的部分内容发送到该操作的端点。
如果您有疑问或遇到其他限制,您可以加入 OpenAI 开发者论坛 上的讨论。
使用 GPT Actions 进行数据检索
使用 GPT Actions 通过 API 和数据库检索数据。
https://platform.openai.com/docs/actions/data-retrieval
GPT 中的动作中最常见的任务之一是数据检索。一个动作可能:
- 访问 API 以根据关键词搜索检索数据
- 访问关系型数据库以根据结构化查询检索记录
- 访问向量数据库以根据语义搜索检索文本块
本指南将探讨特定于各种检索集成类型的考虑因素。
使用API进行数据检索
许多组织依赖第三方软件来存储重要数据。例如,Salesforce用于客户数据,Zendesk用于支持数据,Confluence用于内部流程数据,以及Google Drive用于商业文档。这些提供商通常会提供REST API,允许外部系统搜索和检索信息。
在构建一个用于与提供商的REST API集成的操作时,首先开始审查现有文档。您需要确认以下几点:
1、检索方法
- 搜索 - 每个提供商将支持不同的搜索语义,但通常您需要一个方法,该方法接受一个关键字或查询字符串并返回匹配的文档列表。参见Google Drive的
file.list方法的示例。 - 获取 - 一旦找到匹配的文档,您需要一种方法来检索它们。参见Google Drive的
file.get方法的示例。
2、认证方案
- 例如,Google Drive使用OAuth来验证用户身份并确保只有他们的可用文件可供检索。
3、OpenAPI规范
-
一些提供商将提供OpenAPI规范文档,您可以直接将其导入到操作中。参见 Zendesk。
- 您可能想删除对GPT *无法访问的方法的引用,这限制了GPT可以执行的操作。
-
对于不提供OpenAPI规范文档的提供商,您可以使用ActionsGPT(由OpenAI开发的GPT)创建自己的规范。
您的目标是让GPT使用操作来搜索和检索包含与用户提示相关的上下文的文档。您的GPT遵循您的指示,使用提供的搜索和获取方法来实现这一目标。
使用关系型数据库进行数据检索
组织使用关系型数据库来存储与业务相关的各种记录。这些记录可以包含有助于改进GPT(大型语言模型)响应的有用上下文。例如,假设你正在构建一个GPT,以帮助用户了解保险索赔的状态。如果GPT可以根据索赔号在关系型数据库中查找索赔,那么GPT对用户将更加有用。
在构建与关系型数据库集成的操作时,需要注意以下几点:
1、REST API的可用性
- 许多关系型数据库本身不提供用于处理查询的REST API。在这种情况下,你可能需要构建或购买中间件,该中间件可以位于你的GPT和数据库之间。
- 这个中间件应该执行以下操作:
- 接受一个正式的查询字符串
- 将查询字符串传递给数据库
- 向请求者响应返回的记录
2、从公共互联网的访问性
- 与旨在从公共互联网访问的API不同,关系型数据库传统上是为在组织的应用程序基础设施内使用而设计的。由于GPT托管在OpenAI的基础设施上,你需要确保你公开的任何API都可以在你的防火墙之外访问。
3、复杂的查询字符串
- 关系型数据库使用像SQL这样的正式查询语法来检索相关记录。这意味着你需要向GPT提供额外的说明,指示哪种查询语法被支持。好消息是,GPT通常非常擅长根据用户输入生成正式查询。
4、数据库权限
- 尽管数据库支持用户级权限,但你的最终用户很可能没有权限直接访问数据库。如果你选择使用服务帐户来提供访问权限,请考虑仅授予服务帐户只读权限。这样可以避免意外覆盖或删除现有数据。
你的目标是让GPT编写与用户提示相关的正式查询,通过操作提交查询,然后使用返回的记录来增强响应。
使用向量数据库进行数据检索
如果您想为您的 GPT 配置最相关的搜索结果,您可能需要考虑将您的 GPT 与支持上述语义搜索的向量数据库集成。市场上有很多托管和自托管解决方案可供选择,在此处查看部分列表。
在构建一个用于与向量数据库集成的操作时,有一些事情需要考虑:
1、REST API 的可用性
- 许多关系型数据库没有原生地公开 REST API 以处理查询。在这种情况下,您可能需要构建或购买中间件,该中间件可以位于您的 GPT 和数据库之间(关于中间件的更多信息见下文)。
2、从公共互联网的访问性
- 与设计为从公共互联网访问的 API 不同,关系型数据库传统上是为在组织的应用程序基础设施内使用而设计的。由于 GPT 在 OpenAI 的基础设施上托管,您需要确保您公开的任何 API 都可以绕过您的防火墙进行访问。
3、查询嵌入
- 如上所述,向量数据库通常接受向量嵌入(而不是纯文本)作为查询输入。这意味着您需要使用嵌入 API 将查询输入转换为向量嵌入,然后才能将其提交给向量数据库。这种转换最好在 REST API 网关中处理,以便 GPT 可以提交纯文本查询字符串。
4、数据库权限
- 由于向量数据库存储的是文本片段而不是完整文档,因此维护可能存在于原始源文档上的用户权限可能很困难。请记住,任何可以访问您的 GPT 的用户都将有权访问数据库中的所有文本片段,并据此进行规划。
向量数据库的中间件
如上所述,向量数据库的中间件通常需要完成以下两项任务:
- 通过 REST API 提供对向量数据库的访问
- 将纯文本查询字符串转换为向量嵌入

目标是让你的 GPT 向向量数据库提交一个相关的查询以触发语义搜索,然后使用返回的文本块来增强响应。
使用 GPT Actions 发送和返回文件
https://platform.openai.com/docs/actions/sending-files
发送文件
POST 请求可以包含多达十个文件(包括 DALL-E 生成的图像)来自对话。它们将被发送为有效的 URL,有效期五分钟。
为了使文件成为您的 POST 请求的一部分,参数必须命名为 openaiFileIdRefs,并且描述应向模型解释 API 期望的文件类型和数量。
openaiFileIdRefs 参数将包含一个 JSON 对象数组。每个对象包含:
name文件名称。当由 DALL-E 创建时,这将是一个自动生成的名称。id文件的稳定标识符。mime_type文件的 MIME 类型。对于用户上传的文件,这是基于文件扩展名。download_link获取文件的 URL,有效期五分钟。
以下是一个包含两个元素的 openaiFileIdRefs 数组的示例:
json
[
{
"name": "dalle-Lh2tg7WuosbyR9hk",
"id": "file-XFlOqJYTPBPwMZE3IopCBv1Z",
"mime_type": "image/webp",
"download_link": "https://files.oaiusercontent.com/file-XFlOqJYTPBPwMZE3IopCBv1Z?se=2024-03-11T20%3A29%3A52Z&sp=r&sv=2021-08-06&sr=b&rscc=max-age%3D31536000%2C%20immutable&rscd=attachment%3B%20filename%3Da580bae6-ea30-478e-a3e2-1f6c06c3e02f.webp&sig=ZPWol5eXACxU1O9azLwRNgKVidCe%2BwgMOc/TdrPGYII%3D"
},
{
"name": "2023 Benefits Booklet.pdf",
"id": "file-s5nX7o4junn2ig0J84r8Q0Ew",
"mime_type": "application/pdf",
"download_link": "https://files.oaiusercontent.com/file-s5nX7o4junn2ig0J84r8Q0Ew?se=2024-03-11T20%3A29%3A52Z&sp=r&sv=2021-08-06&sr=b&rscc=max-age%3D299%2C%20immutable&rscd=attachment%3B%20filename%3D2023%2520Benefits%2520Booklet.pdf&sig=Ivhviy%2BrgoyUjxZ%2BingpwtUwsA4%2BWaRfXy8ru9AfcII%3D"
}
]动作可以包括用户上传的文件、DALL-E 生成的图像以及代码解释器创建的文件。
OpenAPI 示例
yaml
/createWidget:
post:
operationId: createWidget
summary: Creates a widget based on an image.
description: Uploads a file reference using its file id. This file should be an image created by DALL·E or uploaded by the user. JPG, WEBP, and PNG are supported for widget creation.
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
openaiFileIdRefs:
type: array
items:
type: string虽然此架构显示openaiFileIdRefs是一个类型为string的数组,但在运行时,它将被填充为之前显示的JSON对象数组。
返回文件
请求可能返回最多10个文件。每个文件大小最多可达10 MB,但不能是图片或视频。
这些文件将与用户上传的文件类似成为对话的一部分,这意味着它们可以被提供给代码解释器、文件搜索,并在后续操作调用中发送。在Web应用程序中,用户将看到已返回的文件,并可以下载它们。
要返回文件,响应体必须包含一个 openaiFileResponse 参数。此参数必须始终是一个数组,并且必须以两种方式之一进行填充。
行内选项
数组中的每个元素都是一个包含以下内容的 JSON 对象:
name文件名称。这将对用户可见。mime_type文件的 MIME 类型。这用于确定资格以及哪些功能可以访问该文件。content文件的 base64 编码内容。
以下是一个包含两个元素的 openaiFileResponse 数组的示例:
json
[
{
"name": "example_document.pdf",
"mime_type": "application/pdf",
"content": "JVBERi0xLjQKJcfsj6IKNSAwIG9iago8PC9MZW5ndGggNiAwIFIvRmlsdGVyIC9GbGF0ZURlY29kZT4+CnN0cmVhbQpHhD93PQplbmRzdHJlYW0KZW5kb2JqCg=="
},
{
"name": "sample_spreadsheet.csv",
"mime_type": "text/csv",
"content": "iVBORw0KGgoAAAANSUhEUgAAAAUAAAAFCAYAAACNbyblAAAAHElEQVQI12P4//8/w38GIAXDIBKE0DHxgljNBAAO9TXL0Y4OHwAAAABJRU5ErkJggg=="
}
]OpenAPI 示例
yaml
/papers:
get:
operationId: findPapers
summary: Retrieve PDFs of relevant academic papers.
description: Provided an academic topic, up to five relevant papers will be returned as PDFs.
parameters:
- in: query
name: topic
required: true
schema:
type: string
description: The topic the papers should be about.
responses:
'200':
description: Zero to five academic paper PDFs
content:
application/json:
schema:
type: object
properties:
openaiFileResponse:
type: array
items:
type: object
properties:
name:
type: string
description: The name of the file.
mime_type:
type: string
description: The MIME type of the file.
content:
type: string
format: byte
description: The content of the file in base64 encoding.URL 选项
数组中的每个元素都是一个指向要下载文件的 URL。Content-Disposition 和 Content-Type 标头必须设置,以便可以确定文件名和 MIME 类型。文件名将对用户可见。文件的 MIME 类型决定了文件的资格以及哪些功能可以访问该文件。
获取每个文件都有一个 10 秒的超时时间。
以下是一个包含两个元素的 openaiFileResponse 数组的示例:
json
[
"https://example.com/f/dca89f18-16d4-4a65-8ea2-ededced01646",
"https://example.com/f/01fad6b0-635b-4803-a583-0f678b2e6153"
]以下为每个URL所需的标题示例:
yaml
Content-Type: application/pdf
Content-Disposition: attachment; filename="example_document.pdf"OpenAPI 示例
yaml
get:
operationId: findPapers
summary: Retrieve PDFs of relevant academic papers.
description: Provided an academic topic, up to five relevant papers will be returned as PDFs.
parameters:
- in: query
name: topic
required: true
schema:
type: string
description: The topic the papers should be about.
responses:
'200':
description: Zero to five academic paper PDFs
content:
application/json:
schema:
type: object
properties:
openaiFileResponse:
type: array
items:
type: string
format: uri
description: URLs to fetch the files.2025-03-29(六)