老规矩,今天是使用Gemini2.5pro来生成的模板
这篇论文研究了如何为处理多个相关任务的强化学习智能体自动设计学习课程(即任务顺序),以加速训练过程,并解决现有方法需要大量调参或缺乏理论依据的问题。为此,作者受到教育学中"最近发展区"(Zone of Proximal Development, ZPD)概念的启发,提出了一种名为 PROCURL 的新策略。该策略的核心思想是选择那些对智能体来说既不太难也不太容易、预期学习进展最大的任务。作者首先在简化的理论模型中推导了这一策略,然后设计了一个实用的版本,该版本通过评估智能体对不同任务的 Q 值(动作价值)的统计特性(如标准差)来估计学习潜力,从而选择下一个训练任务。这种方法易于集成到现有的深度强化学习框架中,且需要很少的调整。最后,通过在多种模拟环境中的实验,证明了 PROCURL 相比其他方法能更有效地提升智能体的学习速度
1. 问题陈述 (Problem Statement)
该论文讨论了在上下文多任务设置 (contextual multi-task settings) 中为强化学习 (RL) 智能体设计课程的问题。具体来说,它解决了以下问题:
- 现有的自动课程设计技术通常需要大量的领域特定的超参数调整。
- 许多当前方法缺乏强有力的理论基础来证明其设计选择的合理性。
- 目标是开发一种课程策略,通过优化选择任务来加速深度强化学习智能体的训练过程。
2. 挑战 (Challenges)
论文中考虑了在为强化学习智能体设计课程时面临的以下挑战:
- 平衡探索与利用 (Balancing Exploration and Exploitation): 决定何时专注于智能体已经擅长的任务,何时探索新的、可能更难的任务。
- 任务选择难度 (Task Selection Difficulty): 识别具有适当挑战性的任务------既不能太简单(导致进展缓慢),也不能太难(可能阻碍学习)。这与最近发展区 (Zone of Proximal Development, ZPD) 的概念有关。
- 实际实施 (Practical Implementation): 设计一种易于与现有深度强化学习框架集成、且需要最少超参数调整的策略。
- 理论依据 (Theoretical Justification): 开发一种基于可靠理论原则而非纯粹经验启发式的课程策略。
3. 解决方案如何应对挑战 (How the Solution Addresses the Challenges)
论文提出的解决方案 PROCURL (Proximal Curriculum for Reinforcement Learning) 通过以下方式应对这些挑战:
- 平衡探索与利用 / 任务选择: PROCURL 在数学上操作化了 ZPD 概念。它根据性能的预期提升 (expected improvement) 来选择任务,优先考虑那些智能体预期能学到最多的任务。这内在地平衡了在既不太简单也不太困难的任务上的学习。
- 实际实施: 提出了 PROCURL 的一个实用变体,该变体使用价值函数(或 Q 值)来估计预期提升,使其能够以最小的开销和调整与标准的深度强化学习算法兼容。
- 理论依据: PROCURL 是通过分析两个简化的理论设置(一个赌博机设置和一个线性上下文赌博机设置)中的学习进展推导出来的,为该策略提供了理论基础。
4. 解决方案陈述 (Solution Statement)
该论文提出了一种名为 PROCURL 的课程学习策略,具有以下关键方面:
- 其灵感来源于教育学概念最近发展区 (ZPD),即当任务既不太容易也不太难时,学习效果最大化。
- 它通过最大化智能体性能的预期提升来数学化任务选择过程,这一概念是在简化设置中理论推导出来的。
- 它提供了一个实用变体,该变体易于集成到深度强化学习框架中,使用价值函数来估计预期提升,并且需要最少的超参数调整。
5. 系统模型 (System Model)
论文在上下文多任务强化学习设置中对学习问题进行建模。系统表示如下:
- 一组任务(或上下文),表示为 C。
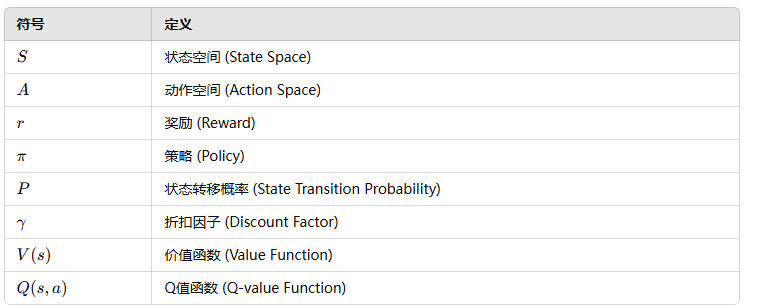
- 对于每个任务 c ∈ C,都有一个相关的马尔可夫决策过程 (MDP),M<sub>c</sub> = (S, A, P<sub>c</sub>, R<sub>c</sub>, γ),其中 S 是状态空间,A 是动作空间,P<sub>c</sub> 是转移概率函数,R<sub>c</sub> 是奖励函数,γ 是折扣因子。
- 智能体维护一个由 θ 参数化的策略 π<sub>θ</sub>。
- 智能体在任务 c 上的性能通过预期回报 J<sub>c</sub>(θ) = E<sub>π<sub>θ</sub>, M<sub>c</sub></sub>∑\
- 总体目标通常是最大化所有任务的平均性能,J(θ) = (1/|C|) ∑<sub>c∈C</sub> J<sub>c</sub>(θ)。
- 课程设计问题涉及在每个步骤选择一个任务序列或任务分布来训练智能体,以最大化朝着最终目标的学习速度。
论文中的图 1 说明了在上下文多任务设置中课程学习的总体概念。
6. 符号表示 (Notation)
7. 设计 (Design)
设计问题被表述为在每个训练步骤选择下一个要训练智能体的任务(或一批任务),目标是最大化朝着最终目标(通常是最大化所有任务的平均性能)的学习进展。
- 设计问题: 如何在每个训练步骤 t 选择一个任务 c(或任务上的分布 p(c))来更新策略参数 θ<sub>t</sub> 到 θ<sub>t+1</sub>,从而使整体性能 J(θ) 尽可能快地提高。
- 决策变量: 核心决策变量是为下一次训练更新选择的任务 c ,或者更一般地,是从中抽取下一个训练任务的任务集合 C 上的概率分布 p(c)。PROCURL 策略旨在基于最大化预期提升的原则来计算这种选择/分布。
图 1 有助于可视化课程策略为 RL 智能体选择任务的设置。图 2 说明了指导设计的 ZPD 概念。
8. 解决方案 (确定决策变量) (Solution - Determining Decision Variables)

9. 定理 (Theorems)
该论文主要通过在简化设置中的分析来呈现理论结果,而不是正式陈述和编号的定理。驱动 PROCURL 的核心理论见解源于对两种设置中学习进展的分析:
-
多臂赌博机类比 (Multi-Armed Bandit Analogue) (第 3.1 节):
- 内容: 分析了一个简化场景,其中每个"臂"对应一个任务,拉动一个臂会产生该任务梯度范数平方 (||∇J<sub>c</sub>(θ)||<sup>2</sup>) 的噪声估计。它表明,选择当前对此梯度范数平方估计最高的臂(任务)可以最大化整体目标函数的预期单步提升。
- 解释: 这证明了选择性能梯度较大的任务是合理的,因为这表示了一个陡峭上升的方向,因此通过在该任务上训练具有很高的即时改进潜力。
-
线性上下文赌博机设置 (Linear Contextual Bandit Setting) (隐含在推导中):
- 内容: 分析通常假设局部线性或使用一阶泰勒近似(在优化分析中常见)来近似提升 (Δ<sub>c</sub>(θ) ≈ α ||∇J<sub>c</sub>(θ)||<sup>2</sup>)。
- 解释: 这种近似将预期的即时性能增益直接与任务特定梯度的平方范数联系起来,强化了梯度较大的任务提供更快学习进展潜力的观点。
虽然没有标记为"定理 1"、"定理 2"等,但这些分析部分为 PROCURL 策略提供了理论基础。
10. 设计过程 (执行步骤) (Process of Design - Execution Procedure)
与深度强化学习算法(如 DQN 或 DDPG)集成的实用 PROCURL 变体 (ProCuRL-val) 的分步执行过程通常如下:
- 初始化 (Initialization): 初始化智能体的策略/价值函数参数 (θ)。初始化可用任务集 C。
- 任务选择 (Task Selection):
- 对于每个任务 c ∈ C(或当前考虑的子集):
- 使用当前策略/价值函数 π<sub>θ</sub> 估计提升潜力。在 ProCuRL-val 中,这涉及计算基于该任务 Q 值的度量,例如 std<sub>a</sub>(Q<sub>c</sub><sup>π<sub>θ</sub></sup>(s<sub>0</sub>, a)) 或 max<sub>a</sub>(Q<sub>c</sub><sup>π<sub>θ</sub></sup>(s<sub>0</sub>, a)) - min<sub>a</sub>(Q<sub>c</sub><sup>π<sub>θ</sub></sup>(s<sub>0</sub>, a))。
- 选择最大化此估计提升度量的任务 c*。
- 对于每个任务 c ∈ C(或当前考虑的子集):
- 智能体训练 (Agent Training):
- 与所选任务 c* 的环境交互一定数量的步骤(或回合)。
- 将收集到的经验(转移)存储在回放缓冲区中(通常是特定于任务的或通用的缓冲区)。
- 采样一批数据(可能优先考虑来自 c* 的数据或进行通用采样)。
- 使用采样批次和所选 RL 算法的损失函数对智能体的参数 θ 执行梯度更新步骤。
- 重复 (Repeat): 返回步骤 2(任务选择)进行下一次训练迭代。
- 终止 (Termination): 在固定的训练步数、回合数后或性能收敛时停止。
11. 模拟 (Simulations)
模拟验证了 PROCURL 相对于基线方法(如均匀/独立同分布任务采样、Goal GAN、ALP-GMM)在各种环境中的有效性。验证的关键方面和结果包括:
- 加速学习 (Accelerated Learning): 与基线相比,PROCURL 显著加快了训练过程,在 PointMass、FetchReach、AntMaze 和 BasicKarel 等环境中,用更少的训练步骤达到了更高的性能水平。(参见图 3, 4, 5, 6, 11)。
- 鲁棒性 (Robustness): 实用变体 ProCuRL-val 在没有大量超参数调整的情况下表现良好,这与其他一些需要调整的课程方法不同。
- 可扩展性 (Scalability): 在简单的网格世界和更复杂的具有连续状态/动作空间的机器人模拟任务中都展示了有效性。
- ZPD 相关性 (ZPD Correlation): 分析表明,PROCURL 选择的任务通常与中等难度水平相关,这与 ZPD 的直觉一致(例如,图 7 显示了任务选择频率)。
- 在更难任务上的性能 (Performance on Harder Tasks): 即使任务池变得更具挑战性,PROCURL 也表现出更好的泛化能力和更快的学习速度(图 11)。
12. 讨论 (局限性与未来工作) (Discussion - Limitations and Future Work)
论文提到了以下局限性和潜在的未来工作方向:
-
局限性 (Limitations):
- 理论分析依赖于简化的设置和近似(例如,用于提升的一阶泰勒展开)。基于 Q 值的实用度量与理论上的预期提升(梯度范数)之间的直接联系是启发式的。
- 实际实现需要计算 Q 值统计数据以进行任务选择,这与更简单的策略(如均匀采样)相比增加了一些计算开销,尽管通常少于需要完整梯度计算的方法。
- 与许多强化学习方法一样,即使课程部分需要较少调整,性能仍然可能对底层强化学习算法的超参数(学习率、网络架构等)敏感。
-
未来工作 (Future Work):
- 在实用价值度量与真实预期学习进展之间建立更深入的理论联系。
- 探索考虑长期学习进展而非仅仅下一步梯度提升的非短视课程策略。
- 研究 PROCURL 在强化学习之外的其他学习范式(如监督学习或自监督学习)中的适用性。
- 将框架扩展到处理动态变化的任务集或任务生成。
- 将 PROCURL 与自动任务生成或参数化的技术相结合。