Kafka 全面解析
- [一、Kafka 简介与发展历程](#一、Kafka 简介与发展历程)
-
- [1. Kafka 简介](#1. Kafka 简介)
- [2. 发展历程](#2. 发展历程)
- 二、核心概念与术语
- [三、Kafka 架构与组件详解](#三、Kafka 架构与组件详解)
-
- [1. Broker 集群](#1. Broker 集群)
- [2. ZooKeeper 与 KRaft](#2. ZooKeeper 与 KRaft)
- [3. Topic 与 Partition 设计](#3. Topic 与 Partition 设计)
- [4. 副本机制与数据同步](#4. 副本机制与数据同步)
- [5. 日志存储机制](#5. 日志存储机制)
- [四、Kafka 消息生产与消费流程](#四、Kafka 消息生产与消费流程)
-
- [1. 消息生产流程](#1. 消息生产流程)
- [2. 消息消费流程](#2. 消息消费流程)
- 五、性能调优与最佳实践
- 六、事务处理、幂等性与数据一致性
- [七、 Kafka 应用场景与案例分析](#七、 Kafka 应用场景与案例分析)
- [八、 监控、故障排查与安全性](#八、 监控、故障排查与安全性)
- [九、Kafka 与其他消息中间件对比](#九、Kafka 与其他消息中间件对比)
- [十、 Kafka 客户端开发实践与生态工具](#十、 Kafka 客户端开发实践与生态工具)
- 总结
一、Kafka 简介与发展历程
1. Kafka 简介
Apache Kafka 最初由 LinkedIn 开发,2011 年贡献给 Apache 基金会,现已成为大数据实时流处理、分布式消息系统的事实标准。Kafka 主要特点包括:
-
高吞吐量与低延迟 :每秒能处理上十万甚至上百万条消息,延迟仅几毫秒;
-
分布式与可扩展:采用分区(Partition)机制,实现横向扩展,支持集群扩容;
-
持久化存储与容错 :消息持久化写入磁盘,并支持多副本备份,确保数据不丢失;
-
灵活的消息传输模式:既支持点对点也支持发布订阅,通过消费者组实现负载均衡;
-
实时流处理:与 Kafka Streams、Flink、Spark Streaming 等流处理框架无缝集成。
2. 发展历程
Kafka 的版本演进和设计改进使其不断提升性能和易用性,下面用表格展示其主要版本特点:
| 版本 | 主要特性描述 | 发布时间 |
|---|---|---|
| 0.7.x | 提供基础消息队列功能,较为简单的设计 | 2010 年前后 |
| 0.8.x | 引入分区与副本机制,实现分布式高可靠性,支持 ZooKeeper 协调 | 2011-2013 年 |
| 0.9.x | 增加权限和认证、引入新的 Consumer API、改进消费者组管理 | 2014 年 |
| 0.10.x | 引入时间戳支持、Kafka Streams 及其他改进,正式定位为流处理平台 | 2015-2016 年 |
| 0.11.x | 支持幂等性 Producer、跨分区事务,消息格式重构,提高数据一致性 | 2017 年 |
| 1.x / 2.x | 持续优化 Kafka Streams、性能调优、稳定性提升,以及 KRaft 模式试验 | 2018-至今 |
随着版本不断更新,Kafka 从依赖 ZooKeeper 管理元数据逐步向 KRaft 模式过渡,简化了集群管理流程。
二、核心概念与术语
Kafka 系统中涉及到众多核心概念,理解这些术语对掌握 Kafka 的内部工作原理至关重要。下面的表格对常用术语进行了整理:
| 术语 | 定义及说明 |
|---|---|
| Topic | 消息主题,用于逻辑分组消息。每个 Topic 是一个消息队列,可被多个生产者写入,多个消费者订阅。 |
| Partition | Topic 的物理分区,保证消息有序写入,每个 Partition 是一个有序的不可变消息日志。 |
| Offset | 每条消息在 Partition 内的顺序标识符,由消费者维护,用于记录消费进度。 |
| Broker | Kafka 集群中的服务器实例,负责存储和转发消息。每个 Broker 有唯一的 broker.id。 |
| Producer | 消息生产者,负责将消息发送到 Kafka 集群中的指定 Topic。 |
| Consumer | 消息消费者,从 Kafka 集群中拉取消息。通过消费者组实现消息负载均衡。 |
| Consumer Group | 消费者组,由多个消费者实例构成,同一组内同一 Partition 只被一个消费者消费。 |
| Replication | 副本机制,每个 Partition 可配置多个副本,其中 Leader 处理读写,其余为 Follower,同步复制 Leader 数据。 |
| ISR | In-Sync Replicas,同步副本集合,包含所有与 Leader 数据保持同步的副本。 |
| LEO | Log End Offset,每个 Partition 中最后一条消息的下一个 Offset。 |
| HW | High Watermark,Kafka 中已提交数据的最高 Offset,消费者只能读取 HW 之前的数据。 |
| ZooKeeper | 分布式协调服务,用于管理 Kafka 集群的元数据(在新版本中逐步被 KRaft 替换)。 |
| KRaft | Kafka Raft 模式,Kafka 内部自管理元数据的新架构,摆脱了对 ZooKeeper 的依赖。 |
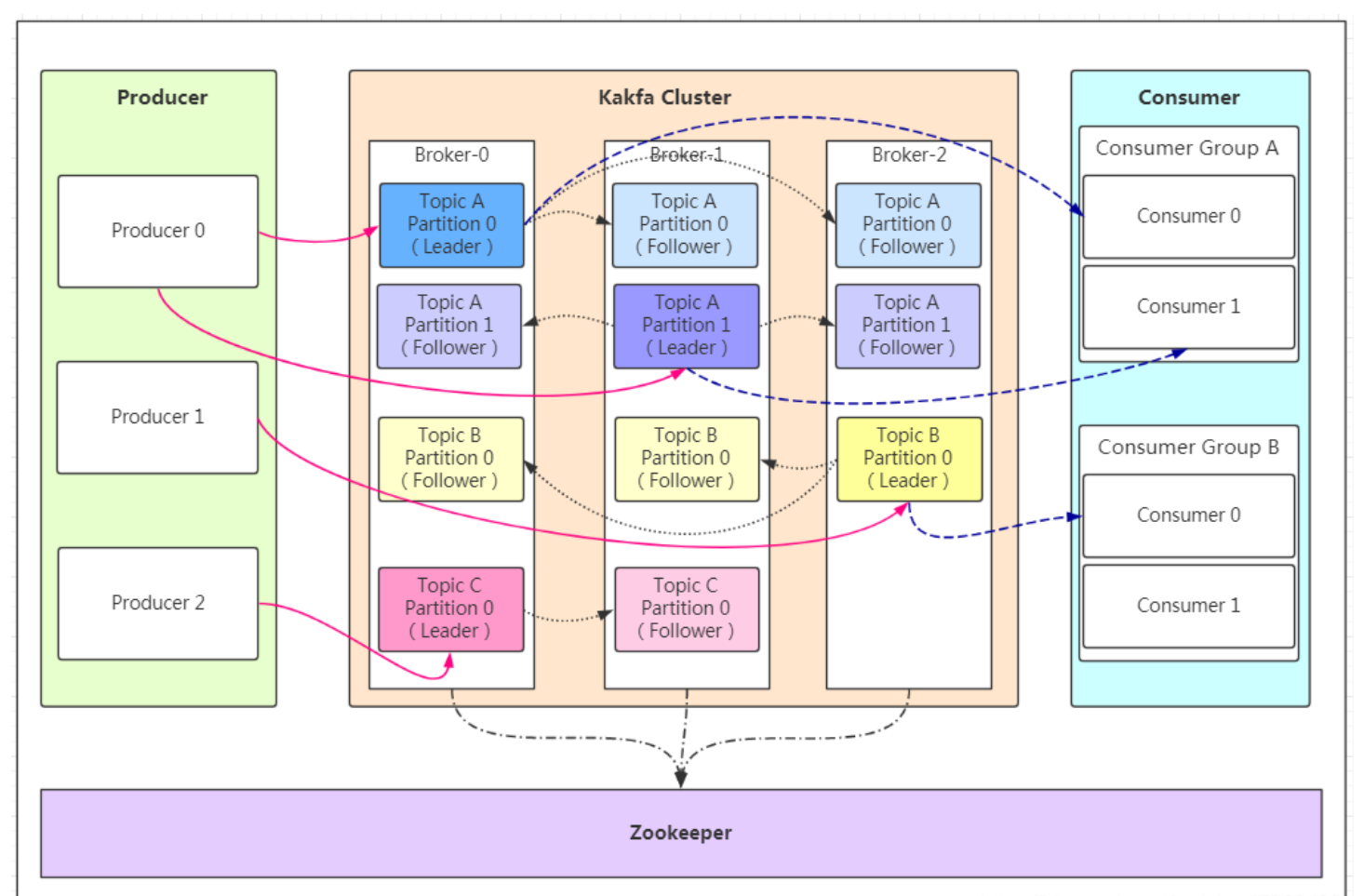
三、Kafka 架构与组件详解
Kafka 的架构设计充分考虑了高性能、分布式扩展和容错能力。下面介绍各个核心组件及其工作原理。
1. Broker 集群
Kafka 集群由多个 Broker 组成,每个 Broker 在集群中存储部分 Topic 的 Partition。集群中 Broker 之间通过内部协议交换元数据、进行负载均衡和故障切换。
Broker 核心功能:
-
消息存储
采用追加写入(append-only)的方式将消息写入磁盘文件,利用顺序写高效性以及操作系统页缓存提高性能。
-
数据复制
每个 Partition 的数据复制到多个 Broker(副本),Leader 负责处理读写,Follower 异步复制数据,保证数据高可用。
-
请求处理
Broker 处理生产者的写请求和消费者的拉取请求,并负责消息的序列化和反序列化。
2. ZooKeeper 与 KRaft
在传统架构中,Kafka 使用 ZooKeeper 管理集群元数据,包括 Broker 注册、Leader 选举、Topic 分区信息以及消费者 Offset(旧版 Consumer 方式)。在 Kafka 2.8 以后,引入 KRaft 模式,元数据管理逐步迁移到 Kafka 内部,简化了集群管理架构。
3. Topic 与 Partition 设计
每个 Topic 分为若干 Partition,每个 Partition 是一个有序的消息日志。
sql
Topic "orders":
├── Partition 0 (日志文件 orders-0)
├── Partition 1 (日志文件 orders-1)
└── Partition 2 (日志文件 orders-2)
在每个 Partition 内,消息按写入顺序追加,并赋予唯一 Offset。多个 Partition 的设计既提高了并发读写能力,也使得消息在同一 Partition 内保持顺序性。
4. 副本机制与数据同步
为了保证数据可靠性,Kafka 为每个 Partition 提供多副本机制。下面的表格描述了副本相关的核心参数和概念:
| 参数或概念 | 说明 | 建议配置或注意事项 |
|---|---|---|
| Replication Factor | 副本数,决定一个 Partition 数据在集群中复制的数量。 | 生产环境通常设置为 3 或更多,以确保容错性。 |
| Leader | Partition 中负责处理所有读写请求的主副本。 | 需均衡分布在各 Broker 上,防止热点。 |
| Follower | 负责跟 Leader 同步数据的备份副本。 | 需保持与 Leader 的数据同步,滞后时间不能过长。 |
| ISR | 同步副本集合,只有与 Leader 保持同步的副本才在此集合中。 | Follower 若长时间滞后则会被踢出 ISR。 |
| HW (High Watermark) | 已提交消息的最高 Offset,消费者只能拉取 HW 之前的消息。 | HW 由 Leader 与 ISR 中最小 LEO 决定。 |
5. 日志存储机制
Kafka 使用日志结构存储,将每个 Partition 以文件形式存储,每个文件进一步拆分为多个 Segment。Segment 文件结构包括数据文件和索引文件。下面是 Segment 文件存储结构的示意表:
| 文件类型 | 后缀 | 功能说明 |
|---|---|---|
| 日志数据文件 | .log | 存储实际消息数据,以追加写方式写入。 |
| 偏移量索引文件 | .index | 建立消息 Offset 与数据文件中物理位置之间的映射。 |
| 时间索引文件 | .timeindex | 根据时间戳建立消息与 Offset 之间的映射,便于按时间查找。 |
这种设计充分利用了顺序写磁盘的高效性,同时利用内存映射(mmap)技术实现 O(1) 级别的随机查找,大大提高了日志读取和数据恢复的性能。
四、Kafka 消息生产与消费流程
Kafka 的消息传输流程涉及生产者发送、Broker 写入、数据复制和消费者拉取,下面详细说明各个环节。
1. 消息生产流程
-
消息封装
生产者将待发送数据封装成 ProducerRecord 对象,包含 Topic、Key、Value 和可选的 Partition 信息。
-
分区选择
-
若手动指定 Partition,则直接写入该 Partition。
-
若未指定 Partition但提供 Key,则使用 Key 的 hash 值决定 Partition。
-
若 Key 为空,则采用轮询方式分配 Partition。
-
-
消息发送与 ACK
生产者将消息发送给对应 Partition 的 Leader Broker,根据 acks 参数等待确认:
-
acks=0:不等待确认,快速但风险较大。
-
acks=1:等待 Leader 写入成功返回确认。
-
acks=all(或 -1):等待所有 ISR 内副本同步后返回确认。
-
-
数据复制
Leader Broker 接收到消息后,异步将数据复制到所有 Follower Broker,更新 ISR 与 High Watermark(HW)。
-
幂等性与事务(可选)
如果启用了幂等性,生产者会为每个分区记录唯一的 PID 与序列号,防止重试过程重复写入。若启用事务,则生产者将消费、生产和 Offset 提交打包为原子操作。
2. 消息消费流程
-
订阅主题
消费者通过 subscribe() 方法订阅一个或多个 Topic,并加入一个 Consumer Group。
-
拉取消息
消费者调用 poll() 方法主动从 Broker 拉取数据,Broker 根据消费者在组中的分配情况返回对应 Partition 的数据。
-
处理消息
消费者对拉取的消息进行反序列化和业务逻辑处理。
-
Offset 提交
消费成功后,消费者提交当前 Offset 至 Kafka 内部的 __consumer_offsets 主题,支持自动提交和手动提交两种方式。
-
再均衡
当消费者数量变化或 Broker 故障时,Kafka 会触发再均衡,重新分配 Partition 给消费者,确保消息被均匀消费。
下面给出消费者 Offset 提交与再均衡的关键参数表:
| 参数 | 说明 | 建议配置 |
|---|---|---|
| enable.auto.commit | 是否自动提交 Offset,默认 true | 对于要求精确一次语义建议 false |
| auto.commit.interval.ms | 自动提交 Offset 的时间间隔 | 1000~5000 毫秒,根据负载调整 |
| max.poll.records | 每次 poll 拉取的最大消息数 | 500~1000,根据消息大小调整 |
| session.timeout.ms | 消费者与 GroupCoordinator 心跳超时时间 | 30000 毫秒左右 |
五、性能调优与最佳实践
针对不同场景,可通过调整配置参数和硬件资源,达到最佳性能和稳定性。
- 生产者调优参数
| 参数 | 说明 | 建议值或注意事项 |
|---|---|---|
| batch.size | 每批次发送消息的最大字节数 | 16KB ~ 32KB,根据消息大小调整 |
| linger.ms | 在达到 batch.size 前等待更多消息的时间 | 1-5 毫秒,根据吞吐量需求调整 |
| buffer.memory | 生产者用于缓存消息的总内存大小 | 32MB ~ 64MB,根据生产者压力调整 |
| compression.type | 压缩类型(none、gzip、snappy、lz4) | 根据数据特点选择,推荐 snappy/lz4 |
| retries | 发送失败时自动重试次数 | 建议设置为较高值,结合幂等性一起使用 |
| acks | 消息确认级别(0、1、all/-1) | 要保证高可靠性,建议使用 all 或 -1 |
- 消费者调优参数
| 参数 | 说明 | 建议值 |
|---|---|---|
| max.poll.records | 每次 poll 最大拉取消息数量 | 500~1000,根据消费速率调整 |
| fetch.min.bytes | 每次 poll 拉取的最小数据量 | 1KB~64KB,根据网络情况调整 |
| fetch.max.bytes | 每次 poll 最大拉取的数据量 | 50MB,确保不超大导致内存压力 |
| session.timeout.ms | 消费者与 GroupCoordinator 心跳超时时间 | 30000 毫秒左右 |
| enable.auto.commit | 是否自动提交 Offset | 高可靠性场景建议关闭,采用手动提交 |
- Broker 调优建议
-
硬件选型
使用 SSD 磁盘提高顺序写性能;配置高速网络;增加内存用于页缓存。
-
日志配置
调整
log.segment.bytes、log.retention.hours、log.flush.interval.ms,平衡存储与性能。 -
资源监控
使用 JMX、Prometheus、Grafana 等工具监控 CPU、内存、磁盘 IO、网络流量与消费者滞后情况,及时调整集群规模和配置。
六、事务处理、幂等性与数据一致性
为了解决消息重复与丢失问题,Kafka 从 0.11 版本开始支持生产者幂等性与跨分区事务。
-
幂等性 Producer
启用幂等性后,生产者在重试时不会重复写入相同消息。配置参数如下:
| 参数 | 说明 |
|---|---|
| enable.idempotence | 设置为 true,即可启用幂等性 |
| max.in.flight.requests.per.connection | 建议设置为 1 或 5,确保消息顺序性 |
Kafka 会为每个生产者分配一个 PID,并为每个分区维护消息序列号,确保消息顺序一致。
-
跨分区事务
跨分区事务可以将生产、消费与 Offset 提交整合为原子操作,确保"恰好一次"语义。使用时需要配置:
-
transactional.id:唯一事务 ID;
-
启用幂等性(enable.idempotence=true);
事务处理主要流程:
-
初始化事务:调用 initTransactions()。
-
开始事务:调用 beginTransaction()。
-
发送消息和提交 Offset:调用 send() 与 sendOffsetsToTransaction()。
-
提交或中止事务:调用 commitTransaction() 或 abortTransaction()。
-
七、 Kafka 应用场景与案例分析
Kafka 广泛应用于各类大数据和实时流处理场景,以下是一些典型案例:
- 日志收集与集中管理
-
场景描述
分布式系统中,各个应用服务器产生大量日志数据。Kafka 作为日志收集中间件,将日志数据实时传输到日志分析平台(如 ELK、Splunk)。
-
优势
高吞吐、实时性好,支持数据持久化,便于后续分析与审计。
- 用户行为跟踪与实时监控
-
场景描述
网站或 APP 产生的用户点击、浏览、搜索等行为数据,通过 Kafka 进行实时收集,结合 Spark Streaming 或 Flink 进行实时分析,实现用户行为监控与实时推荐。
-
优势
能够支撑高并发流量,实时统计指标,及时响应异常情况。
- 数据管道与 ETL
-
场景描述
企业数据平台将多个数据源(如数据库、日志、传感器数据)实时汇聚到 Kafka 集群,再通过 Kafka Connect 将数据导入到 Hadoop、Elasticsearch 等系统,进行离线分析和报表制作。
-
优势
解耦数据源与数据处理系统,实现数据异构系统之间高效传输。
- 事件驱动微服务架构
-
场景描述
在微服务架构中,各个服务通过 Kafka 进行异步通信,实现事件驱动模式,降低服务之间的耦合度。
-
优势
提供可靠的消息传递,支持消息重放,便于故障排查与扩展。
下面给出一个 Kafka 应用场景的对比表:
| 应用场景 | 优点 | 典型应用案例 |
|---|---|---|
| 日志收集与管理 | 高吞吐、集中存储、便于后续审计 | ELK、Splunk |
| 用户行为实时分析 | 实时性好、支持大数据量、便于个性化推荐 | 电商、社交网络平台 |
| 数据管道与 ETL | 解耦数据源、跨系统数据传输、易于扩展 | 数据仓库、数据湖建设 |
| 微服务事件驱动架构 | 降低服务耦合、支持异步通信、具备重放与补偿机制 | 金融风控、订单处理、物流调度 |
八、 监控、故障排查与安全性
-
监控指标
Kafka 通过 JMX 提供大量监控指标,常见的有:
-
Broker 指标
CPU、内存、磁盘 IO、网络流量等;
-
Topic/Partition 指标
消息吞吐量、写入延迟、日志大小、ISR 状态等;
-
消费者指标
消费滞后(Lag)、 Offset 提交频率等;
-
系统级指标
请求失败率、重试次数等。
-
-
常用监控工具
-
JMX 工具
如 JConsole、VisualVM 监控 Kafka Broker 的 JMX 指标。
-
Prometheus + Grafana
采集 Kafka 指标,并通过 Grafana 制作监控大盘。
-
Kafka Manager/CMAK
提供集群状态、主题及消费者组的可视化管理界面。
-
-
故障排查与容错
常见故障排查思路:
-
查看 Broker 日志
定位 Broker 启动、复制、网络异常等问题。
-
检查消费者滞后
消费者 Lag 指标异常可能提示某个分区处理慢或宕机。
-
监控 ISR 变化
若 ISR 持续缩减,说明部分 Follower 无法同步,可能由于硬件或网络问题。
-
验证 ZooKeeper 状态
确保 ZooKeeper 集群正常工作,元数据更新及时。
-
-
安全性
Kafka 支持多种安全特性:
-
身份认证
支持 SASL 认证方式(如 SASL/PLAIN、SASL/SCRAM);
-
数据加密
支持 SSL 加密传输;
-
访问控制
通过 ACL 控制生产者和消费者访问权限;
-
数据审计
日志记录与监控帮助追踪数据流向和操作行为。
-
九、Kafka 与其他消息中间件对比
Kafka 与市场上主流的消息中间件(如 RabbitMQ、RocketMQ)在架构、性能、可靠性等方面各有特点,下面给出对比表:
| 特性 | Kafka | RabbitMQ | RocketMQ |
|---|---|---|---|
| 架构模型 | 分布式、分区日志结构;支持发布订阅与数据流 | 基于 AMQP 协议;点对点和发布订阅混合 | 分布式、基于 CommitLog 模型 |
| 消息吞吐量 | 高(每秒百万级别消息) | 中等(适用于中小流量场景) | 高,适合大规模分布式环境 |
| 消息持久化 | 持久化写入磁盘,追加写方式 | 消息默认存储在内存,持久化需要额外配置 | 基于磁盘的 CommitLog 存储 |
| 数据复制与容错 | 多副本机制,Leader-Follower 模型;支持 ISR | 集群模式支持镜像队列,但复杂性较高 | 支持分布式副本,主从切换机制 |
| 消息确认机制 | ACK 机制可调,支持 acks=0/1/all | 支持消息确认,确保消息可靠传递 | ACK 机制较完善,支持事务 |
| 事务支持 | 从 0.11 开始支持事务,实现"恰好一次"语义 | 原生不支持事务,需借助插件或额外机制 | 部分支持事务,主要用于订单等场景 |
| 延时队列支持 | 需借助延时 Topic 或外部调度实现 | 具备一定延时功能,但使用上相对复杂 | 原生支持延时消息 |
| 使用场景 | 日志收集、实时数据管道、流处理、微服务事件驱动 | 企业级消息传递、任务队列、可靠性较高的业务系统 | 大数据场景、分布式事务、金融支付 |
通过上表可以看出,Kafka 更适合高吞吐、实时数据流处理的场景,而 RabbitMQ 和 RocketMQ 在部分可靠性和事务性要求较高的业务场景中有其独特优势。
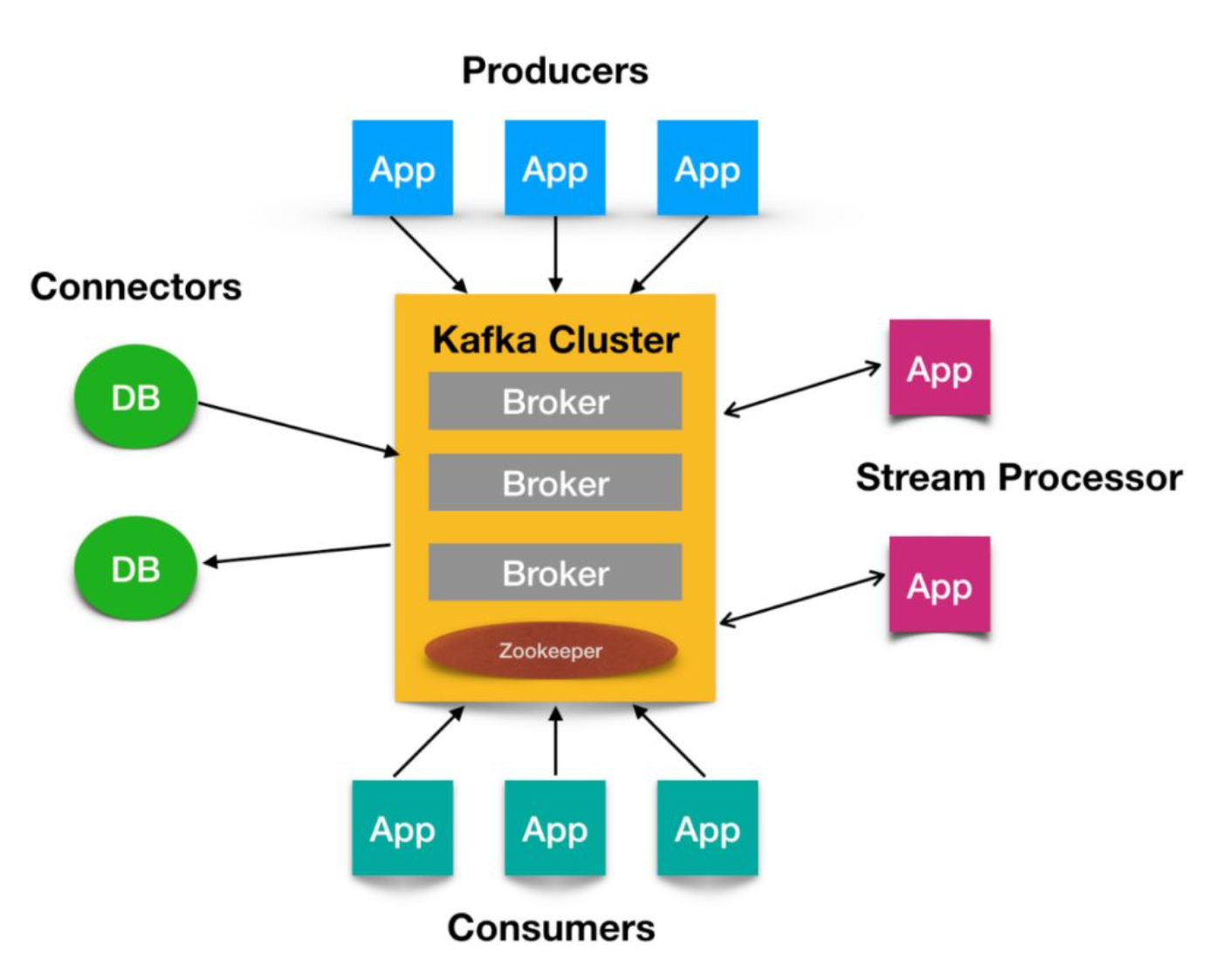
十、 Kafka 客户端开发实践与生态工具
-
客户端 API 介绍
Kafka 为 Java、Python、C/C++、Go 等多种语言提供了客户端库,核心 API 包括:
-
Producer API:用于发送消息,可选择同步或异步方式。
-
Consumer API:用于订阅和消费消息,支持自动和手动 Offset 管理。
-
Streams API:用于构建流处理应用,实现实时数据转换与聚合。
-
Connector API:用于 Kafka 与外部系统之间的数据导入导出。
-
-
开发实践示例
生产者示例代码(Java)
javaimport org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class SimpleProducer { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "kafka-1:9092,kafka-2:9092,kafka-3:9092"); props.put("acks", "all"); props.put("retries", 3); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("enable.idempotence", "true"); props.put("transactional.id", "prod-transaction-001"); KafkaProducer<String, String> producer = new KafkaProducer<>(props); producer.initTransactions(); try { producer.beginTransaction(); for (int i = 0; i < 1000; i++) { ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "key" + i, "value" + i); producer.send(record); } producer.commitTransaction(); } catch (Exception e) { producer.abortTransaction(); e.printStackTrace(); } finally { producer.close(); } } }消费者示例代码(Java)
javaimport org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.Arrays; import java.util.Properties; public class SimpleConsumer { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "kafka-1:9092,kafka-2:9092,kafka-3:9092"); props.put("group.id", "test-group"); props.put("enable.auto.commit", "false"); props.put("auto.offset.reset", "earliest"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("test-topic")); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); } consumer.commitSync(); } } } -
Kafka 生态工具
-
Kafka Streams:内置流处理库,实现实时数据转换与聚合。
-
Kafka Connect:用于数据导入导出,与数据库、HDFS、Elasticsearch 等系统无缝对接。
-
MirrorMaker:跨集群数据同步工具,支持多数据中心部署。
-
Confluent Platform:包含 Schema Registry、REST Proxy、KSQL 等组件,扩展 Kafka 功能。
-
开源项目:如 CMAK(Kafka Manager)、Burrow(消费者监控)等,为集群管理和监控提供支持。
总结
Kafka 以其卓越的高吞吐、低延迟和分布式容错能力,在大数据、实时流处理、微服务架构和事件驱动系统中发挥着关键作用。本文从 Kafka 的基础概念、架构设计、数据传输流程、性能调优、事务保障、监控安全以及客户端开发实践等多个角度进行全面解析,并通过表格和示例代码帮助读者更直观地理解 Kafka 各个组件和参数的实际作用。
随着 KRaft 模式的成熟,Kafka 的元数据管理将更加简单高效,未来版本可能进一步简化运维、提升容错能力和扩展性。与此同时,随着数据量不断增长和业务场景不断丰富,Kafka 在流处理、分布式事务、消息审计以及安全控制等方面也将持续优化,为企业级应用提供更全面、更可靠的支持。
总之,Kafka 的核心设计思想和不断迭代的创新,使其在分布式系统和实时数据处理领域保持领先。无论是在日志收集、实时数据管道构建,还是在微服务事件驱动架构中,Kafka 都已成为不可或缺的基础设施组件。通过本文的详解,希望读者能够从理论和实践两个层面全面掌握 Kafka 的内在原理与运用技巧,为构建高性能、高可靠的数据流系统提供坚实保障。