【第十三届"泰迪杯"数据挖掘挑战赛】【2025泰迪杯】【代码篇】A题解题全流程(持续更新)
环境配置:
- 显存>=24GB
- PyTorch 2.3.0
- Python 3.12(ubuntu22.04)
- CUDA 12.1
- autoDL服务器平台,(好处:可以分享镜像,一键初始化服务器实例,不用关心所需环境、所需模型下载等)也可自己实验室服务器部署(全家桶包售后)
代码+模型文件总览
1、其中系统盘为所需模型的文件,比较大,包含clip的clip_cn_vit-b-16.pt,千问是视觉大模型7B量级,以及版面分析模型权重文件,移入autodl平台的服务器系统盘,我已保存为ATI镜像,直接分享镜像,创建实例后即可,不用浪费时间下载。
2、数据盘为代码和数据、解题代码、保存结果,需自己下载,上传服务器的autodl-tmp文件夹。(也可自己本地服务器使用)
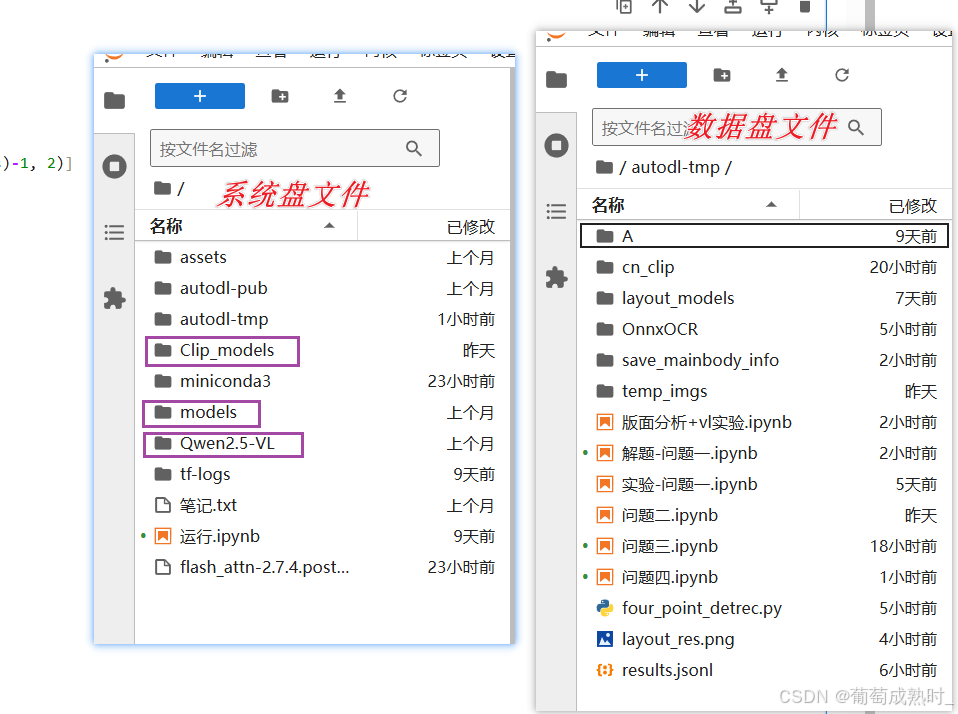
售后提供用户id,直接分享环境镜像
一、针对问题一:
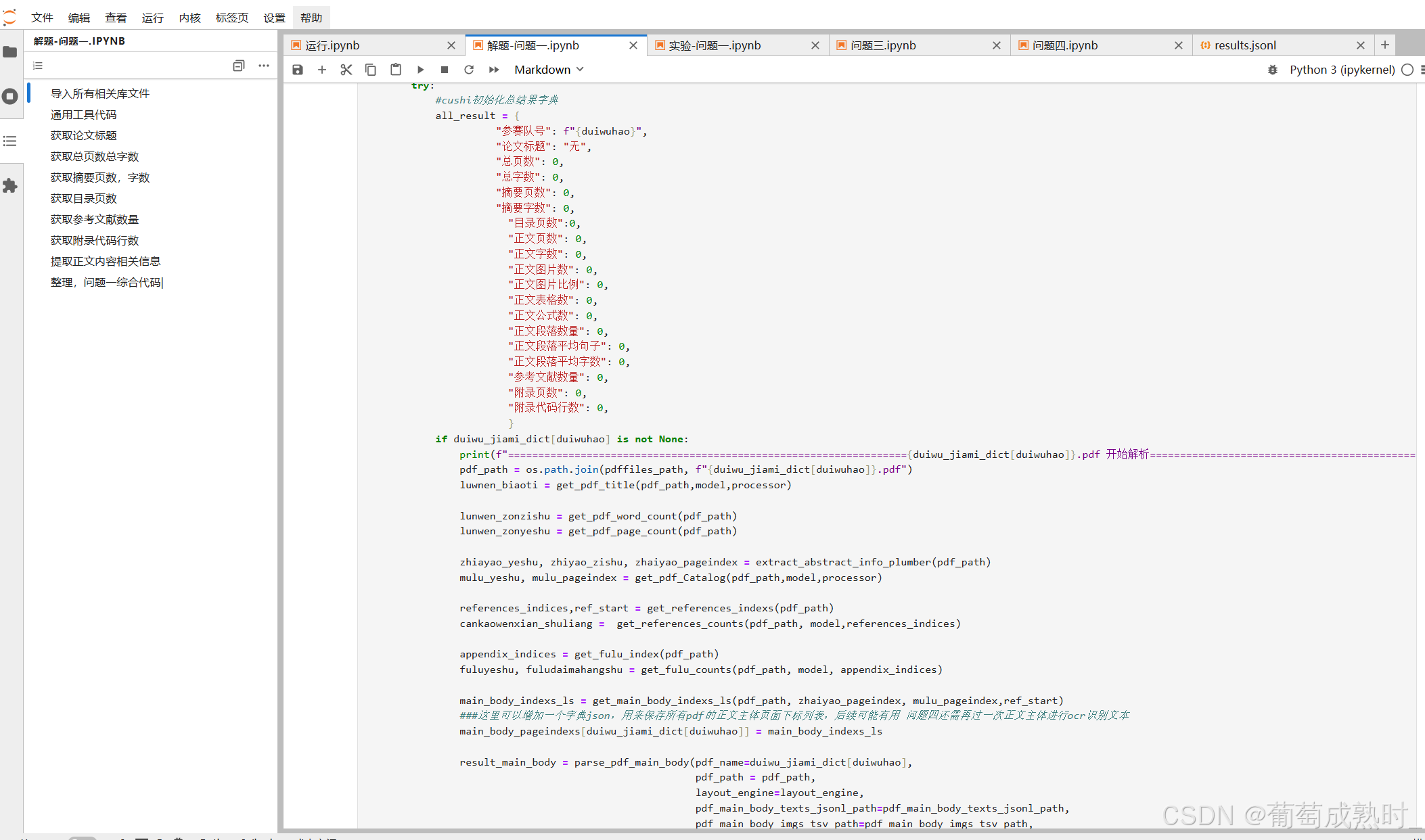
首先通过实验、各种测试后,分模块进行开发功能函数代码,最终汇总功能函数调用,进行解析pdf。获取结果追加进result1.xlsx
- 通过视觉大模型获取论文标题、目录页数下标、附录代码行数、参考文献数据量
- 通过pdf属性获取文本内容、页数、字数
- 综合计算正文内容的页面下标列表,得出正文内容是pdf的哪些页面
- 通过版面分析和pdf属性处理正文部分内容,提取正文文字、表格、图片、公式、计算相关内容等
- 并且保存数据至数据库jsonl、tsv;包括正文内容、图片、公式,用于后续问题的使用


二、针对问题二:
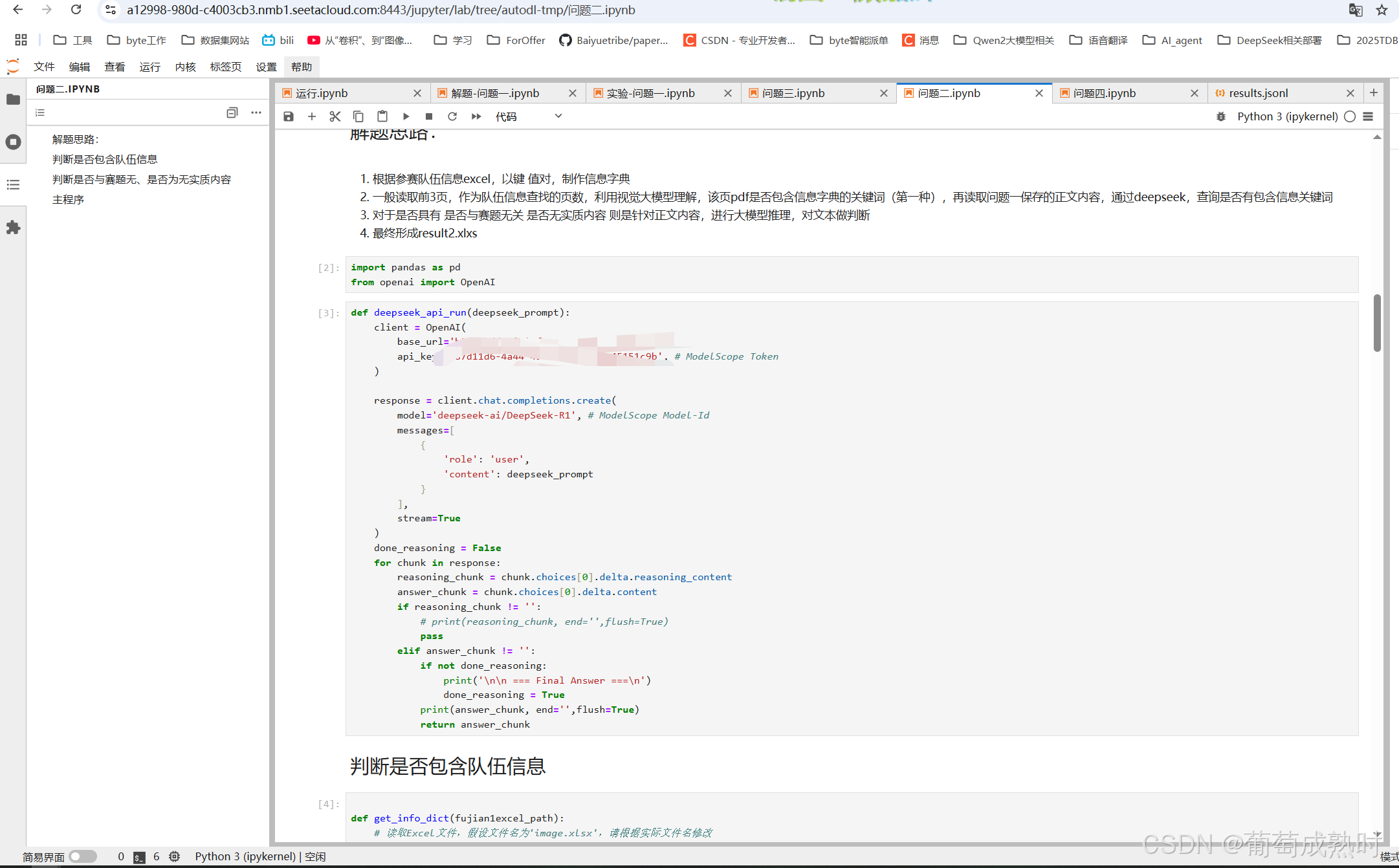
首先读取问题一保存的正文内容数据、以及pdf的摘要部分,进行deepseek R1大模型api调用,判断是否每日免费2k调用额度,针对此任务足够。
- 根据附件一参赛队伍信息excel,以键 值对,制作信息字典
- 一般读取前3页,作为队伍信息查找的页数,利用视觉大模型理解,该页pdf是否包含信息字典的关键词(第一种),再读取问题一保存的正文内容,通过deepseek,查询是否有包含信息关键词
- 对于是否具有 是否与赛题无关 是否无实质内容 则是针对正文内容,进行大模型推理,对文本做判断
- 最终形成result2.xlxs


三、针对问题三:
总体相似度 = 相似字数 / 检测字数
被系统自动识别出来的非正文部分(如目录,标题,公式,图表,参考文献等)不参与检测,检测字数一般略小于论文字数。
相似字数 =(句子1字数 * 句子1相似度 + 句子2字数 * 句子2相似度 + ...... + 句子n字数 * 句子n相似度),句子相似度范围0.00~1.00,绿色句子相似度按照0计算。红色句子为重度相似(80%~100%),建议修改;橙色句子为轻度相似(50%~80%),可酌情修改;绿色句子表示没有检测到相似语句。首先严格按照论文重复率的计算方式来定义论文重复率,该论文重复率是基于此比赛论文的论文库,进行计算每篇论文的重复率。需要基于保存的论文正文部分数据,构建一个论文数据库,再进行对每篇论文遍历,除开自身,计算与其余论文的重复率。
- 论文重复率 = 论文中抄袭字数/论文中总字数
- 构建论文文本重复率代码
- 使用clip模型,图文模态模型,进行对问题一保存的图片、公式图片进行特征导出
- 利用图片、公式图片的特征检索,利用knn特征相似度原理,快速计算,得出雷同图片、雷同公式,并且根据其id分割出页编码、页内顺序(这得益于我们问题一的巧妙设计,保存图片、公式的base64编码为tsv,id为pdfname-页编码-页内顺序)
- 汇总,整理为主程序



四、针对问题四:
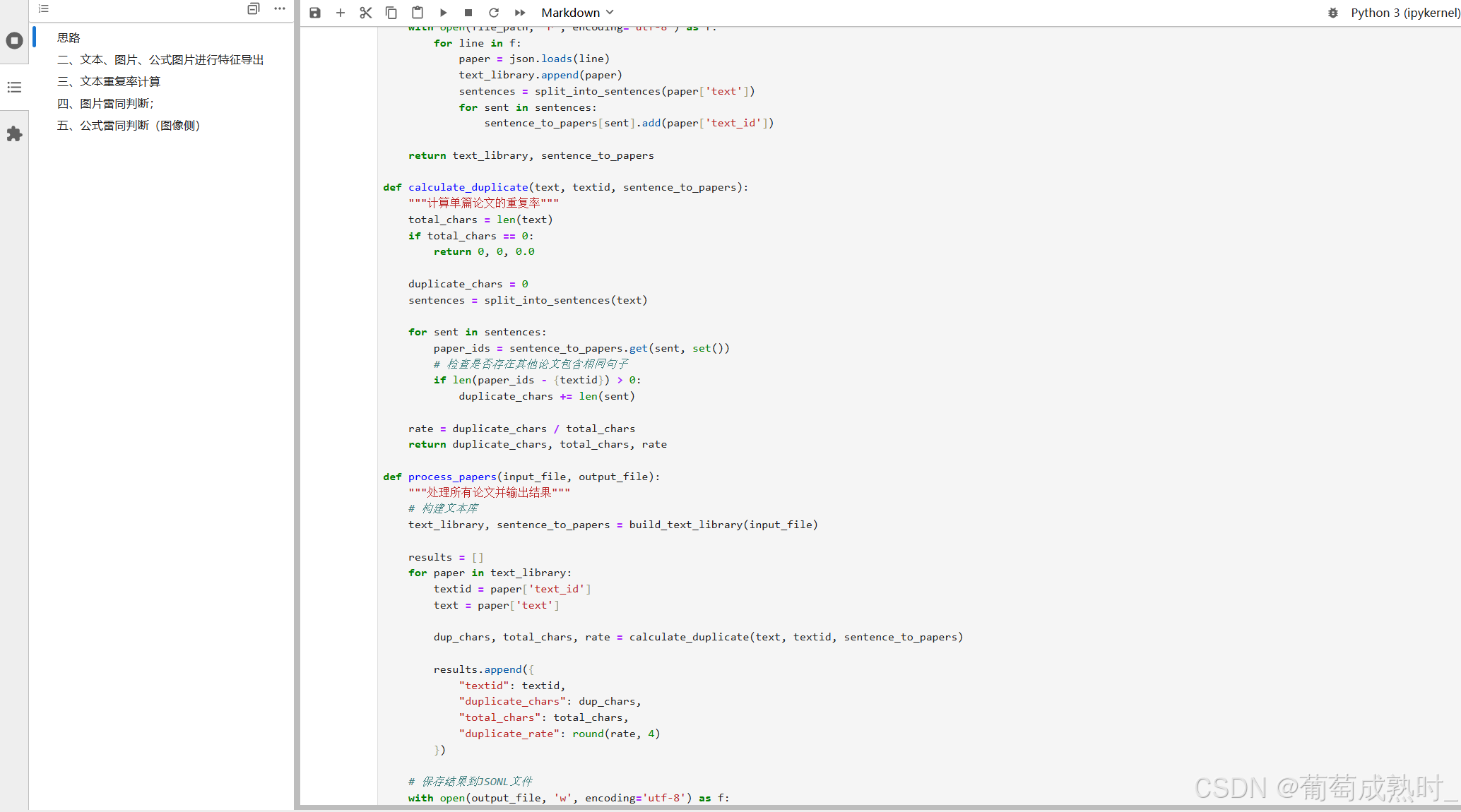
核心任务就是针对问题一的正文内容是使用的pdf属性为文本,提取文本内容,通过result1.xlsx可以看出存在文本字数为0的情况,也即是说会有pdf是又由截图组成的,例如将word内容截图贴图,形成pdf。
所以主要是重新设计提取论文正文部分文本的方法,通过问题一保存的每个论文的正文页面下标,我们遍历每个论文,然后通过版面分析+ocr重新获取正文内容。
-
论文重复率 = 论文中抄袭字数/论文中总字数
-
重新定义版面分析+ocr,处理所有pdf,提取论文中文部分文本(问题一的时候,用的是pdf文字属性,查看结果会发现其,有的pdf全为图片属性,文本属性为0)
-
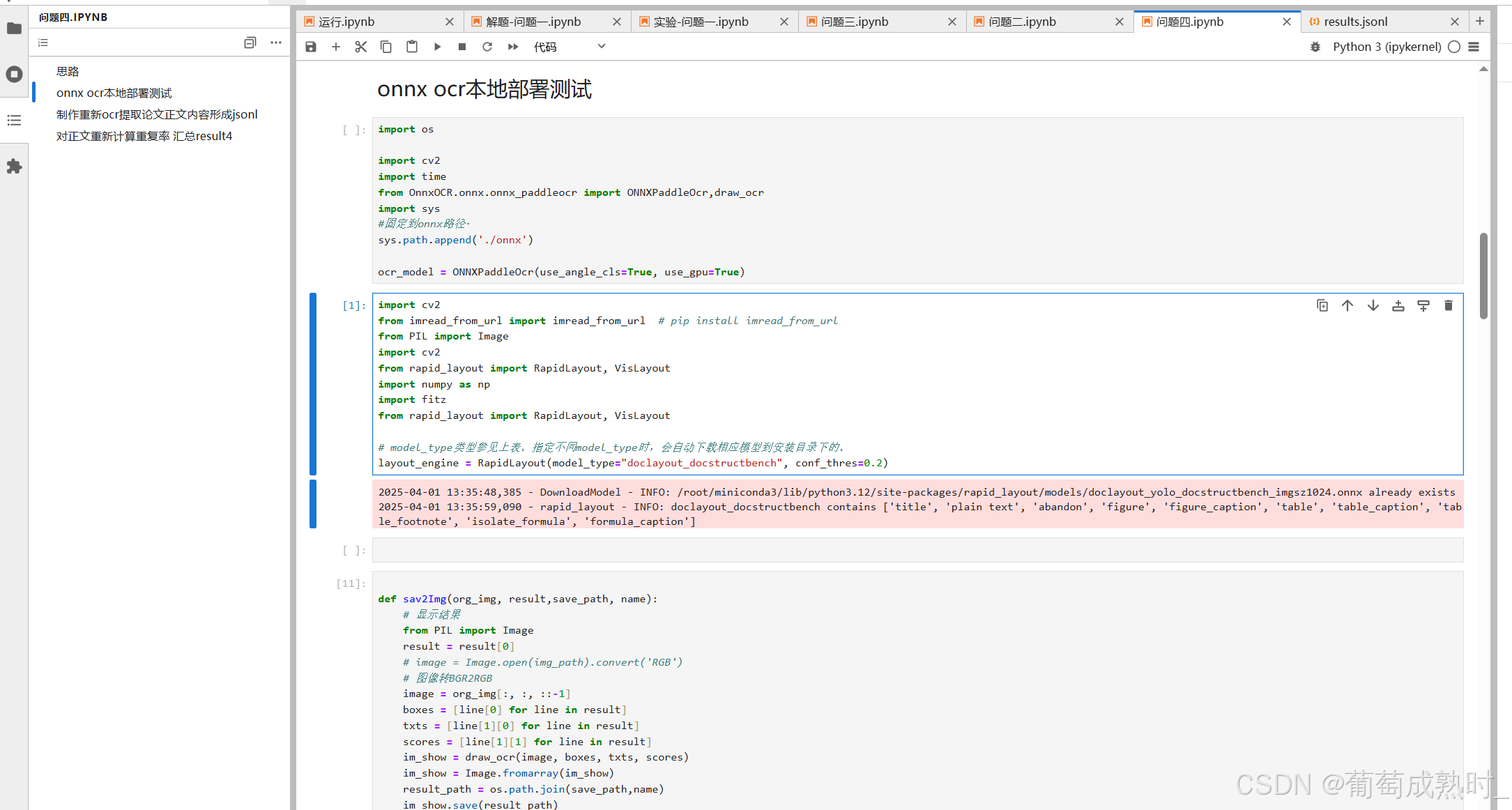
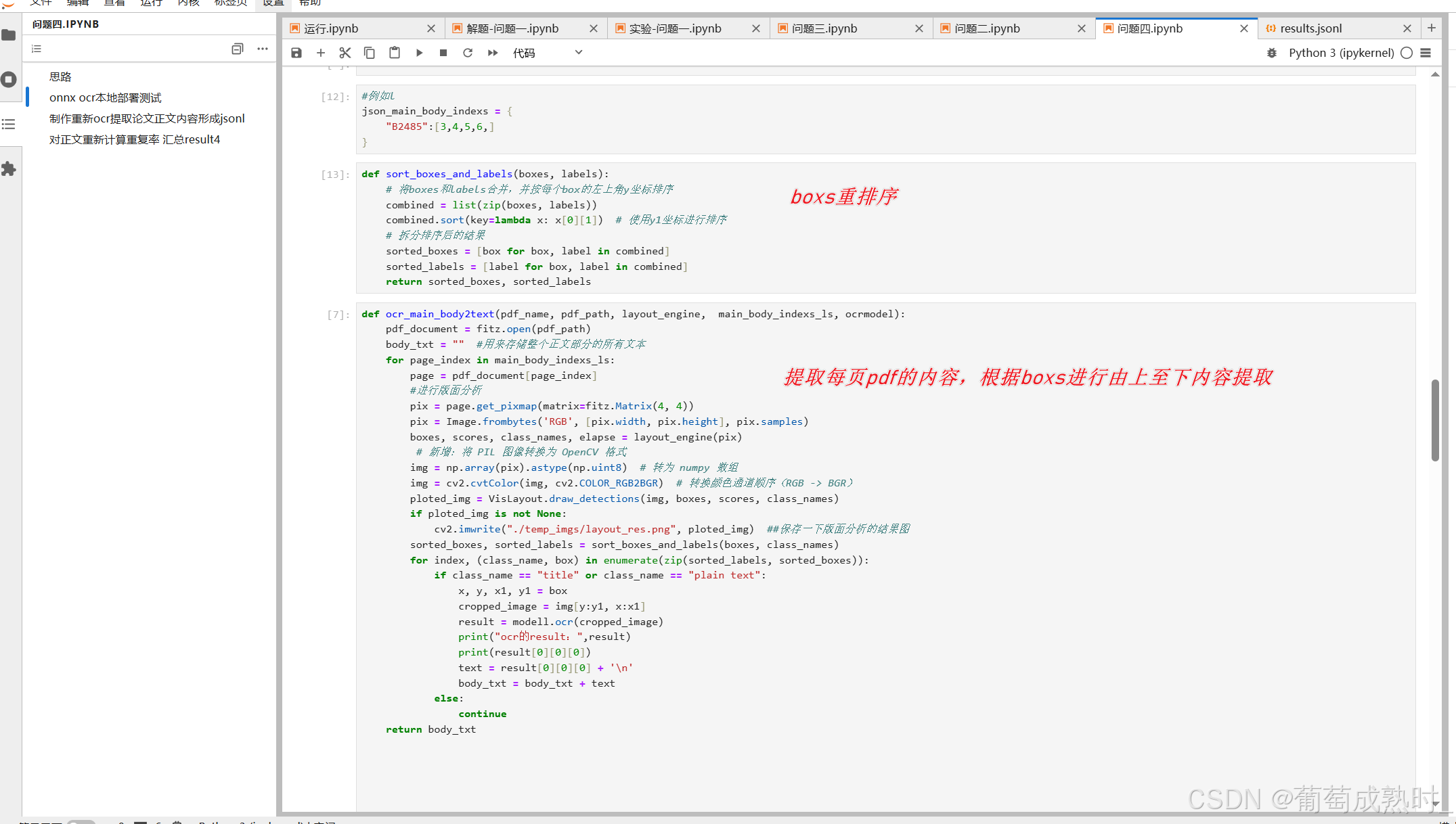
版面分析后,根据label和box进行重排序,确保文本顺序为论文中的从上至下
-
ocr为PaddlePaddle的ocr导出onnx模型
赛题全家桶获取
依旧如24年泰迪杯一样,全家桶包含:
- 分问题模块进行录制讲解视频
- 论文一篇(写作中,后两天出,另外梳理论文创新修改点子)
- 代码
- 结果(正式数据出来时,会及时更新结果,同步到售后群)
- 包售后(包括本地实现环境配置,部署实现代码、问题回答、论文指导)
赠品:
老规矩, 比赛结束后,制作【基于大模型的pdf文件转换提取系统】
(利用大模型+版面分析将pdf无缝转换为Markdown文件,文本、图片、公式按顺序呈现)
获取链接
烦请移步社区:http://t.csdnimg.cn/ZIgVI
【基于大模型的pdf文件转换提取系统】
(利用大模型+版面分析将pdf无缝转换为Markdown文件,文本、图片、公式按顺序呈现)