配置运行任务的历史服务器
1.配置mapred-site.xml
在hadoop的安装目录下,打开mapred-site.xml,并在该文件里面增加如下两条配置。
eg我的是在hadoop199上

<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop100:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop100:19888</value>
</property>添加后该文件是这样的:

2.同步配置
将此文件配置同步到其他节点中命令为:
root@hadoop100 hadoop xsync HADOOP_HOME/etc/hadoop/mapred-site.xml
3.启动历史服务器
请注意:你在配置的时候指定哪个节点是历史服务器,就在哪里启动,请不要搞错了。
对应的命令是: mapred --daemon start historyserver
4.检查历史服务器是否启动
通过jps命令来查看历史服务器是否已经成功启动了。
root@hadoop100 hadoop$ jps
出现下图这样即代表成功启动

5.查看JobHistory
方式1:直接去看所有的历史记录 ++++http://hadoop100:19888/jobhistory++++
方式2:重新启动yarn服务。再从具体的history链接进行跳转。
开启日志聚集功能
1.配置yarn-site.xml
同样也是在hadoop100内找到yarn-site.xml文件,我们添加如下的配置。

在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>2.分发配置
和之前的配置一样,我们需要把这个更新之后的yarn-site.xml文件同步到其他的机器。这里还是使用脚本xsync。具体如下:
xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
3.重启ResourceManager和HistoryServer
进入到我们安装yarn的主机,通过命令来关闭掉yarn和historyServer,然后再重启。
root@hadoop103 hadoop-3.1.3$ sbin/stop-yarn.sh
root@hadoop103 hadoop-3.1.3$ mapred --daemon stop historyserver
启动ResourceManage和HistoryServer
mapred --daemon start historyserver
4.测试是否运行成功
命令如下:
root@hadoop100 hadoop-3.1.3$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
查看日志:
如果一切正常,我们打开历史服务器地址http://hadoop101:19888/jobhistory 可以看到历史任务列表,如下:
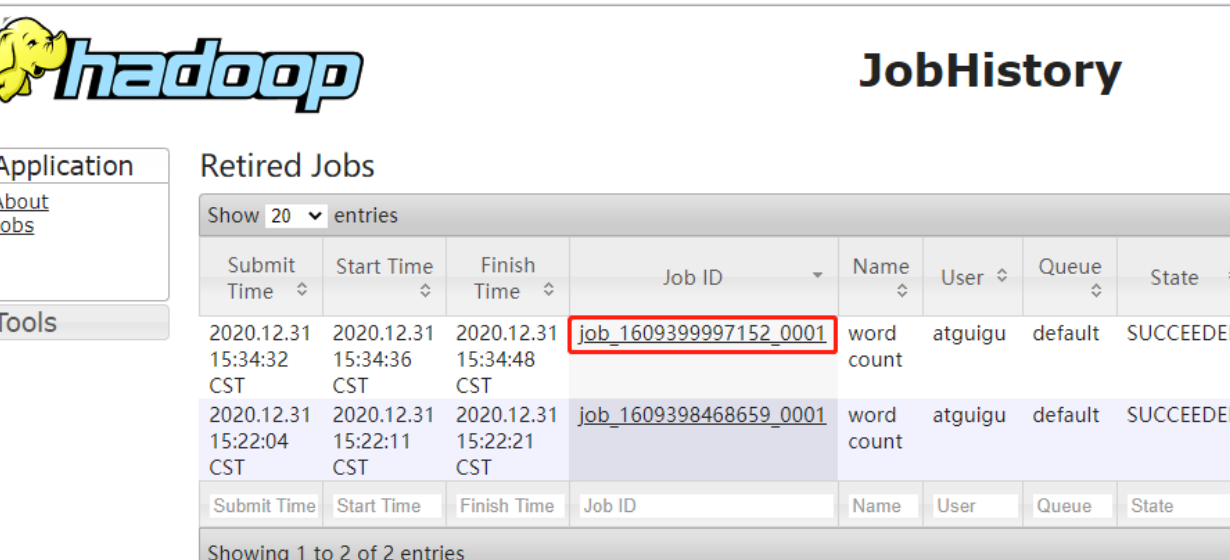
点击对应的JobID,就可以进一步查看任务运行日志
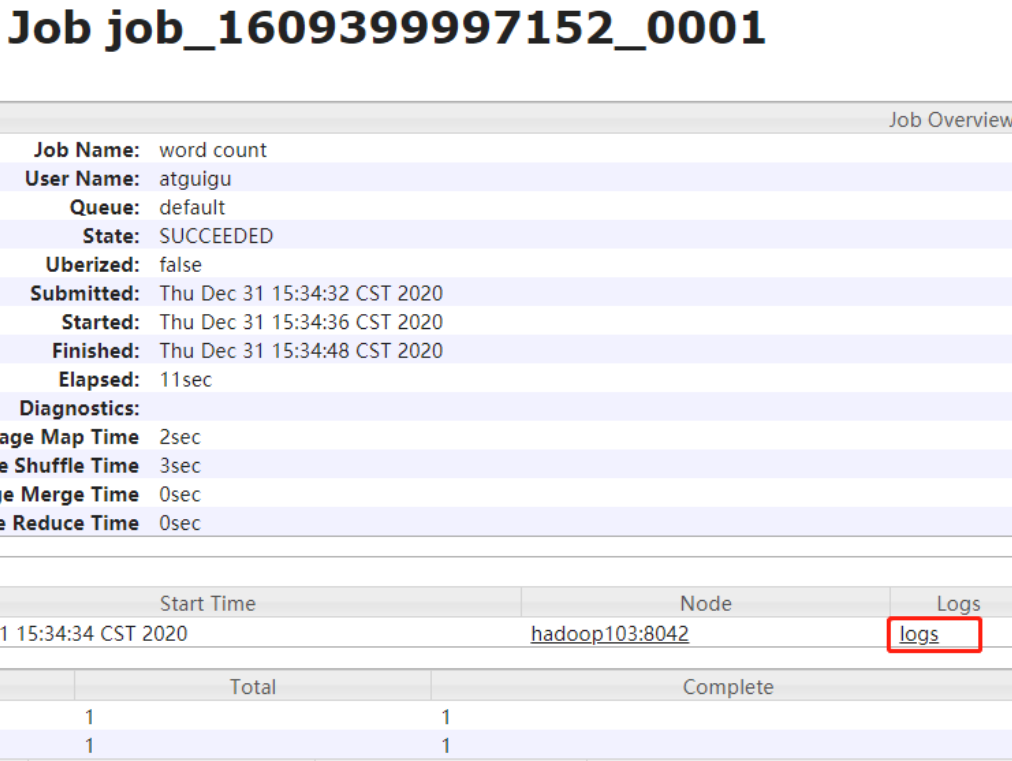
然后在点击logs,就可以查看运行日志的详情了。
